一种基于RASA的任务型智能多轮对话方法及相关设备与流程
一种基于rasa的任务型智能多轮对话方法及相关设备
技术领域
1.本发明涉及人机交互技术领域,尤其涉及一种基于rasa的任务型智能多轮对话方法、系统及终端。
背景技术:
2.对话系统是人机交互领域的重要内容,人类使用自然语言与系统进行信息交流,机器可以为其提供个性化服务,由于语言的灵活性,单轮的对话系统在一轮的交互中难以理解用户所提出的问题,因此任务型多轮对话系统成为了当前的研究重点。
3.多轮对话系统旨在用最少的轮数了解用户复杂的意图并针对性地提供个性化服务,有关多轮对话的研究目前已经取得了一定的研究进展和研究成果,但距离实际应用还有一定的差距,面临着以下问题:传统的任务型多轮对话系统流程繁琐、重复性高,其各个环节较为分散且没有形成工程化的流程;大部分的任务型多轮对话系统不支持可视化分析,因此用户或管理者无法直观评估对话效果;由于对话管理语料不是用户输入的原始语言,而是人工基于原始输入数据标注的包含意图、词槽和历史对话内容的结构化的对话故事流;所以,对话管理语料标注较为困难,无法实现用户个性化服务;尤其当对话场景、对话流程复杂,意图词槽较多的情况下,人工标注困难且很难保证语料标注质量;目前现有的技术存在不支持可视化分析从而导致用户或管理者无法直观评估对话效果、针对对话管理语料标注困难且无法实现用户个性化的问题。
4.因此,现有技术还有待于改进和发展。
技术实现要素:
5.本发明的主要目的在于提供一种基于rasa的任务型智能多轮对话方法及相关设备,旨在解决现有技术中不支持可视化分析及无法实现用户个性化的问题。
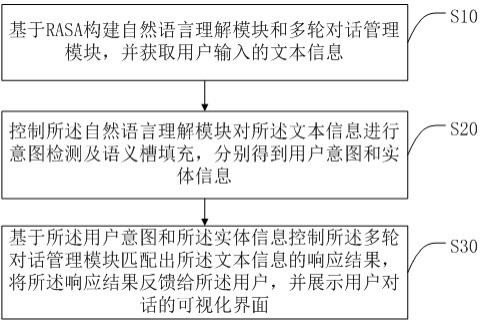
6.为实现上述目的,本发明提供一种基于rasa的任务型智能多轮对话方法,所述基于rasa的任务型智能多轮对话方法包括如下步骤:基于rasa构建自然语言理解模块和多轮对话管理模块,并获取用户输入的文本信息;控制所述自然语言理解模块对所述文本信息进行意图检测及语义槽填充,分别得到用户意图和实体信息;基于所述用户意图和所述实体信息控制所述多轮对话管理模块匹配出所述文本信息的响应结果,将所述响应结果反馈给所述用户,并展示用户对话的可视化界面。
7.可选地,所述的基于rasa的任务型智能多轮对话方法,其中,所述基于rasa构建自然语言理解模块和多轮对话管理模块,并获取用户输入的文本信息,之前还包括:基于语义数据和口语习惯构建场景语料,并根据不同的意图类别对所述场景语料进行分类以构建文本信息的数据类型。
8.可选地,所述的基于rasa的任务型智能多轮对话方法,其中,所述控制所述自然语
言理解模块对所述文本信息进行意图检测及语义槽填充,分别得到用户意图和实体信息,之前还包括:基于大规模中文语料训练的预训练语言模型实现对所述文本信息的特征进行抽取得到文本特征,并将所述文本信息进行分词得到目标文本信息;基于所述文本特征将所述目标文本信息嵌入到向量空间中,以使得所述自然语言理解模块处理所述文本信息。
9.可选地,所述的基于rasa的任务型智能多轮对话方法,其中,所述控制所述自然语言理解模块对所述文本信息进行意图检测及语义槽填充,分别得到用户意图和实体信息,具体包括:预先将dietclassifier作为意图识别的分类器,将所述文本信息输入至所述分类器进行意图分类;对意图分类后的所述文本信息中的口语文本进行意图检测,得到所述文本信息的用户意图;基于语义信息将所述文本信息中的词语打上标签,并控制抽取器基于所述标签进行语义槽填充得到所述文本信息的实体信息。
10.可选地,所述的基于rasa的任务型智能多轮对话方法,其中,所述抽取器包括diet抽取器、正则表达式抽取器和条件随机场抽取器。
11.可选地,所述的基于rasa的任务型智能多轮对话方法,其中,所述基于rasa构建自然语言理解模块和多轮对话管理模块,并获取用户输入的文本信息,之后还包括:当rasa提供的组件不足时,获取所述rasa的组件接口,并基于所述组件接口接入不同的组件。
12.可选地,所述的基于rasa的任务型智能多轮对话方法,其中,所述基于所述用户意图和所述实体信息控制所述多轮对话管理模块匹配出所述文本信息的响应结果,将所述响应结果反馈给所述用户,并展示用户对话的可视化界面,具体包括:基于解释器将所述用户意图和所述实体信息输入至追踪器中,得到所述用户的对话状态,并将所述对话状态发送至策略器;控制所述策略器基于所述对话状态进行动作响应,并基于响应后的动作输出文本对话;基于botfront框架将用户对话的可视化界面进行展示,并构建多语言会话代理。
13.可选地,所述的基于rasa的任务型智能多轮对话方法,其中,所述数据类型包括天气查询、日程安排查询和影视查询。
14.可选地,所述的基于rasa的任务型智能多轮对话方法,其中,所述基于rasa的任务型智能多轮对话系统包括:数据获取模块,用于基于rasa构建自然语言理解模块和多轮对话管理模块,并获取用户输入的文本信息;所述自然语言理解模块,用于理解文本信息的用户意图,将所述用户意图输入到正确的意图类别中,并提取所述文本信息的语义槽值;所述多轮对话管理模块,用于训练对话管理模型,并输出所述文本信息的回答文本;
数据分析模块,用于控制所述自然语言理解模块对所述文本信息进行意图检测及语义槽填充,分别得到用户意图和实体信息;结果展示模块,用于基于所述用户意图和所述实体信息控制所述多轮对话管理模块匹配出所述文本信息的响应结果,将所述响应结果反馈给所述用户,并展示用户对话的可视化界面。
15.此外,为实现上述目的,本发明还提供一种终端,其中,所述终端包括:存储器、处理器及存储在所述存储器上并可在所述处理器上运行的基于rasa的任务型智能多轮对话程序,所述基于rasa的任务型智能多轮对话程序被所述处理器执行时实现如上所述的基于rasa的任务型智能多轮对话方法的步骤。
16.本发明基于rasa构建自然语言理解模块和多轮对话管理模块,并获取用户输入的文本信息;控制所述自然语言理解模块对所述文本信息进行意图检测及语义槽填充,分别得到用户意图和实体信息;基于所述用户意图和所述实体信息控制所述多轮对话管理模块匹配出所述文本信息的响应结果,将所述响应结果反馈给所述用户,并展示用户对话的可视化界面。本发明基于rasa开源框架和管道方法构建对话系统,各模块任务明确且相互独立,将复杂繁琐的配置过程以图形化的方式呈现,提高了搭建效率;还通过botfront开源框架和前后端交互技术,只需要配置相关参数即可一键训练模型,并实现用户个性化服务。
附图说明
17.图1是本发明中基于rasa的任务型智能多轮对话方法的较佳实施例的流程图;图2是本发明中基于rasa的任务型智能多轮对话系统的整体框架示意图;图3是本发明中基于rasa的任务型智能多轮对话方法的rasa自然语言理解及rasa核心的较佳示意图;图4是本发明中基于大规模中文语料训练的预训练语言模型的示意图;图5是本发明中用于意图分类和实体识别的多任务体系结构示意图;图6是本发明中多轮对话管理模块框架示意图;图7是本发明实施例中的创建和训练故事示意图;图8是本发明实施例中的创建、训练和评估nlu模型示意图;图9是本发明实施例中的创建和编辑相应的响应示意图;图10是本发明实施例中的监控对话示意图;图11是本发明实施例中的审查和注释输入的nlu话语示意图;图12是本发明中基于rasa的任务型智能多轮对话的系统的较佳实施例的原理示意图;图13为本发明终端的较佳实施例的运行环境示意图。
具体实施方式
18.为使本发明的目的、技术方案及优点更加清楚、明确,以下参照附图并举实施例对本发明进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
19.需要说明,若本发明实施例中有涉及方向性指示(诸如上、下、左、右、前、后
……
),
则该方向性指示仅用于解释在某一特定姿态(如附图所示)下各部件之间的相对位置关系、运动情况等,如果该特定姿态发生改变时,则该方向性指示也相应地随之改变。
20.另外,若本发明实施例中有涉及“第一”、“第二”等的描述,则该“第一”、“第二”等的描述仅用于描述目的,而不能理解为指示或暗示其相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括至少一个该特征。另外,各个实施例之间的技术方案可以相互结合,但是必须是以本领域普通技术人员能够实现为基础,当技术方案的结合出现相互矛盾或无法实现时应当认为这种技术方案的结合不存在,也不在本发明要求的保护范围之内。
21.任务型多轮对话系统主要以任务为导向,通过与用户进行多轮自然语言的对话来逐步收集与目标任务相关的信息,从而辅助用户获得某种服务。现有技术中任务型多轮对话系统的有关研究通常基于管道(pipeline)结构和端对端(end-to-end)结构;早期的任务型对话系统的研究最典型的是,以darpa旅行信息系统(atis,air traffic information system)和旅行计划系统communicator最为典型,它们主要基于管道结构分别提供以机票预订和旅游计划制定为目标任务的对话服务,其中管道结构分成自然语言理解、对话管理(对话状态追踪和对话策略选择)和自然语言生成三大模块,按照顺序连接起来。近年国内外也有一些优秀的任务型多轮对话系统涌现,科大讯飞开发了aiui系统,仅提供自然语言理解(natural language understanding,nlu)服务;百度开发了百度智能对话定制与服务平台(understanding and interaction technology,unit),该平台以意图识别和词槽填充模型为主,对话模板为辅,通过触发规则组以实现对话管理;unit给每个意图定义了多个触发规则组,一旦满足某个规则组的条件,平台便会触发意图下的执行动作,但该平台不支持开发者定义多个执行动作且并未提供可视化模块。
22.国外同样也有很多对话系统或平台,微软公司研发了基于nlu服务的luis(language understanding intelligent service)平台,该平台采用管道结构和机器学习为开发者定义的意图和词槽分别训练模型,但未提供对话管理功能;google在2016年收购了api.ai,并将其改名为dialogflow,其自然语言处理模块的方法与微软公司研发的luis平台相似,采用上下文的方式进行对话管理,而上下文可以体现用户当前的请求状态,使得对话系统将一个意图传递给里一个意图,以此控制对话路径。除此之外,与微软的luis和google的dialogflow平台不同的是,facebook公司的wit.ai平台采用端到端结构联合识别意图和词槽,不需要开发者配置意图和词槽,而任务型多轮对话具有较强的领域相关性,意图和词槽的定义对于自然语言理解也有所帮助;目前端到端架构还在初始研究阶段,在任务型多轮对话场景下,该模型架构表现并不优秀。
23.本发明较佳实施例所述的基于rasa的任务型智能多轮对话方法,如图1所示,所述基于rasa的任务型智能多轮对话方法包括以下步骤:步骤s10、基于rasa构建自然语言理解模块和多轮对话管理模块,并获取用户输入的文本信息。
24.具体地,基于rasa的任务型智能多轮对话系统主要基于rasa框架进行算法实现和基于botfront(机器人前端)进行可视化界面的实现,其中,所述rasa框架是一个基于机器学习实现多轮对话的开源机器人框架;采用pipeline(管道方法)将多轮对话中的关键技术问题拆分并模块化,通过所述管道方法将多个模块级联,并为各模块定义可交互的接口模
式,从而确定每个模块的输入输出。在一般的管道方法中,多轮对话系统主要包括asr(自动语音识别)、nlu(自然语言理解)、dm(对话管理)、nlg(自然语言生成)和tis(语音合成)五个部分,如图2所示;用户将语音信号发送至asr;所述asr识别出所述语音信号中的文本信息(例如,查一下阿里巴巴的法人),并将所述文本信息发送至nlu;所述nlu识别出所述文本信息中的意图和语义槽(例如,意图为查法人,语义槽为公司名:阿里巴巴、属性:法人),并将所述意图和所述语义槽发送至dm,所述dm基于所述意图和所述语义槽对所述文本信息进行dst(状态追踪)和dpo(策略优化),并基于知识库及apis检索出法人,并将所述法人发送至nlg;所述nlg将文本回复(例如,阿里巴巴公司的法人是xxx)发送至tis;所述tis将所述文本回复合成为语音,并将所述语音播放值用户,完成与用户的对话。
25.而自然语言理解和对话管理两个模块,它们逻辑联系最紧密,是任务型对话的核心,也是每个对话系统都需要关注和解决的问题;如图3所示,rasa 建立 rasa nlu (rasa自然语言理解)和 rasa core (rasa核心,又称多轮对话管理模块);所述 rasa nlu用于意图识别、实体识别、将用户的输入的数据转化为结构化数据、nlu.md及nlu_config.yml,所述rasa core 用于对话管理及决定接下来返回什么内容给用户,主要是分析故事和定义域,其中,故事包括对话的场景流程、创建故事、分析标题、意图及动作、stories.md;定义域包括机器的知识库、意图、动作、回答模板、实体、词槽和domain.yml;通过rasa 建立 rasa nlu 和 rasa core 分别完成用户消息理解和多轮对话管理,解决上述两个核心问题、实现对话系统的主要功能;而使用的主要文件及相关作用如下表所示。
26.自然语言理解模块的主要目的是理解用户意图。通常包括意图检测和语义槽填充两个任务,通过解析用户输入文本语义,并提取与任务有关的关键信息,达到理解并格式化用户意图的目的,为多轮对话的后续模块提供支持;意图检测通常被认为是一个句子分类问题,通过算法从预定义的类别集合中,预测出用户目的的类别,此处的类别即对应着意图;与其他分类任务不同的是,意图检测的数据是口语文本,需要结合句子本身和语境,捕获真正的语义信息;而语义槽填充则通过标记句子中有意义的词语或记号来理解一段文字,它根据语义信息,为文本中的每个词语(字)打上标签,本质上是序列标注任务,利用标签,可以从文本中提取被明确定义的属性(即槽位),从而将用户意图转化为明确指令;相比之下,意图检测更关注用户输入的整体含义,语义槽填充则侧重于对文本细粒度的理解和
捕捉,如下表所示。
27.进一步地,数据是人工智能系统的基础,不论是基于规则,或是传统机器学习方法,还是现在常用的神经网络方法,常需要数以万计的高质量数据进行训练,才能获得准确、符合问题的参数;而任务型对话的应用场景,则更需要大量针对特定领域,并且符合日常对话逻辑、口语习惯的训练数据;甚至可以说,数据的好坏很大程度上决定对话系统的性能,而受制于任务型对话系统的研究现状,和本发明面向的特殊应用场景,暂无充足的开源数据集来完成任务,于是在本发明中通过自主构建数据集,从而支持模型实现任务型对话系统的功能;首先参考其他多轮对话任务以及日常口语习惯,构建普通场景语料(例如,问候、告别、闲聊等),再按照不同的意图类别,为本发明的实际应用场景(例如,天气查询、日程安排查询和影视查询)构建数据,并标注语义槽以提取用户输入的关键信息;接着为提高模型的泛化能力,对上述基础数据进行数据增强;一方面对语义槽进行同义词、近义词、联想词替换,使得数据集能够涵盖更多场景;另一方面对数据进行句式变换,使得数据集能够适应更多类型的口语表达;经过构建和增强的数据集在后续的过程中被证明是有效的,可以支持系统完成大部分语境下的多轮对话,但仍有一些特殊情况无法顺利完成,将这些无法顺利完成的数据记录下来,反馈给多轮对话系统并加入数据集重新训练,通过自监督的方式不断提高系统准确率和泛化能力。
28.步骤s20、控制所述自然语言理解模块对所述文本信息进行意图检测及语义槽填充,分别得到用户意图和实体信息。
29.所述步骤s20包括:步骤s21、预先将dietclassifier作为意图识别的分类器,将所述文本信息输入至所述分类器进行意图分类;步骤s22、对意图分类后的所述文本信息中的口语文本进行意图检测,得到所述文本信息的用户意图;步骤s23、基于语义信息将所述文本信息中的词语打上标签,并控制抽取器基于所述标签进行语义槽填充得到所述文本信息的实体信息。
30.具体地,依照自然语言理解模块的一般处理流程,针对意图检测任务,rasa nlu (rasa自然语言理解模块)设计分类器模块(classifier)进行分类;针对语义槽填充任务,rasa nlu 则设计分词器(tokenizer)、特征提取器(featurizer)、抽取器(extractors)等部分完成对输入文本的解析和关键信息提取,rasa 框架内容丰富、功能强大,集成众多组
件;在分类器模块中,包括基于关键词的方法、基于 mitie 语言模型的方法等;在分析语义槽时,提供高效的 mitie、spacy等语言模型,并为中文提供 jieba分词等工具,使得整个开源框架开源兼容中文;其中,当rasa框架本身提供的组件无法满足对话系统需求时,开发者可以通过框架提供的各类接口自定义组件,使得人工规则、传统机器学习及统计学习方法、前沿深度学习成果,都可以被按需集成在多轮对话系统中,使rasa框架可以被自由地应用于各种实际场景,极具灵活性、可扩展性;自然语言理解模块是任务型对话系统的核心模块之一,也是本发明在接收到用户输入后的第一个模块,其主要任务是理解文本信息中的用户意图,将所述用户意图进行正确的意图类别,并提取恰当的语义槽值;在这部分中,本发明主要基于rasa开源框架和针对任务设立的规则完成。
31.进一步地,若使模型能够处理文本信息,首先需要抽取所述文本信息的文本特征,将所述文本特征进行分词后嵌入向量空间表示;rasa 框架提供了支持中文的 jiebatokenizer 分词组件和 mitienlp 中文词向量工具,以完成中文任务;但它们有一定的局限性,首先基于中文分词的处理方法,由于分词误差可能导致级联错误,影响后续意图分类和语义槽值抽取的效果;而mitie 自然语言处理工具包,主要基于svm等机器学习算法,虽有较好的关键词抽取性能,但已逐渐被大型预训练语言模型超越,且训练速度慢;于是本发明采用基于大规模中文语料训练的预训练语言模型 bert-base-chinese,实现对中文文本的特征抽,所述预训练语言模型 bert-base-chinese是基于bert模型(bert模型主要输入是文本中各个字/词的原始词向量)丰富的预训练知识,以使得预训练语言模型模型可以广泛适用于各种下游任务和不用的语境,其基于完形填空的预训练任务也能够结合上下文信息,提升语义槽抽取的性能,如图4所示。
32.而rasa 框架提出了diet(dual intent entity transformer)框架用于意图分类和实体抽取;所述diet框架是一种用于意图分类和实体识别的多任务体系结构,如图5所示,所述diet框架能够以即插即用的方式结合语言模型的预训练单词嵌入,并将它们与单词和字符级 n-gram 稀疏特征结合起来,实验表明,即使没有预训练的嵌入,仅使用单词和字符级 n-gram 稀疏特征,diet 仍可以在复杂的自然语言理解数据集上取得优于其他模型的结果,并且训练速度远超微调的 bert 模型;所述diet框架是继承自transformerrasamodel 类,并基于 transformer 模型的框架,通过使用一个12层的transformer和相对位置注意力机制,对整个句子进行编码,并将transformer 输出的 cls 标记表示用于用户输入的意图分类,并与意图标签的语义向量空间进行相似度比较,计算出损失函数,其中,就收纳损失函数的目的是衡量模型模型预测的好坏;本发明使用dietclassifier 作为意图识别的分类器,能够较为准确地分类意图。
33.自然语言理解模块的另一个主要任务是语义槽填充,所述语义槽填充本质上是一个实体识别以及实体抽取问题;由于实体的多样性和不同语言表达的复杂性,采用多种抽取器组合的方式解决该问题,所述抽取器主要包括 diet 抽取器、正则表达式抽取器和条件随机场抽取器;所述diet抽取器是对于命名实体识别任务,在 transformer 输出的基础上,将结果通过条件随机场层获得上下文标记与输入序列标记的关系,从而获得实体预测;所述正则表达式抽取器则是通过在训练数据中定义查找表和/或正则表达式的方式抽取实体,该组件检查用户消息是否包含查找表之一的条目或匹配正则表达式之一;如果找到匹配项,则将该值提取为实体,所述正则表达式抽取器可以为一些特殊词汇或表达方式设置
规则,过滤掉特殊情况而导致的错误;而所述条件随机场抽取器实现了一个条件随机字段来进行命名实体识别,条件随机场可以被认为是一个无向马尔可夫链,其中时间步长是单词,状态是实体类,单词的特征(例如大写、pos 标记等)给出了某些实体类的概率,相邻实体标签之间的转换也是如此:然后计算并返回最可能的标签集;所述条件随机场抽取器可以更好地学习到文本中上下文之间的关系。
34.步骤s30、基于所述用户意图和所述实体信息控制所述多轮对话管理模块匹配出所述文本信息的响应结果,将所述响应结果反馈给所述用户,并展示用户对话的可视化界面。
35.所述步骤s40包括:步骤s31、基于解释器将所述用户意图和所述实体信息输入至追踪器中,得到所述用户的对话状态,并将所述对话状态发送至策略器;步骤s32、控制所述策略器基于所述对话状态进行动作响应,并基于响应后的动作输出文本对话;步骤s33、基于botfront框架将用户对话的可视化界面进行展示,并构建多语言会话代理。
36.具体地,rasa_core(多轮对话管理模块)负责完成多轮对话的管理,因为rasa_自然语言理解模块本身是只支持英文和德文,而本系统由于是中文,所以使用结巴分词器(jieba)作为中文的分词器(tokenizer)作为整个流水线的一部分;当使用rasa_自然语言理解模块做意图识别任务时,需要一个基于非监督方法训练好的 mitie的模型,类似于word2vec中的word embedding;利用自己创建的数据库训练该mitie 模型,使用结巴分词对整篇语料进行分词;具体而言,在ubuntu 操作系统下,先通过命令 sudo pip install jieba 安装结巴分词库,随后通过编译命令cmake来创建一个可执行的 wordrep 工具;最后训练生成了一个total_word_feature_extractor_chi.dat的二进制文件,所述二进制文件就是贯穿整个对话系统中的要用到的300维的词向量,有了所述词向量之后,就可以着手训练 nlu(自然语言理解)模型了,但是在训练之前,需先配置 pipeline,具体实现为[“nlp_mitie”,“tokenizer_jieba”,“ner_mitie”,“ner_synonyms”,“intent_featurizer_mitie”,“intent_classifier_sklearn”],其中,“nlp_mitie”用于初始化mitie,“tokenizer_jieba”通过用jieba做分词,用“ner_mitie”和“ner_synonyms”做实体识别,“intent_featurizer_mitie”做意图特征提取,“intent_classifier_sklearn”使用 sklearn 做意图识别;当sklearn 做意图识别时,用到的核心算法是支持向量机(support vector machine,svm),svm的输入特征为300维的句子中的每个单词的词向量相加再取平均的向量;其中,为了提高nlu模型的性能,通过改进rasa nlu,采用基于大规模中文语料训练的预训练语言模型bert-base-chinese,实现对中文文本的特征抽取。
[0037]
而rasa_core并非通过 if/else 条件判断来实现复杂的对话逻辑,而是通过机器学习方法来训练对话管理模型,所述机器学习方法既具有较好的可移植性,也具有良好的维护性;具体实现如图6所示,首先系统接受用户消息,将所述用户消息送入interpreter模块(解释器模块),识别并生成包含消息text(文本)、intent(用户意图)的字典;其所述interpreter模块对意图的识别通过paddlenlp深度学习模型实现的;之后通过tracker(追踪器)对对话状态进行追踪,其中,所述tracker主要用来接收并记录所述interpreter模型
识别的新消息;然后将当前的对话状态发送至policy(策略),所述policy选择响应哪一个action(动作),响应的action会被记录在tracker中,并返回响应action的结果给用户。
[0038]
进一步地,结合rasa和botfront框架进行操作的交互和可视化界面的展示,所述botfront框架可以构建高级多语言会话代理,例如,创建和训练故事(具体界面如图7所示),创建、训练和评估nlu模型(具体界面如图8所示),创建和编辑相应的响应(具体界面如图9所示),监控对话(具体界面如图10所示),审查和注释输入的nlu话语(具体界面如图11所示);本发明基于rasa开源框架和管道式结构快速构建任务型多轮对话系统,该系统具有一整套工程化流程,且模块清晰,可解释性强,支持多种语言,易于维护和扩展;还基于botfront开源框架实现图形化配置,本系统将复杂繁琐的配置过程以图形化的方式呈现,用户或管理者只需要进行简单的选择、填写、拖拽等操作即可快速配置对话,从而降低学习成本,并提高搭建效率;而利用botfront开源框架和前后端交互技术,用户只需要配置相关参数即可一键训练模型,此外,用户也可以随时更新、添加或修改对话语料,使用新语料重新训练模型以实现用户个性化服务。
[0039]
进一步地,如图12所示,基于上述基于rasa的任务型智能多轮对话方法,本发明还相应提供了基于rasa的任务型智能多轮对话系统,所述基于rasa的任务型智能多轮对话系统包括:数据获取模块51,用于基于rasa构建自然语言理解模块和多轮对话管理模块,并获取用户输入的文本信息;所述自然语言理解模块52,用于理解文本信息的用户意图,将所述用户意图输入到正确的意图类别中,并提取所述文本信息的语义槽值;所述多轮对话管理模块53,用于训练对话管理模型,并输出所述文本信息的回答文本;数据分析模块54,用于控制所述自然语言理解模块对所述文本信息进行意图检测及语义槽填充,分别得到用户意图和实体信息;结果展示模块55,用于基于所述用户意图和所述实体信息控制所述多轮对话管理模块匹配出所述文本信息的响应结果,将所述响应结果反馈给所述用户,并展示用户对话的可视化界面。
[0040]
进一步地,如13所示,基于上述基于rasa的任务型智能多轮对话方法,本发明还相应提供了一种终端,所述终端包括处理器10、存储器20、显示器30;图13仅示出了终端的部分组件,但是应理解的是,并不要求实施所有示出的组件,可以替代的实施更多或者更少的组件。
[0041]
所述存储器20在一些实施例中可以是所述终端的内部存储单元,例如终端的硬盘或内存。所述存储器20在另一些实施例中也可以是所述终端的外部存储设备,例如所述终端上配备的插接式硬盘,智能存储卡(smart media card,smc),安全数字(secure digital,sd)卡,闪存卡(flash card)等。进一步地,所述存储器20还可以既包括所述终端的内部存储单元也包括外部存储设备。所述存储器20用于存储安装于所述终端的应用软件及各类数据,例如所述安装终端的程序代码等。所述存储器20还可以用于暂时地存储已经输出或者将要输出的数据。在一实施例中,存储器20上存储有基于rasa的任务型智能多轮对话的程序40,该基于rasa的任务型智能多轮对话的程序40可被处理器10所执行,从而实
现本技术中基于rasa的任务型智能多轮对话方法。
[0042]
所述处理器10在一些实施例中可以是一中央处理器(central processing unit,cpu),微处理器或其他数据处理芯片,用于运行所述存储器20中存储的程序代码或处理数据,例如执行所述基于rasa的任务型智能多轮对话方法等。
[0043]
所述显示器30在一些实施例中可以是led显示器、液晶显示器、触控式液晶显示器以及oled(organic light-emitting diode,有机发光二极管)触摸器等。所述显示器30用于显示在所述终端的信息以及用于显示可视化的用户界面。所述终端的部件10-30通过系统总线相互通信。
[0044]
在一实施例中,当处理器10执行所述存储器20中分屏窗口的界面显示程序40时实现以下步骤:基于rasa构建自然语言理解模块和多轮对话管理模块,并获取用户输入的文本信息;控制所述自然语言理解模块对所述文本信息进行意图检测及语义槽填充,分别得到用户意图和实体信息;基于所述用户意图和所述实体信息控制所述多轮对话管理模块匹配出所述文本信息的响应结果,将所述响应结果反馈给所述用户,并展示用户对话的可视化界面。
[0045]
其中,所述基于rasa构建自然语言理解模块和多轮对话管理模块,并获取用户输入的文本信息,之前还包括:基于语义数据和口语习惯构建场景语料,并根据不同的意图类别对所述场景语料进行分类以构建文本信息的数据类型。
[0046]
其中,所述控制所述自然语言理解模块对所述文本信息进行意图检测及语义槽填充,分别得到用户意图和实体信息,之前还包括:基于大规模中文语料训练的预训练语言模型实现对所述文本信息的特征进行抽取得到文本特征,并将所述文本信息进行分词得到目标文本信息;基于所述文本特征将所述目标文本信息嵌入到向量空间中,以使得所述自然语言理解模块处理所述文本信息。
[0047]
其中,所述控制所述自然语言理解模块对所述文本信息进行意图检测及语义槽填充,分别得到用户意图和实体信息,具体包括:预先将dietclassifier作为意图识别的分类器,将所述文本信息输入至所述分类器进行意图分类;对意图分类后的所述文本信息中的口语文本进行意图检测,得到所述文本信息的用户意图;基于语义信息将所述文本信息中的词语打上标签,并控制抽取器基于所述标签进行语义槽填充得到所述文本信息的实体信息。
[0048]
其中,所述抽取器包括diet抽取器、正则表达式抽取器和条件随机场抽取器。
[0049]
其中,所述控制所述自然语言理解模块对所述文本信息进行意图检测及语义槽填充,分别得到用户意图和实体信息,之后还包括:当rasa提供的组件不足时,获取所述rasa的组件接口,并基于所述组件接口接入不同的组件。
[0050]
其中,所述基于所述用户意图和所述实体信息控制所述多轮对话管理模块匹配出所述文本信息的响应结果,将所述响应结果反馈给所述用户,并展示用户对话的可视化界面,具体包括:基于解释器将所述用户意图和所述实体信息输入至追踪器中,得到所述用户的对话状态,并将所述对话状态发送至策略器;控制所述策略器基于所述对话状态进行动作响应,并基于响应后的动作输出文本对话;基于botfront框架将用户对话的可视化界面进行展示,并构建多语言会话代理。
[0051]
其中,所述数据类型包括天气查询、日程安排查询和影视查询。
[0052]
综上所述,本发明提供一种基于rasa的任务型智能多轮对话方法及相关设备,所述方法包括:基于rasa构建自然语言理解模块和多轮对话管理模块,并获取用户输入的文本信息;控制所述自然语言理解模块对所述文本信息进行意图检测及语义槽填充,分别得到用户意图和实体信息;基于所述用户意图和所述实体信息控制所述多轮对话管理模块匹配出所述文本信息的响应结果,将所述响应结果反馈给所述用户,并展示用户对话的可视化界面。本发明基于rasa开源框架和管道方法构建对话系统,各模块任务明确且相互独立,将复杂繁琐的配置过程以图形化的方式呈现,提高了搭建效率;还通过botfront开源框架和前后端交互技术,只需要配置相关参数即可一键训练模型,并实现用户个性化服务。
[0053]
需要说明的是,在本文中,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者装置不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者装置所固有的要素。在没有更多限制的情况下,由语句“包括一个
……”
限定的要素,并不排除在包括该要素的过程、方法、物品或者装置中还存在另外的相同要素。
[0054]
当然,本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,是可以通过计算机程序来指令相关硬件(如处理器,控制器等)来完成,所述的程序可存储于一计算机可读取的计算机可读存储介质中,所述程序在执行时可包括如上述各方法实施例的流程。其中所述的计算机可读存储介质可为存储器、磁碟、光盘等。
[0055]
应当理解的是,本发明的应用不限于上述的举例,对本领域普通技术人员来说,可以根据上述说明加以改进或变换,所有这些改进和变换都应属于本发明所附权利要求的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1