一种用于遥感影像语义生成的视觉特征增强方法
1.本发明属于遥感图像应用技术领域,特别是涉及一种用于遥感影像语义生成的视觉特征增强方法。
背景技术:
2.随着遥感技术的发展以及人类对遥感影像利用的高效性和时效性的要求,研究者提出不同的智能化方法处理遥感影像。遥感影像语义生成技术是将遥感影像的信息转化成文本的技术,传统技术利用卷积神经网络提取图像特征,然后利用语言解码器生成描述文本。然而,目前的语义生成技术在图像特征的提取和利用方面还不够有效和充分,这阻碍了文本信息的准确生成。
技术实现要素:
3.针对以上技术问题,本发明提供一种用于遥感影像语义生成的视觉特征增强方法。
4.本发明解决其技术问题采用的技术方案是:
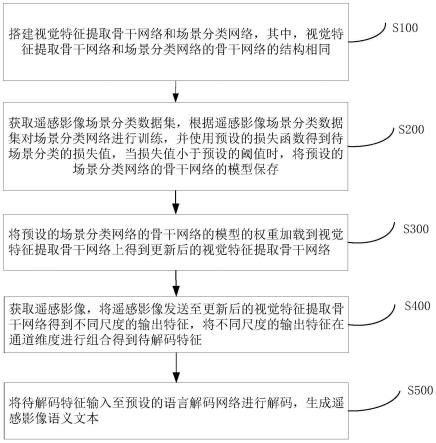
5.一种用于遥感影像语义生成的视觉特征增强方法,方法包括以下步骤:
6.步骤s100:搭建视觉特征提取骨干网络和场景分类网络,其中,视觉特征提取骨干网络和场景分类网络的骨干网络的结构相同;
7.步骤s200:获取遥感影像场景分类数据集,根据遥感影像场景分类数据集对场景分类网络进行训练,并使用预设的损失函数得到待场景分类的损失值,当损失值小于预设的阈值时,将预设的场景分类网络的骨干网络的模型保存;
8.步骤s300:将预设的场景分类网络的骨干网络的模型的权重加载到视觉特征提取骨干网络上得到更新后的视觉特征提取骨干网络;
9.步骤s400:获取遥感影像,将遥感影像发送至更新后的视觉特征提取骨干网络得到不同尺度的输出特征,将不同尺度的输出特征在通道维度进行组合得到待解码特征;
10.步骤s500:将待解码特征输入至预设的语言解码网络进行解码,生成遥感影像语义文本。
11.优选地,步骤s200中的视觉特征提取骨干网络包括依次相连的第一残差模块、第二残差模块、第三残差模块和第四残差模块,第一残差模块用于对输入图像进行特征提取得到第一尺度的特征图,第二残差块用于对第一尺寸的特征图进行特征提取得到第二尺度的特征图,第三残差块用于对第二尺寸的特征图进行特征提取得到第三尺度的特征图,第四残差块用于对第三尺寸的特征图进行特征提取得到第四尺度的特征图。
12.优选地,步骤s400包括:
13.步骤s410:获取遥感影像,将遥感影像发送至更新后的视觉特征提取骨干网络得到第一尺度的特征图、第二尺度的特征图、第三尺度的特征图和第四尺度的特征图;
14.步骤s420:将第四尺度的特征图与其余任意至少一种不同尺度的特征图在通道维
度上进行组合得到待解码特征。
15.优选地,步骤s200还包括:当损失值大于预设的阈值时,根据损失值对场景分类网络的网络参数进行更新,并重复使用预设的损失函数得到待场景分类的更新后的损失值,直至更新后的损失值小于预设的阈值。
16.优选地,预设的语言解码网络为fc模型、soft attention模型和up-down模型中的任意一个。
17.优选地,fc模型包括依次连接的第一lstm单元和第一mlp单元,第一lstm单元用于根据上一时刻隐藏状态、第一lstm单元携带信息、待解码特征获取当前时刻的隐藏状态和携带信息,第一mlp单元用来根据当前时刻的隐藏状态和携带信息解码生成单词文本。
18.优选地,soft attention模型包括第一注意力单元、第二lstm单元和第二mlp单元,第一注意力单元连接第二lstm单元和第二mlp单元,第二lstm单元连接第二mlp单元,第一注意力单元用于根据上一时刻隐藏状态为待解码特征赋予权重,lstm单元用于根据上一时刻的隐藏状态、上一时刻生成的单词和经过第一注意力单元加权的待解码特征得到当前时刻的隐藏状态,mlp单元用来根据当前时刻的隐藏状态解码生成单词文本。
19.优选地,up-down模型包括第二注意力单元、注意力lstm单元、语言lstm单元和softmax单元,第二注意力单元连接语言lstm单元,注意力lstm单元连接第二注意力单元和语言lstm单元,语言lstm单元连接softmax单元,
20.注意力lstm单元根据待解码特征、上一时刻语言lstm单元的隐藏状态、上一时刻注意力lstm单元的隐藏状态和上一时刻生成的单词生成当前时刻注意力lstm的隐藏状态;
21.第二注意力单元结合注意力lstm单元输出的当前时刻注意力lstm的隐藏状态为视觉特征赋予权重;
22.语言lstm单元根据经过第二注意力单元加权的视觉特征和当前时刻注意力lstm单元的输出和上一时刻的lstm单元的隐藏状态生成当前时刻语言lstm的隐藏状态;
23.softmax单元利用当前时刻语言lstm的隐藏状态生成单词文本。
24.上述一种用于遥感影像语义生成的视觉特征增强方法,借鉴了迁移学习的思想,将在大规模遥感影像场景分类数据集上训练的场景分类网络的骨干网络权重迁移至视觉特征提取骨干网络提取视觉特征,有效提升特征提取网络提取特征的能力,并引入了一种多尺度特征组合机制,增强送入预设的语言解码网络的特征,其目的在于提升遥感影像语义生成文本的质量,使语义生成文本中包含更多目标、关系和属性等信息。
附图说明
25.图1为本发明一实施例中一种用于遥感影像语义生成的视觉特征增强方法的流程图;
26.图2为本发明一实施例中的视觉特征提取骨干网络的结构示意图;
27.图3为本发明一实施例中权重预训练和迁移示意图;
28.图4为本发明一实施例中特征组合方式示意图;
29.图5为本发明一实施例中soft attention语言模型结构图;
30.图6为本发明一实施例中up-down语言模型结构图;
31.图7为本发明一实施例中特征增强方法生成文本对比图。
具体实施方式
32.为了使本技术领域的人员更好地理解本发明的技术方案,下面结合附图对本发明作进一步的详细说明。
33.在一个实施例中,如图1所示,一种用于遥感影像语义生成的视觉特征增强方法,方法包括以下步骤:
34.步骤s100:搭建视觉特征提取骨干网络和场景分类网络,其中,视觉特征提取骨干网络和场景分类网络的骨干网络的结构相同。
35.具体地,场景分类网络使用resnet101网络。
36.步骤s200:获取遥感影像场景分类数据集,根据遥感影像场景分类数据集对场景分类网络进行训练,并使用预设的损失函数得到待场景分类的损失值,当损失值小于预设的阈值时,将预设的场景分类网络的骨干网络的模型保存。
37.具体地,使用nwpu-resisc45数据集训练场景分类网络,将20%的图片作为训练集,其余影像作为测试集。使用大型遥感影像场景分类数据集对场景分类网络进行训练,待场景分类的损失不再下降,分类准确率稳定后,将场景分类网络的骨干网络的模型保存。
38.在一个实施例中,步骤s200还包括:当损失值大于预设的阈值时,根据损失值对场景分类网络的网络参数进行更新,并重复使用预设的损失函数得到待场景分类的更新后的损失值,直至更新后的损失值小于预设的阈值。
39.在一个实施例中,如图2所示,步骤s200中的视觉特征提取骨干网络包括依次相连的第一残差模块、第二残差模块、第三残差模块和第四残差模块,第一残差模块用于对输入图像进行特征提取得到第一尺度的特征图,第二残差块用于对第一尺寸的特征图进行特征提取得到第二尺度的特征图,第三残差块用于对第二尺寸的特征图进行特征提取得到第三尺度的特征图,第四残差块用于对第三尺寸的特征图进行特征提取得到第四尺度的特征图。
40.具体地,可以理解,可以根据实际需求设置残差模块的数量。
41.步骤s300:将预设的场景分类网络的骨干网络的模型的权重加载到视觉特征提取骨干网络上得到更新后的视觉特征提取骨干网络。
42.具体地,如图3所示,将保存的场景分类网络的骨干网络模型权重加载到视觉特征提取骨干网络上,然后使用视觉特征提取骨干网络提取图像视觉特征。该方法借鉴了迁移学习的思想,将在大规模遥感影像场景分类数据集上训练的网络权重迁移过来提取视觉特征。
43.步骤s400:获取遥感影像,将遥感影像发送至更新后的视觉特征提取骨干网络得到不同尺度的输出特征,将不同尺度的输出特征在通道维度进行组合得到待解码特征。
44.在一个实施例中,步骤s400包括:
45.步骤s410:获取遥感影像,将遥感影像发送至更新后的视觉特征提取骨干网络得到第一尺度的特征图、第二尺度的特征图、第三尺度的特征图和第四尺度的特征图;
46.步骤s420:将第四尺度的特征图与其余任意至少一种不同尺度的特征图在通道维度上进行组合得到待解码特征。
47.具体地,将视觉特征提取骨干网络提取的不同尺度特征在通道维度进行组合,以resnet101为例,如图4所示,将最后一个残差模块和倒数第二个残差模块的输出特征在通
道维度拼接组合作为待解码特征,倒数第二个残差模块的输出特征经过平均池化后得到平均池化后的特征,将平均池化后的特征和最后一个残差模块的输出特征进行拼接组合作为待解码特征。可以理解,可以根据实际需求进行不同尺度的特征图的组合,比如第四尺度的特征图和第二尺度的特征图,或者第四尺度的特征图和第三尺度的特征图等。
48.步骤s500:将待解码特征输入至预设的语言解码网络进行解码,生成相关语义文本。
49.在一个实施例中,预设的语言解码网络为fc模型、soft attention模型和up-down模型中的任意一个。
50.具体地,图像编码器提取完视觉特征后,会将这些特征送入语言解码器中进行解码。不同的解码器生成文本的能力也有所不同。为了全面分析我们特征增强技术的效果,我们挑选了三个具有代表性的语言解码器来生成文本,分别是fc模型,softattention模型和up-down模型。fc模型是图像描述领域最典型的结构,soft attention模型是最先使用注意力进行语言解码的方法,up-down是现阶段最优秀的语言解码器之一。
51.在一个实施例中,fc模型包括依次连接的第一lstm单元和第一mlp单元,第一lstm单元用于根据上一时刻隐藏状态、第一lstm单元携带信息、待解码特征获取当前时刻的隐藏状态和携带信息,第一mlp单元用来根据当前时刻的隐藏状态和携带信息解码生成单词文本。
52.具体地,fc模型是图像描述领域最基本的模型,即show and tell模型。其过程可以表示为:
53.i
t
=σ(w
ix
x
t
+w
ihht-1
+bi)
54.f
t
=σ(w
fx
x
t
+w
fhht-1
+bf)
55.o
t
=σ(w
ox
x
t
+w
ohht-1
+bo)
56.c
t
=i
t
⊙
tanh(w
zx
x
t
+w
zhht-1
+bz)+f
t
⊙ct-1
57.h
t
=o
t
⊙
tanh(c
t
)
58.其中,i
t
,f
t
,o
t
分别代表t时刻输入门、遗忘门和输出门的输出,σ为sigmoid激活函数。c0和h0一般初始化为0,w是权重矩阵,b是偏置项。为了方便描述,上述过程在下文中均用下式表示:
59.h
t
=lstm(x
t
,h
t-1
)
60.其中x
t
~y
t-1
。在得到每一个时刻隐藏状态h
t
后,生成的下一个单词可以表示为:
61.y
t
~softmax(w
sht
)
62.使用θ表示模型中的参数,一般来说,参数θ通过最大化观测序列的可能性来学习。
63.具体来说,优化的目标是让交叉熵函数(xe)最小:
[0064][0065]
其中,为给定的参考序列。
[0066]
在一个实施例中,如图5所示,soft attention模型包括第一注意力单元、第二lstm单元和第二mlp单元,第一注意力单元连接第二lstm单元和第二mlp单元,第二lstm单元连接第二mlp单元,第一注意力单元用于根据上一时刻隐藏状态为待解码特征赋予权重,lstm单元用于根据上一时刻的隐藏状态、上一时刻生成的单词和经过第一注意力单元加权
gram精确度。rouge基于最长公共子序列的统计来反映获得描述的准确程度。cider是专门为图像描述设计的评价指标,它通过tf-idf计算每个n-gram的权重,用于评价描述的一致性。spice也是专门用于评价图像描述生成质量的指标,其通过分析待评价描述和参考描述中的目标、属性和关系来判断文本生成的质量。
[0085]
本发明在测试集上的结果如表1和图7所示。
[0086]
表1是两种视觉特征增强策略在三种语言模型上的表现,*为增强视觉特征的模型,#为使用遥感影像预训练权重提取并增强视觉特征的模型
[0087]
modelb1b2b3b4rouge_lciderspicefc0.7140.5890.4960.4210.6312.3390.444fc
*
0.7310.6120.5210.4460.6532.4260.462fc
#
0.7380.620.5270.4520.652.5530.466soft-att0.6910.5360.4340.3570.6252.1360.402soft-att
*
0.7140.5940.50.4240.6422.3820.455soft-att
#
0.7360.6230.5310.4570.6542.5770.463up-down0.7380.6140.5160.4370.6482.4350.465up-down
*
0.7460.6280.5330.4550.6582.5140.468up-down
#
0.7540.640.5460.4710.6582.6590.466
[0088]
通过表1可以看出,在三个不同的语言模型上我们的两种视觉特征增强策略都取得了显著的效果。应用视觉增强策略的模型在所有评价指标上都有了较大的提升。其中在bleu指标上通过加强视觉特征带来的提升大于使用遥感影像预训练权重的提升。而在cider指标上的效果刚好相反。cider是专门用于图像描述任务的评价指标,在fc模型中,cider相对提升了9.15%。在soft-att模型中,cider相对提升了20.65%。在up-down模型中,cider相对提升了9.20%。
[0089]
图7展示了在不同特征增强策略下fc模型生成文本的直观比较。第一行是基线模型,即标准的fc模型;第二行是使用多尺度特征组合策略增强特征的fc模型;第三行是多尺度特征组合策略和预训练权重提取特征策略结合的fc模型。从图中可以看出,在应用了本文提出的视觉特征增强方法后,fc模型生成的文本在长度和丰富度上都有了明显的提升。总的来说,本技术的视觉特征增强方法在生成的文本上拥有两个明显的优势:(1)在应用了视觉特征增强方法后,模型能够产生更多目标的信息,例如第一幅场景中生成的候机楼,建筑,树木第二幅场景中生成的道路,建筑;第三幅场景中生成的道路,操场,篮球场。这些新产生的目标信息有效的提升了文本的丰富程度。(2)在生成的目标信息中,小型目标和位于图像边缘的目标信息有所增加,例如第一幅场景中的候机楼,树木均属于较小的目标。第二幅场景中的道路,建筑均属于位于图像边缘区域的目标。这些目标的信息使得生成文本的全面性有所提升。(3)生成的目标信息更加准确。如第三幅场景中中,标准的fc模型生成的河流在图像中并不存在,而经过特征增强的fc模型则能正确生成道路。(4)在经过数据增强后,模型能够生成更多目标的属性和目标间关系的信息。如第一幅场景中的附近,绿色的;第四幅场景中的不规则的。这些信息提供了更多目标的特点信息,也能够更准确的描述整个图像。
[0090]
上述一种用于遥感影像语义生成的视觉特征增强方法,借鉴了迁移学习的思想,
将在大规模遥感影像场景分类数据集上训练的网络权重迁移过来提取视觉特征,并引入了一种多尺度特征组合机制增强送入语言解码网络的特征。其目的在于提升遥感影像语义生成文本的质量,使语义生成文本中包含更多目标、关系和属性等信息。
[0091]
本发明与现有技术相比具有以下优点:
[0092]
(1)本发明使用在大规模遥感影像场景分类数据集上进一步训练,得到骨干网络的预训练权重,有效提升特征提取网络提取特征的能力。(2)本发明将特征提取网络获取的多尺度特征进行结合,使送入解码器的特征更加全面,包含更多信息。(3)本发明所提出的视觉特征增强方法可以和任意语言解码器相结合。
[0093]
以上对本发明所提供的一种用于遥感影像语义生成的视觉特征增强方法进行了详细介绍。本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的核心思想。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以对本发明进行若干改进和修饰,这些改进和修饰也落入本发明权利要求的保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1