基于语义变化的视频质量评估方法
1.本发明涉及计算机视觉技术领域,尤其是基于语义变化的视频质量评估方法。
背景技术:
2.视频质量评估即video quality assessment(vqa)。其主要任务是给定一个视频片段,预测人类对视频片段感知质量。随着近年来视频质量评估不断发展,出现了大量评估效果好且运行速度快的视频质量评估模型。现有的全参考和半参考视频质量评估的研究取得了一定的效果,但由于对原始视频的依赖性,这两种方法往往并不实用。因为在实际生活中原始未失真的视频往往不易获得,我们观看到的视频往往需要进行压缩及传输,此过程中产生的混合视频失真难以估计,故无参考视频质量评价甚至是基于用户产生视频的无参考质量评价在将来会具有更广泛的应用。
3.目前学术界在无参考视频质量评估问题上采用的主流框架是提取视频空间特征后用gru(gate recurrent unit)建模时序信息。在这主流的框架中,怎样让特征更好的表现视频失真程度和怎样建立视频帧在时序上的联系是本发明解决的问题。因此本发明采用提取多尺度特征和边缘检测的方法加强对视频模糊程度的感知,在transformer block中用q去查询相邻帧的语义信息的变化,提升模型对视频抖动、模糊等运动失真的感知。
技术实现要素:
4.本发明提出基于语义变化的视频质量评估方法,能够有效地提取视频的时空特征,使得质量评价模型获取的视频失真信息更加全面。
5.本发明采用以下技术方案。
6.基于语义变化的视频质量评估方法,包括以下步骤;
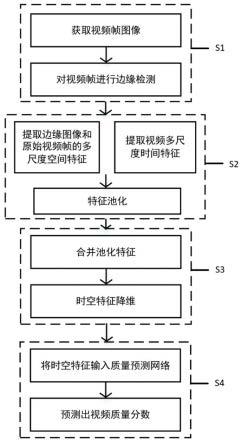
7.步骤s1:对于移动设备拍摄的不同场景的视频,对视频的每一个帧提取边缘特征;
8.步骤s2:将视频每一帧的边缘与原始图像分别输入空间特征提取网络,获取视频的多尺度空间特征,同时将视频输入时间特征提取网络,获取多尺度时间特征,对多尺度特征进行多频率分量池化和标准池化;
9.步骤s3:将池化后的结果合并,获得视频的时空特征,并将时空特征降维;
10.步骤s4:将降维后的视频时空特征输入质量预测网络建模时序关系,进而预测出整体视频的质量分数。
11.所述步骤s1具体包括以下步骤;
12.步骤s11:步骤s1的视频划分为视频帧后,利用改进的边缘检测算子提取每个视频帧的边缘信息;
13.步骤s12:利用改进的边缘检测算子提取边缘信息,获得视频边缘r,令r={cannyi},i=1,2,...,t,表示一个视频序列中所有检测结果的集合,其中t表示一个视频序列中帧的数量,cannyi表示一个视频序列中的第i帧的边缘检测图像。
14.步骤s12中,提取边缘信息的方法具体为:
15.首先使用一个较大的5
×
5的高斯卷积核进行滤波,能更大程度去除图像尖锐噪声;接着使用改进的sobel算子对图像进行梯度幅值和梯度方向的计算;然后依据梯度幅值和梯度方向对图像边缘进行非极大值抑制操作。
16.sobel算子如下:
[0017][0018]
梯度方向的计算方法如下:
[0019]gleft
=sobel_left*frame and g
right
=sobel_right*frame
ꢀꢀꢀ
公式二;
[0020][0021][0022]
其中frame表示视频帧图像,sobel_left表示左斜对角方向上的sobel算子,sobel_right表示右斜对角方向上的sobel算子,g
left
表示图像在左斜对角方向上的梯度幅值,g
right
表示图像在右斜对角方向上的梯度幅值,g表示一个视频帧的梯度幅值,θ表示图像的梯度方向。
[0023]
步骤s2具体包括以下步骤;
[0024]
步骤s21:将处理后视频帧的边缘图像r和原始视频帧分别输入到空间特征提取网络,根据模型的迁移学习理念,所述空间特征提取网络采用在imagenet上预训练的convnext-t基础上去掉最后面的池化层和全连接层,对于convnext-t的4个阶段,抽取每一个阶段的特征,每一个阶段输出的特征尺度不同,称为多尺度特征;
[0025]
步骤s22:将视频输入时间特征提取网络,所述时间特征提取网络采用的是在kinetics-400视频数据集上预训练slowfast网络中fast流,表示为slowfastf,其可以产生具有高时间分辨率的运动特征,对于slowfastf获得的时间范围内的视频运动特征的表达,同样提取多尺度特征;
[0026]
步骤s23:对于多尺度的特征使用优于全局平均池化的多个频率分量池化的方法来压缩单个帧的特征。
[0027]
步骤s3具体包括以下步骤;
[0028]
步骤s31:由于slowfastf的时间步幅为2,为了匹配运动管道的时间分辨率,对空间、边缘特征张量的每两帧进行采样,即i=1,3,5,...,t,然后将沿通道维度的空间、边缘和时间的卷积特征连接;
[0029]
步骤s32:为了建立视频时间维度的相关性,采用改进的transformer block,首先使用全连接层对帧级特征向量执行降维,降维到128维张量,记为feature。
[0030]
所述步骤s4具体包括以下步骤;
[0031]
步骤s41:对于降维后的128维特征向量,在输入序列中加入一个特殊的token,记为feature
cls
,用于学习到整个序列的特征,再加上位置编码e
pos
,具体操作如下:
[0032]
f0=[feature
cls
;feature1;feature3;
…
;feature
t
]+e
pos
ꢀꢀ
公式五;
[0033]
其中featurei表示视频第i帧(i=1,3,5,...,t)的时空特征;
[0034]
步骤s42:处理后的向量输入改进的transformer block;
[0035]
步骤s43:对于transformer block输出的特征向量,使用全连接层将状态序列映射到帧级质量分数;
[0036]
步骤s44:对于帧级质量分数,采用平均池将帧级质量分数临时聚合到整体视频质量分数。
[0037]
所述改进的transformer block操作如下:
[0038]
相邻视频帧语义信息的差异表现为视频的变化,相邻帧的变化是导致视频产生伪影、抖动等失真的重要因素,
[0039]
首先计算相邻帧的特征变化:
[0040]
feature_differencei=feature
i+1-featurei,0≤i<t-1
[0041]
feature_differencei=0,i=t-1
ꢀꢀꢀ
公式六;
[0042]
给定一个序列feature作为输入,自注意模块首先将feature和feature_difference投影到查询q、键k、值v、特征差d矩阵中,如下所示:
[0043]
q=linear(feature),k=linear(feature),v=linear(feature)
ꢀꢀꢀ
公式七;
[0044]
d=linear(feature_difference)
ꢀꢀꢀ
公式八;
[0045]
其中,linear表示全连接投影,feature_differnece表示相邻帧的特征变化;然后用q去查询k和特征差d得到查询矩阵m,m中的元素代表q对k和d的注意值:
[0046][0047][0048][0049]
其中,m
qk
表示q对k的注意力矩阵,m
qd
表示q对d的注意力矩阵。
[0050]
所述移动设备为数码相机、智能手机或平板电脑。
[0051]
本发明与现有技术相比具有以下有益效果:
[0052]
1、本发明采用改进的边缘检测算子提取图像边缘,相比仅关注水平垂直方向的梯度,提出的方法更加突出对角线的梯度,加大梯度幅值使边缘更清晰,刻画了视频的模糊程度,并使用多尺度的方法突出细粒度和粗粒度的视频的特征;
[0053]
2、由于全局平均池化代表了2d-dct的最低频率分量,为了更好地压缩信道并引入更多信息,本发明将全局平均池化推广到2d-dct的更多频率分量,压缩更多信息;
[0054]
3、本发明采用改进的transformerblock,通过查询相邻帧语义信息的变化,使模型更好的学习到视频抖动、伪影等运动失真。
附图说明
[0055]
下面结合附图和具体实施方式对本发明进一步详细的说明:
[0056]
附图1是本发明的流程示意图。
具体实施方式
[0057]
如图1所示,基于语义变化的视频质量评估方法,包括以下步骤;
[0058]
步骤s1:对于移动设备拍摄的不同场景的视频,对视频的每一个帧提取边缘特征;
[0059]
步骤s2:将视频每一帧的边缘与原始图像分别输入空间特征提取网络,获取视频的多尺度空间特征,同时将视频输入时间特征提取网络,获取多尺度时间特征,对多尺度特征进行多频率分量池化和标准池化;
[0060]
步骤s3:将池化后的结果合并,获得视频的时空特征,并将时空特征降维;
[0061]
步骤s4:将降维后的视频时空特征输入质量预测网络建模时序关系,进而预测出整体视频的质量分数。
[0062]
所述步骤s1具体包括以下步骤;
[0063]
步骤s11:步骤s1的视频划分为视频帧后,利用改进的边缘检测算子提取每个视频帧的边缘信息;
[0064]
步骤s12:利用改进的边缘检测算子提取边缘信息,获得视频边缘r,令r={cannyi},i=1,2,...,t,表示一个视频序列中所有检测结果的集合,其中t表示一个视频序列中帧的数量,cannyi表示一个视频序列中的第i帧的边缘检测图像。
[0065]
步骤s12中,提取边缘信息的方法具体为:
[0066]
首先使用一个较大的5
×
5的高斯卷积核进行滤波,能更大程度去除图像尖锐噪声;接着使用改进的sobel算子对图像进行梯度幅值和梯度方向的计算;然后依据梯度幅值和梯度方向对图像边缘进行非极大值抑制操作。
[0067]
sobel算子如下:
[0068][0069]
梯度方向的计算方法如下:
[0070]gleft
=sobel_left*frame and g
right
=sobel_right*frame
ꢀꢀꢀ
公式二;
[0071][0072][0073]
其中frame表示视频帧图像,sobel_left表示左斜对角方向上的sobel算子,sobel_right表示右斜对角方向上的sobel算子,g
left
表示图像在左斜对角方向上的梯度幅值,g
right
表示图像在右斜对角方向上的梯度幅值,g表示一个视频帧的梯度幅值,θ表示图像的梯度方向。
[0074]
步骤s2具体包括以下步骤;
[0075]
步骤s21:将处理后视频帧的边缘图像r和原始视频帧分别输入到空间特征提取网络,根据模型的迁移学习理念,所述空间特征提取网络采用在imagenet上预训练的convnext-t基础上去掉最后面的池化层和全连接层,对于convnext-t的4个阶段,抽取每一个阶段的特征,每一个阶段输出的特征尺度不同,称为多尺度特征;
[0076]
步骤s22:将视频输入时间特征提取网络,所述时间特征提取网络采用的是在kinetics-400视频数据集上预训练slowfast网络中fast流,表示为slowfastf,其可以产生
具有高时间分辨率的运动特征,对于slowfastf获得的时间范围内的视频运动特征的表达,同样提取多尺度特征;
[0077]
步骤s23:对于多尺度的特征使用优于全局平均池化的多个频率分量池化的方法来压缩单个帧的特征。
[0078]
步骤s3具体包括以下步骤;
[0079]
步骤s31:由于slowfastf的时间步幅为2,为了匹配运动管道的时间分辨率,对空间、边缘特征张量的每两帧进行采样,即i=1,3,5,...,t,然后将沿通道维度的空间、边缘和时间的卷积特征连接;
[0080]
步骤s32:为了建立视频时间维度的相关性,采用改进的transformerblock,首先使用全连接层对帧级特征向量执行降维,降维到128维张量,记为feature。
[0081]
所述步骤s4具体包括以下步骤;
[0082]
步骤s41:对于降维后的128维特征向量,在输入序列中加入一个特殊的token,记为feature
cls
,用于学习到整个序列的特征,再加上位置编码e
pos
,具体操作如下:
[0083]
f0=[feature
cls
;feature1;feature3;
…
;feature
t
]+e
pos
ꢀꢀꢀ
公式五;
[0084]
其中featurei表示视频第i帧(i=1,3,5,...,t)的时空特征;
[0085]
步骤s42:处理后的向量输入改进的transformer block;
[0086]
步骤s43:对于transformer block输出的特征向量,使用全连接层将状态序列映射到帧级质量分数;
[0087]
步骤s44:对于帧级质量分数,采用平均池将帧级质量分数临时聚合到整体视频质量分数。
[0088]
所述改进的transformer block操作如下:
[0089]
相邻视频帧语义信息的差异表现为视频的变化,相邻帧的变化是导致视频产生伪影、抖动等失真的重要因素,
[0090]
首先计算相邻帧的特征变化:
[0091]
feature_differencei=feature
i+1-featurei,0≤i<t-1
[0092]
feature_differencei=0,i=t-1
ꢀꢀꢀ
公式六;
[0093]
给定一个序列feature作为输入,自注意模块首先将feature和feature_difference投影到查询q、键k、值v、特征差d矩阵中,如下所示:
[0094]
q=linear(feature),k=linear(feature),v=linear(feature)
ꢀꢀꢀ
公式七;
[0095]
d=linear(feature_difference)
ꢀꢀꢀ
公式八;
[0096]
其中,linear表示全连接投影,feature_differnece表示相邻帧的特征变化;然后用q去查询k和特征差d得到查询矩阵m,m中的元素代表q对k和d的注意值:
[0097][0098][0099][0100]
其中,m
qk
表示q对k的注意力矩阵,m
qd
表示q对d的注意力矩阵。
[0101]
所述移动设备为数码相机、智能手机或平板电脑。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1