一种变电站场景点云语义分割方法与流程
1.本发明提供了一种变电站场景点云语义分割方法,属于计算机视觉与模式识别、深度学习及点云语义分割技术领域。
背景技术:
2.随着电网数字化的运行以及人工智能技术的发展,变电站的智能巡检正逐步取代人工模式成为主要的巡检方式。智能巡检过程中,需要对环境进行感知,对场景进行理解能力,从而设计有效的避障方法。3d语义分割作为场景理解的主要环节,指的是给点云中的每个点赋予特定的语义标签,赋予每个点云特定的含义从而准确描述空间中物体的类型,且所赋予的语义标签在真实世界中具有特定意义。
3.变电站场景下的3d点云语义分割的主要挑战为:(1)数据采集不易:变电站场景复杂,非可移动区域较多,数据采集受限;(2)数据标注复杂:3d点云中标注数据集是以点为单位的,标注过程耗时较长;(3)特征提取困难:变电站的3d点云相对稀疏,具有不规则性,而语义分割需要给点云中的每个点赋予特定的语义标签,难度较大。
技术实现要素:
4.本发明为了解决变电站场景复杂、点云数众多、特征提取困难、特征提取过程中会出现忽略局部特征、提取较浅层次的特征,无法准确提取到具有鉴别性的特征,因此分割结果容易出现欠分割或者过分割等问题,提出了一种变电站场景点云语义分割方法。
5.为了解决上述技术问题,本发明采用的技术方案为:一种变电站场景点云语义分割方法,包括如下步骤:
6.步骤1:建立变电站点云语义分割数据集;
7.步骤2:点云数据集标注:采用点云标注工具,将场景下的语义类别分为6类:10kv变电室外墙、变压器、人、围墙、地、消防沙箱;
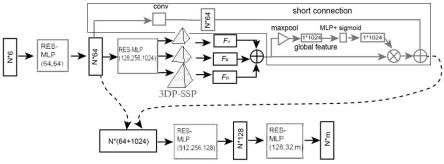
8.步骤3:构建变电站点云语义分割模型:以pointnet为基础,进行模型优化,构建变电站点云语义分割的深度模型seg-pointnet;
9.seg-pointnet模型的网络结构主要由多尺度残差的感知模块res-mlp、3d点云特征金字塔3dp-ssp和注意力机制senet构成;
10.假设点云的采样点个数设置为n,n个点云经过基于残差结构的多尺度感知模块res-mlp进行升维;然后通过三维点云的空间金字塔3dp-ssp模块提取不同尺度的特征向量,之后将全局特征和局部特征进行拼接,拼接的过程中采用senet注意力机制对特征进行加权;最后,将经过拼接的特征复制到n个点中的每个点,再经过基于残差结构的多尺度感知模块res-mlp进行降维,最终得到每个点的语义分割结果;
11.步骤4:模型训练和测试:对构建的seg-pointnet模型进行训练和验证,并将其部署在设备进行点云语义分割。
12.基于残差结构的多尺度感知模块res-mlp包括res-mlp-1、res-mlp-2、res-mlp-3、
res-mlp-4四个残差多层感知器,每个残差多层感知器的深度是原pointnet结构中mlp深度的两倍。
13.所述res-mlp-1、res-mlp-2用于将原始点云数据进行升维操作,得到升维后的特征;
14.其中res-mlp-1将点云的数据维度从n*6进行升维,每个点生成64维的点云特征矩阵,生成n*64维的点云特征矩阵,res-mlp-2将点云的数据维度从64维升到1024维,生成n*1024维的点云特征矩阵。
15.所述res-mlp-3、res-mlp-4用于将经过拼接的特征复制到n个点中的每个点云数据进行降维操作;
16.其中res-mlp-3对n*1088维度的组合特征进行降维,维度降为n*128,res-mlp-4继续对n*128维的特征进行降维,到m个分割的类别中,输出最终的语义分割结果。
17.所述res-mlp-1,包含两个残差块,每个残差块包含两个卷积层,将点云的数据维度进行升维,从n*6升维到n*64。
18.所述res-mlp-2,包含三个残差块,每个残差块包括两个卷积层,将点云的数据进行升维,从n*64升维到n*1024。
19.所述res-mlp-3,包含三个残差块,每个残差块包括两个卷积层,将全局特征和局部特征拼接为1088维特征进行降维,降维到128维。
20.所述res-mlp-4,包含两个残差块,每个残差块包括两个卷积层,将经过降维的128维特征映射到m个语义标签。
21.所述3dp-ssp采用多窗口的池化方式,得到多维度的局部特征,所述3dp-ssp用如下公式表示:
[0022][0023]
上式中,wn为金字塔池化的窗口尺寸,f代表mlp提取的特征,g代表最大池化操作,con代表多尺度特征的合并。
[0024]
本发明相对于现有技术具备的有益效果为:本发明提供的变电站场景点云语义分割方法针对变电站复杂场景下激光雷达点云数据的语义分割任务,提出了一种基于多尺度残差结构和3d点云特征金字塔(3dp-ssp)的改进的pointnet模型,命名为seg-pointnet模型。此模型以pointnet为基础,引入多尺度残差结构(res),提出基于多尺度残差的感知模块(res-mlp),充分挖掘不同尺度的特征,提高其复杂特征的表征能力;在此基础上,引入3d点云特征金字塔模块(3dp-ssp),表征变电站场景的深度语义特征。将提出的seg-pointnet模型在斯坦福大学构建的公共数据集s3dis上进行训练和测试,训练之后的模型在自建的变电站点云数据集(scp-dataset)上进行验证,结果表明,本发明提出的seg-pointnet模型有效地提高了点云的分割精度,较好的适用于变电站场景,为复杂变电站环境下的场景建模应用提供技术支撑。
附图说明
[0025]
下面结合附图对本发明做进一步说明:
[0026]
图1为本发明提出的seg-pointnet模型的网络结构图;
[0027]
图2为本发明提出的res-mlp模块的结构图;
[0028]
图3为本发明提出的3dp-ssp模块的结构图;
[0029]
图4为采用本发明的seg-pointnet模型与传统pointnet模型在s3dis数据集上的语义分割结果对比图。
具体实施方式
[0030]
如图1至图4所示,本发明研究点云语义分割方法,以pointnet网络模型为基础,通过对模型的优化,实现变电站点云的3d语义分割,提出了一种基于seg-pointnet的变电站点云语义分割方法,核心步骤如下:
[0031]
步骤1:建立变电站点云语义分割数据集。本发明所构建的变电站点云数据集采用ouster os-1-64线激光雷达采集点云数据,采集模式1024*10,即每根线每秒十圈,每圈1024个点;共64根线,即转一圈64*1024个点。构建的变电站点云数据集命名为(substation cloud point data set,scp dataset),scp dataset规模为320。
[0032]
步骤2:点云数据集标注。数据标注采用semantic-segmentation-editor点云标注工具,根据本发明所要解决问题,将场景下的语义类别分为6类:10kv变电室外墙,变压器,人,围墙,地,消防沙箱。
[0033]
步骤3:构建变电站点云语义分割模型——seg-pointnet模型。以pointnet思想为基础,进行模型优化,构建适合变电站点云语义分割的深度模型seg-pointnet。
[0034]
pointnet在进行语义分割的过程中因其忽略局部特征,提取的多为较浅层次的特征,对所有的特征赋予同样的重要程度,因此出现欠分割或过分割等问题。针对以上问题,本发明提出了一种seg-pointnet模型,对复杂的变电站场景进行语义分割。
[0035]
seg-pointnet模型的网络结构如图1所示:主要由多尺度残差的感知模块(res-mlp)、3d点云特征金字塔(3dp-ssp)和注意力机制senet构成。
[0036]
假设点云的采样点个数设置为n,输入维度为6。
[0037]
首先,经过本发明提出的基于残差的多尺度感知模块(res-mlp)进行特征提取,包括4个不同的res-mlp结构(res-mlp-1到res-mlp-4)。经过res-mlp-1升维到n*64维的特征,再经过res-mlp-2结构的变换,得到n*1024维的输出特征。通过提出的三维点云的空间金字塔3dp-ssp模块提取不同尺度的特征向量,之后全局特征和局部特征进行拼接,拼接的过程中采用senet注意力机制对特征进行加权。最后,经过拼接的特征复制到n个点中的每个点,经过res-mlp-3降维为128维的特征,再经过res-mlp-4降维,得到每个点的语义分割结果。
[0038]
下面对本发明提出的基于残差的多尺度感知(res-mlp)模块进行进一步说明。
[0039]
基于残差网络的思想,本发明设计了基于残差结构的多尺度感知模块(res-mlp),res-mlp意思是残差多层感知器,包括res-mlp-1到res-mlp-4,每个res-mlp的深度是原pointnet结构中mlp深度的两倍,res-mlp-1到res-mlp-4的结构如图2所示,res-mlp-1和res-mlp-2进行点云数据的升维操作,res-mlp-3和res-mlp-4进行点云数据的降维操作。
[0040]
res-mlp-1结构将点云的数据维度从n*6进行升维,每个点生成64维的点云特征矩阵,生成n*64维的点云特征矩阵。res-mlp-2将点云的数据维度从64维升到1024维,生成n*1024维的点云特征矩阵。根据seg-pointnet模型结构,将全局特征和金字塔提取的局部特征进行拼接,即图1中n*(64+1024)部分,拼接成n*1088维的组合特征。resmlp-3模块对n*1088维度的组合特征进行降维,维度降为n*128。resmlp-4结构继续对n*128维的特征进行
降维,到m个分割的类别中,输出最终的语义分割结果。
[0041]
图2(a)所示为res-mlp-1,包含两个残差块,每个残差块包含两个卷积层。将点云的数据维度进行升维,从n*6升维到n*64,其深度为原始对应位置mlp深度的两倍。与原始结构中的mlp相比,res-mlp-1可获得更多的点云特征。
[0042]
图2(b)所示为res-mlp-2,包含三个残差块,每个残差块包括两个卷积层。其功能为将点云的数据进行升维,从n*64升维到n*1024,其深度为原始对应位置mlp深度的两倍,深度比res-mlp-1更深,因之后的最大池化会损失较多的特征,该操作必须较大程度提升特征的维度,获得丰富的特征信息。
[0043]
图2(c)所示为res-mlp-3,同理包含三个残差块,每个残差块包括两个卷积层。将全局特征和局部特征拼接为的1088维特征进行降维,降维到128维。
[0044]
图2(d)所示为res-mlp-4,包含两个残差块,每个残差块包括两个卷积层。其功能为经过降维的128维特征映射到m个语义标签。同理,此处的网络结构也是原结构中的mlp层的两倍。
[0045]
上述网络结构的构建原理为,如果在输入和输出之间有残差连接,神经网络将更容易训练,并且不容易发生梯度爆炸和梯度消失。基于此观点,利用残差块来深化pointnet的mlp,深化后的网络深度语义特征提取能力会变得更强,因此网络性能会更好。
[0046]
以resmlp-2的体系结构为例,分析网络的整体性能,当残差块的堆叠层全部设置为0时,残差块的输出也为0。此时,res-mlp-2成为mlp,变为标准pointnet中的浅层神经网络。
[0047]
在整个网络中,如果所有的残差块的输出全部为零时,深层网络转化为浅层网络,因此整个网络灵活度比较高。在训练过程的初始阶段,所有深度网络的残差块都参与训练,深度网络会获得丰富且准确的特征,当网络接近稳定时,逐步将残差块的权重设置为0,网络逐步转换为浅层网络。
[0048]
下面对本发明提出的三维点云的空间金字塔(3dp-ssp)模块进行进一步说明。
[0049]
pointnet模型经过池化得出全局特征,但模型缺少对局部特征的提取,而局部特征的提取对于整个网络的性能起着重要作用,受特征金字塔思路的影响,本发明设计了一种适用于三维点云的空间金字塔结构3dp-ssp,可得到任意维度、兼顾全局信息和局部信息的特征。
[0050]
如图3所示,3dp-ssp采用多窗口的池化方式,得到多维度的局部特征。黑色条表示点云的dim维信息,金字塔分别用不同大小的圆锥表示,池化窗口大小分别为每个池化窗口的池化步长等于池化窗口的大小,窗口得到的特征为w1*dim,窗口得到的特征为w2*dim,窗口得到的特征为wn*dim。3dp-ssp聚合不同大小的池化特征,得到(w1+w2+
…
wn)*dim维特征。经过本发明提出的3dp-ssp模块得到的特征既保留全局特征,也包含不同尺度的局部特征。
[0051]
3dp-ssp可用如公式(1)表示:
[0052][0053]
公示(1)中,wn为金字塔池化的窗口尺寸,f代表mlp提取的特征,g代表最大池化操
作,con代表多尺度特征的合并,g()表示整个特征金字塔处理的过程,xn表示特征信号量。
[0054]
(3)senet注意力机制
[0055]
senet是由自动驾驶公司momenta提出的用于图像识别的卷积结构,又称为压缩和激励模块。本发明将senet模块融入模型的目标是通过显式建模其卷积特征通道之间的依赖性来提高生成特征的质量。具体的原理为提出一种机制对特征进行压缩,压缩后的特征进行加权处理,得到新的鉴别能力强的特征。senet结构使用全局信息来突出强调重要的信息特征,并抑制非重要的特征。本发明采用senet作为网络的注意力模块,加入注意力的过程如图1中黑线框柱部分所示,由于特征的维度不同,在短连接中使用卷积来匹配维度,此短连接的作用是为了防止当senet模块的权重为0时特征消失。
[0056]
步骤4:模型训练和测试。基于本发明构建的seg-pointnet模型进行训练和验证,并将其部署在移动端嵌入式设备进行点云语义分割。
[0057]
首先,在斯坦福大学构建的s3dis数据集(6个区域,271个房间)上进行训练,验证提出算法的可行性和有效性,s3dis数据集场景中的每个点进行过语义标注,s3dis数据集按照建筑区域划分为6个区域area1、area2、area3、area4、area5、area6,标注类别分别有桌子、椅子、地板、墙壁、天花板等13个类别。每个点由(x,y,z,r,g,b)六维向量表示,x,y,z为点云的位置通道,rgb为颜色通道。采用交叉验证的方法进行训练与测试,交叉验证具体方法为,按照顺序分别将5个区域设为训练集,另外1个为测试集。
[0058]
为了验证本发明提出算法的有效性,将其与pointnet在s3dis数据集上进行了训练,图4为和seg-pointnet和pointnet的各个语义类别下分割结果,分别为会议室,办公室,走廊等的分割结果的对比,其中天花板,地板,墙,桌子,椅子,书架等分割的较为准确。从图4效果图可以看出,本发明提出的seg-pointnet网络在语义分割上的表现效果优于pointnet,对于各个部件的分割结果更加清晰。
[0059]
关于本发明具体结构需要说明的是,本发明采用的各部件模块相互之间的连接关系是确定的、可实现的,除实施例中特殊说明的以外,其特定的连接关系可以带来相应的技术效果,并基于不依赖相应软件程序执行的前提下,解决本发明提出的技术问题,本发明中出现的部件、模块、具体元器件的型号、相互间连接方式以及,由上述技术特征带来的常规使用方法、可预期技术效果,除具体说明的以外,均属于本领域技术人员在申请日前可以获取到的专利、期刊论文、技术手册、技术词典、教科书中已公开内容,或属于本领域常规技术、公知常识等现有技术,无需赘述,使得本案提供的技术方案是清楚、完整、可实现的,并能根据该技术手段重现或获得相应的实体产品。
[0060]
最后应说明的是:以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1