一种图文合规的检测与过滤方法与流程
1.本发明涉及的是多模态分类技术领域,具体涉及一种图文合规的检测与过滤方法。
背景技术:
2.通常在不同的网络平台上进行留言评论发文都需要遵守平台的规则和法律法规,但是人工审核的工作量是巨大的,同时由于汉字语义博大精深,配合不同的图片会产生不同的表达含义,有些内容并不符合平台规则和相关法律法规。尤其是一些特殊场景下文字和图片分开阅读是合规的,但是合并到一起时是不合规的,这样的内容是需要被算法模块识别过滤的。
3.我们的方法是将多张图片和文字分别进行编码,然后使用自注意力机制进行增强表达能力,编码图像的过程中按照图片顺序进行编号分别与多张图片的编码进行拼接;对文本也进行编码获得向量,再对文本和图片向量进行联合编码,同时基于注意力机制使用文本向量增强图片向量,最后将相关向量拼接接入全连接网络。本发明的图文合规的检测与过滤方法,在不显著增加计算成本的情况下,增加了识别的有效率和准确率;有效在保障了识别效果的前提下,大大节省了人工成本。
技术实现要素:
4.针对现有技术上存在的不足,本发明目的是在于提供一种图文合规的检测与过滤方法,充分使用图片和文字交互挖掘出更多的特征用来判断内容是否合规,实现内容过滤的目的。
5.为了实现上述目的,本发明是通过如下的技术方案来实现:一种图文合规的检测与过滤方法,包括以下步骤:
6.1、图片编码器:使用resnet网络架构提取图片特征,得到一个多通道的卷积特征图;
7.2、文本编码器:首先使用word2vec得到词向量,使用lstm提取文本特征,得到一组文本向量;
8.3、自注意力模块:使用自注意力机制使向量自身表达得到一定程度的强化,同时使用跨层链接将两种向量累加起来,自注意力模块公式如下:
9.self-attention的输入用矩阵x进行表示,则可以使用线性变阵矩阵wq,wk,wv计算得到q,k,v。
[0010][0011]dk
是q,k矩阵的列数,即向量维度,
[0012]
公式中计算矩阵q和k每一行向量的内积。多头注意力机制就是将多个结果进行拼
接。
[0013]
4、注意力模块:针对图像特征,注意力机制中的q,k,v向量中的q使用文本向量,k和v使用图像向量,使用文本向量强化图像特征图的表达;针对文本特征,注意力机制中的q,k,v向量中的q使用图像特征,k和v使用文本向量。通过跨模态的向量强化自身有利于挖掘出更多的特征。
[0014]
5、将自注意力机制得到的图片卷积特征图,通过注意力模块得到的卷积特征图,自注意力机制得到的文本向量,通过注意力模块得到的文本向量进行拼接,接入全连接层得到二分类结果。
[0015]
本发明具有以下有益效果:
[0016]
本发明在多模态分类数据集上获得较高的准确率,继而体现出本发明的有效性;针对社交平台上存在的不良信息问题提出的图文过滤方法有效过滤不良信息,净化网络环境。基于此,本发明能明显能够有效利用多种模态的数据提高识别准确率。
附图说明
[0017]
下面结合附图和具体实施方式来详细说明本发明;
[0018]
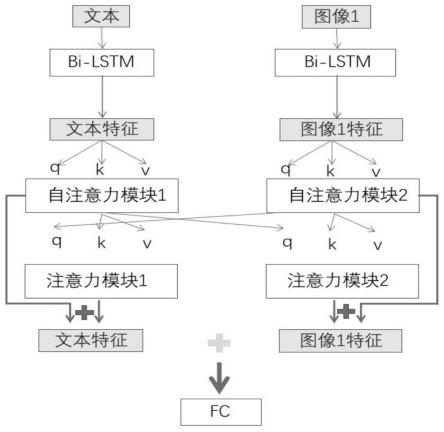
图1为本发明针对一段文本和一张图片的模型示意图;
[0019]
图2为本发明针对一段文本和多张图片的模型示意图;
[0020]
图3为本发明的self-attention的输入用矩阵x示意图。
具体实施方式
[0021]
为使本发明实现的技术手段、创作特征、达成目的与功效易于明白了解,下面结合具体实施方式,进一步阐述本发明。
[0022]
本具体实施方式采用以下技术方案:一种图文合规的检测与过滤方法,包括以下步骤:
[0023]
1、图片编码器:使用resnet网络架构提取图片特征,得到一个多通道的卷积特征图;
[0024]
2、文本编码器:首先使用word2vec得到词向量,使用lstm提取文本特征,得到一组文本向量;
[0025]
3、自注意力模块:使用自注意力机制使向量自身表达得到一定程度的强化,同时使用跨层链接将两种向量累加起来,自注意力模块公式如下:
[0026]
self-attention的输入用矩阵x进行表示,则可以使用线性变阵矩阵wq,wk,wv计算得到q,k,v。计算如图3所示,注意x,q,k,v的每一行都表示一个单词。
[0027][0028]dk
是q,k矩阵的列数,即向量维度,公式中计算矩阵q和k每一行向量的内积。多头注意力机制就是将多个结果进行拼接。
[0029]
s4.注意力模块:针对图像特征,注意力机制中的q,k,v向量中的q使用文本向量,k和v使用图像向量,使用文本向量强化图像特征图的表达;针对文本特征,注意力机制中的
q,k,v向量中的q使用图像特征,k和v使用文本向量。通过跨模态的向量强化自身有利于挖掘出更多的特征。
[0030]
s5.将自注意力机制得到的图片卷积特征图,通过注意力模块得到的卷积特征图,自注意力机制得到的文本向量,通过注意力模块得到的文本向量进行拼接,接入全连接层得到二分类结果。
[0031]
本具体实施方式的一种图文合规的检测与过滤方法在开源数据集上获得很好的准确率,继而体现出本发明的有效性;基于此,本发明能明显提高图文混合情况下不合规识别的准确率。
[0032]
实施例1:(单文本单图像)
[0033]
本实施例中,一种图文合规的检测与过滤方法,以社交平台作为业务场景,使用我们的方法大幅提高不合规图文信息识别的准确率,具体的说,如图1所示,是按如下步骤进行:
[0034]
s1.初始化resnet,bi-lstm等结构。
[0035]
s2.使用resnet网络架构提取图片特征,得到一个多通道的卷积特征图。
[0036]
s2.将文本通过word2vec使用lstm提取文本特征,得到一组向量。
[0037]
s3.自注意力模块。使用自注意力机制使向量自身表达得到一定程度的强化,同时使用跨层链接将两种向量累加起来,
[0038]
s4.对于文本向量的注意力模块,q采用图像1特征向量,k和v采用文本向量;对于图像1向量的注意力模块,q采用文本特征向量,k和v采用图像1特征向量。将新的文本特征向量和原文本特征向量进行累加,将新的图像特征向量和原图像特征向量进行累加。
[0039]
s5.将以上向量拼接放入全连接模块fc进行分类。
[0040]
实施例2:(单文本多图像)
[0041]
本实施例中,一种图文合规的检测与过滤方法,以社交平台作为业务场景,使用我们的方法大幅提高不合规图文信息识别的准确率,具体的说,如图1所示,是按如下步骤进行:
[0042]
s1.初始化resnet,bi-lstm等结构。
[0043]
s2.使用resnet网络架构提取图片特征,得到一个多通道的卷积特征图。
[0044]
s2.将文本通过word2vec使用lstm提取文本特征,得到一组向量。
[0045]
s3.自注意力模块。使用自注意力机制使向量自身表达得到一定程度的强化,同时使用跨层链接将两种向量累加起来,
[0046]
s4.对于文本向量的注意力模块,q采用图像1特征向量,k和v采用文本向量;对于图像1-n向量的注意力模块,q采用文本特征向量,k和v采用图像1-n特征向量。将新的文本特征向量和原文本特征向量进行累加,将新的图像特征向量和原图像特征向量进行累加。
[0047]
s5.将以上所有的向量拼接放入全连接模块fc进行分类。
[0048]
以上显示和描述了本发明的基本原理和主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护范围由所附的权利要求书及其等效物界定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1