基于数据驱动的高速路网拥堵预测与成因分析方法及系统
1.本发明涉及大数据技术领域,尤其涉及一种基于数据驱动的高速路网拥堵预测与成因分析方法及系统。
背景技术:
2.近些年,大数据技术的迅速发展,让以数据为依托的经济、文化、交通、娱乐等各个方面都迎来新的技术变革,以数据挖掘、数据驱动为中心的研究方法与理念在信息、生物、能源等不同的学科领域都得到了广泛应用。
3.交通拥堵问题一直是市民出行非常关注的问题,交通拥堵预测也是智能交通系统的重要研究领域。结合大数据,交通拥堵预测模型能够根据路况、站点流量、历史拥堵数据对未来通行情况进行有效预测,从而指导市民出行、绕行、错峰出行。现有的研究方法主要包括基于统计学的方法、传统的机器学习方法和基于深度学习模型的方法。基于统计学的方法主要针对小数据集设计,不适合处理复杂动态的数据,并且无法捕获特征之间的关系;随着深度学习方法的发展,深度学习可以达到优良的预测效果,但是深度学习方法的可解释能力较差。
技术实现要素:
4.本发明目的在于公开一种基于数据驱动的高速路网拥堵预测与成因分析方法及系统,以提高拥堵预测的精度及拥堵成因的解释性。
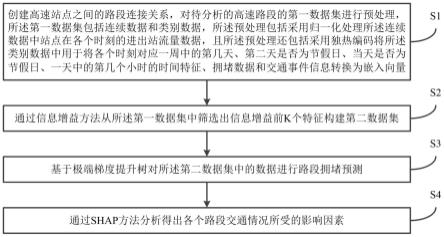
5.为达上述目的,本发明公开一种基于数据驱动的高速路网拥堵预测与成因分析方法,包括以下步骤:
6.步骤s1、创建高速站点之间的路段连接关系,对待分析的高速路段的第一数据集进行预处理,所述第一数据集包括连续数据和类别数据,所述预处理包括采用归一化处理所述连续数据中站点在各个时刻的进出站流量数据,且所述预处理还包括采用独热编码将所述类别数据中用于将各个时刻对应一周中的第几天、第二天是否为节假日、当天是否为节假日、一天中的第几个小时的时间特征、拥堵数据和交通事件信息转换为嵌入向量;
7.步骤s2、通过信息增益方法从所述第一数据集中筛选出信息增益前k个特征构建第二数据集;
8.步骤s3、基于极端梯度提升树对所述第二数据集中的数据进行路段拥堵预测;
9.步骤s4、通过shap方法分析得出各个路段交通情况所受的影响因素。
10.为达上述目的,本发明还公开一种基于数据驱动的高速路网拥堵预测与成因分析系统,包括:
11.预处理模块,用于创建高速站点之间的路段连接关系,对待分析的高速路段的第一数据集进行预处理,所述第一数据集包括连续数据和类别数据,所述预处理包括采用归一化处理所述连续数据中站点在各个时刻的进出站流量数据,且所述预处理还包括采用独热编码将所述类别数据中用于将各个时刻对应一周中的第几天、第二天是否为节假日、当
天是否为节假日、一天中的第几个小时的时间特征、拥堵数据和交通事件信息转换为嵌入向量;
12.特征自动选择器,用于通过信息增益方法从所述第一数据集中筛选出信息增益前k个特征构建第二数据集;
13.拥堵预测模块,用于基于极端梯度提升树对所述第二数据集中的数据进行路段拥堵预测;
14.拥堵解释模块,用于通过shap方法分析得出各个路段交通情况所受的影响因素。
15.本发明具有以下有益效果:
16.1、对不同类型的数据分别采用不同的处理方法,便于极端梯度提升树预测模型迅速拟合。
17.2、通过信息增益方法从所述第一数据集中筛选出信息增益前k个特征构建第二数据集,可实现特征的自动提取。
18.3、基于极端梯度提升树对所述第二数据集中的数据进行路段拥堵预测,通过参数调优及泛化分析,便于快速找到模型在训练数据集上的最佳表现。
19.4、在保证拥堵预测模型的预测精度的基础上,为增强机器学习的可解释性,引入shap模型对影响拥堵的各因素进行分析,为高速公路工作人员及市民提供决策参考。
20.下面将参照附图,对本发明作进一步详细的说明。
附图说明
21.构成本技术的一部分的附图用来提供对本发明的进一步理解,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:
22.图1是本发明实施例公开的基于数据驱动的高速路网拥堵预测与成因分析方法流程示意图。
23.图2是本发明实施例公开的影响交通情况的若干影响因素的shap值示意图。
24.图3是本发明实施例公开的各影响因素对shap值的正负向影响示意图。
25.图4本发明实施例公开的基于数据驱动的高速路网拥堵预测与成因分析系统的逻辑处理示意图。
具体实施方式
26.以下结合附图对本发明的实施例进行详细说明,但是本发明可以由权利要求限定和覆盖的多种不同方式实施。
27.实施例1
28.本实施例公开一种基于数据驱动的高速路网拥堵预测与成因分析方法,如图1所示,包括以下步骤:
29.步骤s1、创建高速站点之间的路段连接关系,对待分析的高速路段的第一数据集进行预处理,所述第一数据集包括连续数据和类别数据,所述预处理包括采用归一化处理所述连续数据中站点在各个时刻的进出站流量数据,且所述预处理还包括采用独热编码将所述类别数据中用于将各个时刻对应一周中的第几天、第二天是否为节假日、当天是否为节假日、一天中的第几个小时的时间特征、拥堵数据和交通事件信息转换为嵌入向量。
30.在该步骤的具体实现时,具体可例如:
31.将站点m在时刻t的进出站流量表示为其中m为站点总数。本实施例可结合了高德地图返回的拥堵事件数据(车辆行驶速度低于30km/h),将拥堵事件数据结合桩号,将拥堵事件精准定位到高速公路上,例如:将路段n在时段[t,t+t1](t1取0.5h,即30min)内发生拥堵时,拥堵数据为1,若路段n在时段[t,t+t1](t1取0.5h,即30min)内未有任何拥堵事件信息,则拥堵数据为0。
[0032]
本实施例第一数据集包含某省级高速路网系统的收费站进出站记录、以及拥堵数据和交通事件信息;其中,拥堵数据包括目标路段及其相邻路段的拥堵数据,同理,交通事件信息也包括目标路段及其相邻路段的交通事件信息。通过对第一数据集进行清洗和预处理,得到268个收费站点的进出站流量数据。其中流量的统计间隔为0.5小时,每个站点的流量数据均包含从2019年1月1日至2019年12月31日一年的收费站进出站流量数据,流量单位为辆/小时。针对流量值,该步骤采用归一化层对流量值进行处理,归一化层的目的是因为使用梯度下降的方法求解最优化问题时,归一化后可以加快梯度下降的求解速度,即提升模型的收敛速度。归一化处理之后,每个样本集包含17520条数据,按照6:2:2划分为模型的训练集、验证集和测试集。
[0033]
对于收费站点每个时刻的流量,提取其一天中第几个小时、一周中第几天、是否是周末、是否是节假日、前一天是否是节假日、后一天是否是节假日、温度等具有时间特性的类别特征,并采用独热编码机制将该对应时刻的时间特征转换为嵌入向量r,包括一天中的第几个小时(24个特征)、一周中的第几天(7个特征)、是否是节假日(2个特征)、前一天是否是节假日(2个特征)、后一天是否是节假日(2个特征)、当前路段历史交通事件数据(2个特征)等。此发明中,对于二分类变量(如是否是节假日),本发明采用0-1变量来表示,对于多分类的类别型变量,本发明使用独热编码的方法映射为多个0-1二元特征,保证不同类别之间的距离相同,以便于更好地提取特征之间的关系。可选地,本实施例可将历史时间步t设置为6(过去3个小时),即通过历史6个时间步(3个小时)来预测未来单个时间步的路段拥堵情况。
[0034]
步骤s2、通过信息增益方法从所述第一数据集中筛选出信息增益前k个特征构建第二数据集。
[0035]
在该步骤中,运用了信息增益的方法,并且自动选择信息增益前k个特征进行预测。设训练数据集为d,|d|表示其样本容量,即样本个数,设有k个类。设特征a有n个不同的取值{a1,a2,...,an},根据特征a的取值将d的划分为n个子集d1,d2,...,dn,|di|为di的样本个数,|d
ik
|为d
ik
的样本个数。对数据集d的信息增益g(d,a)的计算方式如下:
[0036]
g(d,a)=h(d)-h(d|a)
[0037]
其中:h(d)为数据集d的经验熵,h(d|a)为特征a对数据集d的经验条件熵,计算方式如下:
[0038]
[0039][0040]
其中,|ck|为属于类ck的样本个数。
[0041]
步骤s3、基于极端梯度提升树(xgboost,extreme gradient boosting)对所述第二数据集中的数据进行路段拥堵预测。
[0042]
在该步骤中,xgboost是梯度提升机器算法(gradient boosting machine)的扩展。boosting分类器属于集成学习模型,其基本思想是把成百上千个分类准确率较低的树模型组合成一个准确率较高树。xgboost的基学习器既有树(gbtree)又有线性分类器(gblinear),从而得到带l1+l2惩罚的线性回归或逻辑回归,其损失函数采用二阶泰勒展开,具有高准确度、不易过拟合、可扩展性等特点,能分布式处理高维稀疏特征。
[0043]
步骤s4、通过shap(shapley additive explanations)方法分析得出各个路段交通情况所受的影响因素。
[0044]
在该步骤中,shap属于模型事后解释,其核心思想是计算特征对模型输出的边际贡献,再从全局和局部两个层面对“黑盒模型”进行解释。对于每个预测样本,模型都产生一个预测值,shapvalue就是该样本中每个特征所分配到的数值。相比于模型重要性的度量,shap更能反映特征与预测值的关系。对于每个预测样本,shap值的计算方法如下:假设第i个样本为xi,第i个样本的第j个特征为x
ij
,模型对第i个样本的预测值为yi,所有样本预测均值为y
base
,那么x
ij
的shap值服从以下等式:
[0045]
yi=y
base
+f(xi,1)+f(xi,2)+...+f(xi,s)
[0046]
其中,f(xi,s)表示第xi个样本的第s个特征贡献的shap值,shap方法将每个样本的指标组合贡献通过shap值计算出来,如果某指标在大多数样本上表现出一致的趋势,即说明模型认定这一指标具有很重要的正向或者负向关系。
[0047]
在该步骤中,优选地,对于每个预测样本,计算该样本中每个特征对预测值所分配到的数值以反映各特征与预测值之间的关系。进一步地,还包括:计算并输出显示各特征对相应路段拥堵预测结果的正向影响或负向影响。
[0048]
为使本领域技术人员进一步理解本实施例上述内容,将本实施例方法与现有方法进行对比的拥堵性能及结果分析具体为:
[0049]
(1)性能比较
[0050]
本实施例使用决策树(decision tree)、朴素贝叶斯(gaussiannb)、随机森林(random forest)、knn(kneighbors)和梯度提升树(gradient boosting)等基线预测方法与xgboost模型进行整体性能的比较评估。
[0051]
其中,决策树(decision tree)是一种用于分类和回归任务的非参数监督学习算法,也是一种分层树形结构,由根节点、分支、内部节点和叶节点组成。
[0052]
knn(knn算法,又译k-近邻算法)是一种用于分类和回归的非参数统计方法。
[0053]
朴素贝叶斯(gussiannb)是基于贝叶斯定理与特征条件独立性假设的分类方法。
[0054]
随机森林(random forest)是一个包含多个决策树的分类器,并且其输出的类别是由个别树输出的类别的众数而定。
[0055]
梯度提升树(gradient boosting)是一种基于决策树的集成学习算法。
[0056]
本实施例使用f1分数(f1 score)、正样本分类精确率(p)和正样本分类召回率(r)作为预测模型性能的评价指标,这三种指标被广泛应用于样本分布极度不均匀的分类情况。其中,tp(true positive)为真阳性、fp(false positive)为假阳性、fn(false negative)为假阴性。性能指标的计算方式如公式如下:
[0057][0058][0059][0060]
对比数据如表1所示:
[0061]
表1:
[0062][0063]
由表1可知:本实施例xgboost的预测效果最好,在f1分数、精确率、召回率均是最高的。对于正样本(拥堵)的预测精确率能够达到81.553%,这对市民的出行有着非常重要的指导性作用。
[0064]
(2)高速路段拥堵成因分析
[0065]
在对每一条数据样本进行预测与成因分析的同时,本实施例可对各个路段的交通情况所受的影响因素进行宏观上的分析,以便工作人员对每条路段的拥堵成因有整体上的把握,以便后续的拥堵管控及道路规划。本实施例使用shap方法解释拥堵预测的影响因素,并计算了某路段数据集上的shap值,根据排序之后,得出影响交通情况的若干影响因素如图2,分析图2,可得到以下结论:
[0066]
最影响该路段拥堵的因素为本路段前半小时是否有拥堵情况的发生,该路段前半小时如果发生拥堵的话,在该路段会增加|shap_value|=0.85左右的概率会发生拥堵,而后的影响因素是上游路段历史上的入站流量情况以及下游的出站流量情况。而具体的影响是正向影响还是负向影响,是如何作用在拥堵预测上的,如图3所示。
[0067]
shap图由于同时兼顾取值、shap值和多指标呈现来反映全局解释,因此将指标在样本点上的取值大小采用不同颜色来表示,每个特征的图形由集合中所有的样本点构成。以shap值取零为中间分界线,对于处在左侧的样本点,该特征对于对应样本点的shap值为负,特征取定该样本点对应值时对拥堵概率有负向贡献,处在右侧样本点则特征取定对应值时对拥堵概率有正向贡献。因此,可以从图2结合图3可以得出:
[0068]
①
、该路段在历史上发生过拥堵的情况下,下一个时间步有极大的概率会发生拥堵。
[0069]
②
、上游收费站的历史进站流量越大,该路段发生拥堵的可能性越大。
[0070]
③
、下游收费站的历史出站流量越小,该路段发生拥堵的可能越大。
[0071]
④
、节假日发生拥堵的可能性比工作日发生拥堵的可能性要大。
[0072]
⑤
、该路段常在夜间23时发生拥堵,因此成为影响较大的因素。
[0073]
实施例2
[0074]
与上述实施例相对应的,本实施例公开一种基于数据驱动的高速路网拥堵预测与成因分析系统,参照图4,包括:
[0075]
预处理模块,用于创建高速站点之间的路段连接关系,对待分析的高速路段的第一数据集进行预处理,所述第一数据集包括连续数据和类别数据,所述预处理包括采用归一化处理所述连续数据中站点在各个时刻的进出站流量数据,且所述预处理还包括采用独热编码将所述类别数据中用于将各个时刻对应一周中的第几天、第二天是否为节假日、当天是否为节假日、一天中的第几个小时的时间特征、拥堵数据和交通事件信息转换为嵌入向量。
[0076]
特征自动选择器,用于通过信息增益方法从所述第一数据集中筛选出信息增益前k个特征构建第二数据集。
[0077]
拥堵预测模块,用于基于极端梯度提升树对所述第二数据集中的数据进行路段拥堵预测。优选地,该模块包含了xgboost组件与阈值自动选择器。当xgboost组件对样本数据进行拥堵预测,得到预测概率后,阈值自动选择器会调整模型分类效果最佳的阈值,当拥堵预测概率值大于这个阈值,会作出预测:在未来的时间步内,该路段会发生拥堵;当拥堵概率值小于这个阈值,会作出预测:在未来的时间步内,该路段不会发生拥堵(即保持畅通状态)。
[0078]
拥堵解释模块,用于通过shap方法分析得出各个路段交通情况所受的影响因素。
[0079]
由于所处的地理位置不同,各个高速路段拥堵所受的影响因素不同,不同地点的路段所受的交通站点流量、上下游路段交通情况的影响不同。优选地,本实施例系统还可以进一步包括地理位置嵌入层以区分不同交通路段。
[0080]
优选地,所述拥堵解释模块还用于对于每个预测样本,计算该样本中每个特征对预测值所分配到的数值以反映各特征与预测值之间的关系。
[0081]
进一步地,所述拥堵解释模块还用于计算并输出显示各特征对相应路段拥堵预测结果的正向影响或负向影响、以及影响程度的大小。
[0082]
综上,本发明上述各实施例所分别公开的基于数据驱动的高速路网拥堵预测与成因分析方法及系统,至少具有以下有益效果:
[0083]
1、对不同类型的数据分别采用不同的处理方法,便于极端梯度提升树预测模型迅速拟合。
[0084]
2、通过信息增益方法从所述第一数据集中筛选出信息增益前k个特征构建第二数据集,可实现特征的自动提取。换言之,由于高速路段所受影响因素过多,导致数据集数据量大、且存在较大的噪音,这严重影响预测精度。因此,本发明添加会根据特征重要性自动选择预测效果最好的特征集合的自动特征选择器以提高路段拥堵预测的性能。
[0085]
3、基于极端梯度提升树对所述第二数据集中的数据进行路段拥堵预测,通过参数调优及泛化分析,便于快速找到模型在训练数据集上的最佳表现。
[0086]
4、在保证拥堵预测模型的预测精度的基础上,为增强机器学习的可解释性,引入shap模型对影响拥堵的各因素进行分析,为高速公路工作人员及市民提供决策参考。
[0087]
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技
术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1