一种基于机器学习的县域森林碳汇估算方法和装置与流程
1.本发明涉及一种森林经营管理技术领域,尤其涉及一种基于机器学习的县域森林碳汇估算方法和装置。
背景技术:
2.准确计算森林碳储量对落实碳中和具有重要支撑作用,可为未来森林生态系统的可持续发展提供科学依据。目前广泛使用的生物量因子法、生物转换因子连续函数法、遥感法、样地网络等技术均适用于省级及以上层面的大尺度区域的森林碳储量估算,若应用于更小颗粒度的森林碳储量估算将显著降低估算精度。而异速方程适用于计算单木碳储量,要实现所有县域森林全覆盖需要耗费巨大人力、物力和财力。县域作为森林经营管理主体,现有森林碳储量估算方法难以准确反映县域森林碳储量水平,阻碍县域森林碳汇治理工作开展。
3.因此,迫切需要一种高精度、低成本、可通用的县域森林碳储量估算方法。
技术实现要素:
4.本发明的目的在于提供一种基于机器学习的县域森林碳汇估算方法和装置,解决了现有技术中缺少适用于县域森林碳储量估算方法的问题,如何以高效率、低成本、可通用的方式实现全省范围内各县域森林碳储量的精准估算的问题。
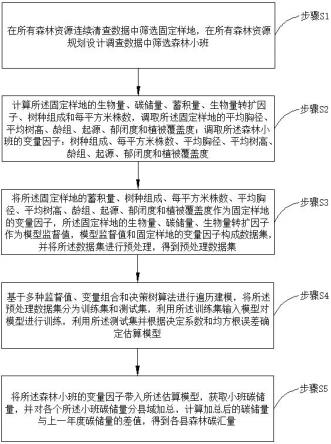
5.本发明采用的技术方案如下:一种基于机器学习的县域森林碳汇估算方法,包括以下步骤:步骤s1:在所有森林资源连续清查数据中筛选固定样地,在所有森林资源规划设计调查数据中筛选森林小班;步骤s2:计算所述固定样地的生物量、碳储量、蓄积量、生物量转扩因子、树种组成和每平方米株数,调取所述固定样地的平均胸径、平均树高、龄组、起源、郁闭度和植被覆盖度;调取所述森林小班的变量因子:树种组成、每平方米株数、平均胸径、平均树高、龄组、起源、郁闭度和植被覆盖度;步骤s3:将所述固定样地的蓄积量、树种组成、每平方米株数、平均胸径、平均树高、龄组、起源、郁闭度和植被覆盖度作为固定样地的变量因子,所述固定样地的生物量、碳储量、生物量转扩因子作为模型监督值,模型监督值和固定样地的变量因子构成数据集,并将所述数据集进行预处理,得到预处理数据集;步骤s4:基于多种监督值、变量组合和决策树算法进行遍历建模,将所述预处理数据集分为训练集和测试集,利用所述训练集输入模型对模型进行训练,利用所述测试集并根据决定系数和均方根误差确定估算模型;步骤s5:将所述森林小班的变量因子带入所述估算模型,获取小班碳储量,并对各个所述小班碳储量分县域加总,计算加总后的碳储量与上一年度碳储量的差值,得到各县森林碳汇量。
6.进一步地,所述步骤s1中所述筛选的方法包括数据集筛选法和特征变量筛选法,所述数据集筛选法为以地类类型为乔木林和疏林地进行筛选,所述特征变量筛选法为以所述固定样地和所述森林小班共有的林分因子作为特征变量进行筛选。
7.进一步地,所述s2中计算所述固定样地的树种组成的方式为:通过所述森林小班的树种组成十分法,根据各树种蓄积量占比换算得到固定样地的树种组成。
8.进一步地,所述s2中所述生物量转扩因子为所述固定样地的生物量与所述固定样地的蓄积量的比值。
9.进一步地,所述步骤s3中所述预处理具体为:采用一位有效编码将所述数据集中的离散型特征变量映射到多维空间,并利用standardscaler函数进行标准化处理,得到预处理数据集。
10.进一步地,所述步骤s4中利用随机森林、梯度提升决策树、轻量的梯度提升机、极端梯度提升和梯度提升+类别型特征的机器学习算法进行遍历建模。
11.进一步地,所述步骤s4中训练得到的多个模型,对多个模型计算决定系数和均方根误差,并对多个所述决定系数和多个所述均方根误差进行排序,将所述决定系数排序第一和所述均方根误差排序倒数第一的模型作为估算模型。
12.进一步地,所述步骤s5中获取小班碳储量计算路径的类型分为:当所述估算模型中预测变量为生物量转扩因子,则结合活立木蓄积量、树种含碳系数计算得到小班碳储量;当所述估算模型中预测变量为生物量,则结合树种含碳系数计算得到小班碳储量;当所述估算模型中预测变量为碳储量,则无需再做进一步计算,得到小班碳储量。
13.本发明还提供一种基于机器学习的县域森林碳汇估算装置,包括存储器和一个或多个处理器,所述存储器中存储有可执行代码,所述一个或多个处理器执行所述可执行代码时,用于实现上述任一项所述的一种基于机器学习的县域森林碳汇估算方法。
14.本发明还提供一种计算机可读存储介质,其上存储有程序,该程序被处理器执行时,实现上述任一项所述的一种基于机器学习的县域森林碳汇估算方法。
15.本发明的有益效果是:本发明针对固定样地数据和森林小班数据提出了一种高效率、低成本、可推广的县域森林碳储量估算方法,实现了固定样地数据与森林小班数据融合视角下的县域森林碳储量估算。本发明提出的建模方法能够有效覆盖全省各类型森林特点,并体现在县域森林碳储量差异中。本建模方法采用了机器学习技术,避免了传统森林碳储量估算模型中变量数量有限、无法充分纳入所有林分因子变量导致森林碳储量估算偏差较大的缺点,且模型迁移应用的潜力更大,能更精确的估算县级尺度的森林碳储量。
附图说明
16.图1为本发明一种基于机器学习的县域森林碳汇估算方法的流程示意图;图2为实施例的具体流程图;图3为基于三个监督值的catboost算法与线性模型预测精度对比:决定系数;图4为基于三个监督值的catboost算法与线性模型预测精度对比:均方根误差;图5为本发明一种基于机器学习的县域森林碳汇估算装置的结构示意图。
具体实施方式
17.以下对至少一个示例性实施例的描述实际上仅仅是说明性的,决不作为对本发明及其应用或使用的任何限制。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
18.参见图1,一种基于机器学习的县域森林碳汇估算方法,包括以下步骤:步骤s1:在所有森林资源连续清查数据中筛选固定样地,在所有森林资源规划设计调查数据中筛选森林小班;所述筛选的方法包括数据集筛选法和特征变量筛选法,所述数据集筛选法为以地类类型为乔木林和疏林地进行筛选,所述特征变量筛选法为以所述固定样地和所述森林小班共有的林分因子作为特征变量进行筛选。
19.步骤s2:计算所述固定样地的生物量、碳储量、蓄积量、生物量转扩因子、树种组成和每平方米株数,调取所述固定样地的平均胸径、平均树高、龄组、起源、郁闭度和植被覆盖度;调取所述森林小班的变量因子:树种组成、每平方米株数、平均胸径、平均树高、龄组、起源、郁闭度和植被覆盖度;计算所述固定样地的树种组成的方式为:通过所述森林小班的树种组成十分法,根据各树种蓄积量占比换算得到固定样地的树种组成。
20.所述生物量转扩因子为所述固定样地的生物量与所述固定样地的蓄积量的比值。
21.步骤s3:将所述固定样地的蓄积量、树种组成、每平方米株数、平均胸径、平均树高、龄组、起源、郁闭度和植被覆盖度作为固定样地的变量因子,所述固定样地的生物量、碳储量、生物量转扩因子作为模型监督值,模型监督值和固定样地的变量因子构成数据集,并将所述数据集进行预处理,得到预处理数据集;所述预处理具体为:采用一位有效编码将所述数据集中的离散型特征变量映射到多维空间,并利用standardscaler函数进行标准化处理,得到预处理数据集。
22.步骤s4:基于多种监督值、变量组合和决策树算法进行遍历建模,将所述预处理数据集分为训练集和测试集,利用所述训练集输入模型对模型进行训练,利用所述测试集并根据决定系数和均方根误差确定估算模型;利用随机森林、梯度提升决策树、轻量的梯度提升机、极端梯度提升和梯度提升+类别型特征的机器学习算法进行遍历建模。
23.训练得到的多个模型,对多个模型计算决定系数和均方根误差,并对多个所述决定系数和多个所述均方根误差进行排序,将所述决定系数排序第一和所述均方根误差排序倒数第一的模型作为估算模型。
24.步骤s5:将所述森林小班的变量因子带入所述估算模型,获取小班碳储量,并对各个所述小班碳储量分县域加总,计算加总后的碳储量与上一年度碳储量的差值,得到各县森林碳汇量。
25.获取小班碳储量计算路径的类型分为:当所述估算模型中预测变量为生物量转扩因子,则结合活立木蓄积量、树种含碳系数计算得到小班碳储量;当所述估算模型中预测变量为生物量,则结合树种含碳系数计算得到小班碳储量;
当所述估算模型中预测变量为碳储量,则无需再做进一步计算,得到小班碳储量。
26.实施例:参见图2,一种基于机器学习的县域森林碳汇估算方法,包括以下步骤:步骤s1:在所有森林资源连续清查数据中筛选固定样地,在所有森林资源规划设计调查数据中筛选森林小班;所述筛选的方法包括数据集筛选法和特征变量筛选法,所述数据集筛选法为以地类类型为乔木林和疏林地进行筛选,所述特征变量筛选法为以所述固定样地和所述森林小班共有的林分因子作为特征变量进行筛选。
27.固定样地筛选规则为:地类类型为乔木林、疏林地,或同时包含乔木林和疏林地。在各固定样地的样木数据中筛选树种属于针叶树种、阔叶树种与经济树种中的活立木。
28.步骤s2:计算所述固定样地的生物量、碳储量、蓄积量、生物量转扩因子、树种组成和每平方米株数,调取所述固定样地的平均胸径、平均树高、龄组、起源、郁闭度和植被覆盖度;调取所述森林小班的变量因子:树种组成、每平方米株数、平均胸径、平均树高、龄组、起源、郁闭度和植被覆盖度;计算所述固定样地的树种组成的方式为:通过所述森林小班的树种组成十分法,根据各树种蓄积量占比换算得到固定样地的树种组成。
29.确认固定样地的样木所述树种分类后(松、杉、硬阔1、硬阔2、软阔),利用生物量模型计算每棵样木生物量,并进一步乘以各树种含碳系数计算获得样木碳储量。利用材积模型计算每棵样木蓄积量。各固定样地中所有样木求和得到每个固定样地生物量、碳储量、蓄积量。
30.其中,为固定样地生物量为固定样地蓄积量;为固定样地碳储量;所述生物量转扩因子为所述固定样地的生物量与所述固定样地的蓄积量的比值。
31.各固定样地生物量除以固定样地蓄积量获得固定样地生物量转扩因子(bcefj)。
32.在固定样地数据库和森林小班数据库中筛选出两套数据库共有的林分因子作为特征变量输入备选,即活立木蓄积量、平均胸径,平均树高,树种组成(松组成,杉组成,硬阔1组成,硬阔2组成,软阔组成),龄组,起源(天然,人工),郁闭度,植被覆盖度,立木株数(棵/平方米)。根据每棵样木蓄积量与所属树种组成分类(松组成,杉组成,硬阔1组成,硬阔2组成,软阔之一),计算固定样地树种组成。
33.步骤s3:将所述固定样地的蓄积量、树种组成、每平方米株数、平均胸径、平均树高、龄组、起源、郁闭度和植被覆盖度作为固定样地的变量因子,所述固定样地的生物量、碳储量、生物量转扩因子作为模型监督值,模型监督值和固定样地的变量因子构成数据集,并将所述数据集进行预处理,得到预处理数据集;
所述预处理具体为:采用一位有效编码(one-hot)将所述数据集中的离散型特征变量映射到多维空间,并利用standardscaler函数进行标准化处理,得到预处理数据集。
34.离散型特征变量为起源和树种组成。
35.步骤s4:基于多种监督值、变量组合和决策树算法进行遍历建模,将所述预处理数据集按照80%、20%划分为训练集和测试集,利用所述训练集输入模型对模型进行训练,利用所述测试集并根据决定系数r2和均方根误差rmse确定估算模型;利用随机森林、梯度提升决策树、轻量的梯度提升机、极端梯度提升和梯度提升+类别型特征的机器学习算法进行遍历建模。
36.训练得到的多个模型,对多个模型计算决定系数r2和均方根误差rmse,并对多个所述决定系数r2和多个所述均方根误差rmse进行排序,将所述决定系数r2排序第一和所述均方根误差rmse排序倒数第一的模型作为估算模型。
37.式中,分别代表固定样地的生物量转扩因子、生物量和碳储量的三个预测变量设计;分别代表随机森林(random forest)、梯度提升决策树(gbdt)、轻量的梯度提升机(lightgbm)、极端梯度提升(xgboost)、梯度提升+类别型特征(catboost)五种机器学习算法,代表以平均胸径为基础,其与其他特征变量可能构成的所有变量组合。
38.采用选择决定系数r2最高、均方根误差rmse最低的模型作为估算模型:其中,为监督值;为预测值;为样本均值;n为样本数量。
39.步骤s5:将所述森林小班的变量因子带入所述估算模型,获取小班碳储量,并对各个所述小班碳储量分县域加总,计算加总后的碳储量与上一年度碳储量的差值,得到各县森林碳汇量。
40.获取小班碳储量计算路径的类型分为:当所述估算模型中预测变量为生物量转扩因子,则结合活立木蓄积量、树种含碳系数计算得到小班碳储量;当所述估算模型中预测变量为生物量,则结合树种含碳系数计算得到小班碳储量;当所述估算模型中预测变量为碳储量,则无需再做进一步计算,得到小班碳储量。
41.以浙江省为例,进行浙江省各小班碳汇估算建模:数据来源于浙江省所有林业调查固定样地数据和全省林业图班数据。按照本发明筛选出符合要求的固定样地5420个和森林小班3140598个。计算出固定样地蓄积量、生物
量、碳储量。筛选并计算固定样地数据库和森林小班数据库中共有的特征变量。得到数据集如表1所示:表1数据集汇总表表2数据集汇总表(续表1)将数据集按照80:20比例随机分为4336个训练集和1084个测试集。将训练集输入模型对模型进行训练,通过验证集来验证模型的准确性。首先,用python语言编写基于机器学习算法的建模运行程序,将表1中的生物量转扩因子、生物量、碳储量密度作为监督值,其余作为模型输入备选。根据遍历建模,共建立4590个模型,筛选出预测精度最高的模型,参见图3-图4。
42.三个监督值精度最高的模型组合如表3所示。可见最优的估算模型是:监督值为生物量,算法为梯度提升+类别型特征catboost,变量组合为平均胸径,平均树高,郁闭度,植被覆盖度,立木株数/m2,龄组,蓄积量,树种组成。
43.表3最优建模路径
表4基于生物量最优预测模型的预测结果最后为将森林小班特征变量输入到最优的估算模型中,计算的森林小班的碳储量,并对两期碳储量相减获得碳汇量。
44.与前述一种基于机器学习的县域森林碳汇估算方法的实施例相对应,本发明还提供了一种基于机器学习的县域森林碳汇估算装置的实施例。
45.参见图5,本发明实施例提供的一种基于机器学习的县域森林碳汇估算装置,包括存储器和一个或多个处理器,所述存储器中存储有可执行代码,所述一个或多个处理器执行所述可执行代码时,用于实现上述实施例中的一种基于机器学习的县域森林碳汇估算方法。
46.本发明一种基于机器学习的县域森林碳汇估算装置的实施例可以应用在任意具备数据处理能力的设备上,该任意具备数据处理能力的设备可以为诸如计算机等设备或装置。装置实施例可以通过软件实现,也可以通过硬件或者软硬件结合的方式实现。以软件实现为例,作为一个逻辑意义上的装置,是通过其所在任意具备数据处理能力的设备的处理器将非易失性存储器中对应的计算机程序指令读取到内存中运行形成的。从硬件层面而言,如图5所示,为本发明一种基于机器学习的县域森林碳汇估算装置所在任意具备数据处理能力的设备的一种硬件结构图,除了图5所示的处理器、内存、网络接口、以及非易失性存储器之外,实施例中装置所在的任意具备数据处理能力的设备通常根据该任意具备数据处理能力的设备的实际功能,还可以包括其他硬件,对此不再赘述。
47.上述装置中各个单元的功能和作用的实现过程具体详见上述方法中对应步骤的实现过程,在此不再赘述。
48.对于装置实施例而言,由于其基本对应于方法实施例,所以相关之处参见方法实
施例的部分说明即可。以上所描述的装置实施例仅仅是示意性的,其中所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部模块来实现本发明方案的目的。本领域普通技术人员在不付出创造性劳动的情况下,即可以理解并实施。
49.本发明实施例还提供一种计算机可读存储介质,其上存储有程序,该程序被处理器执行时,实现上述实施例中的一种基于机器学习的县域森林碳汇估算方法。
50.所述计算机可读存储介质可以是前述任一实施例所述的任意具备数据处理能力的设备的内部存储单元,例如硬盘或内存。所述计算机可读存储介质也可以是任意具备数据处理能力的设备的外部存储设备,例如所述设备上配备的插接式硬盘、智能存储卡(smart media card,smc)、sd卡、闪存卡(flash card)等。进一步的,所述计算机可读存储介质还可以既包括任意具备数据处理能力的设备的内部存储单元也包括外部存储设备。所述计算机可读存储介质用于存储所述计算机程序以及所述任意具备数据处理能力的设备所需的其他程序和数据,还可以用于暂时地存储已经输出或者将要输出的数据。
51.以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1