基于Stacking算法的碳排放预测模型的构建和预测方法及介质与流程
基于stacking算法的碳排放预测模型的构建和预测方法及介质
技术领域
1.本发明属于人工智能应用领域,具体涉及碳排放预测技术领域,尤其涉及一种基于stacking算法的碳排放预测模型的构建和预测方法及介质。
背景技术:
2.碳排放所导致的气候变暖问题是世界各国面临的共同挑战,并提出了构建绿色低碳可持续发展体系,控制能源消费总量,提升能源利用效率,提高可再生能源消费占比等主要目标。因此,我们需要开展重点用能行业的能源消费特征研究,掌握重点行业及企业的碳排放情况和演化趋势,有针对性地开展碳减排潜力挖掘、碳减排服务等相关工作,为重点行业及企业实施节能降碳、提高资源利用效率提供支撑。目前,该部分工作主要面临以下几方面问题:
3.1)企业用能及碳排放数据难以实时、准确、全面掌握。目前仅少量重点用能企业建有能耗在线监测平台,但运行维护成本较高,且缺乏碳排放管理功能,无法对企业碳排放进行预测和预警;此外,仍有大量规模以上控排企业尚未建设能耗监测系统。对于政府监管部门及企业来说,难以实时、准确、全面地掌握企业的用能数据及碳排放数据,相关数据来源主要依据年度碳核查报告、统计年鉴等。
4.2)重点用能企业缺乏碳资产管理功能,未能充分挖掘碳减排潜力。目前重点用能企业对碳排放核算、碳资产管理、碳市场交易等方面的认知及知识储备仍较为缺乏,企业碳减排潜力未能得到有效挖掘,无法最经济、最有效地达到减排要求。
5.因此构建科学的碳排放模型对未来碳排放情况做出预测,对我国节能减排工作和可持续发展有重要的意义。
6.随着人工智能的发展,人们可以通过分析影响碳排放的因素,构建算法预测模型,提高模型预测的准确率。例如佟昕等人利用灰色模型gm(1,1)预测了中国2012-2020年碳排放量,根据预测结果得出中国的减排压力还很大。段福梅运用改进的bp神经网络模型,在8种发展模式下对中国碳排放峰值进行预测研宄,研究表明中国能在经济衰退模式、节能模式等模式下能实现2030年碳排放达峰目标。王珂珂等利用鲸鱼优化算法改国2019-2040年的碳排放量和碳排放强度,准确的反映了中国未来的碳排放趋势。杜强等建立碳排放量增长的logistic模型对2011年至2020年不同省份的二氧化碳排放量,通过与原始数据的对比,验证了logistic模型在co2排放预测问题上的精确性和较高的可信性。但目前常见的碳排放方法也存在一定问题,以上方法虽然能够对碳排放进行预测,但是单一模型显然缺乏对多模型、多机理的综合研究。
7.近些年,碳排放组合预测方法在国内也开始流行,例如张峰等人将传统灰色预测模型、系统云灰色预测模型和verhulst模型进行组合,该模型结合了单一模型的优点,运用组合灰色预测模型预测了山东省2013年至2017年间建筑业等行业co2排放量,结果表明该组合模型的预测精度高于单一模型。葛娜等人在2019年提出了一种基于prophet-lstm的时
间序列融合预测模型,通过对比实验,最终验证了模型融合在时间序列预测中具有更高的准确性。这些组合预测方法的预测效果要优于单一模型的预测效果,但在预测效果的精确度上仍有优化空间。
技术实现要素:
8.本发明目的之一在于提供了一种基于stacking算法的碳排放预测模型的构建和预测方法,通过使用stacking集成学习方法组合多种模型为预测模型,最后对组合模型进行改良与优化,得到预测精度更高的组合预测模型。
9.本发明解决上述技术问题的方案如下:一种基于stacking算法的碳排放预测模型的构建方法,包括以下步骤:
10.s1、获取电力数据以及电力数据对应的碳排放数据样本,形成数据集;
11.s2、对数据集进行预处理,按照预设比例将预处理后的数据集划分为训练集和测试集;训练集和测试集预设比例可以是2:8;
12.s3、使用xgboost算法分析影响碳排放的特征,进行特征选择,去除冗余特征,得到目标特征;
13.s4、构建碳排放预测模型,构建的碳排放预测模型包括元模型和多个基模型;
14.s5、使用stacking算法将元模型和多个基模型融合,基于训练集和目标特征对构建的碳排放预测模型进行训练,通过网格搜索的方式对元模型和各基模型的超参数进行参数寻优;
15.s6、基于测试集,根据各基模型输出的碳排放预测结果的误差占比,调整各基模型输入到元模型的预测结果的权重分配,得到训练好的碳排放预测模型。
16.优选的,上述方法步骤还包括s7:
17.s7、评估碳排放预测模型精确度,输入测试集进行预测,比对相应的碳排放数据样本,对预测结果进行分析。
18.优选的,所述s2中,对数据集的处理包括:
19.剔除数据集中的异常值,并补全数据集中的缺失值;针对补全缺失值后的数据集进行归一化处理。
20.由于电力数据通过关联模型获得而来,在特殊或者人为情况下,获取的电力数据可能会存在缺失值、异常值。因此在做碳排放预测时,对电力数据进行剔除异常值
21.和补全缺失值。在本发明中,我们主要采用均值和频率最高的数这两个统计信息来填补缺失值。
22.如果某一维数特征的数值比其它维数特征大几个数量级,那么它将主导机器学习模型的目标函数,使得模型无法学习其它维数的特征。而归一化处理可以使数据集中的每一维特征都被缩放为均值为0的数组,这样每一维特征都被缩放到同一个数量级,避免了机器学习模型训练时出现偏移。如果没有经过归一化处理,在训练模型的过程中会出现偏向数量级较大的特征的现象。
23.归一化处理的公式如下:
24.25.其中,x是初始数据,x
′
是处理后数据,x
min
表示初始数据中的最小值,x
max
表示初始数据中的最大值。
26.优选的,所述s3,包括以下步骤:
27.s31、将影响碳排放的特征输入到xgboost算法中,得到训练过程中提升决策树的增益情况;
28.s32、xgboost算法根据输入的特征对提升决策树的增益情况,对输入的特征进行评分,并选取为评分高的特征为目标特征。
29.xgboost算法可以根据训练过程中树的增益情况来对输入特征进行划分,去除一些重要性较低的冗余特征,使预测更加精确高效。
30.优选的,所述基模型通过选取多个算法模型输入电力数据进行碳排放预测,再根据差异度度量法对各算法模型的预测结果误差进行比较,选择差异度最大的三种算法模型确定;所述元模型包括xgboost。
31.优选的,所述基模型通过在gbdt、rf、svm、knn、lstm算法模型输入电力数据进行碳排放预测,再根据差异度度量法对各算法模型的预测结果误差进行比较,选择差异度最大的三种算法模型确定。
32.由于不同算法的数据观测角度和自身原理结构不同,选择差异度大的算法进行预测时能够使各个算法的优势最大化,有助于大幅度提高预测的精确度。
33.优选的,所述s6包括以下步骤:
34.s61、将基模型的预测结果输入到元模型;
35.s62、通过交叉验证计算基模型输出结果的误差,根据误差占比,对基模型输入到元模型的预测结果进行权重分配,得到构建好的碳排放预测模型。
36.赋权输出可使得精度高的预测值对预测结果的影响程度增大,而精度低的预测值对预测结果的影响程度减少。此方法不仅提高预测模型的精确度,还提升了预测模型的稳定性。
37.优选的,所述s7中,采用平均绝对百分比误差作为评估模型精确度标准。
38.基于stacking算法的碳排放预测模型的构建装置,所述装置包括:
39.第一获取模块,用于获取电力数据以及电力数据对应的碳排放数据样本,形成数据集;
40.预处理模块,用于对数据集进行预处理,按照预设比例将预处理后的数据集划分为训练集和测试集;
41.特征选择模块,用于通过xgboost算法分析影响碳排放的特征,进行特征选择,去除冗余特征,得到目标特征;
42.碳排放预测模型构建模块,用于构建碳排放预测模型,构建的碳排放预测模型包括元模型和多个基模型;
43.碳排放预测模型训练模块,用于通过stacking算法将元模型和多个基模型融合,基于训练集和目标特征对构建的碳排放预测模型进行训练,通过网格搜索的方式对元模型和各基模型的超参数进行参数寻优;
44.碳排放预测模型优化模块,用于基于测试集,根据各基模型输出的碳排放预测结果的误差占比,调整各基模型输入到元模型的预测结果的权重分配,得到训练好的碳排放
预测模型。
45.一种碳排放预测方法,所述方法包括:
46.获取待预测电力数据;
47.将所述待预测电力数据输入预先训练好的碳排放预测模型中,基于所述碳排放预测模型进行碳排放预测,得到碳排放预测结果;
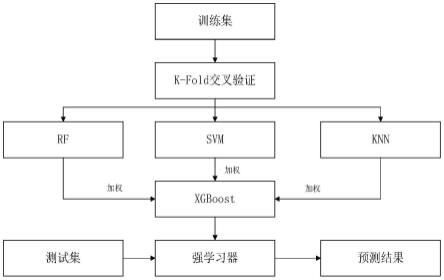
48.其中,所述碳排放预测模型由上述基于stacking算法的碳排放预测模型的构建方法构建得到。
49.一种碳排放预测装置,所述装置包括:
50.第二获取模块,用于获取待预测电力数据;
51.预测模块,用于将所述待预测电力数据输入预先训练好的碳排放预测模型中,基于所述碳排放预测模型进行碳排放预测,得到碳排放预测结果。
52.本发明的另一目的在于提供一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时实现如上所述的基于stacking算法的碳排放预测模型的构建方法。
53.一种电子设备,所述电子设备可读取如上所述计算机可读存储介质。
54.本发明的有益效果是:
55.1、本发明在特征工程时使用xgboost算法对特征重要性进行分析,有效地剔除了冗余的特征。
56.2、本发明在选择stacking模型的基模型时,使用了差异性度量方法来评价各个基模型的差异性。一方面stacking模型使用学习能力强的基模型时可以取得更加良好的预测效果。另一方面选择差异度较大的算法能够充分利用不同算法的优点,使得各个算法能够取长补短。相较于随机选择或者根据人工经验选择基模型,本发明选择差异性较大的基模型可以使预测获得更加良好的效果。
57.上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,并可依照说明书的内容予以实施,以下以本发明的较佳实施例并配合附图详细说明如后。本发明的具体实施方式由以下实施例及其附图详细给出。
附图说明
58.此处所说明的附图用来提供对本发明的进一步理解,构成本技术的一部分,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:
59.图1为本发明实施例1中基于stacking算法的碳排放预测模型的构建方法流程图;
60.图2为本发明实施例1中选择stacking算法的基模型的流程图。
具体实施方式
61.以下结合附图对本发明的原理和特征进行描述,所举实例只用于解释本发明,并非用于限定本发明的范围。
62.本发明的工作原理:发明主要利用经过改进的stacking集成算法,其中stacking集成算法是指将基模型的预测结果作为元模型的输入,将元模型的输出经过结合策略的整合作为最终的预测结果。
63.stacking算法通常比单个模型有着更好的预测表现,可是它也存在一定的缺陷,原始的stacking算法无法保证可以选择合适的基模型,且容易出现过拟合现象。如果模型选择不合适,或者由于数据类型等因素的影响,元模型可能获得比基模型更差的实验效果。本发明对stacking算法做了一些改进:相比于原始stacking算法中的根据人工经验选择的基模型,我们使用差异性度量法评价基模型是差异性,将差异性较大的基模型组合到一起以提高预测精度,并将基模型按照交叉验证的的误差的结果加权分配给元模型来减小预测误差。这虽然在一定程度上增加了训练时间,但是模型的泛化性能将得到提升。改进后的stacking算法克服了原始算法的缺陷,对于碳排放获得了更好的预测效果。
64.实施例1
65.如图1所示,选取陶瓷行业为试点,根据获取的福建省、湖北省建陶企业碳排放数据样本共25家进行分析,所用数据均由企业提供,建立碳排放预测模型,具体步骤如下:
66.s1、获取陶瓷企业的电力数据及电力数据对应的碳排放数据样本,形成数据集。
67.s2、对数据集进行处理,具体包括以下步骤:
68.s21、利用pandas工具对数据集中的异常值进行筛选及处理;
69.s22、使用单一变量特征填补方法来填补数据集中的缺失值,主要采用均值和频率最高的数的统计信息来填补缺失值,首先计算出特征中每个值出现的频率,如果存在出现频率较高的数值,则以该数来填补该特征的缺失值,否则以均值填补;
70.s23、在填补缺失值后,对数据集进行归一化处理,处理公式如下:
[0071][0072]
其中,x是初始数据,x
′
是处理后数据,x
min
表示初始数据中的最小值,x
max
表示初始数据中的最大值。
[0073]
s24、将处理好的电力数据的数据集按照比例进行划分为80%训练集与20%测试集。
[0074]
s3、使用xgboost算法分析影响碳排放的特征,进行特征选择,具体包括以下步骤;
[0075]
s31、将影响碳排放的特征输入到xgboost算法中,得到训练过程中提升决策树的增益情况;
[0076]
s32、xgboost算法根据输入的特征对提升决策树的增益情况,对输入的特征进行评分,并选取为评分高的特征为目标特征。
[0077]
陶瓷的能耗源主要是电力、煤、天然气和柴油,其中烧成工序能耗占比最大,占产品单位综合能耗60%以上,而原料生产工序与窑炉烧成工序的电能消耗则占企业总用电量的85%以上,经过特征选取后,影响本实施例能耗最大的因素分别是:烧成的窑型,烧成的温度、烧成的时间,燃料种类及品质也是重要的影响因素。
[0078]
s4、构建碳排放预测模型,具体包括以下步骤:
[0079]
s41、在gbdt、rf、svm、knn、lstm五个算法模型中输入电力数据进行碳排放预测;
[0080]
s42、采用pearson系数对各个模型的预测误差进行计算,以此分析不同基模型的差异度,具体选择过程如图2所示,各算法模型差异度分析如表1所示。由表1可知,svm、knn、rf的相关系数较低,因此模型差异度也最大,选择rf、knn、svm为stacking集成模型的基模型,然后选择xgboost作为元模型。
[0081]
表1
[0082] gbdtrfsvmknnlstmgbdt10.9230.6640.5970.688rf0.92310.5120.5570.587svm0.6640.51210.5370.684knn0.5970.5570.53710.712lstm0.6880.5870.6840.7121
[0083]
s5、使用stacking算法将各基模型和元模型融合,根据目标特征筛选训练集有效的数据,集成模型在筛选后的训练集上进行训练;并使用网格搜索对各基模型和元模型的超参数集进行寻优,各算法最优参数如表2所示。
[0084]
表2
[0085][0086][0087]
s6、优化模型,具体包括以下步骤:
[0088]
s61、将基模型的预测结果输入到元模型;
[0089]
s62、通过交叉验证计算基模型输出结果的误差,根据误差占比,对基模型输入到元模型的预测结果进行权重分配,公式如下:
[0090]
设第一层模型某个基模型测试集结果为(y1,y2,
…
,yn),计算误差为(x1,x2,
…
,xn),则其权重计算公式为
[0091]
[0092]
输出结果为(e1y1,e2y2,
…
,e
nyn
),各算法交叉验证误差如表3所示。
[0093]
根据各个模型交叉验证表现,设置svm权重为0.5,rf权重为0.3,knn权重为0.2。
[0094]
表3
[0095] errorrf0.1269svm0.0824knn0.1916
[0096]
s7、评估模型精确度,输入测试集进行预测,比对碳排放数据样本,选择平均绝对百分比误差(mape)作为模型评价指标。mape定义如下:
[0097][0098]
其中,x(i)和y(i)分别代表碳排放的实际值和预测值,n代表样本点的数量;
[0099]
经过对测试集的验证,各模型采用5折交叉验证的mape的平均结果如表4所示,本模型为1.59%,对于碳排放预测达到了较好的效果。
[0100]
表4
[0101] mape/%rf2.187svm1.972knn2.784融合模型1.59
[0102]
实施例2
[0103]
一种碳排放预测方法,所述方法包括:
[0104]
获取待预测电力数据;
[0105]
将所述待预测电力数据输入预先训练好的碳排放预测模型中,基于所述碳排放预测模型进行碳排放预测,得到碳排放预测结果;
[0106]
其中,所述碳排放预测模型由实施例1中基于stacking算法的碳排放预测模型的构建方法构建得到。
[0107]
实施例3
[0108]
一种基于stacking算法的碳排放预测模型的构建装置,所述装置包括:
[0109]
第一获取模块,用于获取电力数据以及电力数据对应的碳排放数据样本,形成数据集;
[0110]
预处理模块,用于对数据集进行预处理,按照预设比例将预处理后的数据集划分为训练集和测试集;
[0111]
特征选择模块,用于通过xgboost算法分析影响碳排放的特征,进行特征选择,去除冗余特征,得到目标特征;
[0112]
碳排放预测模型构建模块,用于构建碳排放预测模型,构建的碳排放预测模型包括元模型和多个基模型;
[0113]
碳排放预测模型训练模块,用于通过stacking算法将元模型和多个基模型融合,基于训练集和目标特征对构建的碳排放预测模型进行训练,通过网格搜索的方式对元模型和各基模型的超参数进行参数寻优;
[0114]
碳排放预测模型优化模块,用于基于测试集,根据各基模型输出的碳排放预测结果的误差占比,调整各基模型输入到元模型的预测结果的权重分配,得到训练好的碳排放预测模型。
[0115]
实施例4
[0116]
一种碳排放预测装置,所述装置包括:
[0117]
第二获取模块,用于获取待预测电力数据;
[0118]
预测模块,用于将所述待预测电力数据输入预先训练好的碳排放预测模型中,基于所述碳排放预测模型进行碳排放预测,得到碳排放预测结果。
[0119]
实施例5
[0120]
一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时实现如实施例1中的基于stacking算法的碳排放预测模型的构建方法。
[0121]
实施例6
[0122]
一种电子设备,所述电子设备可读取如实施例5中的计算机可读存储介质。
[0123]
以上所述,仅为本发明的较佳实施例而已,并非对本发明作任何形式上的限制;凡本行业的普通技术人员均可按说明书附图所示和以上所述而顺畅地实施本发明;但是,凡熟悉本专业的技术人员在不脱离本发明技术方案范围内,利用以上所揭示的技术内容而做出的些许更动、修饰与演变的等同变化,均为本发明的等效实施例;同时,凡依据本发明的实质技术对以上实施例所作的任何等同变化的更动、修饰与演变等,均仍属于本发明的技术方案的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1