基于超启发式遗传算法的生产过程智能调度方法及系统与流程
1.本发明属于生产调度技术领域,尤其涉及基于超启发式遗传算法的生产过程智能调度方法及系统。
背景技术:
2.本部分的陈述仅仅是提供了与本发明相关的背景技术信息,不必然构成在先技术。
3.零等待间歇生产是一种常见的流水车间生产模式,用于为需要维持相邻工序之间不间断、连续进行,以保证产品加工质量的工艺路线提供生产加工,在制药、发酵、纺织等行业的生产领域被广泛应用。科学高效的生产调度不仅是确保零等待间歇生产过程稳定、有序进行的关键,更是提高生产效率、改善车间加工性能的有力手段。
4.零等待间歇生产过程的调度优化旨在保证各产品加工过程中相邻工序之间不间断地连续进行的前提下,为产品指定合理的加工次序,以达到对生产过程中重要指标优化的目的。零等待间歇生产过程调度是流水车间调度的重要形式,已被证实是一项np-hard问题。随着人工智能的兴起,启发式算法被广泛应用于解决相关调度问题的领域。以模拟退火算法、贪婪算法为代表的一类元启发式算法,由于计算成本低、易于实现,被广泛应用于各种场景的调度优化。以粒子群优化与遗传算法为代表的基于群体的启发式算法由于状态空间搜索范围广,种群的特征多样性,结果陷入局部最优的风险小等特点被进一步推广与应用,特别是在零等待间歇生产过程的调度研究方面有杰出贡献。
5.上述启发式优化算法虽然都在调度领域具有突出的表现,但任何一项基于上述算法实现的性能优良的调度优化都离不开基于专业知识对算法的改进,启发式调度算法的改进往往只是针对特定的优化场景与目标,具有广泛适用性的启发式算法往往难以出现。
技术实现要素:
6.为了解决上述背景技术中存在的技术问题,本发明提供基于超启发式遗传算法的生产过程智能调度方法及系统,采用了通过在高级启发式染色体中编码并优化低级启发式操作机制,再以低级启发式操作来演化调度解的方式,实现了对遗传操作机制的自学习进化,不仅表现出更具显著优势的调度优化性能,还保证了在不同调度场景下对不同的优化目标具有广泛适用性。
7.为了实现上述目的,本发明采用如下技术方案:
8.本发明的第一个方面提供基于超启发式遗传算法的生产过程智能调度方法,其包括:
9.获取待加工产品的数量以及每件产品的加工信息,通过基于超启发式遗传算法的智能调度机制初始化并优化产品加工计划的调度解集;
10.从调度解集中选出最优解,以将最优解所表示的加工计划投入产品的生产过程;
11.其中,基于超启发式遗传算法的智能调度机制将一条启发式染色体与一条生产次
序染色体组成一个调度解,一条启发式染色体由若干个启发式操作组成,一条生产次序染色体为所有待加工产品编码的全排列;且基于超启发式遗传算法的智能调度机制进行调度解更新的方式包括启发式染色体之间的交叉和变异操作、以及生产次序染色体根据启发式染色体中的启发式操作进行的遗传操作。
12.进一步地,基于超启发式遗传算法的智能调度机制在每一轮迭代中,从父代子代联合种群中选出综合优势度最高的若干个调度解作为优势个体,组成优势解集,并将选出的优势解集作为下一轮遗传操作的父代种群。
13.进一步地,对于多目标优化调度,所述综合优势度为支配优势度和邻域解分布密度的加权和。
14.进一步地,所述启发式操作包括随机交换、相邻交换、前置操作、后置操作、逆序操作和截取操作中的一种或多种。
15.进一步地,对于单目标优化调度,基于超启发式遗传算法的智能调度机制的优化目标为最大生产完工时间、总加工流程时间或最大延误时间;
16.或者,对于多目标优化调度,基于超启发式遗传算法的智能调度机制的优化目标为最大生产完工时间、总加工流程时间和最大延误时间。
17.进一步地,所述产品的加工信息包括:产品在每个设备上进行的加工工序和加工时长。
18.进一步地,对于多目标优化调度,根据加权目标函数值从调度解集中选出最优解;
19.所述加权目标函数值为:
[0020][0021]
其中,ωg为第g个目标fg的权重。
[0022]
本发明的第二个方面提供基于超启发式遗传算法的生产过程智能调度系统,其包括:
[0023]
加工计划优化模块,其被配置为:获取待加工产品的数量以及每件产品的加工信息,通过基于超启发式遗传算法的智能调度机制初始化并优化产品加工计划的调度解集;
[0024]
最优解选择模块,其被配置为:从调度解集中选出最优解,以将最优解所表示的加工计划投入产品的生产过程;
[0025]
其中,基于超启发式遗传算法的智能调度机制将一条启发式染色体与一条生产次序染色体组成一个调度解,一条启发式染色体由若干个启发式操作组成,一条生产次序染色体为所有待加工产品编码的全排列;且基于超启发式遗传算法的智能调度机制进行调度解更新的方式包括启发式染色体之间的交叉和变异操作、以及生产次序染色体根据启发式染色体中的启发式操作进行的遗传操作。
[0026]
本发明的第三个方面提供一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现如上述所述的基于超启发式遗传算法的生产过程智能调度方法中的步骤。
[0027]
本发明的第四个方面提供一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现如上述所述的基于超启发式遗传算法的生产过程智能调度方法中的步骤。
[0028]
与现有技术相比,本发明的有益效果是:
[0029]
本发明提供了基于超启发式遗传算法的生产过程智能调度方法,其采用了通过在高级启发式染色体中编码并优化低级启发式操作机制,再以低级启发式操作来演化调度解的方式,实现了对遗传操作机制的自学习进化,显著提高了调度方法对调度结果的演化能力,增强了调度性能的鲁棒性,不仅表现出更具显著优势的调度优化性能,还保证了此方法在不同调度场景下对不同的优化目标具有广泛适用性。
[0030]
本发明提供了基于超启发式遗传算法的生产过程智能调度方法,其采用加权求和的方式,综合考虑个体在种群中的支配优势度和邻域解分布密度,基于个体综合优势度选择优势种群,与基于非支配排序策略选择精英种群的方法相比,能够综合评价个体的优势程度,并进一步维持了后代种群的特征多样性。
附图说明
[0031]
构成本发明的一部分的说明书附图用来提供对本发明的进一步理解,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。
[0032]
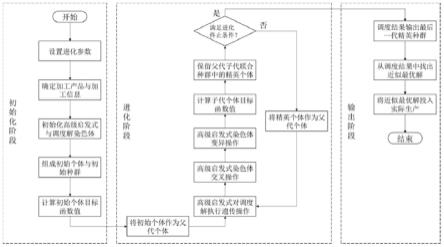
图1是本发明实施例一的基于超启发式遗传算法的生产过程智能调度方法流程图;
[0033]
图2是本发明实施例一的高级启发式、低级启发式操作以及调度问题域之间的关系图;
[0034]
图3是本发明实施例一的单一产品零等待间歇生产过程实例的甘特图;
[0035]
图4是本发明实施例一的多批次产品零等待间歇生产过程实例的甘特图。
具体实施方式
[0036]
下面结合附图与实施例对本发明作进一步说明。
[0037]
应该指出,以下详细说明都是例示性的,旨在对本发明提供进一步的说明。除非另有指明,本文使用的所有技术和科学术语具有与本发明所属技术领域的普通技术人员通常理解的相同含义。
[0038]
实施例一
[0039]
本实施例提供了基于超启发式遗传算法的生产过程智能调度方法,如图1所示,具体包括如下步骤:
[0040]
步骤1、确定所需加工产品的数量以及每件产品的加工信息,明确对零等待间歇生产过程调度优化所依据的目标函数;
[0041]
步骤2、对所有加工产品进行编号,并通过基于超启发式遗传(gahh)算法的智能调度机制初始化并优化决策产品加工计划的调度解集,当满足进化终止条件时结束优化;
[0042]
步骤3、从步骤2最终得到的解集中选出符合实际加工需要的近似最优解,将该调度解所表示的加工计划投入实际生产加工过程。
[0043]
步骤1中所需加工产品的数量以及每件产品的加工信息如下:
[0044]
将n件产品投入由m台设备组成的生产车间中进行加工,每件产品依照相同的次序在经历从第一台设备到第m台设备的加工后,方能完成加工任务。n件产品组成产品集合j={j1,j2,...,jn},m台设备组成设备集合m={m1,m2,...,mm}。产品ji在设备mk上进行的加工工
序为o
ik
,其加工时长为p
ik
。在零等待间歇生产过程中,每件产品从第二道工序开始,每道工序o
ik
的开始时刻为其上一工序o
i(k-1)
的完成时刻。如图3所示,以一件包含3道工序的产品的加工工艺流程为例,表现了该产品零等待间歇生产过程的全流程。
[0045]
步骤1中零等待间歇生产过程调度优化所依据的目标函数描述如下:
[0046]
零等待间歇生产过程的调度优化目标涉及最大生产完工时间、总加工流程时间以及最大延误时间。三个调度优化目标的目标函数表示如下:
[0047]
(1)最大生产完工时间是指完成所有产品加工所需要的时长。以最大生产完工时间作为优化目标是为了保证调度解将使得生产过程花费尽可能少的时间。最大生产完工时间的目标函数可表示为:
[0048]
f1=t=max{ci|i=1,2,...,n}
ꢀꢀ
(1)
[0049]
其中,ci表示从零时刻开始直至产品i加工结束所经历的时长。
[0050]
(2)总加工流程时间是指所有产品的生产完工时间的总和。该优化目标的意义在于,使得调度解能在缩短最大生产完工时间的同时,也尽量减小每件产品的加工时间,以达到降低总的能耗与运行成本的目的。总加工流程时间的目标函数可表示为:
[0051][0052]
(3)最大延误时间用于表示延误加工与交货时间最严重的产品的延误时长。通过优化该目标,调度解应缩短加工产品完工与交货的延误时长,尽量保障所有产品都能够按时完工并且交货。最大延误时间的目标函数为:
[0053]
f3=mlt=max{0,(c
i-di)|i=1,2,...,n}
ꢀꢀ
(3)
[0054]
其中,di表示产品i的最晚交货期。
[0055]
调度的目标优化方向包括单目标优化和多目标优化,其中:
[0056]
(1)单目标优化仅对单个目标进行调度优化,优化的目的是通过智能算法找到一个能够尽可能使得该目标的函数值接近最佳值的近似最优解。以对最大生产完工时间的调度优化为例,优化方向可表示为:
[0057]
f=min f1ꢀꢀ
(4)
[0058]
(2)多目标优化对多个或全部目标进行调度优化。由于各个优化目标并不是相互独立的,对其中一个目标进行优化会影响到其他目标的优化结果,目标之间往往具有相互制约的作用。为达到对多目标协同优化的目的,需要计算每个调度解的目标函数,确定其在多维目标空间中的位置,并测算个体的综合优势度,从而判断个体的优劣。通过进化过程,使得后代种群中的个体综合优势度整体上朝着相对理想点趋近,从而实现对调度解的优化。在结束进化调度之后,将最终代优势解集作为近似最优解集。当对最大生产完工时间、总加工流程时间、最大延误时间这三个目标同时进行优化时,优化方向可表示为:
[0059]
f=(min f1,min f2,min f3)
ꢀꢀ
(5)
[0060]
以对n-乙酰氨基葡萄糖零等待间歇生产过程的调度为例:
[0061]
表1、产品加工信息表
[0062]
批次j1j2j3j4j5j6j7j8j9j
10
种子生产1113169111215141712发酵生产57465448534941525448
酸化2424323431陶瓷膜5763675422絮凝剂1314342312板框2648143172ro膜5281746326中压膜5737564835mvr浓缩6201234186231517水解10149111012131368板框、配料122042314821231517浓缩结晶20132624162320171922抽滤851210981213511双锥、筛分4763564786
[0063]
表1记录了产品10个批次的加工信息(单位:小时),调度任务是对这10个批次的产品进行零等待间歇生产过程优化调度。
[0064]
将每个批次的加工产品视为一个整体,把这10件产品投入由14道工序的生产设备组成的生产车间中进行加工,每件产品依照表1中的工艺步骤,从第一道工序种子生产开始,直到双锥、筛分工艺结束后,方能完成加工任务。10件产品组成产品集合j={j1,j2,...,j
10
},14道工序的生产设备组成设备集合m={m1,m2,...,m
14
}。产品ji在设备mk上进行的加工工序为o
ik
,其加工时长为p
ik
。例如,j1在设备m1上进行的工序o
11
为种子生产,其加工时长p
11
为11。在零等待间歇生产过程中,每件产品从第二道工序开始,每道工序o
ik
的开始时刻为其上一工序o
i(k-1)
的完成时刻。例如,若o
11
从零时刻开始加工,经历11小时后完成该工序的加工。紧接着,o
12
在第11个小时,o
11
加工结束并把物料传送到m2的时候即刻开始加工。
[0065]
若n-乙酰氨基葡萄糖零等待间歇生产过程的调度优化为单目标优化,涉及的目标为最大生产完工时间。本实例将通过基于超启发式遗传(gahh)算法的智能调度机制安排合理的生产计划,保证10个批次的产品能够在近似最短的时间内全部完工。
[0066]
若n-乙酰氨基葡萄糖零等待间歇生产过程的调度优化为多目标优化,n-乙酰氨基葡萄糖的零等待间歇生产过程的多目标调度优化涉及最大生产完工时间、总加工流程时间以及最大延误时间三个目标。在本实施例中,每件产品的最晚交货期设置为该产品所有14道工序的加工时长总和的1.5倍。
[0067]
步骤2中基于gahh算法的智能调度机制是一种超启发式遗传算法机制。该机制通过直接进化高级启发式,再由高级启发式中的低级启发式操作来进化调度解,并通过测算种群中个体综合优势度的方式实现对调度目标的优化,其具体优化过程包括:
[0068]
步骤(1)设置进化参数,包括最大迭代次数ite
max
、调度种群规模pop
size
、高级启发式染色体长度lh、高级启发式交叉概率p
hc
、高级启发式变异概率p
hm
、低级启发式对生产次序染色体的操作概率p
l
。
[0069]
在本实施例中,若是n-乙酰氨基葡萄糖零等待间歇生产过程的单目标优化调度,最大迭代次数ite
max
为300,调度种群规模pop
size
为50,高级启发式染色体长度lh为6,高级启发式交叉概率p
hc
为0.8,高级启发式变异概率p
hm
为0.6,低级启发式对生产次序染色体的操作概率p
l
为0.8,综合优势度测算权重α为0.6。
[0070]
在本实施例中,若是n-乙酰氨基葡萄糖零等待间歇生产过程的多目标优化调度,最大迭代次数ite
max
为500,调度种群规模pop
size
为100,高级启发式染色体长度lh为6,高级启发式交叉概率p
hc
为0.8,高级启发式变异概率p
hm
为0.6,低级启发式对生产次序染色体的操作概率p
l
为0.8,综合优势度测算权重α为0.6。
[0071]
步骤(2)根据调度种群规模的设定,随机生成pop
size
个初始化调度解。如图2所示,每个调度解由一条启发式染色体和一条生产次序染色体组成。每条高级启发式染色体由lh个低级启发式操作组成,表2所列的操作为高级启发式染色体中能够包含的所有启发式操作。每条高级启发式染色体中的lh个低级启发式操作只能从表2中选择。在同一条高级启发式染色体中,任何操作均可以重复出现。生产次序染色体为所有待加工产品编码的全排列。初始化解集中,随机生成pop
size
组产品编码的全排列,并分别与一条高级启发式染色体组成一个初始化调度解。
[0072]
表2、启发式操作表
[0073][0074][0075]
在本实施例中,若是n-乙酰氨基葡萄糖零等待间歇生产过程的单目标优化调度,根据调度种群规模的设定,随机生成50个初始化调度解。每个调度解由一条启发式染色体和一条生产次序染色体组成。每条高级启发式染色体中的6个低级启发式操作由表2中的操作llh_1-llh_6组成。在同一条高级启发式染色体中,任何操作均可以重复出现。例如,一条合法的高级启发式染色体可以是:
[0076]
chro
high
=[llh_3,llh_1,llh_3,llh_6,llh_5,llh_1]
ꢀꢀ
(6)
[0077]
生产次序染色体为所有加工产品编码的全排列。在生产次序染色体中,每个产品
的编号只能出现一次。例如,一条对10件产品编码合法的生产次序染色体可以表示为:
[0078]
chro
low
=[5,9,10,6,1,8,3,7,2,4]
ꢀꢀ
(7)
[0079]
初始化解集中,随机生成50条合法的高级启发式染色体与50条合法的生产次序染色体,并分别将一条高级启发式染色体与一条生产次序染色体组成一个初始化调度解。
[0080]
在本实施例中,若是n-乙酰氨基葡萄糖零等待间歇生产过程的多目标优化调度,根据调度种群规模的设定,随机生成100个初始化调度解。初始化解集中,随机生成100条合法的高级启发式染色体与100条合法的生产次序染色体,并分别将一条高级启发式染色体与一条生产次序染色体组成一个初始化调度解。
[0081]
步骤(3)调度解根据高级启发式染色体中的启发式操作编码,对生产次序染色体进行遗传操作。在每一个调度解中,按照高级启发式染色体的启发式操作编码的排序,依次进行。首先生成一个在[0,1]区间的随机数,如果该随机数小于或等于p
l
,则依照高级启发式染色体中第一个操作编码在表2中对应的操作方式,对生产次序染色体执行相应的遗传操作;否则,不对生产次序染色体执行该项操作。同样地,后续启发式操作均按照该方式依次进行。直到将当前高级启发式染色体中的lh项操作全部经历一遍之后,结束当前调度解对生产次序染色体的遗传操作。种群中pop
size
个调度解均按照上述方式执行生产次序染色体的遗传操作。
[0082]
以通过式(6)表示的高级启发式染色体chro
high
对式(7)表示的生产次序染色体chro
low
进行操作为例。chro
high
中的第一项操作为llh_3,即前置操作:从生产次序染色体中随机选择两个编码,将后一个编码放到前一个编码之前。首先生成一个在[0,1]区间的随机数,如果该随机数小于或等于p
l
,则依照相应的操作方式,对生产次序染色体执行llh_3操作。例如,随机生成的数为0.5,随机选中的产品编码为j2与j6的编码,那么,执行完llh_3操作后,式(7)所示chro
low
染色体变为:
[0083]
chro
low
'=[5,9,10,2,6,1,8,3,7,4]
ꢀꢀ
(8)
[0084]
但如果随机生成的数大于0.8,则不对生产次序染色体执行当前的llh_3操作。同样地,后续启发式操作均按照该方式依次进行。直到将当前高级启发式染色体中的6项操作全部按照如上的形式进行一遍之后,结束当前调度解对生产次序染色体的遗传操作。种群中其余调度解均按照上述方式执行生产次序染色体的遗传操作。
[0085]
步骤(4)高级染色体的交叉操作。将pop
size
个调度解随机两两配对,生成pop
size
/2组相应的交叉组合,依次在每一组调度解中,对高级启发式染色体进行交叉操作。首先生成一个位于[0,1]区间的随机数,如果该随机数小于或等于p
hc
,则在当前的交叉组合中的一条高级启发式染色体中随机选择一段片段,位置与长度随机确定,并与组合中的另一条高级启发式染色体中相应位置的片段进行交换;否则,不对当前组合执行交叉操作。对其余的交叉组合均采取相同的方式进行交叉操作。
[0086]
例如,有一对高级启发式染色体如式(9)所示:
[0087][0088]
若对其进行交叉操作,首先生成一个位于[0,1]区间的随机数,如果该随机数小于或等于p
hc
,则在当前的交叉组合中的一条高级启发式染色体中随机选择一段片段,位置与
长度随机确定,并与组合中的另一条高级启发式染色体中相应位置的片段进行交换。若生成的随机数为0.3,且在chro
high1
中选中的交叉片段的起始位置为染色体中的第2项元素,长度为3,那么,chro
high1
与chro
high2
交叉后的染色体如式(10)所示:
[0089][0090]
若随机数大于0.8,则不对该交叉组合执行此操作。对其余组的交叉组合均采取相同的流程进行交叉操作。
[0091]
步骤(5)高级染色体的变异操作。对种群中pop
size
个调度解的高级启发式染色体依次进行变异操作。生成一个位于[0,1]区间的随机数,如果该随机数小于或等于p
hm
,则在当前调度解的高级启发式染色体中随机选择一个操作编码,用表1中其余操作编码中的任意一个替换;否则,不对当前高级启发式染色体执行变异操作。对其余调度解的高级启发式染色体均采用同样的方式执行变异操作。
[0092]
例如,要对式(10)中的chro
high1
'执行变异操作,生成了随机数0.6,随机选中的变异编码为染色体中的第5项元素,随机生成的替换编码为llh_2,则变异之后的染色体如式(11)所示:
[0093]
chro
high1”=[llh_3,llh_5,llh_1,llh_5,llh_2,llh_1]
ꢀꢀ
(11)
[0094]
若随机数大于0.6,不对当前高级启发式染色体执行变异操作。对其余的调度解的高级启发式染色体均采用同样的步骤执行变异操作。
[0095]
步骤(6)生成父代与子代的联合种群。将依次进行过生产次序染色体遗传操作、高级染色体交叉操作、高级染色体变异操作之后的调度解作为子代个体。将原来的个体作为其父代个体。pop
size
个父代个体与pop
size
个子代个体组成一个规模为的联合种群。
[0096]
步骤(7)目标函数值计算。依据每个调度解中的生产次序,按照零等待间歇生产过程的约束条件,生成相应的加工方案,并计算出相应的目标函数值。
[0097]
在本实施例中,若是n-乙酰氨基葡萄糖零等待间歇生产过程的单目标优化调度,则根据目标函数f1计算出相应的最大生产完工时间。
[0098]
在本实施例中,若是n-乙酰氨基葡萄糖零等待间歇生产过程的多目标优化调度,则根据目标函数f1、f2、f3计算出相应的最大生产完工时间、总加工流程时间、最大延误时间三个目标的结果。
[0099]
步骤(8)基于个体综合优势度测算法选择优势解。
[0100]
如果是单目标优化调度,则通过个体综合优势度测算法,计算联合种群中各个个体在该目标维度中的综合优势度,选出优势度最高的前pop
size
个调度解作为优势个体,组成优势解集。
[0101]
对于n-乙酰氨基葡萄糖零等待间歇生产过程的单目标优化调度,将父代子代联合种群中100个调度解的最大生产完工时间从小到大排序,计算联合种群中目标值优于每个调度解的个体数,并换算成归一化值。然后,计算每个个体在该目标维度上邻域解分布密度。最后加权计算出个体综合优势度,计算方式如式(12)所示,并根据结果对种群中的个体重新排序,选出综合优势度最佳的前50个个体。
[0102]
wd
x
=α
·
gn
x
/(pop
size
·
2)+(1-α)
·
cd
x
ꢀꢀ
(12)
[0103]
其中,wd
x
表示调度解x的综合优势度,gn
x
为联合种群中目标值优于调度解x的解的数量,cd
x
为个体x的邻域解分布密度,α为权重系数。cd
x
的计算方式如下:
[0104]
cd
x
=lcd
x
+rcd
x
ꢀꢀ
(13)
[0105][0106][0107]
其中,lcd
x
和rcd
x
分别表示调度解x的左、右邻近程度;ly
x
和ry
x
分别表示调度解x与左右相邻解的距离;y
max
分别表示联合种群中相邻解之间的距离的最大值。
[0108]
如果是多目标优化调度,则采用个体综合优势度测算法,测算并选出在多目标状态空间中综合优势度最高的前100个调度解作为优势解,组成优势解集。一个调度解的个体综合优势度表示为在当前联合种群中该个体的支配优势度和邻域解分布密度的加权和,计算方式如下:
[0109]
wd
x
=α
·
nd
x
+(1-α)
·
cd
x
ꢀꢀ
(16)
[0110]
其中,wd
x
表示个体x的综合优势度,nd
x
为个体x的支配优势度,cd
x
为个体x的邻域解分布密度,α为权重系数。支配优势度是指个体在联合种群中的非支配水平的归一化结果。支配优势度的计算方式如下:
[0111][0112]
其中,np
x
为调度解x的非支配水平,即联合种群中支配x的解的个数,np
max
为联合种群中受支配程度最高的解的非支配水平。邻域解分布密度表示了在联合种群的分布空间中该个体与各个目标维度上的相邻个体邻近程度的综合水平。邻域解分布密度的计算方式如下:
[0113][0114][0115][0116][0117]
式(18)中,n是目标的个数;表示调度解x在目标fg维度上与相邻个体的邻近程
度。式(19)中,和分别表示调度解x在目标fg维度上的左、右邻近程度。式(20)和式(21)中,和分别表示调度解x在目标fg维度上与左右相邻解的距离;和分别表示种群中目标fg的最大值和最小值。综合优势度测算结果越小的调度解,其优势排序越靠前。最后,按照排序结果,选出排序靠前的100个个体作为优势个体,组成这一代的优势解集。
[0118]
步骤(9)如果迭代次数尚未达到最大迭代次数ite
max
,则返回步骤(3),以当前优势解集作为父代种群进行下一轮遗传操作;否则,结束进化过程。
[0119]
步骤(10)输出最后一代优势解集中的生产次序染色体,作为调度结果。
[0120]
对于n-乙酰氨基葡萄糖零等待间歇生产过程的多目标优化调度,将本发明中的方法(gahh)与nsga-ii算法(来源于2002年在ieee transactions on evolutionary computation上发表的论文a fast and elitist multiobjective genetic algorithm:nsga-ii)与pso算法(来源于2015年在mathematical problems in engineering上发表的论文a comprehensive survey on particle swarm optimization algorithm and its applications)进行对比。通过测试并比较不同算法在相同的多目标调度场景下所得到的非支配解集的性能,以此来分析本发明在实现零等待间歇生产过程调度优化上的优劣。
[0121]
在此通过覆盖集测度,即c测度(来源于2000年在evolutionary computation上发表的论文comparison of multiobjective evolutionary algorithms:empirical results,来将本发明的方法为本实施例得出的pareto前沿解集分别与两种对比方法得到的pareto前沿解集进行比较分析。经过10次独立重复实验之后,得到的c测度结果的平均值如表3所示。
[0122]
表3、c测度结果
[0123][0124]
测试结果表明,本发明中所采用的基于gahh算法的智能调度机制得到的调度解集具有比对比算法得到的解集更显著的优势水平。
[0125]
步骤3中选择近似最优解的方式描述如下:
[0126]
当调度优化为单目标优化时,从最后一代优势解集中选出目标函数值最优的调度解作为近似最优解。依照其决策出的生产次序排列,在遵守零等待间歇生产过程的约束条件的前提下,生成相应的加工方案,投入实际生产过程。
[0127]
对于n-乙酰氨基葡萄糖零等待间歇生产过程的单目标优化调度,调度结果应选择最后一代优势解集中目标函数值最佳的调度解,即最大生产完工时间最短的方案。本实例通过基于超启发式遗传(gahh)算法的智能调度机制为10个批次的n-乙酰氨基葡萄糖零等待间歇生产过程提供的最小化最大生产完工时间的近似最优方案如式(22)所示:
[0128]
chro
low_best
=[4,3,9,7,6,8,5,2,10,1]
ꢀꢀ
(22)
[0129]
根据此加工次序对10个批次的n-乙酰氨基葡萄糖进行零等待间歇生产,得到的最
大生产完工时间为591小时。该方案明显优于调度员人工设计的如式(23)所示的加工计划方案:
[0130]
chro
low_manual
=[8,6,1,5,2,3,9,4,10,7]
ꢀꢀ
(23)
[0131]
此方案的最大生产完工时间为615个小时。
[0132]
若调度优化为多目标优化,则需根据实际需要赋予每个优化目标相应的权重,并计算出加权目标函数值,将其结果最优的调度解作为近似最优解,投入实际生产过程。加权目标依照如下公式计算:
[0133][0134][0135]
其中,fw为加权目标函数,ωg为第g个目标fg的权重。
[0136]
各个目标的权重可以人为地根据实际需要主观给定。本实施例先通过基于层次分析法的主观决策分析得到主观权重,再通过基于熵权法的客观决策分析得出客观权重,最后采用存在于博弈论中的nash均衡模型,基于主观与客观权重求出综合权重:
[0137]
ω=(ω1,ω2,ω3)=(0.329,0.328,0.343)
ꢀꢀ
(26)
[0138]
最后,本实施例为10个批次的n-乙酰氨基葡萄糖零等待间歇生产过程提供的多目标调度优化得出的近似最优方案如式(27)所示:
[0139]
chro
low_best
=[4,7,2,10,6,8,5,3,9,1]
ꢀꢀ
(27)
[0140]
根据此加工次序对10个批次的n-乙酰氨基葡萄糖进行零等待间歇生产,得到的最大生产完工时间为591,总加工流程时间为3706,最大延误时间为369。
[0141]
本实施例以n-乙酰氨基葡萄糖生产过程为例,采用gahh算法为生产过程实施了单目标与多目标调度优化,提供了科学、高效的生产方案。结果表明,本发明基于gahh算法为零等待间歇生产过程提供的调度优化过程具有稳定的性能,其结果具有显著性水平。gahh算法作为一种超启发式寻优机制,能够使得调度优化过程不再过度依赖于调度专家的人工设计,体现了知识自动化的优势特点,使得本发明的方法更具广泛适用性。
[0142]
本技术为零等待间歇生产过程调度问题提供了高效、稳定、具有较好鲁棒性与适用性的优化调度方法。在考虑到元启发式算法的改进往往只针对特定的调度场景与优化目标的局限,以及对专家知识的依赖性,本发明以零等待间歇生产过程为调度场景,采用了通过在高级启发式染色体中编码并优化低级启发式操作机制,再以低级启发式操作来演化调度解的方式,该超启发式进化方式通过知识自动化的理念,实现了对遗传操作机制的自学习进化,显著提高了调度方法对调度结果的演化能力,增强了调度性能的鲁棒性。该方法不仅表现出更具显著优势的调度优化性能,还保证了此方法在不同调度场景下对不同的优化目标具有广泛适用性。
[0143]
此外,本发明改进了传统的基于非支配排序策略选择精英种群的方法,采用加权求和的方式,综合考虑个体在种群中的支配优势度和邻域解分布密度,基于个体综合优势度选择优势种群。本发明中的选择方法与基于非支配排序策略选择精英种群的方法相比,能够综合评价个体的优势程度,并进一步维持了后代种群的特征多样性。
[0144]
实施例二
[0145]
本实施例提供了基于超启发式遗传算法的生产过程智能调度系统,其具体包括:
[0146]
加工计划优化模块,其被配置为:获取待加工产品的数量以及每件产品的加工信息,通过基于超启发式遗传算法的智能调度机制初始化并优化产品加工计划的调度解集;
[0147]
最优解选择模块,其被配置为:从调度解集中选出最优解,以将最优解所表示的加工计划投入产品的生产过程;
[0148]
其中,基于超启发式遗传算法的智能调度机制将一条启发式染色体与一条生产次序染色体组成一个调度解,一条启发式染色体由若干个启发式操作组成,一条生产次序染色体为所有待加工产品编码的全排列;且基于超启发式遗传算法的智能调度机制进行调度解更新的方式包括启发式染色体之间的交叉和变异操作、以及生产次序染色体根据启发式染色体中的启发式操作进行的遗传操作。
[0149]
此处需要说明的是,本实施例中的各个模块与实施例一中的各个步骤一一对应,其具体实施过程相同,此处不再累述。
[0150]
实施例三
[0151]
本实施例提供了一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现如上述实施例一所述的基于超启发式遗传算法的生产过程智能调度方法中的步骤。
[0152]
实施例四
[0153]
本实施例提供了一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现如上述实施例一所述的基于超启发式遗传算法的生产过程智能调度方法中的步骤。
[0154]
本领域内的技术人员应明白,本发明的实施例可提供为方法、系统、或计算机程序产品。因此,本发明可采用硬件实施例、软件实施例、或结合软件和硬件方面的实施例的形式。而且,本发明可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器和光学存储器等)上实施的计算机程序产品的形式。
[0155]
本发明是参照根据本发明实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
[0156]
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
[0157]
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
[0158]
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,是可以通过计算机程序来指令相关的硬件来完成,所述的程序可存储于一计算机可读取存储介质中,该程序在执行时,可包括如上述各方法的实施例的流程。其中,所述的存储介质可为磁碟、光盘、只读存储记忆体(read-only memory,rom)或随机存储记忆体(random accessmemory,ram)等。
[0159]
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1