一种软件缺陷预测模型解释方法
1.本发明涉及一种软件缺陷预测模型解释方法,属于软件工程中的软件分析及缺陷预测技术领域。
背景技术:
2.软件缺陷预测技术诞生于20世纪70年代,主要作用是为了降低软件的测试成本,同时进一步保障软件的开发质量。现代软件开发项目倾向于以快速周期发布软件产品,为了确保所有新提交的质量,开发人员需要在将代码合并到发布分支之前进行代码审查并提供反馈。然而,这样的代码审查活动仍然是耗时且昂贵的。因此,由于有限的软件质量保证(sqa)资源,对所有提交执行详尽的代码审查活动是不可行的。因此提出了软件缺陷预测方法,用于得出软件最有可能出现缺陷的位置、并着重检查,大大提高了效率。然而,由于用户和测试人员只能知道软件是否预测为有缺陷,但并不明白为什么将软件预测为有缺陷。这使得用户无法信任这个预测,这种缺乏解释的预测可能会导致决策和政策制定中的严重错误。
3.现有技术关于对软件缺陷预测的解释设计中,lime算法是最早提出且应用最为广泛的解释算法,但是由于lime算法是通过随机扰动方法来生成待解释实例的合成邻域集合,而随机扰动方法可能会产生与待解释的实例不相似的合成邻域集合,这将导致局部模型不能准确地逼近全局模型的预测。并且由于随机扰动方法的不稳定性,lime也不适用于一些高维稀疏数据集。
技术实现要素:
4.本发明所要解决的技术问题是提供一种软件缺陷预测模型解释方法,采用全新分析逻辑设计,通过与模型无关解释方法给出软件缺陷预测的解释,并结合改进筛选策略,获得较少冗余且精简的解释,高效实现对目标软件预测结果的解释。
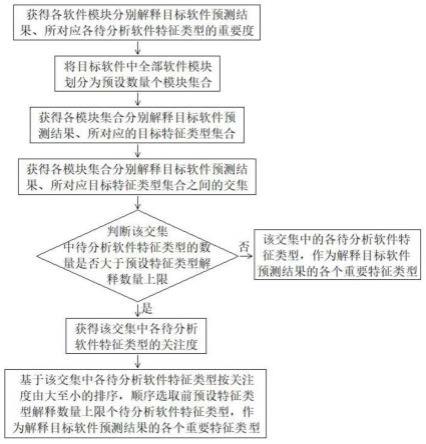
5.本发明为了解决上述技术问题采用以下技术方案:本发明设计了一种软件缺陷预测模型解释方法,用于针对目标软件所对应是否有缺陷的预测结果,基于目标软件中的各个软件模块,实现对目标软件预测结果的解释,包括如下步骤:
6.步骤a.分别针对各个软件模块,将软件模块作为待分析软件模块,执行如下步骤a1至步骤a4,获得待分析软件模块解释目标软件预测结果、对应各待分析软件特征类型的权重系数,进而获得各软件模块分别解释目标软件预测结果、所对应各待分析软件特征类型的重要度,实现对目标软件预测结果的解释;
7.步骤a1.基于待分析软件模块对应预设各待分析软件特征类型的特征数据,获得待分析软件模块所对应的合成邻域集合,然后进入步骤a2;
8.步骤a2.基于实现软件缺陷预测的黑盒模型所对应预训练好以软件模块对应预设各待分析软件特征类型的特征数据为输入、软件模块对应是否有缺陷预测结果为输出的缺陷模型,针对合成邻域集合中各个软件模块分别进行处理,获得合成邻域集合中各软件模
块分别对应是否有缺陷的预测结果,然后进入步骤a3;
9.步骤a3.基于合成邻域集合中各软件模块分别对应预设各待分析软件特征类型的特征数据、以及各软件模块分别对应是否有缺陷的预测结果,以软件模块对应预设各待分析软件特征类型的特征数据为输入、软件模块对应是否有缺陷预测结果为输出,针对用于替代步骤a2中黑盒模型的白盒模型进行训练,获得基于局部规则的回归模型,然后进入步骤a4;
10.步骤a4.提取基于局部规则的回归模型中对应各待分析软件特征类型分别的系数,构成待分析软件模块解释目标软件预测结果、所对应各待分析软件特征类型的权重系数。
11.作为本发明的一种优选技术方案:还包括步骤b至步骤e,执行完步骤a之后进入步骤b;
12.步骤b.将目标软件中全部软件模块划分为预设数量个模块集合,获得各模块集合分别解释目标软件预测结果、所对应的目标特征类型集合,然后进入步骤c;
13.步骤c.获得各模块集合分别解释目标软件预测结果、所对应目标特征类型集合之间的交集,并判断该交集中待分析软件特征类型的数量是否大于预设特征类型解释数量上限,是则进入步骤d,否则该交集中的各待分析软件特征类型,作为解释目标软件预测结果的各个重要特征类型,实现对目标软件预测结果的解释;
14.步骤d.获得该交集中各待分析软件特征类型分别在全部模块集合分别解释目标软件预测结果、所对应目标特征类型集合中出现的次数,作为该交集中各待分析软件特征类型的关注度,然后进入步骤e;
15.步骤e.基于该交集中各待分析软件特征类型按关注度由大至小的排序,顺序选取前预设特征类型解释数量上限个待分析软件特征类型,作为解释目标软件预测结果的各个重要特征类型,实现对目标软件预测结果的解释。
16.作为本发明的一种优选技术方案:所述步骤b中分别针对各模块集合,执行如下步骤b1至步骤b2,获得模块集合解释目标软件预测结果、所对应的目标特征类型集合,进而获得各模块集合分别解释目标软件预测结果、所对应的目标特征类型集合;
17.步骤b1.基于模块集合中各软件模块分别解释目标软件预测结果、所对应各待分析软件特征类型的权重系数,分别针对各待分析软件特征类型,获得该模块集合中各软件模块分别对应待分析软件特征类型的权重系数之和,进而获得该模块集合解释目标软件预测结果、各待分析软件特征类型的重要性系数,然后进入步骤b2;
18.步骤b2.基于该模块集合解释目标软件预测结果、各待分析软件特征类型的重要性系数,按重要性系数由大至小,针对各待分析软件特征类型进行排序,顺序选择前个待分析软件特征类型,构成该模块集合解释目标软件预测结果、所对应的目标特征类型集合;其中,m表示待分析软件特征类型的数量,b表示预设第二百分比,表示向上取整。
19.作为本发明的一种优选技术方案:所述步骤a1包括如下步骤a1-1至步骤a1-2;
20.步骤a1-1.基于预设包含各标准软件模块的训练数据集,根据软件模块对应预设各待分析软件特征类型的特征数据,获得训练数据集中各软件模块分别与待分析软件模块
之间的欧氏距离,并选出欧式距离由小至大排序中、前个欧式距离分别对应的标准软件模块,结合待分析软件特征类型,构成待分析软件模块所对应的实际邻域集合,然后进入步骤a1-2;其中,l表示训练数据集中标准软件模块的数量,a表示预设第一百分比,表示向上取整;
21.步骤a1-2.获得实际邻域集合中各组分别由三个不同软件模块构成的组合,基于该各组组合,选择其中至少一组组合,分别基于所选各组组合,通过交叉变异方法获得组合所对应的新软件模块,进而获得所选各组组合分别对应的新软件模块;然后将各个新软件模块加入实际邻域集合中,构成待分析软件模块所对应的合成邻域集合。
22.作为本发明的一种优选技术方案:所述步骤a1-1中,基于预设包含各标准软件模块的训练数据集,根据软件模块对应预设各待分析软件特征类型的特征数据,按如下公式:
[0023][0024]
获得训练数据集中各软件模块分别与待分析软件模块之间的欧氏距离,其中,xk、xe分别表示软件模块对应预设各待分析软件特征类型的特征数据组成的向量,[dist(xk,xe)]2表示xk与xe之间的距离的平方,exp(
·
)是以自然常数e为底的指数函数,δ表示核宽度,δ等于待分析软件特征类型数量与0.75乘积,k(xk,xe)表示xk与xe之间的欧氏距离。
[0025]
作为本发明的一种优选技术方案:所述步骤a1-2中,分别基于所选各组组合,按如下公式:
[0026]
x
crossover
=x1+(x
2-x1)*a
[0027]
x
mutation
=x1+(x
2-x3)*b
[0028]
通过交叉变异方法获得组合所对应的新软件模块,其中,x1、x2、x3分别表示组合中的软件模块,a、b分别表示0至0.5之间的随机数,x
crossover
表示组合软件模块x1、x2、x3通过交叉法生成的新软件模块,x
mutation
表示组合软件模块x1、x2、x3通过变异法生成的新软件模块。
[0029]
作为本发明的一种优选技术方案:所述步骤a2中实现软件缺陷预测的黑盒模型为随机森林模型。
[0030]
作为本发明的一种优选技术方案:所述步骤a3中用于替代步骤a2中黑盒模型的白盒模型为rulefit模型。
[0031]
作为本发明的一种优选技术方案:所述各待分析软件特征类型包括公共属性的数量nopa、私有属性的数量nopra、继承的属性数量noai、继承树的深度dit、对象之间的耦合度cbo、每个类的加权方法wmc、类的响应rfc。
[0032]
本发明所述一种软件缺陷预测模型解释方法,采用以上技术方案与现有技术相比,具有以下技术效果:
[0033]
本发明所设计一种软件缺陷预测模型解释方法,针对目标软件所对应是否有缺陷的预测结果,首先基于对目标软件中各软件模块对应各待分析软件特征类型的特征数据,结合对各软件模块的是否缺陷的预测结果,获得各软件模块分别解释目标软件预测结果、所对应各待分析软件特征类型的重要度;然后基于对全部软件模块向各模块集合的划分,获得各模块集合分别解释目标软件预测结果、所对应的目标特征类型集合;最后基于各模块集合所对应目标特征类型集合之间的联系,获得解释目标软件预测结果的各个重要特征
类型,实现对目标软件预测结果的解释;设计借助改良的与模型无关解释方法,解决了现有与模型无关解释方法在高纬稀疏数据集中很可能无法生成与待解释实例相似的合成邻域集合从而导致解释不准确的问题,并结合设计筛选方法,构造出更完整的解释方法,使得生成的解释更加容易被用户接受和理解,同时还节省了用户的时间。
附图说明
[0034]
图1是本发明设计软件缺陷预测模型解释方法的流程示意图;
[0035]
图2是本发明设计中步骤a的流程示意图。
具体实施方式
[0036]
下面结合说明书附图对本发明的具体实施方式作进一步详细的说明。
[0037]
本发明设计了一种软件缺陷预测模型解释方法,用于针对目标软件所对应是否有缺陷的预测结果,基于目标软件中的各个软件模块,实现对目标软件预测结果的解释,实际应用当中,如图1所示,具体执行包括如下步骤。
[0038]
步骤a.分别针对各个软件模块,将软件模块作为待分析软件模块,如图2所示,执行如下步骤a1至步骤a4,获得待分析软件模块解释目标软件预测结果、对应各待分析软件特征类型的权重系数,进而获得各软件模块分别解释目标软件预测结果、所对应各待分析软件特征类型的重要度,然后进入步骤b。
[0039]
步骤a1.基于待分析软件模块对应预设各待分析软件特征类型的特征数据,按如下步骤a1-1至步骤a1-2,获得待分析软件模块所对应的合成邻域集合,然后进入步骤a2。
[0040]
步骤a1-1.基于预设包含各标准软件模块的训练数据集,根据软件模块对应预设各待分析软件特征类型的特征数据,按如下公式:
[0041][0042]
获得训练数据集中各软件模块分别与待分析软件模块之间的欧氏距离,并选出欧式距离由小至大排序中、前个欧式距离分别对应的标准软件模块,结合待分析软件特征类型,构成待分析软件模块所对应的实际邻域集合,然后进入步骤a1-2;其中,l表示训练数据集中标准软件模块的数量,a表示预设第一百分比,表示向上取整,xk、xe分别表示软件模块对应预设各待分析软件特征类型的特征数据组成的向量,[dist(xk,xe)]2表示xk与xe之间的距离的平方,exp(
·
)是以自然常数e为底的指数函数,δ表示核宽度,δ等于待分析软件特征类型数量与0.75乘积,k(xk,xe)表示xk与xe之间的欧氏距离。
[0043]
步骤a1-2.获得实际邻域集合中各组分别由三个不同软件模块构成的组合,基于该各组组合,选择其中至少一组组合,分别基于所选各组组合,按如下公式:
[0044]
x
crossover
=x1+(x
2-x1)*a
[0045]
x
mutation
=x1+(x
2-x3)*b
[0046]
通过交叉变异方法获得组合所对应的新软件模块,进而获得所选各组组合分别对应的新软件模块;然后将各个新软件模块加入实际邻域集合中,构成待分析软件模块所对应的合成邻域集合;其中,x1、x2、x3分别表示组合中的软件模块,a、b分别表示0至0.5之间的
随机数,x
crossover
表示组合软件模块x1、x2、x3通过交叉法生成的新软件模块,x
mutation
表示组合软件模块x1、x2、x3通过变异法生成的新软件模块。
[0047]
实际应用中,这里各待分析软件特征类型包括公共属性的数量nopa、私有属性的数量nopra、继承的属性数量noai、继承树的深度dit、对象之间的耦合度cbo、每个类的加权方法wmc、类的响应rfc。
[0048]
步骤a2.基于实现软件缺陷预测的黑盒模型所对应预训练好以软件模块对应预设各待分析软件特征类型的特征数据为输入、软件模块对应是否有缺陷预测结果为输出的缺陷模型,针对合成邻域集合中各个软件模块分别进行处理,获得合成邻域集合中各软件模块分别对应是否有缺陷的预测结果,然后进入步骤a3。实际应用中,这里的黑盒模型,具体选择随机森林模型。
[0049]
步骤a3.基于合成邻域集合中各软件模块分别对应预设各待分析软件特征类型的特征数据、以及各软件模块分别对应是否有缺陷的预测结果,以软件模块对应预设各待分析软件特征类型的特征数据为输入、软件模块对应是否有缺陷预测结果为输出,针对用于替代步骤a2中黑盒模型的白盒模型进行训练,获得基于局部规则的回归模型,然后进入步骤a4。实际应用中,这里的白盒模型,具体选择rulefit模型,rulefit模型是一个结合了树集成和线性模型的分类器,它允许我们像传统的回归模型一样解释模型,同时理解从规则特性中学到的逻辑原因。
[0050]
步骤a4.提取基于局部规则的回归模型中对应各待分析软件特征类型分别的系数,构成待分析软件模块解释目标软件预测结果、所对应各待分析软件特征类型的权重系数。
[0051]
步骤b.将目标软件中全部软件模块划分为预设数量个模块集合,分别针对各模块集合,执行如下步骤b1至步骤b2,获得模块集合解释目标软件预测结果、所对应的目标特征类型集合,进而获得各模块集合分别解释目标软件预测结果、所对应的目标特征类型集合,然后进入步骤c。
[0052]
步骤b1.基于模块集合中各软件模块分别解释目标软件预测结果、所对应各待分析软件特征类型的权重系数,分别针对各待分析软件特征类型,获得该模块集合中各软件模块分别对应待分析软件特征类型的权重系数之和,进而获得该模块集合解释目标软件预测结果、各待分析软件特征类型的重要性系数,然后进入步骤b2。
[0053]
步骤b2.基于该模块集合解释目标软件预测结果、各待分析软件特征类型的重要性系数,按重要性系数由大至小,针对各待分析软件特征类型进行排序,顺序选择前个待分析软件特征类型,构成该模块集合解释目标软件预测结果、所对应的目标特征类型集合;其中,m表示待分析软件特征类型的数量,b表示预设第二百分比,表示向上取整。
[0054]
步骤c.获得各模块集合分别解释目标软件预测结果、所对应目标特征类型集合之间的交集,并判断该交集中待分析软件特征类型的数量是否大于预设特征类型解释数量上限,是则进入步骤d,否则该交集中的各待分析软件特征类型,作为解释目标软件预测结果的各个重要特征类型,实现对目标软件预测结果的解释。
[0055]
步骤d.获得该交集中各待分析软件特征类型分别在全部模块集合分别解释目标软件预测结果、所对应目标特征类型集合中出现的次数,作为该交集中各待分析软件特征
类型的关注度,然后进入步骤e。
[0056]
步骤e.基于该交集中各待分析软件特征类型按关注度由大至小的排序,顺序选取前预设特征类型解释数量上限个待分析软件特征类型,作为解释目标软件预测结果的各个重要特征类型,实现对目标软件预测结果的解释。
[0057]
实际应用中,上述技术方案针对目标软件所对应是否有缺陷的预测结果,首先基于对目标软件中各软件模块对应各待分析软件特征类型的特征数据,结合对各软件模块的是否缺陷的预测结果,获得各软件模块分别解释目标软件预测结果、所对应各待分析软件特征类型的重要度;然后基于对全部软件模块向各模块集合的划分,获得各模块集合分别解释目标软件预测结果、所对应的目标特征类型集合;最后基于各模块集合所对应目标特征类型集合之间的联系,获得解释目标软件预测结果的各个重要特征类型,实现对目标软件预测结果的解释;设计借助改良的与模型无关解释方法,解决了现有与模型无关解释方法在高纬稀疏数据集中很可能无法生成与待解释实例相似的合成邻域集合从而导致解释不准确的问题,并结合设计筛选方法,构造出更完整的解释方法,使得生成的解释更加容易被用户接受和理解,同时还节省了用户的时间。
[0058]
上面结合附图对本发明的实施方式作了详细说明,但是本发明并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下做出各种变化。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1