一种基于覆盖率分析和链路追踪的精准测试方法与流程
1.本发明属于软件测试技术领域,特别是涉及一种基于覆盖率分析和链路追踪的精准测试方法。
背景技术:
2.随着分布式、微服务架构兴起,业务链路越来越长,软件越来越复杂,测试的挑战性也越来越大。
3.如中国专利cn113157549a提供一种软件代码测试系统包括子引擎和存储测试用例的测试用例数据库。测试用例子引擎在多个软件代码模块上运行每个测试用例,并且软件代码覆盖范围确定子引擎识别在软件代码模块中的每一个中包括的每一种软件代码方法的相应的软件代码覆盖范围。然后,测试用例/软件代码覆盖范围映射子引擎将在软件代码模块中的每一个中包括的每一种软件代码方法中的相应的软件代码覆盖范围与在软件代码模块上运行的相应的测试用例进行映射,以提供测试用例/软件代码覆盖范围映射,测试套件优化子引擎使用它来生成包括测试用例的子集的测试套件,这些子集可以使用最少数量的测试用例来提供软件代码覆盖范围的期望程度。
4.又如中国专利cn107463495a提供一种代码增量发布软件测试方法及装置,可以大幅节省测试人员的时间和成本,减少系统的整体变化和部署失败率、中国专利cn114035790a提供一种基于测试例库索引的软件代码获取方法及服务端,可关联得到对应的功能代码块,能够更加准确地得到相应功能的功能代码块,同时所有功能代码块均通过对应的测试用例进行了测试,保证了代码的可用性。
5.然而,程序代码尤其是公共代码改动的关联分析,如何评估测试的充分性,如何提升测试的有效性,是当前测试面临的重要课题。
技术实现要素:
6.本发明的目的在于提供一种基于覆盖率分析和链路追踪的精准测试方法,现在行业上有开源的覆盖率分析工具,通过探针技术,获取所有的用例运行时的覆盖率信息,从而生成代码覆盖率报告;也有链路追踪监控的组件,可以获取请求的调用链路信息,实现请求级的调用链路跟踪,但是,存在以下技术问题:1、虽然可实现覆盖率分析,也能帮助梳理测试遗漏场景及无效代码,但这个是整体的覆盖率分析,而且覆盖率信息文件缺少时间维度的跟踪,也缺少增量代码覆盖率层级的分析;2、链路追踪体现在请求级别,无法体现在用例级别,缺少用例维度的链路追踪,无法关联增量代码与用例,实现精准推荐。
7.为解决上述技术问题,本发明是通过以下技术方案实现的:本发明为一种基于覆盖率分析和链路追踪的精准测试方法,通过增量代码分析,结合用例链路数据梳理,实现精准测试;
一、通过探针技术,动态插桩,识别增量代码,记录测试过程中代码覆盖率信息,并定时主动上传到服务端;服务端根据覆盖率信息结合源码染色,生成覆盖率报告。通过分析未覆盖代码,挖掘漏测场景及无效代码。
8.二、通过链路追踪,记录用例的链路轨迹(含服务、类、方法信息),版本提交时,分析增量代码,梳理变更的方法,匹配用例的链路轨迹,实现用例的精准推荐,具体包括以下步骤:步骤一:数据采集:s11:用例执行时,用例对应的每个请求在header里均带有用例标,具体的,用例执行时带用例标,一个用例可能对应多个请求,用例标是自动化测试平台自动生成,用例对应的每个请求在header里面都需要带用例标;其中,header表示请求头部;s12:请求执行时,链路追踪探针采集运行日志到监控平台,日志包含用例标和traceid信息;一个用例对应多个请求,每个请求在到达service的时候,探针检测traceid;traceid指链路追踪id,由链路追踪探针自动生成;service指被访问服务;若请求在service中调用其他服务,则获取到请求在各service的调用信息,通用日志sdk(软件开发工具包)采集调用信息日志到监控平台;s13:测试用例执行完毕后,对采集的数据进行落库;步骤二:流水线调用:获取增量文件并对增量代码分析落库、对推荐用例结果集去重后完成精准推荐用例,并在自动化测试平台根据用例id自动回归,实现精准测试。
9.通过覆盖率数据,对未覆盖代码分析,挖掘遗漏场景,减少漏测;通过采集用例链路数据,实现用例的自动链路梳理和分析,可以辅助快速定位问题;通过分析增量代码,对比用例链路数据,实现精准推荐测试用例,缩小测试范围,减少无效人力投入。
10.进一步地,所述traceid信息的获取方式为:用例对应的每个请求在到达service时,探针均需检测traceid,若不存在traceid,或者traceid为0/null,则探针为请求创建唯一的traceid;用例标与traceid 为一对多的对应关系;一个用例对应一个用例标,一个用例对应多个请求,一个请求对应一个traceid,从而建立了用例标(用例标表示为:x-request-id)与traceid 一对多的对应关系。
11.进一步地,获取到请求在各service的调用信息的方法为:当请求在service中调用其他服务时,探针将当前请求的traceid透传下去,在每个service中都存在对应traceid的调用记录,从调用记录中获取到请求在各service的调用信息;traceid透传用的是skywalking(skywalking:一款国产的开源框架,是分布式系统的应用程序性能监视工具)的功能。traceid 透传主要实现了请求在各服务间的调用跟踪,请求与traceid是一对一的,traceid在透传后,在每个service中都存在对应traceid的调用记录。
12.进一步地,所述调用信息包括用例标、traceid、服务名、类名、方法。
13.进一步地,采集的数据进行落库的方法为:测试用例执行完毕后,自动化测试平台调用精准测试平台接口,把项目id和用例标传至精准测试平台;精准测试平台根据用例标从监控平台查询运行日志,获取到用例对应的所有的
traceid,并根据@timestamp字段对traceid升序排序;@timestamp:时间戳,字段名,由lop平台返回;按顺序遍历每一个traceid,从监控平台查询调用信息日志,获取traceid对应的所有调用信息记录并按@timestamp字段对traceid升序排序;每一条记录对应一个调用,每一个调用插入一条数据库记录;所述数据库记录字段包含:项目id、测试用例id、traceid、servic(服务)、class(类)、method(方法)。
14.进一步地,所述流水线调用的步骤为:发起devops流水线,从gitlab中拉取项目代码并编译部署完成;流水线发起精准测试分析,并传递项目id给精准测试平台。
15.进一步地,所述精准推荐用例的方法为:s31:根据项目id获取自动化测试平台中关联的项目信息,项目信息包括:项目名称、服务名称、gitlab代码地址;s32:根据codeurl通过git diff 获取到项目当前版本与上一版本的增量文件清单,并过滤非代码文件,利用javaparser分析java类文件,获取增量文件对应的差异id;s33:增量代码分析落库;s34:用例精准推荐:根据差异id获取明细表中对应的记录,遍历每一条记录,根据项目id、服务名称、类、方法与调用信息做匹配,只要匹配上面4个条件的记录,则获取对应的用例id,加入到推荐用例结果集中;遍历完成后对推荐用例结果集去重,完成精准推荐用例。
16.进一步地,利用javaparser分析java类文件的方法为:如果文件是新增的,则返回该文件所有的方法;如果文件是修改的,则比对新旧两个分支/tag/版本文件对应的方法清单,如果方法是新增的,加入返回方法结果集;如果方法已存在,则比对方法的md5值,如果一致则方法不变,如果不一致则表示方法是变更的,加入返回方法结果集。
17.进一步地,所述增量代码分析落库的方法为:主表:每次增量代码分析均插入一条记录,记录包含差异id、项目id、gitlab代码路径、创建时间;明细表:每一个新增/变更的方法,对应一条明细记录,明细记录信息包含:差异id、类、方法。
18.进一步地,完成精准推荐用例后,调用自动化测试平台接口,传入精准推荐用例集,自动化测试平台根据用例id自动回归,实现精准测试。
19.本发明具有以下有益效果:本发明通过探针技术,动态插桩,识别增量代码,记录测试过程中代码覆盖率信息,并定时主动上传到服务端;服务端根据覆盖率信息结合源码染色,生成覆盖率报告。
20.通过分析未覆盖代码,挖掘漏测场景及无效代码,通过链路追踪,记录用例的链路轨迹,版本提交时,分析增量代码,梳理变更的方法,匹配用例的链路轨迹,实现用例的精准推荐。
21.当然,实施本发明的任一产品并不一定需要同时达到以上所述的所有优点。
附图说明
22.为了更清楚地说明本发明实施例的技术方案,下面将对实施例描述所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
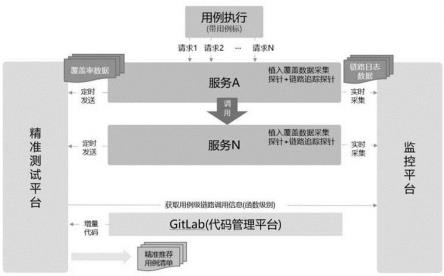
23.图1为本发明的架构图;图2为本发明实施例的运行日志;图3为本发明实施例的调用信息样例;图4为本发明实施例的数据库记录字段;图5为本发明实施例的增量代码分析落库-主表;图6为本发明实施例的增量代码分析落库-明细表。
具体实施方式
24.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
25.请参阅图1所示,本发明为一种基于覆盖率分析和链路追踪的精准测试方法,包括精准测试平台、监控平台,基于代码覆盖率/增量代码覆盖率用于评估测试充分性及挖掘测试遗漏场景,基于链路追踪实现测试用例链路自动梳理,基于增量代码分析和链路分析实现的精准测试,具体包括以下步骤:步骤一、数据收集:
①
用例执行时带用例标(x-request-id),一个用例可能对应多个请求,用例标是自动化测试平台自动生成,格式为:测试用例id+“_”+时间戳(yyyymmddhhmmss),如testcase001_20221012102424。用例对应的每个请求在header里面都需要带用例标,如:x-request-id:testcase001_20221012102424;通过用例标标识本次执行的用例,便于从后面的日志数据中筛选出来;
②
一个用例对应多个请求,每个请求在到达service的时候,探针检测traceid,若不存在traceid,或者traceid为0/null,则探针为请求创建唯一的traceid。traceid的形式为:"traceid":"8472.162.16653854468120209";也即一个用例对应一个用例标,一个用例对应多个请求,一个请求对应一个traceid,从而建立了用例标(x-request-id)与traceid 一对多的对应关系;作为本技术提供的一个实施例,优选的,请求执行时,链路追踪探针会采集运行日志(running log)到监控平台,运行日志含x-request-id信息和traceid信息,见图2所示;
③
如果请求在service中调用其他服务,探针会把当前请求的traceid透传下去;通用日志sdk会采集调用信息日志(pfm log)到监控平台,调用信息包含:用例标(x-request-id),traceid,服务名(appname),类名(class),方法(method)等,样例见图3;traceid透传用的是skywalking的功能;traceid 透传主要实现了请求在各服务
间的调用跟踪,请求与traceid是一对一的,traceid在透传后,在每个service中都存在对应traceid的调用记录,从而获取到请求在各service的调用信息;skywalking即一款国产的开源框架,是分布式系统的应用程序性能监视工具;
④
数据采集落库:i. 测试用例执行完毕后,自动化测试平台调用精准测试平台接口,把项目id(projectid)和用例标(x-request-id)传给精准测试平台;ii. 精准测试平台根据用例标x-request-id从监控平台查询运行日志(running log),获取到用例对应的所有的traceid,并根据@timestamp字段升序排序;iii. 按顺序遍历每一个traceid,从监控平台查询调用信息日志(pfm log),获取traceid对应的所有调用信息记录并按@timestamp字段升序排序,每一条记录对应一个调用,每一个调用插入一条数据库记录;数据库记录字段包含:项目id(projectid,自动化测试平台传递过来),测试用例id(testcaseid,根据x-request-id截取
”‑”
前半段),traceid,servic (对应日志的appname),class (对应日志的class),method(对应日志的method);见图4。
26.步骤二、流水线调用:
①
devops流水线发起,从gitlab中拉取项目代码并编译部署完成;其中,devops即development(开发)和 operations(运维)两个词的组合,指开发运维一体化;gitlab即一个用于仓库管理系统的开源项目,使用git作为代码管理工具,这里指私有化部署的gitlab服务;
②
流水线发起精准测试分析,并传递项目id(projectid)给精准测试台:i. 根据项目id(project id)获取测试平台中关联的项目信息,项目信息包括:项目名称,服务名称(servicename),gitlab代码地址(codeurl);ii. 根据codeurl,通过git diff 获取到当前版本与上一版本的增量文件清单,并过滤非代码文件(文件后缀不为.java),利用javaparser分析java类文件:其中,codeurl即项目对应在gitlab上面的代码地址;git diff即git 的一个命令行工具,git diff 主要用于比较差异,查看差异,可以比较不同分支差异、不同区域(git的分区)差异、不同提交记录之间差异;javaparser即一款开源的java代码分析工具;a) 如果文件是新增的,则返回该文件所有的方法(层级为services-》class-》method);b) 如果文件是修改的,则比对新旧两个分支/tag/版本该文件对应的方法list,如果方法是新增的,加入返回方法结果集;如果方法已存在,则比对方法的md5值(方法体删除备注信息后,获取整个的md5值),如果一致则方法不变,如果不一致则表示方法是变更的,加入返回方法结果集。其中,tag即标签,md5即一种被广泛使用的密码散列函数;iii. 增量代码分析落库:a) 主表:每次增量代码分析插入一条记录,记录包含差异id(id,自增列),项目id(projected,调用传入),gitlab代码路径(code_url,平台配置查询返回),创建时间(create_time,系统当前时间),详见图5;b) 明细表:每一个新增/变更的方法,对应一条明细记录,明细记录信息包含:差异id(diff_id,对应主表id)、类(class_file),方法(method_name),详见图6;
iv. 用例精准推荐:根据差异id(diff_id)获取明细表中对应的记录,遍历每一条记录,根据项目id(projectid,调用传入),服务名称、(servicename,平台配置查询返回),类(class),方法(method_name)与步骤一数据收集中的调用信息做匹配,当项目id、服务名称、类、方法全部匹配成功后,则获取其用例id(testcaseid),加入到推荐用例结果集中,遍历完成后对推荐用例结果集去重,则完成精准推荐用例;v. 调用自动化测试平台接口,传入精准推荐用例集,自动化测试平台根据用例id自动回归,实现精准测试。
27.一种基于覆盖率分析和链路追踪的精准测试方法,通过探针采集覆盖率数据,分析增量代码,结合链路追踪实现精准测试;通过覆盖率数据,对未覆盖代码分析,挖掘遗漏场景,减少漏测;通过采集用例链路数据,实现用例的自动链路梳理和分析,可以辅助快速定位问题;通过分析增量代码,对比用例链路数据,实现精准推荐测试用例,缩小测试范围,减少无效人力投入。
28.本发明是一种简单的能快速实现精准测试的方法,通过增量代码分析,结合用例链路数据梳理,实现精准测试,如果实现用例与代码双向绑定,分析用例执行与函数分支的关联关系,结合增量代码的函数分支变更分析,能实现更小粒度的精准测试。
29.在本说明书的描述中,参考术语“一个实施例”、“示例”、“具体示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不一定指的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任何的一个或多个实施例或示例中以合适的方式结合。
30.以上公开的本发明优选实施例只是用于帮助阐述本发明。优选实施例并没有详尽叙述所有的细节,也不限制该发明仅为所述的具体实施方式。显然,根据本说明书的内容,可作很多的修改和变化。本说明书选取并具体描述这些实施例,是为了更好地解释本发明的原理和实际应用,从而使所属技术领域技术人员能很好地理解和利用本发明。本发明仅受权利要求书及其全部范围和等效物的限制。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1