基于产品底层知识的多需求融合标书筛选方法与流程
1.本发明涉及数据处理技术领域,具体涉及基于产品底层知识的多需求融合标书筛选方法。
背景技术:
2.标书是由发标单位编制或委托设计单位编制,向投标者提供对该工程的主要技术、质量、工期等要求的文件。标书是招标工作时采购当事人都要遵守的具有法律效应且可执行的投标行为标准文件。
3.目前常见的对标书进行筛选的方法为:招标方设置若干个关键词和关键词后的数值,由审核人员设置关键词的顺序,招标系统优先按照第一关键词的顺序对标书进行排序,如遇到有第一关键词的相似度相同的,则顺次按照下一级关键词的相似度进行排序,按照相似度从高到低进行排除。该方法需要审核人员设置关键词的顺序,且仅根据招标方设置的关键词对标书进行筛选,而没有根据关键词对应的数值和难易程度进行筛选,其仅根据关键词进行筛选,筛选出的标书数量仍较多,难易做到精简筛选。如公司规模人数,不同的公司的标书中可能都有公司规模这个关键词,但不同公司的公司规模是不同的,其仅根据关键词进行排序,没有根据标书中关键词对应的数值对标书进行筛选,且不同的关键词的满足难易程度是不同的,没有考虑在筛选过程中。
技术实现要素:
4.为了解决上述技术问题,本发明的目的在于提供基于产品底层知识的多需求融合标书筛选方法,所采用的技术方案具体如下:根据每个标书的标书数据构建满足需求向量,对满足需求向量二值化得到对应的二值化向量;基于二值化向量对标书进行分类,得到至少两个第二类别;计算第二类别中各标书对应的满足需求向量的均值作为类别中心向量;设定所有所述满足需求向量中满足需求的满足趋势,根据所述满足趋势得到需求对应的最满足值和各标书的满足度,由每个需求对应的最满足值构建理想向量;计算所述类别中心向量和所述理想向量的相似度作为第一理想相似度;获取所有所述满足需求向量中每个满足需求对应的标书数量,根据每个满足需求对应的标书数量和满足度计算满足需求对应的需求难度;由第二类别中各标书中满足需求对应的需求难度的均值作为对应的难度调节值,所述难度调节值和所述第一理想相似度的乘积为第二理想相似度;计算每个标书的满足需求向量和所属第二类别的类别中心向量的相似度作为调节相似度,所述调节相似度和所述第二理想相似度的乘积作为最终相似度;根据所述最终相似度对标书进行筛选。
5.优选的,所述基于二值化向量对标书进行分类,得到至少两个第二类别,包括:
将二值化向量相同的标书划分至同一类别中,得到至少两个第一类别;基于每个第一类别对应的二值化向量的相似度对标书进行二次分类,得到至少两个第二类别。
6.优选的,所述根据每个标书的标书数据构建满足需求向量,包括:根据招标方多个需求,提取每个标书中的多个满足招标方需求的数据作为满足需求,构建满足需求序列,并得到对应的满足需求向量。
7.优选的,所述设定所有所述满足需求向量中满足需求的满足趋势,包括:人为设定所有满足需求向量中的每个满足需求的满足趋势。
8.优选的,所述满足度的获取方法为:根据满足趋势对各个标书进行排序得到标书序列,其中,将最满足的标书放置于标书序列中的第一位;获取标书中任意满足需求对应的元素与该满足需求的最满足值在标书序列中序列号的差值的绝对值;以自然常数为底数,以负的所述差值的绝对值为指数的指数函数作为满足度。
9.优选的,所述计算所述类别中心向量和所述理想向量的相似度作为第一理想相似度,包括:所述类别中心向量和所述理想向量的余弦相似度为第一理想相似度。
10.优选的,所述根据每个满足需求对应的标书数量和满足度计算满足需求对应的需求难度,包括:所述需求难度的计算公式为:其中,为第i个满足需求对应的需求难度;为自然常数;为第i个满足需求对应的标书数量;为第j个标书中第i个满足需求对应的满足度;为标书总数量。
11.优选的,所述对满足需求向量二值化得到对应的二值化向量,包括:将满足需求向量中的非零元素置为一,保留满足需求向量中的零元素,构成对应的二值化向量。
12.优选的,所述计算每个标书的满足需求向量和所属第二类别的类别中心向量的相似度作为调节相似度,包括:每个标书的满足需求向量和所属第二类别的类别中心向量的余弦相似度为调节相似度。
13.优选的,所述根据所述最终相似度对标书进行筛选,包括:将各标书对应的最终相似度从大到小进行排序,得到对应的相似度序列;保留相似度序列中前n个的相似度对应的标书,筛除掉其他标书,其中,n≥2。
14.本发明实施例至少具有如下有益效果:本发明根据每个标书的标书数据构建满足需求向量和对应的二值化向量;基于二值化向量对标书分类得到至少两个第二类别。对标书进行分类减小了后续计算的计算量。
15.计算第二类别中各标书对应的满足需求向量的均值作为类别中心向量;计算满足需求对应的最满足值和各标书的满足度,由最满足值构建理想向量;计算类别中心向量和理想向量的相似度作为第一理想相似度;根据每个满足需求对应的标书数量和满足度计算满足需求对应的需求难度;由第二类别中各标书中满足需求对应的需求难度的均值作为难度调节值,难度调节值和第一理想相似度的乘积为第二理想相似度。通过每个满足需求的对应的标书数量对每个满足需求的需求难度进行计算,对不同的满足需求根据其对应的难度进行不同的修正,结合需求难度对第二类别中各标书的满足需求向量与理想向量的第一理想相似度进行修正,得到第二理想相似度,使得结果更加符合实际。
16.计算每个标书的满足需求向量和所属第二类别的类别中心向量的相似度作为调节相似度,调节相似度和第二理想相似度的乘积作为最终相似度;根据最终相似度对标书进行筛选。本发明首先通过每个标书在不同满足需求上的数据相似性进行分类得到第二类别,进而得到每个满足需求的需求难度,然后通过需求难度对每个类别中标书与理想向量的相似度距离进行更新,得到所有标书与理想向量的相似度,进而对标书进行筛选,仅结合了满足需求对应的数据和满足需求的难易程度进行了筛选,筛选出的标书更加精简,使得招标方更容易挑选出合适的标书。
附图说明
17.为了更清楚地说明本发明实施例或现有技术中的技术方案和优点,下面将对实施例或现有技术描述中所需要使用的附图作简单的介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其它附图。
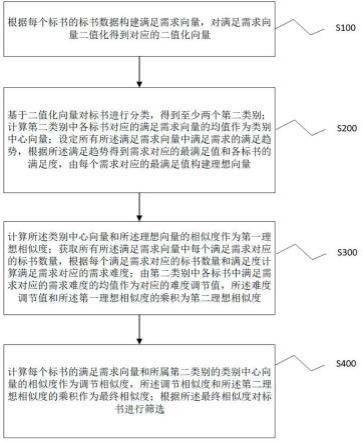
18.图1为本发明一个实施例所提供的基于产品底层知识的多需求融合标书筛选方法的方法流程图。
具体实施方式
19.为了更进一步阐述本发明为达成预定发明目的所采取的技术手段及功效,以下结合附图及较佳实施例,对依据本发明提出的基于产品底层知识的多需求融合标书筛选方法,其具体实施方式、结构、特征及其功效,详细说明如下。在下述说明中,不同的“一个实施例”或“另一个实施例”指的不一定是同一实施例。此外,一或多个实施例中的特定特征、结构或特点可由任何合适形式组合。
20.除非另有定义,本文所使用的所有的技术和科学术语与属于本发明的技术领域的技术人员通常理解的含义相同。
21.本发明实施例提供了基于产品底层知识的多需求融合标书筛选方法的具体实施方法,该方法适用于标书筛选场景。本发明中的标书为电子标书。为了解决仅根据招标方设置的关键词对标书进行筛选,而没有根据关键词对应的数值和难易程度进行筛选,其仅根据关键词进行筛选,筛选出的标书数量仍较多,难易做到精简筛选的问题。本发明首先通过每个标书在不同满足需求上的数据相似性进行分类得到第二类别,进而得到每个满足需求的需求难度,然后通过需求难度对每个类别中标书与理想向量的相似度距离进行更新,得到所有标书与理想向量的相似度,进而对标书进行筛选,仅结合了满足需求对应的数据和
满足需求的难易程度进行了筛选,筛选出的标书更加精简,使得招标方更容易挑选出合适的标书。
22.下面结合附图具体的说明本发明所提供的基于产品底层知识的多需求融合标书筛选方法的具体方案。
23.请参阅图1,其示出了本发明一个实施例提供的基于产品底层知识的多需求融合标书筛选方法的方法流程图,该方法包括以下步骤:步骤s100,根据每个标书的标书数据构建满足需求向量,对满足需求向量二值化得到对应的二值化向量。
24.首先根据每个标书的标书数据构建满足需求向量。具体的:根据招标方多个需求关键字,提取每个标书中的多个满足招标方需求的数据作为满足需求,构建满足需求序列,并得到对应的满足需求向量。所述满足需求是指:满足招标方需求的标书中的多个数据,也即满足条件。例如:招标方对公司规模的要求和对项目完成时间的需求,则标书对应的满足需求向量为:[公司规模对应的数据,项目完成所需时间对应的数据],其中某个公司的标书中的标书数据为:公司规模对应的数据:5000人,项目完成所需时间对应的数据:110-120天。对应的满足需求向量为:[5000,110-120]。其中,标书中没有出现的满足需求对应的位置的元素为0。其中,根据招标方多个需求关键字,提取每个标书中的多个满足招标方需求的数据作为满足需求,具体的:对标书进行字符识别,识别得到关键字符,该关键字符是指招标方提供的招标数据中的需求关键字,将标书中需求关键字后的数字作为该标书中需求关键字对应的数值,也即满足需求向量中该需求对应的满足需求的元素。
[0025]
可能有些标书中对于某些满足需求没有标明,即每个标书能够满足的或提到的需求不同,例如:标书1中有标明公司规模,标书2中没有标明公司规模,则标书1和标书2可以满足的需求不同。
[0026]
首先根据每个标书的满足需求向量,对满足需求向量二值化得到对应的二值化向量。所述二值化向量是指将标书中的没有出现的满足需求对应位置标注为0,也即保留满足需求向量中的零向量,有标明对应满足需求的标注为1,也即将满足需求向量中的非零元素置为一,进而构成对应的二值化向量。例如:当标书1中出现了项目质量,而未出现项目完成所需时间;标书2中出现了项目完成所需时间,而未出现项目质量的时候。满足需求序列为:[项目完成所需时间对应的数据,项目质量对应的数据],标书1对应的满足需求向量为:[0,0.9],对应的二值化向量为[0,1];标书2对应的满足需求向量为:[100,0],对应的二值化向量为[1,0]。这两个标书能满足的需求不同。
[0027]
步骤s200,基于二值化向量对标书进行分类,得到至少两个第二类别;计算第二类别中各标书对应的满足需求向量的均值作为类别中心向量;设定所有所述满足需求向量中满足需求的满足趋势,根据所述满足趋势得到需求对应的最满足值和各标书的满足度,由每个需求对应的最满足值构建理想向量。
[0028]
由于当标书的数据量较大时,为了对标书进行快速筛选,首先通过标书向量进行分类,进而计算不同类别的代表向量与理想标书向量的差别,根据差别对标书进行筛选,因此首先需要根据二值化向量对不同的标书进行分类,得到不同的标书类别,计算得到标书类别的过程如下:通过步骤s100可以得到每个标书对应的满足需求向量的二值化向量,首先根据二
值化向量对标书进行分类,将二值化向量完全相同的标书划分为同一类别种,称之为第一类别,得到至少两个第一类别。每个第一类别对应一个二值化向量,二值化向量中可以满足的满足需求设为1,不能满足的需求用0表示。
[0029]
得到第一类别后,对于每个类别中的二值化向量,通过计算余弦相似度的方法,划分为不同的第二类别,所述第二类别是指能满足的需求相同,且满足度相近的标书被划分为同一类。也即基于每个第一类别对应的二值化向量的相似度对标书进行二次分类,得到至少两个第二类别。
[0030]
具体的:计算得到任意两个第一类别的二值化向量的余弦相似度,首先对余弦相似度进行降序排序,得到初始相似度序列,初始相似度序列中的元素依次记为:第一相似度、第二相似度,
…
。首先计算第一相似度对应的第一类别的数量,记为第一数量m1,如果第一数量m1大于等于预设类别数量,作为层次聚类中的初始类别,如果第一数量小于预设类别数量,计算第二相似度对应的第一类别数量,记为第二数量m2,直到第n相似度对应的第一类别数量大于等于预设类别数量,将此时得到的每个第一类别作为一个初始类别;之后按照余弦相似度从大到小的顺序依次计算每个第一类别的二值化向量与每个初始类别的二值化向量的余弦相似度,将最大余弦相似度对应的初始类别作为该第一类别的所属第二类别,该第二类别也即标书类别。在本发明实施例中预设类别数量为10,在其他实施例中实施者可根据实际情况调整该取值。
[0031]
计算得到至少两个第二类别后,计算每个第二类别的类别中心向量,类别中心向量的计算方法如下:计算第二类别中各标书对应的满足需求向量的均值作为类别中心向量,也即计算满足需求向量中每个对应位置元素的均值作为类别中心向量中每个位置的元素值。例如:第二类别3中有两个满足需求向量,分别为:[99,50]和[101,50],则类别中心向量为:[100,50]。
[0032]
通过类别中心向量的最大值的组合得到理想向量,根据理想向量与类别中心向量的距离得到每个第二类别的第一理想相似度。具体的:首先人为设定所有满足需求向量中的每个满足需求的满足趋势。每个标书中都有对于每个满足需求的对应范围或值,例如:标书1中对应的项目完成所需时间为:100-120天,标书2中对应的项目完成所需时间为:120-130天,对于项目完成所需时间来说,往往时间越短越好,则标书1中对于需求1的满足度更大,故对应的对于项目完成所需时间来说,该满足需求的满足趋势为越小越好;同样地,可以得到哪个标书对于需求2、需求3的满足度更大,不同的满足需求对应的满足趋势也不同,如对于公司规模来说,公司规模越大越好,故对应的满足趋势为越大越好,人为设定每个满足需求的满足趋势。根据满足趋势对各个标书进行排序,得到标书序列。对于不同的满足需求,其对应的标书序列也不同,将最满足的标书放置于标书序列中的第一位。位于第一位的标书中满足需求对应的值即为该满足需求的最满足值,由每个满足需求对应的最满足值构建理想向量,理想向量是指其中每个满足需求位置处的元素均为该满足需求对应的所有标书中能满足的最大上限。也即对于每个满足需求,可以首先人为确定每个满足需求的满足趋势,所述满足度方向是指,例如:对于项目完成所需时间来说,时间越短,满足度越大;对于项目的投入资金来说,资金越多,满足度越大。每个满足需求的满足趋势可以事先通过人为理解得到,进而对于每个满足需求来说,所有标书的最大满足值为对应的范围或值,例如:对于项目完成时间来说,时间越短,满足
度越大,则将所有标书的项目完成时间中最短时间对应的时间作为最大满足度对应的值,进而获取每个满足需求的最满足值得到了理想向量。
[0033]
由于不同满足需求的满足趋势不同,首先根据不同满足需求的满足趋势计算得到每个标书对应满足需求的满足度。对于同一满足需求,满足度的获取方法为:获取每个标书中该满足需求对应的元素与该满足需求的最满足值在标书序列中序列号的差值的绝对值;以自然常数为底数,以负的差值的绝对值为指数的指数函数作为满足度。
[0034]
该满足度的计算公式如下:其中,为第i个标书中第j个满足需求的满足度;为对于第j个满足需求,第i个标书在标书序列中的序列号;为第j个满足需求的最满足值在标书序列中的序列号。
[0035]
公式中,通过计算每个标书的对应位置元素值与对应位置满足需求的最满足值在标书序列中序列号的差值计算满足度,差值越大,满足度越小;差值越小,满足度越大。因此通过反函数变为正比关系的同时,进行归一化,得到满足度。进而每个满足需求向量转化为对应的满足度向量,一个满足需求向量对应一个标书满足度向量,满足度向量中每个元素为满足需求对应的满足度。得到满足度向量后,通过所述满足度向量计算需求难度。
[0036]
步骤s300,计算所述类别中心向量和所述理想向量的相似度作为第一理想相似度;获取所有所述满足需求向量中每个满足需求对应的标书数量,根据每个满足需求对应的标书数量和满足度计算满足需求对应的需求难度;由第二类别中各标书中满足需求对应的需求难度的均值作为对应的难度调节值,所述难度调节值和所述第一理想相似度的乘积为第二理想相似度。
[0037]
计算类别中心向量与理想向量的余弦相似度,将余弦相似度作为每个第二类别的第一理想相似度,所述第一理想相似度是指每个第二类别与理想向量的相近程度。
[0038]
通常来说,大部分标书均可以满足的需求往往是难度较低的,而越少的标书才可以满足的需求往往是难度较高的,根据该逻辑对每个满足需求的难度进行大致估计,计算每个满足需求的需求难度的过程如下:首先获取所有标书中每个满足需求对应的该满足需求的响应标书数量,也即获取满足需求向量中每个满足需求对应的标书数量,响应标书是指对于某个满足需求来说,该标书的二值化向量对应位置元素不为0。计算每个满足需求对应的标书数量与标书总数量的比值,该比值越大,说明有越多的标书可以满足该需求,同时每个标书上的满足需求越接近该需求的最满足值,该满足需求的完成难度越小。
[0039]
该需求难度的计算公式为:
其中,为第i个满足需求对应的需求难度;为自然常数;为第i个满足需求对应的标书数量;为第j个标书中第i个满足需求对应的满足度;为标书总数量。
[0040]
其中,表示的是第i个满足需求的标书数量在所有标书中的数量占比;该占比越大,对应满足需求的难度越小;该占比越大,则对应的满足需求的难度越大。公式中表示的是满足需求的满足度的均值;该满足度的均值越大,对应满足需求的难度越小;反之该满足度的均值越小,对应满足需求的难度越大。由于占比越大,对应的满足需求难度越小;满足度的均值越大,对应的满足需求难度越小,因此通过反函数变为正比关系的同时,进行归一化,得到需求难度。
[0041]
每个满足需求均有各自对应的需求难度,由每个第二类别中各标书中的满足需求所对应的需求难度的均值作为该第二类别对应的难度调节值。也即对于每个第二类别,可以得到第二类别中每个标书对应的需求难度,构成需求难度向量,得到每个第二类别的需求难度向量后,需求难度向量中的值越大,也即难度越大,仍可以满足的,则该第二类别中标书的质量较好。故计算每个第二类别的需求难度向量中的元素的均值作为对应的难度调节值。然后计算难度调节值与每个类别的第一理想相似度的乘积作为第二理想相似度r,通过需求难度实现了对第二类别的第一理想相似度的更新。
[0042]
步骤s400,计算每个标书的满足需求向量和所属第二类别的类别中心向量的相似度作为调节相似度,所述调节相似度和所述第二理想相似度的乘积作为最终相似度;根据所述最终相似度对标书进行筛选。
[0043]
根据所述第二理想相似度、每个第二类别中个体标书的满足需求向量与第二类别的类别中心向量得到每个标书与理想向量的最终相似度,根据最终相似度进行降序排列。具体的:得到第二理想相似度后,计算每个第二类别中标书的满足需求向量与类别中心向量的余弦相似度作为调节相似度,调节相似度越大,与理想向量越相近,计算得到每个第二类别中所有标书的满足需求向量与理想向量的最终相似度的过程为:首先计算得到每个第二类别中标书的满足需求向量与类别中心向量的余弦相似度作为调节相似度后,将调节相似度与第二类别的第二理想相似度的乘积作为每个标书的满足需求向量与理想向量的最终相似度,最终相似度越小,被筛除的优先级越大。将各标书对应的最终相似度从大到小进行降序排序,得到对应的相似度序列;保留相似度序列中前n个的相似度对应的标书,筛除
掉其他标书,其中,n≥2。在本发明实施例中n的取值为50,在其他实施例中实施者可根据实际情况调整改取值。
[0044]
综上所述,本发明涉及数据处理技术领域。该方法根据每个标书的标书数据构建满足需求向量,对满足需求向量二值化得到对应的二值化向量;基于二值化向量对标书进行分类,得到至少两个第二类别;计算第二类别中各标书对应的满足需求向量的均值作为类别中心向量;设定满足需求向量中的满足需求的满足趋势,根据满足趋势得到满足需求对应的最满足值和各标书的满足度,由每个满足需求对应的最满足值构建理想向量;计算类别中心向量和理想向量的相似度作为第一理想相似度;获取满足需求向量中每个满足需求对应的标书数量,根据每个满足需求对应的标书数量和满足度计算满足需求对应的需求难度;由第二类别中各标书中满足需求对应的需求难度的均值作为对应的难度调节值,难度调节值和第一理想相似度的乘积为第二理想相似度;计算每个标书的满足需求向量和所属第二类别的类别中心向量的相似度作为调节相似度,调节相似度和第二理想相似度的乘积作为最终相似度;根据最终相似度对标书进行筛选。本发明基于产品底层知识的多需求融合标书筛选方法,首先通过每个标书在不同满足需求上的数据相似性进行分类,得到标书类别,进而根据标书类别中心的需求满足度,得到每个满足需求的需求难度,然后通过需求难度对每个类别中标书与理想向量的的相似度距离进行更新,得到所有标书与理想向量的相似度,进而对标书进行筛选。
[0045]
需要说明的是:上述本发明实施例先后顺序仅仅为了描述,不代表实施例的优劣。在附图中描绘的过程不一定要求示出的特定顺序或者连续顺序才能实现期望的结果。在某些实施方式中,多任务处理和并行处理也是可以的或者可能是有利的。
[0046]
本说明书中的各个实施例均采用递进的方式描述,各个实施例之间相同相似的部分互相参见即可,每个实施例重点说明的都是与其他实施例的不同之处。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1