核反应堆数字孪生关键参数自主优化数据反演方法
1.本发明涉及的是一种核反应堆控制领域的技术,具体是一种核反应堆关键参数自主优化数据反演方法。
背景技术:
2.数字孪生(digital twin)是以数字化方式创建物理实体的虚拟模型,充分利用物理模型、传感器、运行历史等数据,集成多学科、多尺度对物理实体在现实环境中的行为进行模拟的仿真过程。随着核电站智能监控技术的更新,核电站的数字孪生技术不断发展,有利于核电站以较低成本实现高可靠性、可用性与可维护性。为实现实时监测核电站运行状态并进行故障诊断,需要布置大量传感器,用于实时监测各项瞬态运行参数。然而大量的传感器产生的数据种类多、总量大,造成存储空间需求大、传输效率不高、数据分析复杂度高等问题,如何优化传感器的布置也需要进一步研究。目前核电领域常采用数据降维与反向求解的特征工程解决上述问题。数据降维是将原始数据转变为低维度的特征向量,从而提高数据传输与分析效率,也节约了存储空间。反向求解则通过使用降维后的数据求出对应的物理场分布与相应探测器的理论测量值,从而完成数据的反演。反演后的数据可用于状态监测、故障诊断、时序预测等。在核电站数字孪生引入数据的降维与复原方法,能够协助核电站运行操作人员更好地监测核电站数据与更高效地利用数据。但目前此类研究在特征提取上面临如下的问题:通过逐次实验的方式获取特征参数,依赖长期数据,运算量大、效率较低;采用主成分分析等方式进行数据压缩,在压缩过程中改变了原参数的值,虽然提升了传输效率且能达到很高精度,但也因此失去了特征参数的可解释性。原始数据中的部分数据对反演其他参数的影响更大,这部分数据具有单独研究的意义。如果能够找出并保留这部分数据,能更好地完成反应堆数字孪生虚拟空间与真实空间的交互,提升计算效率,从而抵抗反应堆探测器损坏与数据丢失的影响,也能使特征具有可解释性,为未来小型堆的探测器安装提供评判依据。
技术实现要素:
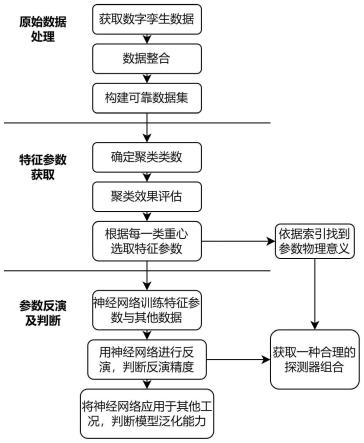
3.本发明针对现有技术为减少计算量,过度压缩原始数据导致得到的特征不具有可解释性;选取特征参数依赖长期的大量运行数据,效率低且随着运行工况的改变需要重新进行大量计算等不足,提出一种核反应堆数字孪生关键参数自主优化数据反演方法,搭建核反应堆数字孪生,使用轮廓系数(silhouette score)结合聚类算法确定范围内最佳聚类数,进行聚类,依据各聚类中心选择出反应堆数字孪生中的一部分特征参数,以特征参数作为输入,其他参数作为输出,搭建前馈—反向传播全连接神经网络并进行超参数搜索优化,从而在保留原有特征参数的情况下,获得特征参数的物理意义,并完成对其他参数的反演。该方法已应用于核反应堆数字孪生堆芯温度场的反演,并取得平均相对误差在0.2%以内的精度。
4.本发明是通过以下技术方案实现的:
5.本发明涉及一种核反应堆数字孪生关键参数自主优化数据反演方法,通过多物理场耦合数值模拟平台构建反应堆堆芯的数字孪生,将原始数据预处理得到可靠数据集后,用轮廓系数为指标对一定范围内的不同聚类数进行评价,选择最佳聚类数进行聚类,选取得到的最接近各个聚类中心的曲线对应的参数作为堆芯处具有典型温度变化特征的特征参数,获取特征参数的物理含义;搭建全连接神经网络,再通过搜索方法优化神经网络参数,训练神经网络,在在线阶段进行参数反演,得到其余参数的反演结果,通过特征参数的物理含义确认一组探测器位点,反演精度则代表该探测器组合在数字孪生系统中对温度场的重建效果。
6.本发明涉及一种实现上述方法的系统,包括:反应堆堆芯数据整理模块、聚类特征提取模块、神经网络训练及反演与评价模块,其中:反应堆堆芯数据整理模块根据核反应堆数字孪生数据进行提取和整合处理,得到可用于进一步划分和分析的可靠数据集,聚类特征提取模块通过轮廓系数法确定最佳聚类数,对堆芯数据进行聚类、特征提取与数据索引返回,得到特征参数、其物理含义和待反演的参数,神经网络训练及反演与评价模块根据特征参数与待反演参数,划分数据集为训练集、测试集和验证集,构建并训练神经网络,再将训练后的神经网络反演得到所有参数的反演结果,并与实际数据进行比较和评价,依据误差直方图判断反演效果。通过聚类特征提取模块获取特征参数的物理含义,结合特征参数在神经网络训练及反演与评价模块中的反演效果,即可得到特征参数对应的探测器位点组合对堆芯数字孪生系统温度场的重建效果。技术效果
7.本发明使用kmeans算法进行聚类,依据聚类中心选取特征参数,从而在保留原数据的情况下提取反应堆的特征参数,并能得到特征参数的物理意义,能够为未来小型堆的探测器安装提供评判依据;结合聚类与深度学习,实现对反应堆数字孪生温度参数的高效反演,精度较高,且有较大发展空间。
附图说明
1.图1为本发明流程图;
2.图2为实施例温度参数的降维与反演原理示意图;
3.图3为数据预处理示意图;
4.图4为堆芯温度反演预测值与实际值的比较示意图。
具体实施方式
5.如图1所示,为本实施例涉及的一种核反应堆关键参数自主高效数据反演方法,以堆芯冷却剂为例,通过将核反应堆数字孪生数据预处理得到可靠数据集后,通过轮廓系数指标确定一定范围内的最佳聚类数,进行聚类,选取得到的最接近各个聚类中心的曲线对应的参数作为堆芯冷却剂的特征参数,通过如图2所示的温度参数的降维与反演原理,搭建特征参数与非特征参数的之间的神经网络表达并使用反应堆20%热管失效工况下的堆芯冷却剂温度数据进行特征提取与参数反演,并用15%热管失效工况下的堆芯冷却剂数据测试神经网络的泛化性能。
6.所述的神经网络,为针对堆芯系统搭建的采用深度学习方法的前馈-反向传播全
连接神经网络,该网络通过搜索方法调试隐藏层、隐藏层节点、学习率,综合考虑验证集损失值的收敛速度和收敛值确定神经网络的结构与超参数。将神经网络得到的其他参数的拟合值(输出值)与其他参数的实际值比较得到误差,根据误差修正神经网络的权值,以逐步降低误差。在达到训练收敛后,将得到的神经网络应用于15%热管失效工况下的相同参数,根据真实值与实际值的误差判断反演精度。
7.如图3所示,所述的预处理是指:读取核反应堆数字孪生数据,即反应堆堆芯数字孪生系统的冷却剂数据后,组合得到数据集并剔除最初极小部分由于数据生成误差导致数值异常突变点的时间节点,剩下的数据仍可充分必要反应堆芯系统的温度分布;再使用归一化或标准化进行数据归约,得到可用于特征提取的可靠数据集。
8.所述的特征参数,即使通过聚类的方式细分预处理后的可靠数据集,使用轮廓系数指标确定一定范围内的最佳聚类数并聚类,得到多个簇类;最后构建每一类中特征参数到原数据集的索引,从而高效并良好地完成特征提取任务,将为未来对更多维度的数据进行特征提取提供借鉴,具体步骤包括:
9.1)先对400个堆芯冷却剂温度参数使用聚类算法;
10.2)以循环方式逐步增加聚类数,分别考察不同聚类数结果下的轮廓系数;
11.3)选取轮廓系数最大的聚类数进行聚类,依据每一类的聚类中心,以欧式距离计算最接近聚类中心的参数,存入特征列表;按照特征参数到原数据集的索引确定特征参数的物理含义。通过甄选的25个特征参数作为神经网络的输入,同时,剩下的375个非特征参数作为待反演的对象。
12.所述的训练集、验证集与测试集通过以下方式得到:从堆芯冷却剂的400种温度参数中选出25个温度参数。将这些特征参数进行整合与标记,得到特征数据集,其他参数则作为待反演的目标参数,然后将各参数的16748个时间节点按照接近75:15:10的比例进行划分,将20%热管失效工况下的堆芯温度数据集划分为训练集、验证集与测试集,将特征参数作为输入,进行训练。
13.所述的在线阶段进行参数反演是指:将参数反演模型应用于反应堆的堆芯温度时,以25个特征参数反演出375个参数,从而重建堆芯温度场。在线阶段的反演效果,结合离线阶段获取的特征参数,即可得到特征参数对应空间位点处的探测器对数字孪生数字系统温度场的重建效果。
14.经过具体实际实验,对堆芯冷却剂400个温度参数共16748个时间节点的数据,以25个特征参数反演375个参数。冷却剂温度参数的误差分布如图4所示。92.09%的反演值误差在
±
0.3%以内,98.67%的反演值误差在[-0.3%,0.9%],相对误差均方根不超过0.2%。以上结果表明,该参数反演模型能够使用原数据量1:16的数据对反应堆堆芯冷却剂温度场进行较高精度重建。该模型将可运用于反应堆数字孪生系统的数据分析,重点传输特征参数,提高数据传输效率;观察与分析特征参数变化,提高数据分析效率,并按需要使用该参数反演模型快速重建堆芯温度场,从而服务于反应堆实时运行的监控。同时,特征数据反映出的堆芯的数据变化特征,也为优化未来反应堆探测仪器布置提供依据。
[0015]
现有的相关参数反演技术中,运用主成分分析(pca)对25维数据压缩到4维,再通过高斯回归过程(gpr)对其进行复原的数据压缩与复原方法,结果的误差不超过0.1%;bp神经网络(bpnn)、思维进化算法优化的bp神经网络(rf-mea-bp)、量子遗传算法优化的bp神
经网络(rf-qga-bp)算法应用于核事故源项反演的测试平均相对误差分别为2.25%、1.63%、1.79%。
[0016]
与现有技术相比,本方法在保留原数据的情况下,使用聚类算法并以轮廓系数法作为聚类评价指标,能实现对反应堆堆芯系统温度特征参数的快速提取,并使提取到的低维特征具有可解释性;通过聚类算法自主甄选特征温度参数,结合搜索方法搭建与优化前馈—反向传播全连接神经网络,构建反应堆温度反演模型,且反演精度高于一般的bp神经网络。
[0017]
上述具体实施可由本领域技术人员在不背离本发明原理和宗旨的前提下以不同的方式对其进行局部调整,本发明的保护范围以权利要求书为准且不由上述具体实施所限,在其范围内的各个实现方案均受本发明之约束。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1