一种基于招聘需求相似度的职位推荐方法与流程
1.本发明涉及计算机软件领域,尤其涉及的是一种基于招聘需求相似度的职位推荐方法。
背景技术:
2.已有专利为申请号201710534021.5的“一种职位推荐方法及计算设备”。该方法通过职位共现信息筛选候选与目标职位共现次数较多的候选职位集合,然后利用lda主题模型、完全基于文本信息来计算招聘需求文本间的相似度,将候选职位中与目标职位的文本相似度大于某个阈值的职位推荐给当前用户。
3.另一个专利是申请号为202110661337.7的“一种职位推荐方法”,该方法根据用户的职位浏览序列训练深度学习模型(未利用文本信息),生成每个职位的特征向量表示,根据职位的特征向量相似度,来为用户推荐更多的职位。
4.现有技术存在的缺陷有:
5.1、缺少对用户在平台中的交互记录信息的利用,无法获取用户在本次求职时的真实求职意向。对文本信息的利用也不够充分,未充分挖掘文本信息与人才岗位匹配度之间的关联。
6.2、文本相似度高、但实际适合的候选人完全不同的jd,已有技术无法区分,会被同时推荐给一个候选人。文本相似度低、却实际适合同一类候选人的jd,已有技术无法发现它们之间的联系,不会将它们推荐给同一个候选人。
7.3、计算某一用户所适合职位的最相似的若干个职位进行职位推荐时,计算速度慢。
8.因此,现有技术存在缺陷,需要改进。
技术实现要素:
9.本发明所要解决的技术问题是:提供一种获取并满足求职者的真实求职意向、可以使那些职位需求很相似但实际上适合的候选人群完全不同的职位对应的特征向量的差异提高、使那些文本相似度较低但适合同一批候选人群的职位对应的特征向量的差异减小和相似度提高、以及效率更高、更适用于为用户提供实时服务的基于招聘需求相似度的职位推荐方法。
10.本发明的技术方案如下:一种基于招聘需求相似度的职位推荐方法,包括如下步骤:步骤s0:匹配预测模型构建阶段;其中,从个人简历、企业招聘需求中获取文本信息,并将获取的文本信息用来训练基于skip-gram model的word2vec模型;使用获取的文本信息、训练好的word2vec模型、以及收集到的简历和岗位的历史匹配信息,共同来训练基于textcnn+mlp的匹配预测模型;步骤s1:hnsw图构图阶段;其中,使用所述匹配预测模型为系统中所有的企业招聘需求计算特征向量,并使用得到的特征向量构建hnsw图;步骤s2:用户服务阶段;其中,获取适合求职者的岗位招聘需求,并根据该岗位招聘需求在构建好的hnsw
图中检索最相似的n个岗位,并将其推荐给该求职者,其中n为自然数。
11.应用于上述技术方案,所述的基于招聘需求相似度的职位推荐方法中,步骤s0中,在获取文本信息后,还对获取的文本信息进行分词、去停用词、去标点的文本预处理操作,得到预处理后的文本信息;并且,使用预处理后的文本信息,来训练基于skip-gram model的word2vec模型;并使用预处理后的文本信息、训练好的word2vec模型、以及收集到的简历和岗位的历史匹配信息,共同来训练基于textcnn+mlp的匹配预测模型。
12.应用于上述技术方案,所述的基于招聘需求相似度的职位推荐方法中,步骤s0中,是从系统中存储的所有个人简历、企业招聘需求中获取文本信息;其中,对于个人简历,从中提取出有关个人陈述、工作经历、项目经历的整段文本,并将这些段文本拼接为一段,作为个人简历文本信息;对企业招聘需求,从中提取出有关招聘需求的整段文本,并将这些文本拼接为一段,作为企业招聘需求文本信息。
13.应用于上述技术方案,所述的基于招聘需求相似度的职位推荐方法中,步骤s0中,在训练基于skip-gram model的word2vec模型时,skip-gram model的指定窗口大小win为2,word2vec模型在将每个词语转换为一个高维向量的维度记d为128。
14.应用于上述技术方案,所述的基于招聘需求相似度的职位推荐方法中,步骤s0中,在训练基于textcnn+mlp的匹配预测模型时,是从系统的历史数据中收集简历和岗位的成功匹配的历史匹配信息。
15.应用于上述技术方案,所述的基于招聘需求相似度的职位推荐方法中,步骤s0中,在收集简历和岗位的成功匹配的历史匹配信息后,将收集的成功匹配的数据作为样本正例,并按照1:1的正负样本比例随机采样出样本负例,最终正负样本混合在一起形成训练数据,并且,每一条训练数据都包括了一个个人简历文本信息、一个企业招聘需求文本信息和一个是否成功匹配的标识。
16.应用于上述技术方案,所述的基于招聘需求相似度的职位推荐方法中,步骤s1中,在使用所述匹配预测模型为系统中所有的企业招聘需求计算特征向量时,是将企业招聘需求的文本信息输入到所述匹配预测模型,从匹配预测模型中获取企业招聘需求的特征向量。
17.应用于上述技术方案,所述的基于招聘需求相似度的职位推荐方法中,步骤s1中,在使用得到的特征向量构建hnsw图时,是先构建nsw图,然后在nsw图的基础上构建hnsw图。
18.应用于上述技术方案,所述的基于招聘需求相似度的职位推荐方法中,步骤s2中,是根据求职者与系统的交互记录,获取适合该求职者的一个或多个岗位招聘需求。
19.应用于上述技术方案,所述的基于招聘需求相似度的职位推荐方法中,步骤s2中,具体是通过求职者投递并获得面试机会的岗位,并获取该岗位的文本信息作为适合该求职者的岗位招聘需求。
20.本发明的有益效果为:
21.1、充分利用求职者在平台上的交互信息,获取并满足求职者的真实求职意向。
22.2、利用文本数据、历史匹配数据和textcnn模型进行有监督学习,训练深度学习模型获取各个职位对应的特征向量,可以使那些职位需求很相似但实际上适合的候选人群完全不同的职位对应的特征向量的差异提高。使那些文本相似度较低但适合同一批候选人群的职位对应的特征向量的差异减小、相似度提高。
23.3、在计算一个职位的相似职位实现职位推荐时,采用hnsw快速检索算法,这样的设计比以往专利采用的排序方法的速度更快,效率更高、更适用于为用户提供实时服务。
附图说明
24.图1为本发明的流程示意图;
25.图2为本发明中skip-gram模型的原理示意图;
26.图3为本发明中基于skip-gram的word2vec模型的结构示意图;
27.图4为本发明中基于textcnn的匹配预测模型的结构示意图;
28.图5为本发明中textcnn的原理示意图;
29.图6为本发明中构建hnsw的结构示意图。
具体实施方式
30.以下结合附图和具体实施例,对本发明进行详细说明。
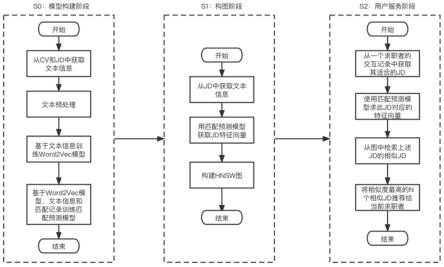
31.本实施例提供了一种基于招聘需求相似度的职位推荐方法,该方法使用包含3个阶段,分别为s0:模型构建阶段;s1:构图阶段;s2:用户服务阶段。s0模型构建阶段包含以下4个步骤,s0-0:从个人简历、企业招聘需求中获取文本信息。s0-1:对文本进行分词、去停用词、去标点等文本预处理操作,得到预处理后的文本。s0-2:使用预处理后的文本信息,来训练基于skip-gram model的word2vec模型。s0-3:使用预处理后的文本信息、训练好的word2vec模型、以及从平台中收集到的简历和岗位的历史匹配信息,共同来训练基于textcnn+mlp的匹配预测模型。s1构图阶段包含以下2个步骤,s1-0:使用上述匹配预测模型,为系统中所有的企业招聘需求计算特征向量。s1-1:使用上述所有企业招聘需求的特征向量,构建hnsw图。s2用户服务阶段包含两个步骤,s2-0:对于一个在找工作的求职者,根据其与系统的交互记录等信息,获取其适合的一个或多个岗位招聘需求。s2-1:使用该用户感兴趣的岗位招聘需求,在s1阶段中构建好的hnsw图里检索最相似的n个岗位,将这n个岗位推荐给该用户,其流程图如图1所示。
32.其中,本发明实施例中,涉及到的英文简写的中文含义如下:
33.cv:curriculum vitae,求职者提供的个人简历。
34.jd:job description,企业发布的企业招聘需求。
35.word2vec:word to vector,指将一个中文词语输入模型,模型输出能代表该词语语义的高维度向量。
36.textcnn:text convolutional neural network,文本卷积神经网络。
37.mlp:multilayer perceptron,多层感知机,即多层神经网络。
38.hnsw:hierarchical navigable small world graphs,分层可导航小世界图,一种可以快速检索目标节点的图结构。
39.本发明的具体实现方式如下:
40.1、s0:模型构建阶段;
41.(1)s0-0:从cv(个人简历)、jd(企业招聘需求)中提取文本;
42.此步骤用于从系统中存储的所有cv和jd中提取文本信息,输入是完整的cv和jd。对于cv,从中提取出有关个人陈述、工作经历、项目经历的整段文本,并将这些段文本拼接
为一段,作为cv文本信息。对于jd,从中提取出有关招聘需求的整段文本,并将这些文本拼接为一段,作为jd文本信息。
43.(2)s0-1:文本预处理;
44.此步骤用于对全部的cv文本信息和jd文本信息做预处理。对于每一个cv文本信息和jd文本信息,我们先根据句号、叹号、问号来分句。再对每个句子去除标点符号,通过编程自动化实现,找到各种标点符号并将标点符号用空格代替。接下来是分词操作,使用python编程语言中的名为“jieba”的工具包来自动实现分词操作。然后是去除停用词,将没有实际意义的词从文本中取出,比如“是”、“也”、“且”、“咱们”等常用的停用词。至此我们就预处理完毕了cv和jd的文本信息。处理后的信息我们简称为“cv文本”、“jd文本”,本说明下述内容中适用的“cv文本”、“jd文本”即指经过预处理后的cv和jd的文本信息。
45.(3)s0-2:训练word2vec模型;
46.此步骤用于使用上述处理好的cv文本和jd文本训练word2vec模型。此模型采用基于skip-gram模型的word2vec结构来进行训练。skip-gram模型的原理图如图2所示,首先需要指定窗口大小记为win,然后对于一个句子中的每个词,使用当前词语来预测他的前win个词语和后win个词语。简单来说,即使用当前词语来预测该词语周围的词语,从而学习到词语之间蕴含的语义关系。基于skip-gram的word2vec模型是一种通用的词向量表示模型,广泛应用于自然语言处理相关的研究中。
47.基于skip-gram的word2vec模型的结构图如图3所示,以“本人擅长机器学习算法实现”这句话为例,我们从第一个词开始逐个作为“中心词”来预测“周围词”。我们以中心词为“机器学习”为例,要使用图3所示的神经网络来预测其周围词有哪些。我们将所有词语组成的词库记为v,从而我们的词库中词语的种数为|v|,同时,因为word2vec模型会将每个词语转换为一个高维向量,我们将这个向量的维度记为d。则word2vec模型的工作步骤如下:
48.输入层:即one-hot编码层。one-hot编码指用一个长度为|v|的向量来表示文本,这个向量的每个维度分别代表词库中的v个词语,当前文本中包含的词语,在向量中对应的位置取值记为1,文本中不包含的词语对应的位置记为0。以本应用中的中心词“机器学习”为例,长度为|v|的向量中只有“机器学习”这个词对应的那一个维度的取值为1,其他维度取值为0。这样,中心词就转换为了一个维度是1*|v|的矩阵。
49.隐藏层:隐藏层由一个名为“词嵌入矩阵”的矩阵组成,用于将输入的词语转换为词向量,因为词向量的维度为d,为了达成这个目标,“词嵌入矩阵”的形状为|v|*d,我们将这个矩阵记为w1。使用输入的one-hot编码与w1矩阵相乘,即可获得一个1*d的向量,这个向量就是当前中心词的词向量。
50.输出层:输出层也是由一个参数矩阵组成,这个矩阵记为w2,这是一个d*|v|的矩阵。我们使用隐藏层输出的词向量与这个矩阵w2做矩阵乘法,即可得到一个1*|v|的向量。
51.输出结果:对输出层得到的1*|v|的向量经过一个softmax函数层,得到一个新的1*|v|的向量,这个向量各个维度的和等于1,向量的每个位置的取值代表该位置对应的词语出现的概率。比如如果“擅长”这个词位于one-hot编码中使用的1*|v|向量的第100位。如果输出结果中第100位的取值为0.3,那么说明模型预测当中心词为“机器学习”时,它的周围词中包含“擅长”的概率为0.3。
52.损失函数:我们采用交叉熵损失来作为损失函数的计算方法。设上述输出结果(1*
|v|的向量)中的每一个维度的取值为pi,我们取一个形状也是1*|v|的向量作为真实值向量,记为t,该向量中真实“周围词”对应的位置取1、其他位置取0。则交叉熵损失的计算方法为:逐步将训练数据输入模型计算上述损失函数,对需要更新的参数w1和w2求导,通过梯度下降的方式不断更新这两组参数的取值。
53.在本实施例中,win取2,d取128。
54.(4)s0-3:训练基于textcnn的匹配预测模型;
55.此步骤用于结合word2vec模型、textcnn模型和数据中的cv-jd匹配数据来训练一个匹配预测模型,此模型可以用于获取cv和jd的特征向量。
56.基于textcnn的匹配预测模型的结构如图4所示,分为以下步骤:
57.从系统的历史数据中收集cv和jd成果匹配的数据,成功匹配是指一个候选人(cv)投递了一个岗位(jd)并且通过了简历筛选获得了面试机会。这些成功匹配的数据作为样本正例。我们按照1∶1的正负样本比例随机采样出样本负例。最终正负样本混合在一起形成训练数据,每一条数据都包括了一个cv文本、一个jd文本和一个是否成功匹配的标识,其中,标识为匹配为1,不匹配取0。
58.对于每一条训练数据。将一个cv或jd的文本包含的句子拼接起来形成一整段文本,文本中的每个词语分别通过s0-2中训练好的word2vec模型转化为d维的词向量。假设一个cv或jd中包含的词语数量为x,则经word2vec模型处理后一个cv或jd文本转化为了一个x*d大小的矩阵。
59.将上述词向量矩阵作为textcnn模型的输入。textcnn模型采用16个卷积核,其中大小为1*d,2*d,3*d,
…
8*d的卷积核各2个。卷积后采用最大池化。最终textcnn会输出16维的cv的textcnn向量和16维的jd的textcnn向量。
60.采用skip-connection方法,即将cv的x*d大小的词向量对行求平均转化为d维的向量,然后与textcnn输出的向量拼接到一起,形成cv的特征向量。jd同理。经过这样的处理,cv和jd分别转为了144维的特征向量。
61.对cv、jd的特征向量计算余弦相似度。计算出的相似度取值作为模型预测的当前cv和jd能够达成匹配的概率。使用预测的概率、cv-jd是否成功匹配的真值(0或1)计算交叉熵损失函数。并使用反向传播的方法训练整个神经网络模型,更新textcnn的参数。
62.上述流程中未详细说明textcnn的卷积层、池化层的具体操作原理。图5为textcnn的原理示意图,本实施例以图5为例,说明textcnn的流程原理,本实施例中采用的textcnn与以下示例模型的区别仅在于卷积核的大小和个数。textcnn包含以下步骤:
63.输入数据:为上述流程中介绍的x*d大小的矩阵,x表示包含的词语数据,d表示词向量的维度,在图5示例中为讲解简便,取x=7,d=5。
64.卷积:使用大小不同的多个卷积核分别进行卷积操作。卷积核大小为n*d的矩阵,下图所示的第一个卷积核即为4*5的矩阵。n*d大小的卷积核对应的卷积操作是指,从输入的x*d的矩阵中,从上到下取n行,即截取一个n*d的矩阵,然后此矩阵与卷积核矩阵的对应位置相乘并累加求和,得到一个求和数字,此数字加上一个随机偏移量后再经过relu激活函数处理得到卷积结果;然后在x*d的输入矩阵中,将截取窗口下滑一格,即从第2行开始再截取一个n*d的矩阵,重复卷积操作得到求和结果。按此步骤,一个x*d的输入矩阵,使用n*d的卷积核,可以得到一个x-n+1长度的卷积结果向量。
65.池化:使用最大值池化方法,即对同一个卷积核生成的卷积向量,取其中的最大值,作为池化结果。
66.结果输出:将多个卷积核的池化结果拼接成一个向量输出,作为textcnn的输出。
67.2、s1:构图阶段;
68.(1)s1-0:计算所有jd的特征向量;
69.对所有jd,分别将其文本输入到s0-3的匹配预测模型中,并从模型中获取“jd的特征向量”并记录下来,其中,本实施例中为144维度的向量。
70.(2)s1-1:利用所有jd的特征向量构建hnsw;
71.构建hnsw图分为两个部分,第一部分为构建nsw图(navigable small world graphs),第二部分为在nsw的基础上构建hnsw图。
72.构建nsw图的流程如下,我们取最近邻的个数为3:
73.首先我们将需要建图的所有jd赋予唯一的id,根据id将jd排序,并将这些jd放置于“候选集合”中。接下来按照顺序逐一将jd放置在图中。
74.假设id为0,1,2,3
…
。
75.开始时,从候选集合中取第一个jd(id=0),直接放置于图中。
76.取jd 1,放置于图中,由于此时图中只有jd 0,因此jd 0即为其邻居节点,在图中添加一条连接jd 1和jd 0的边。
77.同理,取jd 2,添加jd 2到jd 1和jd 2到jd 0的边。
78.取jd 3,添加jd 3到jd 2、jd 3到jd 2以及jd 3到jd 0的边。
79.取jd 4,在图中已放置的节点中,选择3个与jd 4的特征向量相似度最大的3个jd,添加jd 4到这3个jd之间的边。
80.同jd 4,依次处理jd 5,jd 6
…
直到所有jd都被添加到图上。
81.通过上述步骤我们即可构建nsw图,nsw图用于检索是很高效的,比如如果我们此时有一个用户适合的jd x,我们首先使用匹配预测模型求jd x的特征向量。接下来想在图中寻找jd x最相似的jd是哪个。我们可以按照以下步骤寻找,假设要查找m个最相似的jd:
82.建立“已遍历集合”、“候选集合”、“结果集合”,初始值都为空;
83.随机找一个节点jd y作为初始节点,将jd y放入“已遍历集合”,将jd y及其与jd x的特征向量相似度放入“候选集合”。
84.对候选集合中的所有点,查找其邻居节点,若邻居节点在“已遍历集合”中则忽略,否则将这些邻居节点放入“已遍历集合”。
85.计算这些邻居节点到jd x的距离,并把这些邻居节点及其与jd x的距离放入“候选集合”。
86.对“候选集合”中的节点,根据其与jd x的相似度大小由大到小排序。
87.查看“结果集合”中的前m个点与排序后的“候选集合”中的前m个点是否完全一致,如果一致则结束迭代,这m个点即为最相似的m个jd,否则清空“结果集合”,把“候选集合”中的前m个点拷贝到“结果集合”中,回到第三步。
88.上述是nsw的流程,构建hnsw的结构如图6所示,最底层即为上述我们构建的nsw,我们指定hnsw为n层(图6即为3层),从最底层开始,用随机的方法选取部分节点,保留在第二层,依此类推,从第二层可生成第三层。节点之间的边的关系保持不变。最相似jd的查找
过程与nsw一致,初始点jd y取在hnsw的最顶层,在查找一个节点的邻居节点时,如果当前层没有其邻居,则需要到下一层进行查找。
89.其中,hnsw算法来源可以参考:
90.malkov,y.a.,&yashunin,d.a.(2018).efficient and robust approximate nearest neighbor search using hierarchical navigable small world graphs.ieee transactions on pattern analysis and machine intelligence,42(4),824-836.
91.3、s2:用户服务阶段;
92.(1)s2-0:通过交互记录获取求职者意向岗位;
93.将用户投递并获得面试机会的岗位作为他的真实意向岗位,获取该岗位的jd文本。
94.(2)s2-1:计算相似岗位并推荐给用户;
95.在s1中构建的图中查找和该jd文本最相似的m个jd,即所谓新的jd推荐给用户,其中m为自然数,可以根据实际应用场景设定。
96.以上为本发明的全部技术细节具体实现方式。
97.本发明可以解决以下技术问题:
98.1、获取候选人在一次求职中真实的求职意向,并根据真实意向进行职位推荐。具体而言,能够解决的技术问题包括:
99.(1)每个候选人可以适配的职位类型是多样的。如一个有丰富编程经验的测试开发工程师,简历可以适配的职位类别是测试工程师和软件开发工程师,该求职者本次求职想向软件开发方向寻求发展,而不想从事测试工程师工作。此时已有的职位推荐方法,会根据招聘需求与他的工作经历的匹配度,向他推荐测试工程师和软件开发两类岗位,而无法获知其真实求职意向并做出合理推荐。
100.(2)候选人求职新工作的动机是多样的。不喜欢当前职位类型、希望新的职业发展机会是其中重要的一类。比如一个初级产品运营经历,在求职时想向用户产品经理方向转型,已有职位推荐方法仅根据简历信息和招聘需求信息无法获取该求职者的真实意向,只会推荐产品运营类岗位。如何利用系统中的信息获知用户真实求职意向并做出推荐,是一个待解决的技术问题。
101.2、计算招聘需求之间真实的相似和不相似关系。具体而言,包含两类实际问题:
102.(1)许多只从招聘需求文本(jd)的文字上看区别较小、相似度很高的职位,对候选人的需求却差别很大。比如:算法工程师和资深算法工程师岗位,职位需求文本的大部分内容重合、差异体现在工作的熟练度和经验上,此时若仅通过职位需求文本的相似度进行推荐,这两类岗位可能会推荐给同一个候选人。但在推荐相似职位时,一个理想的模型中这两类职位的相似度应该较低。
103.(2)许多从招聘需求文本(jd)的文字上看差别比较大、相似度低的职位,适合的候选人却是一致的。不同jd书写的详细程度、写作风格不同,导致他们在文本上差别虽大、但实际招聘的岗位是一致的。比如:“要求候选人熟悉各类自然语言处理算法,熟悉对应的代码工具框架和代码实现”和“要求候选人熟悉文本处理方法,如分词、句法结构分析、情感倾向识别、自动问答算法等等,并能够熟练地编程实现”这两类表达在文本内容上差别较大,但实际上是在招聘同一类人才。在一个理想的相似职位推荐模型中,这两类职位的相似度
应该较高。
104.3、基于职位需求相似度的推荐,在推荐某个职位的相似职位时,需要计算全部的职位与该职位的相似度、并排序,具有计算时间长、实时性差的问题。本发明提供的解决方法,可以快速推荐相似职位,计算效率高、适合实时为用户服务。
105.与现有技术相比,本发明的优点是:
106.1、充分利用求职者在平台上的交互信息,获取并满足求职者的真实求职意向。
107.2、利用文本数据、历史匹配数据和textcnn模型进行有监督学习,训练深度学习模型获取各个职位对应的特征向量,可以使那些职位需求很相似但实际上适合的候选人群完全不同的职位对应的特征向量的差异提高。使那些文本相似度较低但适合同一批候选人群的职位对应的特征向量的差异减小、相似度提高。
108.3、在计算一个职位的相似职位实现职位推荐时,采用hnsw快速检索算法,这样的设计比以往专利采用的排序方法的速度更快,效率更高、更适用于为用户提供实时服务。
109.以上仅为本发明的较佳实施例而已,并不用于限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1