一种基于类内偏差迁移的小样本图像分类方法
1.本发明涉及计算机视觉领域,具体来说,涉及计算机视觉领域中的图像分类领域,更具体地说,涉及一种小样本图像分类模型的训练方法及基于训练好的模型进行小样本图像分类的方法。
背景技术:
2.图像分类问题是计算机视觉领域中最基本的一类问题,同时也是研究其它视觉问题的基础,其具有重要的学术价值和广阔的应用场景。近年来,基于深度学习的图像分类方法在公共交通、无人驾驶、人脸识别等领域中取得了优异的成绩并逐渐成为了研究图像分类问题的主流方法。但是,现有技术中的大多数传统方法是通过大量高质量的标注数据来进行图像分类模型的训练,这些方法没有考虑到现实场景中制作标注数据困难、无法获得足量标注数据的情况。例如,制作濒危保护动物的标注数据、病例罕见的医疗案例以及个性化的用户定制等都是很困难或者代价极高的。在这些现实场景中,传统的研究方法基于大量高质量标注数据训练出的深度学习模型无法取得预期效果,因此,这促使了对图像分类问题的研究方向转向了小样本学习领域。需要说明的是,本发明中将已有大量标注样本组成的数据集的类别称为基类,只有少量标注数据的类别称为新类,多个含有少量标注样本的新类组成的数据集称为支撑集,在测试时使用的新类无标注数据,并将多个含有少量无标注样本的类别组成的用于测试的数据集称为查询集。
3.小样本学习旨在利用少量新类数据与大量基类数据建立具有一定泛化能力的新类模型,来解决新类标注数据不足的图像分类问题,从而能够拓展深度学习算法的应用场景,并降低生产成本。在小样本学习中,现有的研究技术针对样本数量不足的类别进行建模的常见方法可以分为三类:
4.第一类方法是通过在原始样本上增加扰动来构造新样本,例如,文献[1]中提出通过ideme-net方法学习变形网络,该网络将新类样本与基类样本进行线性组合以获得仍然保留判别信息的困难样本从而促进分类模型的学习。文献[2]提出的mabas方法用支持集学习初始分类器,并采用生成对抗样本的方式生成位于分类器边界处的对抗样本以通过增大对抗样本的分类间隔来更新编码器,从而获得类内更紧凑的特征空间。以文献[1]和文献[2]为代表的这一类方法的核心思想是构造有变化、有难度的样本来扩充小样本图像类别中的标注数据,但是其对于扰动后的样本在图像空间中的具体表现没有固定的期望,这会导致新类类别中扩充的标注数据的质量低、适用性差等问题。
[0005]
第二类方法是直接利用包含大量样本和标注数据的基类类别的类内变化进行模型学习,例如,文献[3]提出的δ-encoder(δ-编码器)、文献[4]提出的dtn(diversity transfer network,偏差迁移网络)和文献[5]提出的mvt(meta variance transfer,元学习类方差迁移)等,这一类方法均是学习将基类中同类样本对之间的差异传递给新类的支撑集样本,以期望基于基类中同类样本对之间的差异新生成的样本与原有样本间满足相同的差异,但若基类的类内变化在新类的支撑集样本上的适用性差,会直接导致基于基类的
类内变化生成的样本与原有样本之间的差异巨大,进而导致通过该类方法训练的深度学习模型无法达到预期效果。
[0006]
第三类方法致力于估计新类类别中样本的完整数据分布,进而从估计的完整数据分布中采样大量样本,例如,为了估计新类类别中样本的完整数据分布,文献[6]提出了dc方法(distribution calibration,分布较准),该方法假设所有类别的特征均服从高斯分布,并利用相似基类对应的均值、协方差矩阵等统计数值来分别估计新类类别对应的均值、协方差矩阵等统计数值,然而,由于新类类别中少量的样本仅能描述有限的类别信息,所以通过这种方法估计的新类的类别信息存在估计的数据分布不完整、估计数据的准确率低以及估计的新类类别信息误差大等问题。
[0007]
综上所述,现有研究技术训练的适用于识别小样本图像分类的深度学习模型大多存在信息利用有效性差、小样本图像分类精度低以及难以应用于现实场景等问题。
[0008]
参考文献列表:
[0009]
[1]chen z,fu y,wang y x,ma l,liu w,hebert m.image deformation meta-networks for one-shot learning[c]//ieee conference on computer vision and pattern recognition.2019:8680-8689.
[0010]
[2]kim j,kim h,kim g.model-agnostic boundary-adversarial sampling for test-time generalization in few-shot learning[c]//european conference on computer vision:volume 12346.2020:599-617.
[0011]
[3]schwartz e,karlinsky l,shtok j,harary s,marder m,kumar a,feris r s,giryes r,bronstein a m.delta-encoder:an effective sample synthesis method for few-shot object recognition[c]//advances in neural information processing systems.2018:2850-2860.
[0012]
[4]chen m,fang y,wang x,luo h,geng y,zhang x,huang c,liu w,wang b.diversity transfer network for few-shot learning[c]//association for the advance of artificial intelligence.2020:10559-10566.
[0013]
[5]park s,han s,baek j,kim i,song j,lee h,han j,hwang s j.meta variance transfer:learning to augment from the others[c]//international conference on machine learning:volume 119.2020:7510-7520.
[0014]
[6]yang s,liu l,xu m.free lunch for few-shot learning:distribution calibration[c]//international conference on learning representations.2021.
[0015]
[7]mangla p,singh m,sinha a,kumari n,balasubramanian vn,krishnamurthy b.charting the right manifold:manifold mixup for few-shot learning[c]//wacv.2020:2207-2216.
[0016]
[8]gidaris s,bursuc a,komodakis n,p
é
rez p,cord m.boosting few-shot visual learning with self-supervision[c]//ieee international conference on computer vision.2019:8058-8067.
技术实现要素:
[0017]
因此,本发明的目的在于克服上述现有技术的缺陷,提供一种基于类内偏差迁移
的小样本图像分类模型的训练方法及基于训练好的模型的小样本图像分类方法。
[0018]
本发明的目的是通过以下技术方案实现的:
[0019]
根据本发明的第一方面,提供一种小样本图像分类模型的训练方法,所述方法包括:s1、获取图像训练集和支撑集,并以图像训练集中的样本为输入、样本分类为输出,用图像训练集将图像编码器和分类器组成的基础图像分类模型训练至收敛以获得初始化的图像编码器;其中,所述图像训练集中包括多个基类,每个基类具有多个带类别标签的样本;所述支撑集中包括多个与基类的类别不同的新类,每个新类具有满足小样本任务要求且具有类别标签的样本;s2、用图像训练集和支撑集对由所述初始化的图像编码器、预训练语言模型、选择器、多个偏差预测器、分类器组成的基本模型进行多次迭代训练直至收敛以获得由图像编码器和分类器组成的小样本图像分类模型,其中每次迭代训练包括:s21、采用预训练语言模型分别提取每个基类和每个新类的语义特征,并采用图像编码器分别提取每个基类和每个新类的样本的视觉特征;s22、采用选择器基于步骤s21中获得的每个基类和每个新类的语义特征以及每个基类和每个新类的样本的视觉特征计算每个新类与每个基类之间的相似度以确定每个新类对应的所有相似基类;s23、采用偏差预测器基于步骤s21中获得的每个基类和每个新类的样本的视觉特征分别进行新类和该新类的所有相似基类分别到各自对应的实际类别中心的偏差预测,并基于预测偏差分别计算新类和该新类的所有相似基类的类别预测中心,其中,每个新类对应一个偏差预测器,且基于每个类别的预测偏差和实际偏差计算偏差预测损失,基于每个类别的类别预测中心和实际类别中心计算类别中心预测损失;s24、采用分类器基于步骤s21中获得的每个新类和该新类的所有样本的视觉特征、获得所述每个新类以及该新类的所有相似基类对应的样本的分类预测结果,并基于样本的分类预测结果与样本类别标签计算分类损失;s25、采用偏差预测损失、类别中心预测损失、分类损失更新所述基本模型的参数。
[0020]
在本发明的一些实施例中,所述图像编码器为深度学习网络。
[0021]
在本发明的一些实施例中,所述图像编码器为alexnet、vggnet、resnet、wrn、wrn-28-10中的一种。
[0022]
在本发明的一些实施例中,所述选择器包括语义分支网络、视觉分支网络、归一化层,所述步骤s22包括:s221、采用选择器中的语义分支网络基于每个基类和每个新类的语义特征,计算每个基类与每个新类之间的语义相似度;s222、采用选择器中的视觉分支网络基于每个基类和每个新类的样本的视觉特征,计算每个基类与每个新类之间的视觉相似度;s223、采用选择器中的归一化层基于步骤s221中获得的语义相似度和步骤s222中获得的视觉相似度,计算每个新类和每个基类之间归一化后的相似度,并基于预设的相似度阈值确定每个新类对应的所有相似基类。
[0023]
在本发明的一些实施例中,在所述步骤s221中,按照如下方式计算每个基类与每个新类之间的语义相似度:
[0024][0025]
其中,表示第i个新类和第j个基类之间的语义相似度,wi表示第i个新类的语义特征,wj表示第j个基类的语义特征,fs表示选择器的语义分支网络。
[0026]
在本发明的一些实施例中,在所述步骤s222中,按照如下方式计算每个基类与每
个新类之间的视觉相似度:
[0027][0028]
其中,表示第i个新类和第j个基类之间的视觉相似度,表示第i个新类的所有样本的视觉特征的均值,表示第j个基类的所有样本的视觉特征均值,fv表示选择器的视觉分支网络。
[0029]
在本发明的一些实施例中,在所述步骤s223中,按照如下方式计算每个新类与每个基类之间的归一化后的相似度:
[0030][0031]
其中,s
ij
表示第i个新类和第j个基类之间的归一化后的相似度,u表示归一化系数,β表示选择器归一化层的学习参数,表示第i个新类和第j个基类之间的视觉相似度,表示第i个新类和第j个基类之间的语义相似度。
[0032]
在本发明的一些实施例中,在所述步骤s23中,当前轮迭代训练中每个类别的实际类别中心按照如下方式确定:基于当前轮迭代训练中每个类别对应的所有样本的视觉特征,分别计算当前轮迭代训练中每个类别对应的视觉特征均值并将其作为每个类别的实际类别中心,其中,所述每个类别是指新类或者基类。
[0033]
在本发明的一些实施例中,在所述步骤s23中,按照如下方式计算偏差预测损失:
[0034][0035][0036]
其中,s
ij
表示第i个新类和第j个基类之间的归一化后的相似度,ci表示当前轮迭代训练中第i个新类的实际类别中心,表示第i个新类的第k个样本的视觉特征,表示与当前轮迭代训练中该新类的实际类别中心ci之间的预测偏差,表示第i个新类的第k个样本的视觉特征与当前轮迭代训练中该新类的实际类别中心ci之间的实际偏差。
[0037]
在本发明的一些实施例中,在所述步骤s23中,按照如下方式分别计算新类和该新类的所有相似基类的类别预测中心:
[0038][0039]
其中,表示第i个新类的类别预测中心,表示第i个新类的第k个样本的视觉特征,k表示第i个新类的样本总数,表示与当前轮迭代训练中该新类的实际类别中心之间的预测偏差。
[0040]
在本发明的一些实施例中,在所述步骤s23中,按照如下方式计算类别中心预测损
失:
[0041][0042]
其中,表示当前轮迭代训练中第i个新类的类别预测中心,ci表示当前轮迭代训练中第i个新类的实际类别中心。
[0043]
在本发明的一些实施例中,在所述步骤s24中,按照如下方式计算分类损失:
[0044][0045]
其中,表示第i个新类的第k个样本的视觉特征,表示的分类概率。
[0046]
在本发明的一些实施例中,所述步骤s25包括:采用分类损失更新图像编码器和分类器;采用偏差预测损失更新选择器;采用偏差预测损失、类别中心预测损失以及分类损失更新偏差预测器。
[0047]
根据本发明的第二方面,提供一种图像分类方法,所述方法包括:t1、获取待处理的图像;t2、采用根据本发明的第一方面所述方法训练的小样本图像分类模型对所述待处理的图像进行处理以识别其图像类别。
[0048]
与现有技术相比,本发明的优点在于:
[0049]
1、本发明在训练的过程中通过计算新类和基类之间的相似度以选择出满足预设相似度阈值的与该新类相似的所有基类,扩充了训练样本的数量,丰富了样本数量不足的新类的类内变化。
[0050]
2、本发明根据新类和与其相似的基类的类内偏差分布是相似的特点,提出了新的偏差预测损失,增强了扩充数据的有效性。
[0051]
3、本发明采用元学习的方式对待训练的深度学习模型进行端到端的训练,提高了训练后的模型对小样本的图像分类的识别效果。
附图说明
[0052]
以下参照附图对本发明实施例作进一步说明,其中:
[0053]
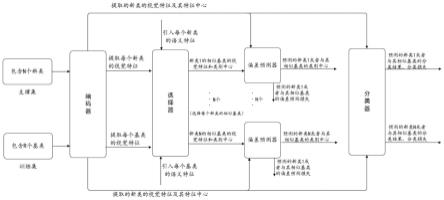
图1为根据本发明实施例的小样本图像分类模型的流程示意图;
[0054]
图2为根据本发明实施例的小样本图像分类模型的训练方法示意图。
具体实施方式
[0055]
为了使本发明的目的,技术方案及优点更加清楚明白,以下通过具体实施例对本发明进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
[0056]
如背景技术中提到的,现有技术的传统方法在对小样本的图像类别进行标注数据扩充时存在扩充的标注数据质量低、有效性差以及训练的深度学习模型识别小样本图像分类的精度低等问题。为了解决现有技术中的这些问题,本发明提出了一种类内偏差迁移的小样本图像分类模型的训练方案,通过引入偏差学习任务、类别中心预测任务,分别计算新类、其对应的所有相似基类的类内偏差,基于类内偏差预测来预测类别中心,然后基于预测
类别中心进行分类预测,并通过偏差预测损失、类别中心预测损失、分类损失对模型参数进行更新。其中,在新类的相似基类的判断过程中,引入了语义特征,相对于仅基于视觉特征的判断来说,能够获得更加完整的类别信息。通过引入偏差学习任务、类别中心预测任务,能够有效增加小样本类别的类内变化,提升分类精度。
[0057]
如图1所示,本发明提供一种类内偏差迁移的小样本图像分类模型的训练方法,概括来说,所述方法包括:s1、获取图像训练集和支撑集,并以图像训练集中的样本为输入、样本分类为输出,用图像训练集将图像编码器和分类器组成的基础图像分类模型训练至收敛以获得初始化的图像编码器;s2、用图像训练集和支撑集对由初始化的图像编码器、预训练语言模型、选择器、多个偏差预测器、分类器组成的基本模型进行多次迭代训练直至收敛以获得由图像编码器和分类器组成的小样本图像分类模型,并采用偏差预测损失、类别中心预测损失、分类损失更新基本模型的参数。其中,初始化图像编码器、预训练语言模型以及对选择器和多个偏差预测器进行训练是本发明引入的多个额外训练任务,其目的分别是增强图像编码器的编码能力、获取新类和基类的类别语义特征以计算新类和基类之间的相似度、选择与新类相似的所有基类以扩充训练样本的数量以及计算每个新类对应的偏差预测损失以增强扩充后的训练样本的有效性。
[0058]
下面结合附图及实施例来详细介绍本发明。
[0059]
根据本发明的一个实施例,如图2所示,本发明的基本模型由图像编码器、预训练语言模型、选择器、多个偏差预测器以及分类器组成。在对所述基本模型进行多次迭代训练时,每次迭代训练执行相同的步骤,故在接下来的介绍中是结合一次迭代训练的过程说明本发明的技术方案。
[0060]
根据本发明的一个实施例,图像训练集中包括多个基类,每个基类具有多个带类别标签的样本;支撑集中包括多个与基类的类别不同的新类,每个新类具有满足小样本任务要求且具有类别标签的样本;图像编码器用于将新类和基类中的样本图像编码为一维的视觉特征向量;选择器用于计算新类和基类之间的相似度以选择出满足预设相似度阈值的与该新类相似的所有基类以扩充小样本图像分类模型的训练样本数量;偏差预测器用于预测新类和该新类的所有相似基类到各自对应的实际类别中心的偏差,以及基于预测偏差分别计算新类和该新类的所有相似基类的类别预测中心,其中,每个新类对应一个偏差预测器;分类器用于计算新类和该新类的所有相似基类对应的样本的分类预测结果。
[0061]
根据本发明的一个实施例,在每次迭代训练时执行步骤t1-t5,下面详细说明每个步骤。
[0062]
在步骤t1中,采用预训练语言模型分别提取每个基类和每个新类的语义特征,采用图像编码器分别提取每个基类和每个新类的样本的视觉特征。需要说明的是,本发明提取的语义特征是将类别名称的单词输入到预训练语言模型中以获得一个定长的语义向量,该定长的语义向量即语义特征,例如,某类别的名称为猫类,那么将“cat”输入到预训练语言模型中,会输出一个定长的语义向量,该语义向量就是猫类的语义特征。
[0063]
在步骤t2中,采用选择器基于步骤t1中获得的每个基类和每个新类的语义特征以及每个基类和每个新类的样本的视觉特征计算每个新类与每个基类之间的相似度以确定每个新类对应的所有相似基类。根据本发明的一个实施例,选择器包括语义分支网络、视觉分支网络以及归一化层。需要说明的是,本发明引入语义特征的目的在于小样本的新类不
能反映出该新类的完整信息,引入的语义特征可以作为视觉特征的补充,从而能够计算出新类与基类之间更为准确的相似度。根据本发明的一个实施例,本发明按照如下方式计算每个新类与每个基类之间的相似度,包括步骤t21-t24,其中,每个步骤如下所述:
[0064]
步骤t21、采用选择器中的语义分支网络基于每个基类和每个新类的语义特征,按照如下方式计算每个基类与每个新类之间的语义相似度:
[0065][0066]
其中,表示第i个新类和第j个基类之间的语义相似度,wi表示第i个新类的语义特征,wj表示第j个基类的语义特征,fs表示选择器的语义分支网络;
[0067]
步骤t22、采用选择器中的视觉分支网络基于每个基类和每个新类的样本的视觉特征,按照如下方式计算每个基类与每个新类之间的视觉相似度:
[0068][0069]
其中,表示第i个新类和第j个基类之间的视觉相似度,表示第i个新类的所有样本的视觉特征的均值,表示第j个基类的所有样本的视觉特征均值,fv表示选择器的视觉分支网络;
[0070]
步骤t23、采用选择器中的归一化层基于步骤t21中获得的语义相似度和步骤t22中获得的视觉相似度,计算每个新类和每个基类之间归一化后的相似度,并基于预设的相似度阈值确定每个新类对应的所有相似基类。优选的,本发明按照如下方式计算每个新类和每个基类之间归一化后的相似度:
[0071][0072]
其中,s
ij
表示第i个新类和第j个基类之间的归一化后的相似度,u表示归一化系数,β表示选择器归一化层的学习参数,表示第i个新类和第j个基类之间的视觉相似度,表示第i个新类和第j个基类之间的语义相似度;
[0073]
步骤t24、通过步骤t21-t23获得每个新类和每个基类之间归一化后的相似度之后,本发明根据预设的相似度阈值来确定每个新类对应的所有相似基类,优选的,将与新类相似度大于或等于相似度阈值的基类作为该新类的相似基类。其中,预设的相似度阈值可以根据实际场景进行设置,本发明不对其作具体的限定。
[0074]
在步骤t3中,采用偏差预测器(每个偏差预测器对应一个新类)基于步骤t1中获得的每个基类和每个新类的样本的视觉特征分别进行新类和该新类的所有相似基类分别到各自对应的实际类别中心的偏差预测,并基于预测偏差分别计算新类和该新类的所有相似基类的类别预测中心,其中,每个类别(即新类和基类)的实际类别中心是基于当前轮迭代训练中每个类别对应的所有样本的视觉特征分别计算当前轮迭代训练中每个类别对应的视觉特征均值来确定,所述每个类别对应的视觉特征均值即是每个类别的实际类别中心。根据本发明的一个实施例,本发明按照如下方式分别计算新类和该新类的所有相似基类的类别预测中心:
[0075][0076]
其中,表示第i个新类的类别预测中心,表示第i个新类的第k个样本的视觉特征,k表示第i个新类的样本总数,表示与当前轮迭代训练中该新类的实际类别中心之间的预测偏差;
[0077]
此外,在本步骤中,还会根据每个类别的预测偏差和实际偏差计算偏差预测损失,以及根据每个类别的类别预测中心和实际类别中心计算类别中心预测损失。根据本发明的一个实施例,按照如下方式计算偏差预测损失:
[0078][0079][0080]
其中,s
ij
表示第i个新类和第j个基类之间的归一化后的相似度,ci表示当前轮迭代训练中第i个新类的实际类别中心,表示第i个新类的第k个样本的视觉特征,表示与当前轮迭代训练中该新类的实际类别中心ci之间的预测偏差,表示第i个新类的第k个样本的视觉特征与当前轮迭代训练中该新类的实际类别中心ci之间的实际偏差;
[0081]
根据本发明的一个实施例,按照如下方式计算类别中心预测损失:
[0082][0083]
其中,表示当前轮迭代训练中第i个新类的类别预测中心,ci表示当前轮迭代训练中第i个新类的实际类别中心。
[0084]
在步骤t4中,采用分类器基于步骤t1中获得的每个新类和该新类的所有样本的视觉特征、获得所述每个新类以及该新类的所有相似基类对应的样本的分类概率,并进一步获得分类预测结果,由此本发明能够基于样本的分类预测结果与样本类别标签计算分类损失。根据本发明的一个实施例,本发明按照如下方式计算每个新类以及该新类的所有相似基类对应的样本的分类概率:
[0085][0086]
其中,表示当前轮迭代训练中第i个新类的类别预测中心,表示第i个新类的第k个样本的视觉特征,τ表示超参数,求和公式∑n中的泛指所有类别的预测中心。
[0087]
根据本发明的一个实施例,本发明按照如下方式计算分类损失:
[0088]
[0089]
其中,表示第i个新类的第k个样本的视觉特征,表示的分类概率。
[0090]
在步骤t5中,采用偏差预测损失、类别中心预测损失以及分类损失更新基本模型的参数。根据本发明的一个实施例,分类损失用于更新图像编码器和分类器;偏差预测损失用于更新选择器;类别中心预测损失、偏差预测损失以及分类损失用于更新偏差预测器。优选的,本发明在对偏差预测器进行更新时,偏差预测损失和分类损失会以l
cls
+a*l
dt
的计算方式更新偏差预测器,根据本发明的一个实施例,参数a的值被设置为0.5。需要注意的是,此处参数a的值可以根据实际场景设置,本发明不对其作具体的限定。
[0091]
根据本发明的一个实施例,在上述训练过程中,本发明还引入了外层优化和内层优化的方式对基本模型进行训练以使训练后的模型具有更好的识别效果,在具体的训练过程中,本发明通过先采用外层优化、后采用内层优化的方式训练所述模型。其中,外层优化方式是指通过固定n个偏差预测器计算所有类别的类别预测中心,以及计算每个类别的分类预测结果,然后根据每个类别对应的分类损失和类别中心预测损失更新选择器和偏差预测器在接下来要进行的内层优化中的初始值;内层优化方式是指基于先前外层优化初始化后的选择器和偏差预测器,通过计算每个类别对应的分类损失和类别中心预测损失更新基本模型中的图像编码器、偏差预测器以及分类器。
[0092]
为了说明采用本发明提出的训练方法训练的小样本图像分类模型对样本数量不足的图像类别具有的识别效果,本发明进行了仿真实验,在仿真实验中,发明人为了避免对图像编码器重复训练以节省时间,利用文献[8]中所述方法在miniimagenet数据集上训练图像编码器,以及利用文献[9]中所述方法在cifar-fs数据集上再次训练图像编码器以获得应用于本发明的初始化的图像编码器。然后通过本发明方法训练出的小样本图像分类模型分别对5-way 1-shot(5个图像类别,每个图像类别包含一个样本)、5-way 5-shot(5个图像类别,每个图像类别包含五个样本)的小样本图像类别的查询集进行分类实验,并将采用本发明方法训练的模型进行分类的方法(即表1中的devnet方法)对应的实验结果与prototypical network方法、ta-prototypical network方法、mpa方法的实验结果做对比,对比结果如表1所示。需要指出的是,图像编码器为深度学习网络,其可以为alexnet、vggnet、resnet、wrn、wrn-28-10中的任意一种,本发明不对其作具体的限定。
[0093]
从表1展示的结果可以看出,在5-way 1-shot组中采用本发明的训练方法训练的小样本图像分类模型的识别准确率最高,为60.75%、误差率最低,为
±
0.58%;在5-way 1-shot组中,采用本发明的训练方法训练的小样本图像分类模型的识别准确率也是最高,为74.39%、误差率也是最低,为
±
0.50%。由此可知,本发明提出的小样本图像分类模型的训练方法可以提高训练后的模型的识别准确率,降低识别误差率。
[0094]
表1
[0095][0096]
此外,本发明还对采用了本发明的训练方法训练的小样本图像分类模型中的图像编码器进行了消融实验,并将该方法(即表2中的devnet方法)对应的实验结果与baseline方法、only方法的实验结果做对比,以展示其优越的性能,对比结果如表2所示:
[0097]
表2
[0098][0099]
从表2展示的结果可以看出,在5-way 1-shot组和5-way 1-shot组中本发明训练出的图像编码器的准确率都是最高,分别为72.31%、87.24%、误差率都是最低,分别为
±
0.68%、
±
0.46%。由此可知,本发明训练出的图像编码器具有优越的编码能力以及准确的特征提取能力。
[0100]
与现有技术相比,本发明的优点在于:
[0101]
1、本发明在训练的过程中通过计算新类和基类之间的相似度以选择出满足预设相似度阈值的与该新类相似的所有基类,扩充了训练样本的数量,丰富了样本数量不足的新类的类内变化。
[0102]
2、本发明根据新类和与其相似的基类的类内偏差分布是相似的特点,提出了新的偏差预测损失,增强了扩充数据的有效性。
[0103]
3、本发明采用元学习的方式对待训练的深度学习模型进行端到端的训练,提高了训练后的模型对小样本的图像分类的识别效果。
[0104]
需要说明的是,虽然上文按照特定顺序描述了各个步骤,但是并不意味着必须按照上述特定顺序来执行各个步骤,实际上,这些步骤中的一些可以并发执行,甚至改变顺序,只要能够实现所需要的功能即可。
[0105]
本发明可以是系统、方法和/或计算机程序产品。计算机程序产品可以包括计算机可读存储介质,其上载有用于使处理器实现本发明的各个方面的计算机可读程序指令。
[0106]
计算机可读存储介质可以是保持和存储由指令执行设备使用的指令的有形设备。计算机可读存储介质例如可以包括但不限于电存储设备、磁存储设备、光存储设备、电磁存储设备、半导体存储设备或者上述的任意合适的组合。计算机可读存储介质的更具体的例
子(非穷举的列表)包括:便携式计算机盘、硬盘、随机存取存储器(ram)、只读存储器(rom)、可擦式可编程只读存储器(eprom或闪存)、静态随机存取存储器(sram)、便携式压缩盘只读存储器(cd-rom)、数字多功能盘(dvd)、记忆棒、软盘、机械编码设备、例如其上存储有指令的打孔卡或凹槽内凸起结构、以及上述的任意合适的组合。
[0107]
以上已经描述了本发明的各实施例,上述说明是示例性的,并非穷尽性的,并且也不限于所披露的各实施例。在不偏离所说明的各实施例的范围和精神的情况下,对于本技术领域的普通技术人员来说许多修改和变更都是显而易见的。本文中所用术语的选择,旨在最好地解释各实施例的原理、实际应用或对市场中的技术改进,或者使本技术领域的其它普通技术人员能理解本文披露的各实施例。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1