基于知识更新和知识整合的终身学习行人再识别方法
1.本发明涉及一种面向终身学习的行人再识别方法,属于深度学习、计算机视觉领域。
背景技术:
2.深度学习已经被广泛运用到人工智能应用,并深度赋能计算机视觉等领域。随着监控安防、智慧城市、无人驾驶等方向的日益发展和成熟,行人再识别逐渐成为一项关键技术。行人再识别旨在从不同相机捕获到的行人队列中找出相同身份的行人。行人图片中可能存在较大的扰动(遮挡,姿态变化,相机视角等)是行人再识别任务的主要挑战。
3.当前深度学习主导下的行人再识别任务在训练过程中遵循训练集独立同分布的假设,然而出于现实应用的需求和数据集隐私的保护,面向终身学习的行人再识别克服了原有设定的局限,能可持续地从不同分布的数据集中获得知识,最终学习到具有抗遗忘能力和强泛化能力的行人再识别模型。
4.评价终身学习模型的学习能力,一般分为两个角度:正向迁移和反向迁移。现有的终身学习方法使用蒸馏、重演和参数正则化等技术减少负的反向迁移,即避免模型的灾难性遗忘。这些方法存在以下缺陷:1)保持了模型的稳定性(stability),但是降低了模型的可塑性(plasticity),即损害了部分新任务的性能。2)只考虑了反向迁移,缺乏对正向迁移的思考。
技术实现要素:
5.本发明要解决的技术问题是:为了实现正向迁移和反向迁移,目前为止,终身学习行人再识别技术存在的主要问题为:1)分布不匹配:逐步增加的任务数据之间存在着天然的分布差异,而现有的方法在不同任务之间采用直接蒸馏的方式,忽略了这种分布差异,进而影响了前向迁移的能力,降低了模型的可塑性(plasticity);2)表征能力不匹配:不同时刻输入的数据集,本身具有不同的规模,现有的方法将以往的模型蒸馏到当前模型,可能给出具有偏向性(bias)的监督信号,从而影响模型的泛化性。
6.为了解决上述技术问题,本发明的技术方案公开了一种基于知识更新和知识整合的终身学习行人再识别方法和装置,包括以下步骤:
7.步骤1:在初始任务t=0开始阶段,t是当前任务序号,给定数据集随机采样一个批次的图片得到nb是批次大小,是第i张图片,并输入到基于卷积神经网络(cnn)的工作模型,进行特征提取并得到softmax预测分数q(
·
)是工作模型采用的softmax函数;
8.步骤2:学习工作模型对当前任务行人图片的判别性,计算基于当前批次图片的交叉熵损失函数其中是第i个预测分数的第
项数值;
9.步骤3:进一步在度量空间优化特征分布,对提取的当前批次特征采用三元组损失函数其中,d(
·
,
·
)代表欧式距离函数,m是设定的阈值参数,表示由工作模型提取的当前批次下第i个行人的锚点特征、正例特征和负例特征;
10.步骤4:结合交叉熵损失函数和三元组损失函数得到t=0阶段的损失函数l0,并经过反向梯度传播更新网络参数,直到达到预设的迭代次数;
11.步骤5:对于t》0时刻的任务,学习网络里兼有记忆模型和工作模型,目标是通过记忆模型和工作模型的联合学习,提升对当前任务和之前任务的效果,提升模型整体的泛化性;
12.在任务t开始时,模型首先进入知识回放阶段,此时的输入为t时刻的数据集缓冲存储区m
t
用于存储0~t-1时刻的所见到的部分样本及其标签,工作模型和记忆模型的学习率分别为γ、η;从和m
t
中分别随机采样一个批次的样本和分别输送到工作模型和记忆模型,输出相应的softmax预测分数,即其中,p(
·
)、q(
·
)代表以(
·
)作为输入分别经过工作模型和记忆模型所输出的预测分数;
13.步骤6:为了防止工作模型在旧任务上的遗忘,在预测分数层面进行知识蒸馏以解决灾难性的遗忘,记忆模型生成的预测分数被用作伪标签指导工作模型的学习,抗遗忘损失函数表示为其中,t表示蒸馏温度,sd(
·
)表示梯度分离算子,js(
·
)表示jesen-shannon散度;
14.步骤7:为了让模型更好地适应到当前任务,设计相应的适应性损失函数其中,适应性损失函数包括一个当前任务的交叉熵损失和一个当前任务的三元组损失
[0015][0016][0017]
表示由工作模型提取的当前批次下第i个行人的锚点特征、正例特征和负例特征;表示由记忆模型提取的当前批次下第i个行人的锚点特
征、正例特征和负例特征;
[0018]
步骤8:获得知识回放阶段工作模型的总体损失函数进而由总体损失函数lw进行梯度反向传播,并由梯度下降算法更新工作模型的参数即对于其中,θ是工作模型的参数,包括特征提取器和分类器的参数。是由当前批次训练样本得到的损失函数lw计算得到的梯度,γ取1;
[0019]
步骤9:知识更新阶段:
[0020]
负责对记忆模型的更新,即用工作模型的知识对记忆模型的响应做校正,以达到更平滑的知识迁移;
[0021]
步骤10:增强记忆模型处理当前任务的能力,计算记忆损失函数包括交叉熵损失和三元组损失
[0022][0023][0024]
其中,交叉熵损失计算于当前任务的样本,而三元组损失计算于缓冲存储区的样本;
[0025]
步骤11:作用于记忆模型的损失被整体计算为进而由lm进行梯度反向传播,并更新工作模型的参数即对于即对于其中,η取0.1;
[0026]
步骤12:重复步骤6至步骤11,直至交替训练结束;
[0027]
步骤13:结束知识回放和知识更新后,进行知识整合,在此阶段,学习网络里分别存有两个训练完毕的工作模型和记忆模型进行模型空间的整合,为下一阶段的训练和部署做准备,得到的复合模型能从记忆模型中获取更大比例的知识,从而对过去的知识做更好的整合;
[0028]
步骤14:其次进行特征空间的知识整合用于测试,给定待测试的图片,分别输入工作模型和记忆模型的特征提取器,得到两个特征向量和为了更好得利用工作模型和记忆模型所捕捉的模式,采用串联的方式得到一个混合的特征最后将得到的混合的特征用于行人检索;
[0029]
步骤15:任务t结束后,进行缓冲储存模块m
t
的更新,首先初始化m
t+1
=m
t
,从新任务的标签库中随机选取多个id,并获取每个id的特征平均值作为该id在特征空间的原型;
[0030]
步骤16:对于每个选中的id,在其特征空间中选择两个相距最远的特征,并更新对
应图片和标签入库缓冲储存区,以更好刻画新任务类别的决策边界;
[0031]
步骤17:拓展新分类器,并初始化新分类器在新任务上的神经元参数;
[0032]
步骤18:重复步骤5~步骤17,直到所有任务结束。
[0033]
优选地,在所述步骤1之前还包括以下步骤:对输入图片进行了一系列预处理,并配置好训练的优化器和训练计划。
[0034]
优选地,步骤1中,工作模型进行特征提取并得到softmax预测分数包括以下步骤:
[0035]
步骤101:工作模型包括五个阶段:
[0036]
第一个阶段是对输入的预处理,包括一个卷积层、批量归一化层、relu激活函数和最大池化层;
[0037]
随后的四个阶段分别由三、四、六、三个bottleneck层组成;
[0038]
步骤102:经过五个阶段处理好的特征图被送入广义池化层和一个批量归一化层,由此得到归一化的特征;
[0039]
步骤103:在训练过程中,还需将归一化的特征输入一个无偏置的线性分类器,从而得到预测分数,最后网络在训练过程中有三个输出:归一化的特征、未归一化的特征、预测分数,其中,未归一化的特征用作训练过程中的三元组损失,归一化的特征仅用于得到预测分数,而预测分数经过softmax之后用作训练过程中的蒸馏和交叉熵损失;
[0040]
步骤104:在测试过程中,只输出归一化的特征,并将查询对象的特征与查找对象的特征计算相似度矩阵其中,是待查询队列里的第qn个特征,是查找对象库里的第gm个特征;之后,根据相似度矩阵可以计算每个查询对象与所有查找对象的相似度排序并计算识别的准确度。
[0041]
优选地,步骤3中,锚点特征为第i个行人图片经工作模型所提取的特征,正例特征为在当前批次特征中与锚点特征属同一身份且欧式距离相距最远的特征,负例特征为在当前批次特征中与锚点特征属不同身份且欧式距离相距最近的特征。
[0042]
优选地,步骤4中,所述t=0阶段的损失函数
[0043]
优选地,步骤4中,网络参数的更新过程包括如下步骤:
[0044]
步骤401:冻结记忆模型参数,将当前任务样本输入到记忆模型得到预测分数作为伪标签,同时输入到工作模型得到预测分数与伪标签计算出js散度得到蒸馏的损失;将蒸馏的损失与当前任务损失相加并进行梯度回传,更新工作模型的参数;
[0045]
步骤502:冻结工作模型参数,将当前任务样本输入到工作模型得到预测分数作为伪标签,同时输入到记忆模型得到预测分数与伪标签计算出js散度得到蒸馏的损失;将蒸馏的损失与当前任务损失相加并进行梯度回传,更新记忆模型的参数;
[0046]
步骤503:重复步骤401至步骤402,直到达到预设的迭代次数。
[0047]
优选地,步骤9中采用记忆校正损失函数
[0048]
优选地,步骤13中,t+1阶段的工作模型参数被更新为被更新为新的记忆模型参数也被更新为
[0049]
优选地,步骤15中,缓冲储存区m
t
的更新方式包括如下步骤:
[0050]
步骤1501:任务t结束后,进行缓冲储存模块m
t
的更新,首先初始化m
t+1
=m
t
,将批次化输入工作模型,指定迭代次数,使得模型提取的所有特征,再从的标签库里随机选取250个id得到{id1,
…
,id
250
},并提取每个id的所有特征的平均值
[0051]
步骤1502:对于每个选中的ididk,将其所有特征与的欧氏距离作排序,选择距离最远的两个特征并更新对应图片和标签入库缓冲储存区:最终得到更新好的m
t
。
[0052]
优选地,步骤17中,所述新分类器拓展过程包括以下步骤:
[0053]
步骤1701:提取新任务的训练数据,输入上阶段训练完毕的工作模型,提取新任务每个类别的特征集合,对该特征集合做平均得到新任务每个类别在特征空间的原型
[0054]
步骤1702:将上一步得到的原型作为分类器在新任务上神经元参数的初始化。而分类器在旧任务上的神经元参数继承原有的权重作为初始化。
[0055]
本发明将终身学习中任务学习过程分为知识回放、知识更新和知识整合三个阶段。知识回放接收本地任务数据和缓冲区任务数据,借助记忆模型产生的伪标签维护工作模型。与此同时,工作模型产生的响应传递到记忆模型自我更新,从而生成更优质的伪标签。这两种模式交替更新模型参数,实现双向的信息传递。任务训练结束后,进入知识整合阶段。在模型层面,本发明设计了一种滑动平均的方法实现工作和记忆模型的整合,以促进下一阶段的部署训练。在测试阶段,本发明提供了一种特征空间的整合以提升在可见和不可见域预测结果的泛化性。
[0056]
与现有技术相比,本发明具有如下有益效果:
[0057]
本发明为终身学习行人再识别提供了一种新的知识更新和知识整合算法,不仅能较好解决灾难性遗忘的问题,同时能够很好地实现正向迁移和反向迁移。在知识回放的基础上,本发明提出了一种知识更新机制,通过动态更新的记忆模型指导工作模型学习,从而实现双向的知识交互,取得更好的迁移效果。此外,本发明介绍了一种知识整合的方法,提升模型长期的稳定性。
附图说明
[0058]
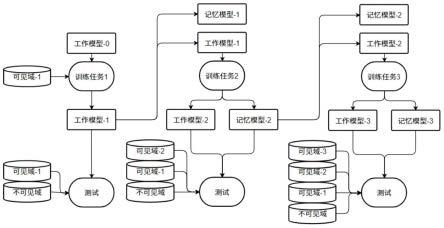
图1为终身学习行人再识别的训练、测试流程图;
[0059]
图2示意了基于知识回放、知识更新和知识整合的算法框架;
[0060]
图3为知识回放和知识更新图;
[0061]
图4为示意了模型知识整合。
具体实施方式
[0062]
下面结合具体实施例,进一步阐述本发明。应理解,这些实施例仅用于说明本发明而不用于限制本发明的范围。此外应理解,在阅读了本发明讲授的内容之后,本领域技术人
pooling)和一个批量归一化层。该批量归一化层的权重初始化为1,偏置初始化为0,并清除偏置的反向梯度更新。由此得到归一化的特征,每个特征维度为2048。
[0082]
步骤203:在训练过程中,还需将归一化的特征输入一个无偏置的线性分类器,从而得到预测分数,最后网络在训练过程中有三个输出:归一化的特征、未归一化的特征、预测分数,其中,未归一化的特征用作训练过程中的三元组损失,归一化的特征仅用于得到预测分数,而预测分数经过softmax之后用作训练过程中的蒸馏和交叉熵损失。
[0083]
步骤204:在测试过程中,只输出归一化的特征,并将查询对象的特征与查找对象的特征计算相似度矩阵其中,是待查询队列里的第qn个特征,是查找对象库里的第gm个特征。之后根据相似度矩阵可以计算每个查询对象与所有查找对象的相似度排序并计算识别的准确度。如图1所示,测试过程包括在不可见域的测试以及所有已见域的测试。
[0084]
步骤3:为了学习工作模型对当前任务行人图片的判别性,计算基于当前批次图片的交叉熵损失函数其中是第i个预测分数的第项数值。
[0085]
步骤4:为了进一步在度量空间优化特征分布,对提取的当前批次特征采用三元组损失函数其中,d(
·
,
·
)代表欧式距离函数,m是设定的阈值参数(大于0),表示由工作模型提取的当前批次下第i个行人的锚点特征、正例特征和负例特征。锚点特征为第i个行人图片经工作模型所提取的特征,正例特征为在当前批次特征中与锚点特征属同一身份且欧式距离相距最远的特征,负例特征为在当前批次特征中与锚点特征属不同身份且欧式距离相距最近的特征。
[0086]
步骤5:结合交叉熵损失函数和三元组损失函数得到t=0阶段的损失函数并经过反向梯度传播更新网络参数,直到达到预设的迭代次数。
[0087]
网络参数的更新过程如图3所示,包括如下步骤:
[0088]
步骤501:冻结记忆模型参数,将当前任务样本输入到记忆模型得到预测分数作为伪标签,同时输入到工作模型得到预测分数与伪标签计算出js散度得到蒸馏的损失,其中蒸馏的温度设置为2。将蒸馏的损失与当前任务损失相加并进行梯度回传,更新工作模型的参数。
[0089]
步骤502:冻结工作模型参数,将当前任务样本输入到工作模型得到预测分数作为伪标签,同时输入到记忆模型得到预测分数与伪标签计算出js散度得到蒸馏的损失,其中蒸馏的温度设置为2。将蒸馏的损失与当前任务损失相加并进行梯度回传,更新记忆模型的参数。
[0090]
步骤503:重复步骤501至步骤502,直到达到预设的迭代次数。
[0091]
步骤6:对于t》0时刻的任务,学习网络里兼有记忆模型和工作模型,目标是通过记忆模型和工作模型的联合学习,提升对当前任务和之前任务的效果,提升模型整体的泛化
性。
[0092]
在任务t开始时,模型首先进入知识回放阶段。具体地,此时的输入为t时刻的数据集缓冲存储区m
t
用于存储0~t-1时刻的所见到的部分样本即其标签,工作模型和记忆模型的学习率分别为γ、η。从和m
t
中分别随机采样一个批次的样本和分别表示图片所对应的标签。分别输送到工作模型和记忆模型,输出相应的softmax预测分数,即输出相应的softmax预测分数,即其中,p(
·
)、q(
·
)代表以(
·
)作为输入分别经过工作模型和记忆模型所输出的预测分数。
[0093]
步骤7:为了防止工作模型在旧任务上的遗忘,在预测分数层面进行知识蒸馏以解决灾难性的遗忘。具体地,记忆模型生成的预测分数可被用作伪标签指导工作模型的学习。抗遗忘损失函数可被具体表示为其中,t表示蒸馏温度,sd(
·
)表示梯度分离算子,js(
·
)表示jesen-shannon散度。
[0094]
步骤8:为了让模型更好地适应到当前任务,设计相应的适应性损失函数其中,适应性损失函数包括一个当前任务的交叉熵损失和一个当前任务的三元组损失
[0095][0096][0097]
表示由工作模型提取的当前批次下第i个行人的锚点特征、正例特征和负例特征;表示由记忆模型提取的当前批次下第i个行人的锚点特征、正例特征和负例特征。
[0098]
步骤9:获得知识回放阶段工作模型的总体损失函数进而由总体损失函数lw进行梯度反向传播,并由梯度下降算法更新工作模型的参数即对于其中,θ是工作模型的参数,包括特征提取器和分类器的参数,是由当前批次训练样本得到的损失函数lw计算得到的梯度,γ取1。
[0099]
步骤10:知识更新阶段:
[0100]
主要负责对记忆模型的更新,即用工作模型的知识对记忆模型的响应做校正,以达到更平滑的知识迁移,本实施例具体采用记忆校正损失函数达到更平滑的知识迁移,本实施例具体采用记忆校正损失函数
[0101]
步骤11:增强记忆模型处理当前任务的能力,计算记忆损失函数包括交叉熵损失和三元组损失
[0102][0103][0104]
其中,交叉熵损失计算于当前任务的样本,而三元组损失计算于缓冲存储区的样本。
[0105]
步骤12:作用于记忆模型的损失可被整体计算为进而由lm进行梯度反向传播,并更新工作模型的参数即对于即对于其中,η取0.1。
[0106]
步骤13:重复步骤7至步骤12,直至交替训练结束。
[0107]
步骤14:结束知识回放和知识更新后,进行知识整合。在此阶段,学习网络里分别存有两个训练完毕的工作模型和记忆模型进行模型空间的整合从而为未来新阶段的训练做准备。具体地,t+1阶段的工作模型参数被更新为类似地,新的记忆模型参数也被更新为通过模型空间的整合得到的复合模型从记忆模型中获取更大比例的知识,从而使其更具有稳定性(stability),即能够对过去的知识做更好的整合。
[0108]
结合图4,模型空间整合过程包括如下步骤:
[0109]
a)将工作模型参数与记忆模型的参数做滑动平均加权,可得到滑动平均模型,由此初始化下一阶段的工作模型。
[0110]
b)同样的方式可以得到下一阶段记忆模型的初始化。采用对工作模型深拷贝的方法得到下一阶段的记忆模型。
[0111]
步骤15:其次进行特征空间的知识整合用于测试。给定待测试的图片,分别输入工作模型和记忆模型的特征提取器,得到两个特征向量和为了更好得利用工作模型和记忆模型所捕捉的模式,采用串联的方式得到一个混合的特征最后将得到的混合的特征用于行人检索。
[0112]
步骤16:任务t结束后,进行缓冲储存模块m
t
的更新。首先初始化m
t+1
=m
t
。从新任务的标签库中随机选取250个id,并获取每个id的特征平均值作为该id在特征空间的原型。
[0113]
本实施例中,缓冲储存区m
t
的更新方式包括如下步骤:
[0114]
a)任务t结束后,进行缓冲储存模块m
t
的更新。首先初始化m
t+1
=m
t
。将批次化输入工作模型,指定迭代次数,使得模型提取的所有特征,再从的标签库里随机选取250个id得到{id1,
…
,id
250
},并提取每个id的所有特征的平均值
[0115]
b)对于每个选中的ididk,将其所有特征与的欧氏距离作排序,选择距离最远的两个特征并更新对应图片和标签入库缓冲储存区:并更新对应图片和标签入库缓冲储存区:最终得到更新好的m
t
。
[0116]
步骤17:对于每个选中的id,在其特征空间中选择两个相距最远的特征,并更新对应图片和标签入库缓冲储存区,以更好刻画新任务类别的决策边界。
[0117]
步骤18:拓展新分类器,并初始化新分类器在新任务上的神经元参数。
[0118]
步骤19:重复步骤6~步骤18,直到所有任务结束。
[0119]
步骤18中,新分类器的拓展过程包括如下步骤:
[0120]
步骤1801:提取新任务的训练数据,输入到经前一个任务训练完成的工作模型,提取得到新任务每一个类别的特征集合,将特征集合做平均可得到新任务每一个类别在特征空间的原型
[0121]
步骤1802:将上一步得到的原型作为分类器在新任务上的神经元参数的初始化,而分类器在旧任务上的神经元参数继承原有的权重作为初始化。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1