一种基于DDAG-SVM的变压器故障诊断方法与流程
一种基于ddag-svm的变压器故障诊断方法
技术领域
1.本发明涉及一种变压器故障诊断方法,尤其涉及一种基于ddag-svm的变压器故障诊断方法。
背景技术:
2.随着新型电力系统的建设,变压器故障诊断的需求越来越迫切,目前常见的有神经网络、灰色系统理论、模糊聚类等方法,这些方法对于变压器的故障诊断起到了一定的作用。然而上述方法还存在一定的缺陷,比如人工神经网络等基于知识的方法需要获取无穷多的故障样本,且训练时间长、存在局部最优解等问题。
3.支持向量机(support vector machine,简称svm)是一种基于统计学习理论的新型学习方法,与传统的学习方法不同,支持向量机是结构风险最小化方法的近似实现,能够在少量样本的情况下,自动建立优秀的故障分类模型,得到较好的分类结果。变压器的故障诊断问题则为一个多分类问题,为此将svm用于变压器的故障诊断需将svm进行多分类扩展。策导向无环图(ddag)就是基于此类问题进而提出的。这种方法的训练过程类似于“一对一”方法,k类别问题需要求解个支持向量机分类器,这些分类器构成一个有向无环图。该有向无环图中含有个内部节点和k个叶节点,每个节点对应一个二类分类器,从而实现多分类问题的诊断,但同时也带来参量选择的计算量过大、容错性差等问题。
技术实现要素:
4.发明目的:针对以上问题,本发明提出一种基于ddag-svm的变压器故障诊断方法,能够降低容错率,提高分类精度,从而提高故障诊断的准确率,更好的为运维人员提供有效的帮助。
5.技术方案:本发明所采用的技术方案是一种基于ddag-svm的变压器故障诊断方法,该方法中的ddag-svm算法采用支持向量机及其对应拉格朗日乘子,计算具有最小样本间隔的类别,将与最小样本间隔最近的样本数据用来训练下一层结点,并且对结点训练后的分类器中的核函数和惩罚因子进行优化,所述对结点训练后的分类器中的核函数和惩罚因子进行优化的步骤包括:
6.(1)根据选定核函数和ddag-svm优化的目标函数,确定待优化的核函数的参数和惩罚因子;
7.(2)设置核函数参数和目标函数的惩罚因子的取值范围,优化核函数参数和惩罚因子的取值;
8.(3)根据核函数参数和惩罚因子的取值范围,计算样本中个体的适应度,以此来随机初始化ddag-svm样本;所述核函数是高斯核函数,所述目标函数为故待优化的核函数的参数为参数γ,待优化的惩罚因子为参数c。
9.所述设置核函数参数和目标函数的惩罚因子的取值,其中核函数参数γ取值和目
标函数的惩罚因子c的取值分别为:
[0010][0011][0012]
式中,ai表示二进制数,是对核函数参数γ以及惩罚因子c的二进制编码,γ
min
,γ
max
分别表示核函数参数γ的最大值和最小值,c
min
,c
max
分别表示惩罚因子c的最大值和最小值。
[0013]
(4)对初始化后的样本进行分层k折交叉验证,得到核函数和惩罚因子的最优参数。
[0014]
所述对初始化后的样本进行分层k折交叉验证,包括以下步骤:
[0015]
(41)将全部训练集分成k个不相交的数据子集,并且保证每次划分中包含类别的比例数和原数据相同;
[0016]
(42)每次从分好的数据子集中取出一个作为测试集,其它k-1个作为训练集;
[0017]
(43)通过训练集训练得出模型,并将所述模型放到测试集上得到分类率;
[0018]
(44)计算k次求得的分类率的平均值,作为该模型的真实分类率,从而得出最优评价结果,对应核函数和惩罚因子的最优参数。
[0019]
有益效果:相比于现有技术,本发明具有以下优点:(1)本发明通过对结点的优化,提高结点容错能力,从而保证结点分类精度,可以有效地提高变压器故障数据分类能力;(2)本发明利用分层k折交叉法对核函数参数和惩罚因子进行优化,大大降低由一次随机划分带来的偶然性,同时通过多次划分,多次训练,模型也能遇到各种各样的数据,从而提高其泛化能力,提升变压器故障数据的识别准确性;(3)通过运用本发明方法进行变压器故障类型的诊断,可以更准确的区分出变压器发生的故障类型,以便运行人员能够有针对性的进行处理。本发明所改进的ddag-svm算法,在原有的ddag-svm算法基础上,在对结点的优化同时,同步优化核函数和误差惩罚因子参数,降低容错率,提高分类精度,从而提高故障诊断的准确率,更好的为运维人员提供有效的帮助。通过提取变压器内部过热故障典型特征量进行了算法验证,实验结果表明,本发明的方法对变压器过热故障诊断具有重要的理论意义和工程应用价值。
附图说明
[0020]
图1是本发明所述的基于ddag-svm的变压器故障诊断方法的流程图。
具体实施方式
[0021]
下面结合附图和实施例对本发明的技术方案作进一步的说明。
[0022]
在变压器的故障诊断中,变压器的故障类型可分为低能放电(low energy discharge,l.e.d)、高能放电(high energy discharge,h.e.d)、局部放电(partial discharge,p.d)、低温过热(low temperature overheating,l.o,t<300℃)、中温过热
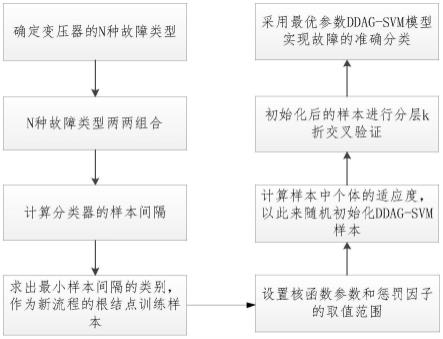
(mediate temperature overheating,m.o,300℃<t<700℃)、高温过热(high temperature overheating,h.o,t>700℃)故障类型。假设变压器的故障训练样本为s={s1,s2,s3,s4,s5,s6}。s1、s2、s3、s4、s5、s6分别表示低能放电(l.e.d)、高能放电(h.e.d)、局部放电(p.d)、低温过热(l.o)、中温过热(m.o)、高温过热(h.o)故障类型的训练样本。本发明所述的基于ddag-svm的变压器故障诊断方法,用于变压器的故障分类,实现流程如图1所示。包括以下步骤:
[0023]
(1)训练二类分类器,对6种故障类型任意两两组合,形成15组二分类svm;
[0024]
(2)根据支持向量机及其对应拉格朗日乘子,计算样本之间的间隔;
[0025]
(3)寻找具有最小样本间隔的类别(sa,sb):sa,sb作为新流程的根结点训练样本;
[0026]
(4)寻找与sa,sb距离最近的样本数据用来训练下一层结点;
[0027]
(5)对结点优化后的分类器中的核函数和惩罚因子进行优化,具体步骤如下:
[0028]
(51)首先根据选定核函数和ddag-svm优化的目标函数,确定待优化的核函数的参数和惩罚因子,这里选择是高斯核函数k(xi,xj)=exp(-γ||x
i-xj||2),γ>0,目标函数为关联目标yi(ω
t
φ(xi)+b)≥1-ξi;式中γ为样本的几何间隔,xi任意点,xj为中心点,ω为平面的法向量,t为维数,ξi为松弛因子,y样本的标记值,b为偏置值。
[0029]
(52)设置核函数参数和目标函数的惩罚因子的取值范围,其中核函数参数γ取值和目标函数的惩罚因子c的取值分别为:
[0030][0031][0032]
式中,ai表示二进制数,是对核函数参数γ以及惩罚因子c的二进制编码。
[0033]
(53)根据核函数参数和惩罚因子的取值范围,计算样本中个体的适应度,以此来随机初始化ddag-svm样本;
[0034]
(54)对初始化后的样本进行分层k折交叉验证:
[0035]
(541)将全部训练集s分成k个不相交的数据子集,并且保证每次划分中包含类别的比例数和原数据相同,如原数据有三类,比例为1∶2∶1,那么划分的k折中,每一折中的数据类别保持着1∶2∶1的比例;
[0036]
(542)每次从分好的数据子集中里面取出一个作为测试集,其它k-1个作为训练集;
[0037]
(543)通过训练集训练得出模型,并将这个模型放到测试集上得到分类率;
[0038]
(544)计算k次求得的分类率的平均值,作为该模型或者假设函数的真实分类率,从而得出一个最优评价结果,通过最优评价结果获得核函数和惩罚因子的最优参数。
[0039]
(6)最终ddag-svm模型采用最优参数实现故障的准确分类。
[0040]
算法效果验证:
[0041]
为验证所提算法的有效性和优越性,基于上述流程,开展实际的变压器故障诊断实验,并与常用的四种方法相对比,其实验结果如表1所示。
[0042]
表1变压器故障诊断实验结果
[0043][0044]
从表1可以看出,所提方法可以对变压器的6种故障类型均可以作出正确的诊断,bp神经网络法、灰色系统理论法和原始ddag-svm均存在一处错误;ahp模糊聚类法存在三处错误。诊断实验的结果进一步验证所提方法的优越性。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1