一种对话状态追踪方法、装置、设备及介质与流程
1.本发明涉及计算机技术领域,特别涉及一种对话状态追踪方法、装置、设备及介质。
背景技术:
2.随着人工智能的不断发展,人机对话技术以个人助理、客服机器人和语音控制系统等多种不同形式在导航、娱乐和通信等多方面得到了广泛的应用。对话系统可分为任务型和非任务型两大类,关于任务型的对话系统,目前主要有两种方法,分别是管道方法和端到端的方法。管道方法将整个人机对话过程划分为语音识别(automatic speech recognition,asr)、自然语言处理(natural language understanding,nlu)、对话管理(dialogue management,dm)、自然语言生成(natural language generation,nlg)和语音合成(text to speech,tts)五大模块。其中,对话管理模块相当于对话系统的大脑,在整个对话系统中起着非常重要的作用,决定着系统要采取的相应动作,包括追问、澄清和确认等,其主要子任务分别是对话状态追踪(dialogue state tracking,dst)和对话策略生成(dialogue policy,dp)。管道方法可以分别建模优化每一部分,但在多轮对话系统中容易产生误差的传递和累积,使得整体性能变差。端到端的方法减少了模块数量,简化了模型结构,有利于全局优化。由于在任务型对话系统中,用户的需求难以在单论对话中完整清楚的表达,因此,需要用户进行多轮对话逐渐表明自己的需求。
3.现有技术之一为早期的对话追踪技术,其主要是利用基于人工规则的方法。基于有限状态机、槽填充和信息状态更新的对话管理,都需要人工定义大量的规则。基于人工制定规则的方法需要根据任务场景制定规则,但无法保证能够穷举出所有可能的状况和对话规则。总的来说,基于规则模板的对话状态追踪方法仅适用于简单任务的对话状态跟踪,不适用于复杂任务且无法在任务改变后复用规则。
4.鉴于基于规则的方法的局限性,学者们对模型的研究大都采用数据驱动的方法,从而产生了生成式方法和判别式方法,也即现有技术之二。其具有以下缺点:(1)未充分提取历史对话信息特征。深度学习中,可以利用循环神经网络(recurrent neural network,rnn)对时间序列进行建模,提取历史对话信息特征。但rnn存在着梯度消失和梯度爆炸的问题,而长短时记忆网络(long short term memory,lstm)和门控循环单元(gated recurrent unit,gru)虽然可以通过门控机制解决序列长依赖的问题,但它们只有前向的上下文信息,忽略了后向的上下文信息;(2)多领域场景下,未充分共享领域-槽值对信息。
5.为此,如何在不忽略前后向的上下文信息的前提下解决多领域场景下的历史对话长依赖问题,并实现不同领域-槽位对之间的信息共享是本领域亟待解决的问题。
技术实现要素:
6.有鉴于此,本发明的目的在于提供一种对话状态追踪方法、装置、设备及介质,能够在不忽略前后向的上下文信息的前提下解决多领域场景下的历史对话长依赖问题,并实
现不同领域-槽位对之间的信息共享,其具体方案如下:
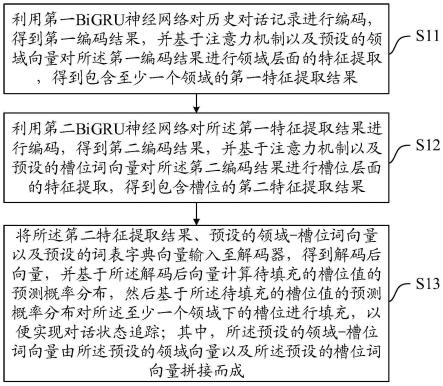
7.第一方面,本技术公开了一种对话状态追踪方法,包括:
8.利用第一bigru神经网络对历史对话记录进行编码,得到第一编码结果,并基于注意力机制以及预设的领域向量对所述第一编码结果进行领域层面的特征提取,得到包含至少一个领域的第一特征提取结果;
9.利用第二bigru神经网络对所述第一特征提取结果进行编码,得到第二编码结果,并基于注意力机制以及预设的槽位词向量对所述第二编码结果进行槽位层面的特征提取,得到包含槽位的第二特征提取结果;
10.将所述第二特征提取结果、预设的领域-槽位词向量以及预设的词表字典向量输入至解码器,得到解码后向量,并基于所述解码后向量计算待填充的槽位值的预测概率分布,然后基于所述待填充的槽位值的预测概率分布对所述至少一个领域下的槽位进行填充,以便实现对话状态追踪;其中,所述预设的领域-槽位词向量由所述预设的领域向量以及所述预设的槽位词向量拼接而成。
11.可选的,所述利用第一bigru神经网络对历史对话记录进行编码,得到第一编码结果之前,还包括:
12.获取若干轮次对话记录,并对所述若干轮次对话记录进行拼接,得到所述历史对话记录。
13.可选的,所述将所述第二特征提取结果、预设的领域-槽位词向量以及预设的词表字典向量输入至解码器,得到解码后向量之后,还包括:
14.基于对话状态追踪策略将所述解码后向量映射为目标概率分布;
15.当所述目标概率分布为第一概率分布,则表示用户对所述至少一个领域下的槽位未提及,当所述目标概率分布为第二概率分布,则表示用户对所述至少一个领域下的槽位持无所谓的状态,当所述目标概率分布为第三概率分布,则表示用户对所述至少一个领域下的槽位有所提及。
16.可选的,所述基于所述解码后向量计算待填充的槽位值的预测概率分布,包括:
17.当所述目标概率分布为所述第三概率分布,则基于所述解码后向量计算所述预设的词表字典中的槽位值的概率分布以及所述历史对话记录中的槽位值的概率分布;
18.根据所述预设的词表字典中的槽位值的概率分布以及所述历史对话记录中的槽位值的概率分布计算所述待填充的槽位值的预测概率分布。
19.可选的,基于所述解码后向量计算所述预设的词表字典中的槽位值的概率分布以及所述历史对话记录中的槽位值的概率分布的公式为:
[0020][0021][0022]
其中,v表示所述预设的词表字典向量,h
decode
表示所述解码后向量,h表示所述第一编码结果,p
vocab
表示所述预设的词表字典中的槽位值的概率分布,p
history
表示所述历史对话记录中的槽位值的概率分布。
[0023]
可选的,根据所述预设的词表字典中的槽位值的概率分布以及所述历史对话记录中的槽位值的概率分布计算所述待填充的槽位值的预测概率分布的公式为:
[0024]
p
value
=p
gen
×
p
vocab
+(1-p
gen
)
×
p
history
;
[0025]
其中,p
gen
表示从所述预设的词表字典中生成所述待填充的槽位值的权重。
[0026]
可选的,所述将所述第二特征提取结果、预设的领域-槽位词向量以及预设的词表字典向量输入至解码器,得到解码后向量,包括:
[0027]
将所述第二特征提取结果、预设的领域-槽位词向量以及预设的词表字典向量输入至由第三bigru神经网络构建的解码器,得到解码后向量。
[0028]
第二方面,本技术公开了一种对话状态追踪装置,包括:
[0029]
第一编码模块,用于利用第一bigru神经网络对历史对话记录进行编码,得到第一编码结果;
[0030]
领域层面特征提取模块,用于基于注意力机制以及预设的领域向量对所述第一编码结果进行领域层面的特征提取,得到包含至少一个领域的第一特征提取结果;
[0031]
第二编码模块,用于利用第二bigru神经网络对所述第一特征提取结果进行编码,得到第二编码结果;
[0032]
槽位层面特征提取模块,用于基于注意力机制以及预设的槽位词向量对所述第二编码结果进行槽位层面的特征提取,得到包含槽位的第二特征提取结果;
[0033]
解码模块,用于将所述第二特征提取结果、预设的领域-槽位词向量以及预设的词表字典向量输入至解码器,得到解码后向量;
[0034]
对话状态追踪模块,用于基于所述解码后向量计算待填充的槽位值的预测概率分布,然后基于所述待填充的槽位值的预测概率分布对所述至少一个领域下的槽位进行填充,以便实现对话状态追踪;其中,所述预设的领域-槽位词向量由所述预设的领域向量以及所述预设的槽位词向量拼接而成。
[0035]
第三方面,本技术公开了一种电子设备,包括:
[0036]
存储器,用于保存计算机程序;
[0037]
处理器,用于执行所述计算机程序,以实现前述公开的对话状态追踪方法。
[0038]
第四方面,本技术公开了一种计算机可读存储介质,用于保存计算机程序;其中,所述计算机程序被处理器执行时实现前述公开的对话状态追踪方法。
[0039]
可见,本技术提出一种对话状态追踪方法,包括:利用第一bigru神经网络对历史对话记录进行编码,得到第一编码结果,并基于注意力机制以及预设的领域向量对所述第一编码结果进行领域层面的特征提取,得到包含至少一个领域的第一特征提取结果;利用第二bigru神经网络对所述第一特征提取结果进行编码,得到第二编码结果,并基于注意力机制以及预设的槽位词向量对所述第二编码结果进行槽位层面的特征提取,得到包含槽位的第二特征提取结果;将所述第二特征提取结果、预设的领域-槽位词向量以及预设的词表字典向量输入至解码器,得到解码后向量,并基于所述解码后向量计算待填充的槽位值的预测概率分布,然后基于所述待填充的槽位值的预测概率分布对所述至少一个领域下的槽位进行填充,以便实现对话状态追踪;其中,所述预设的领域-槽位词向量由所述预设的领域向量以及所述预设的槽位词向量拼接而成。综上可见,由于bigru(双向门控循环单元)神经网络可以利用前向和后向的门控循环单元(gru)结构提取上下文信息,因此本技术基于bigru神经网络在不忽略前后向的上下文信息的前提下解决了多领域场景下的历史对话长依赖问题;此外,传统的对话状态追踪是对领域-槽位对做整体的特征提取,如此一来,同一
领域下的不同槽位信息之间无关,不同领域下的相同槽位信息之间亦无关,而本技术是将领域及槽位分开处理并依次对领域以及槽位做注意力运算,使得提取到的不同领域-槽位对之间的信息能够共享。
附图说明
[0040]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。
[0041]
图1为本技术公开的一种对话状态追踪方法流程图;
[0042]
图2为本技术公开的一种具体的对话状态追踪方法流程图;
[0043]
图3为本技术公开的一种对话状态追踪装置结构示意图;
[0044]
图4为本技术公开的一种电子设备结构图。
具体实施方式
[0045]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0046]
生成式方法和判别式方法,具有以下缺点:(1)未充分提取历史对话信息特征。深度学习中,可以利用循环神经网络对时间序列进行建模,提取历史对话信息特征。但rnn存在着梯度消失和梯度爆炸的问题,而长短时记忆网络和门控循环单元虽然可以通过门控机制解决序列长依赖的问题,但它们只有前向的上下文信息,忽略了后向的上下文信息;(2)多领域场景下,未充分共享领域-槽位对信息。
[0047]
为此,本技术实施例提出一种对话状态追踪方案,能够在不忽略前后向的上下文信息的前提下解决多领域场景下的历史对话长依赖问题,并实现不同领域-槽位对之间的信息共享。
[0048]
本技术实施例公开了一种对话状态追踪方法,参见图1所示,该方法包括:
[0049]
步骤s11:利用第一bigru神经网络对历史对话记录进行编码,得到第一编码结果,并基于注意力机制以及预设的领域向量对所述第一编码结果进行领域层面的特征提取,得到包含至少一个领域的第一特征提取结果。
[0050]
需要指出的是,在多轮次的对话任务过程中,往往会出现没有意义的对话,还会出现话题转移的情况,这些都会导致多领域场景下领域判别不清,上下文之间相互影响,为了捕获不同领域下的历史对话信息,使其更好的关注于各自领域信息而不受其他域的信息干扰,本技术采用领域注意力机制解决传统技术中不能更好的关注于各自领域信息并且受其他域的信息干扰的问题,由于注意力机制能够忽略输入序列中元素的距离,直接捕获任务中的关键信息,因此本技术能够更好的关注于各自领域信息而不受其他域的信息干扰。具体过程如下所示:
[0051]
本实施例中,首先需要获取若干轮次对话记录,并对所述若干轮次对话记录进行
拼接,得到所述历史对话记录。具体的,将t轮对话的多轮次对话d
t
依次拼接成x={u1,s1,u2,s2,...u
t
,s
t
},其中,u
t
表示t时刻的用户话语,s
t
表示t时刻的系统话语。进一步的,利用第一bigru神经网络对x={u1,s1,u2,s2,...u
t
,s
t
}进行编码,得到第一编码结果,表示为h={h1,h2,...h
t
},所述第一编码结果为bigru神经网络的隐含层输出,需要指出的是,此处编码是为了后续提取领域层面的特征。其中,bigru神经网络可以利用前向和后向的gru结构提取上下文信息,充分捕捉到对话语句中蕴含的语义信息。在对拼接后的对话记录进行编码后,对预设的领域词数据库中的领域词进行编码得到所述预设的领域向量,具体的,对于所述预设的领域词数据库中的某一个特定的领域词di,可以将其编码为需要指出的是,此处编码是为了将领域词编码为领域向量。进一步的,对编码后的对话记录和编码后得到的领域向量进行注意力计算,从而完成领域特征提取。所述对编码后的对话记录和编码后得到的领域向量进行计算的过程,通过公式可以表现为以下形式:
[0052][0053][0054][0055]
其中,yi表示预设的领域词向量中第i个域和历史对话记录之间的相关性;y
isoftmax
表示归一化后的yi,也即每一个领域i对应历史对话记录的权重;y
icontext
表示带有领域权重的历史向量h;所述历史向量即上下文向量,也即对历史对话记录进行编码后得到的第一编码结果;t表示转置。
[0056]
由于含有整个历史对话记录的上下文信息,因此,本技术使用作为特定领域di的表示,然后,利用注意力机制计算上下文,通过赋予权重的方式提取神经网络输出的隐含表示,本实施例中,所述第一特征提取结果也即y
icontext
。
[0057]
步骤s12:利用第二bigru神经网络对所述第一特征提取结果进行编码,得到第二编码结果,并基于注意力机制以及预设的槽位词向量对所述第二编码结果进行槽位层面的特征提取,得到包含槽位的第二特征提取结果。
[0058]
本实施例中,在获取带有领域关键信息的第一特征提取结果之后,利用第二bigru神经网络对所述第一特征提取结果进行编码,得到第二编码结果,记为h',需要指出的是,此处编码是为了后续提取槽位层面的特征。在对第一特征提取结果进行编码后,对预设的槽位词数据库中的槽位词进行编码得到所述预设的槽位词向量,具体的,对于所述预设的槽位词数据库中的某一个特定的槽位词sj,可以将其编码为需要指出的是,此处编码是为了将槽位词编码为槽位词向量,进一步的,对第二编码结果以及编码后得到的槽位词向量进行注意力计算,从而完成槽位词特征提取。所述对第二编码结果以及编码后得打的槽位词向量进行注意力计算的过程,通过公式可以表现为以下形式:
[0059][0060]
[0061][0062]
其中,zj表示预设的槽位词向量中第j个域和历史对话记录之间的相关性,z
jsoftmax
表示归一化后的zj,也即每一个槽位词对应历史对话记录的权重;z
jcontext
表示带有槽位词权重的历史向量h。
[0063]
参见领域特征的处理方式,由于含有整个历史对话信息的上下文信息,因此,本技术使用作为特定槽位sj的表示。然后,利用注意力机制计算上下文,通过赋予权重的方式提取神经网络输出的隐含表示,实施例中,所述第二特征提取结果也即z
jcontext
。如此一来,本技术能够将历史对话信息中关于槽位的信息突出表达。
[0064]
需要指出的是,在对话状态追踪中,传统的操作都是对领域-槽位对做整体编码,如此一来,同一领域下的不同槽位之间无关,不同领域下的相同槽位之间亦无关。但是在多领域对话的情况下,所有领域-槽位对之间并不是完全无关的,比如,地点槽位信息会出现在打车和订餐领域中。再者,多领域数据集中不同领域之间的数据规模往往不是完全均衡的,可能有些领域的数据量较少从而导致模型训练不充分,也即传统的操作未充分共享领域-槽位对之间的信息,相较于传统的基于领域-槽位对的处理方式,本技术通过将领域以及槽位分开处理,并依次领域以及槽位做注意力运算,实现了不同领域-槽位对之间的信息共享。例如,假设存在领域a以及领域b,领域a下的某一槽位对应的槽位值是a1,a2,领域b下的相同槽位对应的槽位值是b1,b2,传统的操作是对领域-槽位对做整体编码,也即a-a1,a-a2,b-b1,b-b2,编码结果使得领域a和领域b下的相同槽位之间没有关系,但是在多领域对话的情况下,所有领域-槽位对之间并不是完全无关的,因此,本技术通过将领域以及槽位分开处理,并依次领域以及槽位做注意力运算,也即先对领域做注意力运算,提取到领域a和领域b,再对槽位做注意力运算,然后确定待填充的槽位值可能是a1、a2、b1、b2,此时领域下的槽位对应的槽位值不但可以包括a1与a2还可以包括b1与b2,如此一来,实现了不同领域-槽位对之间的信息共享。
[0065]
步骤s13:将第二特征提取结果、预设的领域-槽位词向量以及预设的词表字典向量输入至解码器,得到解码后向量,并基于所述解码后向量计算待填充的槽位值的预测概率分布,然后基于所述待填充的槽位值的预测概率分布对所述至少一个领域下的槽位进行填充,以便实现对话状态追踪;其中,所述预设的领域-槽位词向量由所述预设的领域向量以及所述预设的槽位词向量拼接而成。
[0066]
具体的,将所述第二特征提取结果、预设的领域-槽位词向量以及预设的词表字典向量输入至由第三bigru神经网络构建的解码器,得到解码后向量。
[0067]
本实施例中,在将第二特征提取结果、预设的领域-槽位词向量以及预设的词表字典向量输入至解码器,得到解码后向量之后,还包括:基于对话状态追踪策略将所述解码后向量映射为目标概率分布;当所述目标概率分布为第一概率分布,则表示用户对所述至少一个领域下的槽位未提及,当所述目标概率分布为第二概率分布,则表示用户对所述至少一个领域下的槽位持无所谓的状态,当所述目标概率分布为第三概率分布,则表示用户对所述至少一个领域下的槽位有所提及。所述对话状态追踪策略具体为当下主流的dst(dialogue state tracking,对话状态追踪)更新策略,即分类器将解码后向量映射成none、dontcare和mentioned的概率分布,其中,当映射为none的概率分布(第一概率分布),
则表示用户对所述至少一个领域下的槽位未提及,当映射为dotcare的概率分布(第二概率分布),则表示用户对所述至少一个领域下的槽位持无所谓的状态,当映射为mentioned的概率分布(第三概率分布),则表示用户对所述至少一个领域下的槽位有所提及。
[0068]
本实施例中,在历史对话记录中,由于用户的表述可能模糊不清,因此无法直接根据用户的表述计算待填充的槽位值,因此本技术引入预设的词表词典,所述预设的词表字典中包括若干个槽位值,进一步的,由于词表字典中无法包括所有的槽位值,因此本技术基于词表字典以及历史对话记录共同计算待填充的槽位值的概率分布。具体的,当映射为第三概率分布时,则基于所述解码后向量计算所述预设的词表字典中的槽位值的概率分布以及所述历史对话记录中的槽位值的概率分布;根据所述预设的词表字典中的槽位值的概率分布以及所述历史对话记录中的槽位值的概率分布计算所述待填充的槽位值的预测概率分布。其中,所述基于所述解码后向量计算所述预设的词表字典中的槽位值的概率分布以及所述历史对话记录中的槽位值的概率分布的公式为:
[0069][0070][0071]
其中,v表示所述预设的词表字典向量,h
decode
表示所述解码后向量,h表示所述第一编码结果,p
vocab
表示所述预设的词表字典中的槽位值的概率分布,p
history
表示所述历史对话记录中的槽位值的概率分布。
[0072]
所述根据所述预设的词表字典中的槽位值的概率分布以及所述历史对话记录中的槽位值的概率分布计算所述待填充的槽位值的预测概率分布的公式为:
[0073]
p
value
=p
gen
×
p
vocab
+(1-p
gen
)
×
p
history
;
[0074]
其中,p
gen
表示从所述预设的词表字典中生成所述待填充的槽位值的权重。
[0075]
如此一来,本技术根据待填充的槽位值的概率分布确定出相应的槽位值,并利用所述槽位值对至少一个领域下的槽位进行填充。
[0076]
可见,本技术提出一种对话状态追踪方法,包括:利用第一bigru神经网络对历史对话记录进行编码,得到第一编码结果,并基于注意力机制以及预设的领域向量对所述第一编码结果进行领域层面的特征提取,得到包含至少一个领域的第一特征提取结果;利用第二bigru神经网络对所述第一特征提取结果进行编码,得到第二编码结果,并基于注意力机制以及预设的槽位词向量对所述第二编码结果进行槽位层面的特征提取,得到包含槽位的第二特征提取结果;将所述第二特征提取结果、预设的领域-槽位词向量以及预设的词表字典向量输入至解码器,得到解码后向量,并基于所述解码后向量计算待填充的槽位值的预测概率分布,然后基于所述待填充的槽位值的预测概率分布对所述至少一个领域下的槽位进行填充,以便实现对话状态追踪;其中,所述预设的领域-槽位词向量由所述预设的领域向量以及所述预设的槽位词向量拼接而成。综上可见,由于bigru(双向门控循环单元)神经网络可以利用前向和后向的门控循环单元(gru)结构提取上下文信息,因此本技术基于bigru神经网络在不忽略前后向的上下文信息的前提下解决了多领域场景下的历史对话长依赖问题;此外,传统的对话状态追踪是对领域-槽位对做整体的特征提取,如此一来,同一领域下的不同槽位信息之间无关,不同领域下的相同槽位信息之间亦无关,而本技术是将领域及槽位分开处理并依次对领域以及槽位做注意力运算,使得提取到的不同领域-槽位
对之间的信息能够共享。
[0077]
图2为本技术公开的一种具体的对话状态追踪方法流程图,参见图2所示,本技术(1)首先使用第一bigru神经网络将拼接的历史对话进行编码,得到第一编码结果;(2)基于注意力机制以及预设的领域向量对第一编码结果进行领域层面的特征提取,得到第一特征提取结果;(3)使用第二bigru神经网络结构对第一特征提取结果进行编码,得到第二编码结果;(4)基于注意力机制以及预设的槽位词向量对第二编码结果进行槽位层面的特征提取,得到第二特征提取结果;(5)将第二特征提取结果、预设的词表字典向量以及领域-槽位词向量输入至解码器,得到解码后向量,解码器采用第三bigru神经网络结构;(6)计算预设的词表字典中槽位值的概率以及历史对话记录中槽位值的概率;并基于预设的词表字典中槽位值的概率、历史对话记录中槽位值的概率以及解码后向量计算槽位值最终的预测概率分布,并根据槽位值最终概率分布确定相应的槽位值,然后完成填充。
[0078]
可见,由于双向门控单元可以利用前向和后向的门控循环单元结构提取上下文信息,因此本技术基于bigru神经网络在不忽略前后向的上下文信息的前提下解决多领域场景下的历史对话长依赖问题;本技术通过将领域及槽位分开处理并依次对领域以及槽位做注意力运算,实现了不同领域-槽位对之间的信息共享。
[0079]
相应的,本技术实施例还公开了一种对话状态追踪装置,参见图3所示,该装置包括:
[0080]
第一编码模块11,用于利用第一bigru神经网络对历史对话记录进行编码,得到第一编码结果;
[0081]
领域层面特征提取模块12,用于基于注意力机制以及预设的领域向量对所述第一编码结果进行领域层面的特征提取,得到包含至少一个领域的第一特征提取结果;
[0082]
第二编码模块13,用于利用第二bigru神经网络对所述第一特征提取结果进行编码,得到第二编码结果;
[0083]
槽位层面特征提取模块14,用于基于注意力机制以及预设的槽位词向量对所述第二编码结果进行槽位层面的特征提取,得到包含槽位的第二特征提取结果;
[0084]
解码模块15,用于将所述第二特征提取结果、预设的领域-槽位词向量以及预设的词表字典向量输入至解码器,得到解码后向量;
[0085]
对话状态追踪模块16,用于基于所述解码后向量计算待填充的槽位值的预测概率分布,然后基于所述待填充的槽位值的预测概率分布对所述至少一个领域下的槽位进行填充,以便实现对话状态追踪;其中,所述预设的领域-槽位词向量由所述预设的领域向量以及所述预设的槽位词向量拼接而成。
[0086]
其中,关于上述各个模块更加具体的工作过程可以参考前述实施例中公开的相应内容,在此不再进行赘述。
[0087]
可见,本技术提出一种对话状态追踪方法,包括:利用第一bigru神经网络对历史对话记录进行编码,得到第一编码结果,并基于注意力机制以及预设的领域向量对所述第一编码结果进行领域层面的特征提取,得到包含至少一个领域的第一特征提取结果;利用第二bigru神经网络对所述第一特征提取结果进行编码,得到第二编码结果,并基于注意力机制以及预设的槽位词向量对所述第二编码结果进行槽位层面的特征提取,得到包含槽位的第二特征提取结果;将所述第二特征提取结果、预设的领域-槽位词向量以及预设的词表
字典向量输入至解码器,得到解码后向量,并基于所述解码后向量计算待填充的槽位值的预测概率分布,然后基于所述待填充的槽位值的预测概率分布对所述至少一个领域下的槽位进行填充,以便实现对话状态追踪;其中,所述预设的领域-槽位词向量由所述预设的领域向量以及所述预设的槽位词向量拼接而成。综上可见,由于bigru(双向门控循环单元)神经网络可以利用前向和后向的门控循环单元(gru)结构提取上下文信息,因此本技术基于bigru神经网络在不忽略前后向的上下文信息的前提下解决了多领域场景下的历史对话长依赖问题;此外,传统的对话状态追踪是对领域-槽位对做整体的特征提取,如此一来,同一领域下的不同槽位信息之间无关,不同领域下的相同槽位信息之间亦无关,而本技术是将领域及槽位分开处理并依次对领域以及槽位做注意力运算,使得提取到的不同领域-槽位对之间的信息能够共享。
[0088]
进一步的,本技术实施例还提供了一种电子设备。图4是根据一示例性实施例示出的电子设备20结构图,图中的内容不能认为是对本技术的使用范围的任何限制。
[0089]
图4为本技术实施例提供的一种电子设备20的结构示意图。该电子设备20,具体可以包括:至少一个处理器21、至少一个存储器22、显示屏23、输入输出接口24、通信接口25、电源26和通信总线27。其中,所述存储器22用于存储计算机程序,所述计算机程序由所述处理器21加载并执行,以实现前述任一实施例公开的对话状态追踪方法中的相关步骤。另外,本实施例中的电子设备20具体可以为电子计算机。
[0090]
本实施例中,电源26用于为电子设备20上的各硬件设备提供工作电压;通信接口25能够为电子设备20创建与外界设备之间的数据传输通道,其所遵循的通信协议是能够适用于本技术技术方案的任意通信协议,在此不对其进行具体限定;输入输出接口24,用于获取外界输入数据或向外界输出数据,其具体的接口类型可以根据具体应用需要进行选取,在此不进行具体限定。
[0091]
另外,存储器22作为资源存储的载体,可以是只读存储器、随机存储器、磁盘或者光盘等,其上所存储的资源可以包括计算机程序221,存储方式可以是短暂存储或者永久存储。其中,计算机程序221除了包括能够用于完成前述任一实施例公开的由电子设备20执行的对话状态追踪方法的计算机程序之外,还可以进一步包括能够用于完成其他特定工作的计算机程序。
[0092]
进一步的,本技术实施例还公开了一种计算机可读存储介质,用于存储计算机程序;其中,所述计算机程序被处理器执行时实现前述公开的对话状态追踪方法。
[0093]
关于该方法的具体步骤可以参考前述实施例中公开的相应内容,在此不再进行赘述。
[0094]
本技术书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其它实施例的不同之处,各个实施例之间相同或相似部分互相参见即可对于实施例公开的装置而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
[0095]
专业人员还可以进一步意识到,结合本文中所公开的实施例描述的各示例的单元及算法步骤,能够以电子硬件、计算机软件或者二者的结合来实现,为了清楚地说明硬件和软件的可互换性,在上述说明中已经按照功能一般性地描述了各示例的组成及步骤。这些功能究竟以硬件还是软件方式来执行,取决于技术方案的特定应用和设计约束条件。专业
技术人员可以对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不应认为超出本技术的范围。
[0096]
结合本文中所公开的实施例描述的方法或算法的步骤可以直接用硬件、处理器执行的软件模块,或者二者的结合来实施。软件模块可以置于随机存储器(ram)、内存、只读存储器(rom)、电可编程rom、电可擦除可编程rom、寄存器、硬盘、可移动磁盘、cd-rom、或技术领域内所公知的任意其它形式的存储介质中。
[0097]
最后,还需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个
……”
限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。
[0098]
以上对本技术所提供的一种对话状态追踪方法、装置、设备、存储介质进行了详细介绍,本文中应用了具体个例对本技术的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本技术的方法及其核心思想;同时,对于本领域的一般技术人员,依据本技术的思想,在具体实施方式及应用范围上均会有改变之处,综上所述,本说明书内容不应理解为对本技术的限制。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1