一种基于生成式自我注意机制的无监督图像翻译方法
1.本发明涉及图像处理技术领域,具体涉及一种基于生成式自我注意机制的无监督图像翻译方法。
背景技术:
2.图像到图像的翻译是计算机视觉和图形问题研究的一个重要分支,它指的是将图像从源域转换到目标域的过程,其应用涉及超分辨率、图像着色、图像修复、图像生成、风格迁移等。在保持图像内容不变的情况下,利用原始域和目标域的映射关系生成翻译图像。在图像到图像的翻译过程中,可以分为有监督式图像翻译和无监督式图像翻译,根据图像数据集是否成对,又分为成对式图像翻译和非成对式图像翻译。在现实生活中,由于成对的数据集极难获取且获取成本非常高,所以对图像数据集的翻译,采用无监督式图像翻译对非成对式图像进行图像翻译,因此,非成对的无监督图像翻译已经成为研究的主流趋势。
3.gan(generative adversarial network,生成对抗网络)是一种强大的生成模型,未来有明显的改进空间。现有gan的图像到图像的翻译方法来自源域的真实图像传递到u型编码器网络结构中,再由生成器生成目标域对应的合成图像。用于分类的网络被称为判别器,它决定了生成器合成的图像是否可以被识别为真实图像。然而,在许多图像翻译任务中,得到的合成图像的图像质量较低,表明源域图像和合成图像仅在极少部分存在不同。但是,将所有目标属性向量作为输入数据可能会干扰生成图像的结果,比如把小猫变成小狗时,不仅要保留背景的内容,还要改变头部区域的特征,循环生成对抗网络(cyclegan)是解决这个问题的常用方法,循环生成对抗网络是无监督图像翻译最具有代表性的方法,特别适用于风格转换,但该方法不能改变高级语义,不具备区分图像主要部分和次要部分的能力,使无监督图像翻译结果不够准确。
技术实现要素:
4.为了解决上述现有方法的无监督图像翻译结果的准确性比较低的技术问题,本发明的目的在于提供一种基于生成式自我注意机制的无监督图像翻译方法,所采用的技术方案具体如下:
5.本发明一个实施例提供了一种基于生成式自我注意机制的无监督图像翻译方法,该方法包括以下步骤:
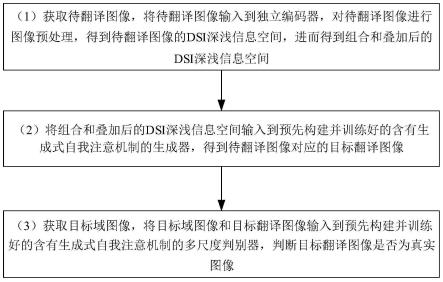
6.获取待翻译图像,将待翻译图像输入到独立编码器,对待翻译图像进行图像预处理,得到待翻译图像的dsi深浅信息空间,进而得到组合和叠加后的dsi深浅信息空间;
7.将组合和叠加后的dsi深浅信息空间输入到预先构建并训练好的含有生成式自我注意机制的生成器,得到待翻译图像对应的目标翻译图像;
8.获取目标域图像,将目标域图像和目标翻译图像输入到预先构建并训练好的含有生成式自我注意机制的多尺度判别器,判断目标翻译图像是否为真实图像,使生成器生成接近目标域的图像。
9.进一步的,所述独立编码器用于对待翻译图像进行图像预处理,所述生成器用于输出待翻译图像对应的目标翻译图像,所述多尺度判别器用于判别生成器所生成的待翻译图像对应的目标翻译图像的真假,所述目标翻译图像为虚假图像,所述待翻译图像和真实图像均为源域图像。
10.进一步的,构建含有生成式自我注意机制的生成器的步骤包括:
11.构建生成式自我注意机制模块,将生成式自我注意机制模块嵌入到生成器中的残差层模块与上采样层模块之间,得到含有生成式自我注意机制的生成器。
12.进一步的,构建含有生成式自我注意机制的多尺度判别器的步骤包括:
13.将生成式自我注意机制模块插入到多尺度判别器的下采样层模块之前,得到含有生成式自我注意机制的多尺度判别器。
14.进一步的,所述含有生成式自我注意机制的生成器包含下采样层模块、修改后残差块模块、生成式自我注意机制模块和上采样层模块。
15.进一步的,得到待翻译图像对应的目标翻译图像的步骤包括:
16.将组合和叠加后的dsi深浅信息空间输入到预先构建并训练好的含有生成式自我注意机制的生成器中的下采样层模块,得到组合和叠加后的dsi深浅信息空间的编码特征映射;
17.修改多尺度判别器的残差块,将编码特征映射输入到生成器中的修改后残差块模块,得到原始域特征图像;
18.将原始域特征图输入到生成器中的生成式自我注意机制网络,得到的原始域特征图像的特征信息;
19.将原始域特征图像的特征信息输入到生成器中的上采样层模块,得到待翻译图像对应的目标翻译图像,所述目标翻译图像为目标翻译图像对应的目标域的特征映射转换而成的合成图像。
20.进一步的,对待翻译图像进行图像预处理的步骤包括:
21.对待翻译图像进行卷积化处理,提取待翻译图像的图像特征,再对待翻译图像的图像特征进行采样后合并隐藏向量,通过卷积运算再次提取待翻译图像的特征信息,所述特征信息为dsi深浅信息空间。
22.本发明具有如下有益效果:
23.本发明提供了一种基于生成式自我注意机制的无监督图像翻译方法,用于实现图像到图像的翻译任务,该方法通过对所获取的待翻译图像进行图像处理,得到待翻译图像的dsi(digital systems information,数字系统的信息)深浅信息空间,将图像转化成图像的特征信息,一定程度上增强了图像翻译的效率,提高了生成器输入数据的准确性,进而提高无监督图像翻译结果的准确性。相比现有技术,预先构建并训练好的生成式自我注意机制网络的含有生成式自我注意机制的生成器有助于提高提取更深的图像特征的能力,进一步提高了变换图像空间细节的能力,有利于生成器生成更逼真的翻译图像。预先构建并训练好的含有生成式自我注意机制的多尺度判别器有助于进一步传输图像特征,最终实现待翻译图像到目标翻译图像的无监督不匹配的图像翻译。基于目标翻译图像对应的分布概率,判断目标翻译图像是否为真实图像,其有效提高了无监督非成对图像翻译中所得的合成图像的图像质量,进而提高无监督图像翻译结果的准确性。
附图说明
24.为了更清楚地说明本发明实施例或现有技术中的技术方案和优点,下面将对实施例或现有技术描述中所需要使用的附图作简单的介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其它附图。
25.图1为本发明一种基于生成式自我注意机制的无监督图像翻译方法的流程图;
26.图2为本发明实施例中的独立编码器对待翻译图像进行图像预处理的步骤的示意图;
27.图3为本发明一种基于生成式自我注意机制的无监督图像翻译方法的结构示意图;
28.图4为本发明实施例中的含有生成式自我注意机制的生成器结构的示意图;
29.图5为本发明实施例中的含有生成式自我注意机制的多尺度判别器结构的示意图;
30.图6为本发明实施例中对于源域为小猫对应的目标域为小狗的数据集,本实施例与多个现有主流无监督图像翻译方法进行无监督图像翻译的翻译图像的对比结果;
31.图7为本发明实施例中对于源域为小狗对应的目标域为小猫的数据集,本实施例与多个现有主流无监督图像翻译方法进行无监督图像翻译的翻译图像的对比结果;
32.图8为本发明实施例中对于源域为苹果对应目标域为橘子以及源域为女生对应目标域为男生的数据集,本实施例与多个现有主流无监督图像翻译方法进行无监督图像翻译的翻译图像的对比结果。
具体实施方式
33.为了更进一步阐述本发明为达成预定发明目的所采取的技术手段及功效,以下结合附图及较佳实施例,对依据本发明提出的技术方案的具体实施方式、结构、特征及其功效,详细说明如下。在下述说明中,不同的“一个实施例”或“另一个实施例”指的不一定是同一个实施例。此外,一个或多个实施例中的特定特征、结构或特点可由任何合适形式组合。
34.除非另有定义,本文所使用的所有的技术和科学术语与属于本发明的技术领域的技术人员通常理解的含义相同。
35.为了更好的解决无监督图像翻译的翻译图像的图像质量低和翻译结果不准确的问题,本实施例提供了一种基于生成式自我注意机制的无监督图像翻译方法,该方法的流程图如图1所示,该方法的结构示意图如图3所示,该方法包括以下步骤:
36.(1)获取待翻译图像,将待翻译图像输入到独立编码器,对待翻译图像进行图像预处理,得到待翻译图像的dsi深浅信息空间,进而得到组合和叠加后的dsi深浅信息空间。
37.在本实施例中,为了减少生成器和多尺度判别器的损失,提高图像翻译结果的准确性,将待翻译图像输入到独立编码器,待翻译图像为源域图像。独立编码器用于对待翻译图像进行图像预处理,独立编码器包含下采样层模块和上采样层模块,独立编码器由多个卷积层组成。独立编码器对待翻译图像进行图像预处理的步骤的示意图如图2所示,具体为:对待翻译图像进行卷积化处理,提取待翻译图像的图像特征,再对待翻译图像的图像特征进行采样后合并隐藏向量,通过卷积运算再次提取待翻译图像的特征信息,这里的特征
信息为dsi深浅信息空间。对待翻译图像进行图像预处理,便于更直观地掌握待翻译图像的信息,使每个网络更专注于本网络的目标,并使翻译后的图像更加合理准确。
38.(2)将组合和叠加后的dsi深浅信息空间输入到预先构建并训练好的含有生成式自我注意机制的生成器,得到待翻译图像对应的目标翻译图像。
39.在本实施例中,生成器可用于输出待翻译图像对应的目标翻译图像,该生成器包含深层模块、下采样层模块、残差层模块、生成式自我注意机制模块和上采样层模块,含有生成式自我注意机制的生成器结构的示意图如图4所示。构建含有生成式自我注意机制的生成器的具体过程为:先构建生成式自我注意机制模块,将该生成式自我注意机制模块嵌入到生成器中的残差层模块与上采样层模块之间,得到含有生成式自我注意机制的生成器。含有生成式自我注意机制的生成器增强了生成器在中心像素处提取更深特征的能力,进一步提高了变化图像空间细节的能力,有助于引导生成器生成更逼真的图像。图像翻译的过程也就是获取待翻译图像对应的目标翻译图像的步骤,目标翻译图像为虚假图像,也就是非真实存在的图像,其步骤包括:
40.(2-1)将组合和叠加后的dsi深浅信息空间输入到预先构建并训练好的含有生成式自我注意机制的生成器中的下采样层模块,得到组合和叠加后的dsi深浅信息空间的编码特征映射。下采样层模块由卷积频谱归一化激活层组成,其用于将变化明显的形状或纹理特征编码为高维特征图像
41.(2-2)修改多尺度判别器的残差块,将编码特征映射输入到生成器中的修改后残差块模块,得到原始域特征图像。残差块是由跳连接组成的,为了提高残差块在图像处理过程中的作用,将原始的残差块的个数修改设置为八个,也就是该残差块由八个残差卷积块组成,残差块也可以称为隐藏层模块,其用于提取高维特征图像的多级特征,对不同数据类型执行精确线性化分。
42.(2-3)将原始域特征图输入到生成器中的生成式自我注意机制网络,得到的原始域特征图像的特征信息。生成式自我注意机制模块由多个卷积层组成,是卷积的补充部分,其用于模拟广泛分离空间区域之间的关系,引导生成器关注图像的空间结构信息,计算图像中的任意两个像素点之间的距离,基于像素点的特征相关性可以获得图像全局的几何特征,从而生成更逼真的图像。
43.(2-4)将原始域特征图像的特征信息输入到生成器中的上采样层模块,得到待翻译图像对应的目标翻译图像,目标翻译图像为待翻译图像对应的目标域的特征映射转换而成的合成图像。上采样层模块由卷积层和双曲正切函数组成,其用于恢复图像。
44.(3)获取目标域图像,将目标域图像和目标翻译图像输入到预先构建并训练好的含有生成式自我注意机制的多尺度判别器,判断目标翻译图像是否为真实图像。
45.在本实施例中,含有生成式自我注意机制的多尺度判别器用于确定生成器所输出待翻译图像对应的目标翻译图像的真假程度和损失程度,该多尺度判别器包含生成式自我注意机制模块、下采样层模块、多层感知模块和多尺度分类器模块,含有生成式自我注意机制的多尺度判别器结构的示意图如图5所示。构建含有生成式自我注意机制的多尺度判别器的具体过程为:将生成式自我注意机制模块插入到多尺度判别器的下采样层模块之前,得到含有生成式自我注意机制的多尺度判别器。
46.将目标域图像和目标翻译图像作为预先构建并训练好的含有生成式自我注意机
制的多尺度判别器的输入图像,具体为:将目标域图像和目标翻译图像输入到预先构建并训练好的含有生成式自我注意机制的多尺度判别器,该多尺度判别器输出目标翻译图像是否为真实图像,真实图像是指真实存在的图像,其为源域图像,并非生成器生成的虚假图像。
47.需要说明的是,多尺度判别器中的生成式自我注意机制网络由多个卷积层组成,其可以将输入图像编码为高维特征,有助于遵循连续性,限制函数变化的严重性,避免生成器发生模型崩溃。多层感知模块由cam(channel attention module,通道注意力机制)注意力模块组成,cam注意力模块包括卷积神经网络层、sn(switchable normalization,可微分学习的自适配归一化)光归一化和leakyrelu激活函数,其有助于注意力导向模型灵活控制形状和纹理的变化量。多尺度分类器模块采用多尺度设计,并引入剩余注意机制,进一步促进特征传播。同时,本实施例也学习了由注意向量w生成的特征映射,特征映射的公式为:f(a)=γ
×
ω
×
ea(a)+ea(a),获取包含剩余注意机制的特征图,其中训练参数r决定了注意特征和原始特征之间的平衡关系,a为目标翻译图像的分布,a为a的样本数据,e为独立编码器的特征映射,本实施例在调整不同特征图像的重要性方向变得更加灵活,有效提高了训练的有效性。
48.其中,为了提高图像翻译结果的准确性,也就是提高翻译图像的图像质量,需要对含有生成式自我注意机制的生成器和多尺度判别器进行训练,其训练过程在图像翻译过程中起到了关键性的作用,训练效果的好坏直接影响到最终翻译图像的翻译效果和质量,其步骤包括:
49.(3-1)从源域数据集中随机抽取图像,并对所抽取的图像进行裁剪,将其大小调整为256*256,得到含有生成式自我注意机制的生成器的训练样本。
50.(3-2)将步骤(3-1)中的训练样本输入到独立编码器中,获得训练样本对应的dsi深度信息空间,dsi深度信息空间为不同层获取的特征信息,特征信息也就是隐藏向量。
51.(3-3)获取目标域图像,构建含有生成式自我注意机制的生成器,将经过组合和叠加的dsi深度信息空间输入到含有生成式自我注意机制的生成器中,得到合成图像。
52.(3-4)将合成图像和目标域图像分别放入到含有生成式自我注意机制的多尺度判别器中,基于多尺度判别器的输出结果,计算损失程度。
53.(3-4-1)生成器中的对抗损失函数促进了合成图像的分布,有助于匹配目标域图像的分布,生成器中的对抗损失函数的计算公式为:
[0054][0055]
其中,ca为判别器a,g为生成器b,ea为独立编码器a,eb为独立编码器b,b为待翻译图像的分布,也就是源域图像的分布,a为目标翻译图像的分布,也就是合成图像的分布,b
′
为b的样本数据,a
′
为a样本数据。
[0056]
(3-4-2)循环一致性损失函数可以用于降低模型碰撞的概率,给定图像a∈a从a转换为b并返回a,所得图像应与a具有相同的分布,循环一致性损失函数的计算公式为:
[0057]
[0058]
其中,b
′
为b的样本数据,a
′
为a样本数据,b为待翻译图像的分布,f为生成器a,g为生成器b,eb为独立编码器a,eb为独立编码器b。
[0059]
(3-4-3)为了确保生成器的输出图像和输入图像具有相似分布,对生成器应用重构进行一致性约束,也就是给定图像a∈a,生成器的输出图像不应该发生更改,而重建损失函数有助于生成器提取层次特征,减少由dain(depth-aware video frame interpolation,深度感知视频帧插值)特征提取过程中发生的错误,重构损失函数的计算公式为:
[0060][0061]
其中,b
′
为b的样本数据,a
′
为a样本数据,b为待翻译图像的分布,f为生成器a,eb为独立编码器b。
[0062]
(3-4-4)在本实施例中,生成器的对抗损失是多尺度判别器中所使用的损失函数,对抗损失有助于引导多尺度判别器区分源域图像和目标域图像,促使生成器输出的合成图像的分布概率不断接近目标域图像的分布概率,也就是促进合成图像的分布与目标域图像的分布的匹配,同时也优化了多尺度判别器的参数,最大化对抗损失。多尺度判别器的损失函数的计算公式为:
[0063][0064]
其中,cb为判别器b,g为生成器b,ea为独立编码器a,eb为独立编码器b,b为待翻译图像的分布,也就是源域图像的分布,a为目标翻译图像的分布,也就是合成图像的分布,b
′
为b的样本数据,a
′
为a样本数据。
[0065]
(3-5)设置总优化目标,对步骤(3)中的各个损失函数设置不同的权重,并将各个损失函数值相加。
[0066]
(3-6)重复步骤(3-1)至步骤(3-5),直到含有生成式自我注意机制的生成器和多尺度判别器达到设置的迭代循环次数。
[0067]
需要说明的是,随着网络的不断训练,含有生成式自我注意机制的生成器和多尺度判别器的特征提取效果逐渐增强,合成图像向目标域图像靠近,最终达到满意的图像翻译结果。
[0068]
为了测试本实施例一种基于生成式自我注意机制的无监督图像翻译方法的图像翻译效果,可以使用fr
é
chet初始距离来衡量两个图像数据集之间的相似性,fr
é
chet初始距离与人类视觉质量的判断可以很好地吻合,且常用于评估生成性对抗网络样本的图像质量。具体为:通过计算两个图像数据集对应的高斯函数之间的fr
é
chet初始距离来计算fid(frequency identify,频率鉴别号码)初始网络的特征,frechette关联距离分数是计算真实图像和合成图像对应的特征向量之间距离的度量,关联距离分数越低,合成图像的图像质量就会越高。当然,kid(kernel inception distance,核起始距离)也可以用于衡量两个图像数据集之间的相似性,kid与fid属于相同性质的度量,其主要区别在于kid具备一个简单且无偏差的估计器,其有助于增加衡量结果的准确性,尤其是初始特征多余图像数量时。为了更好地匹配人类进行图像质量的评估,通过计算最大均方差获取真实图像与合成图像之间的视觉相似性,kid值较小表明真实图像在视觉上更类似于合成图像。
[0069]
在本实施例中,结合实验进一步对本实施例的翻译图像的翻译结果作说明。
[0070]
实验数据,存在3种类型的未配对的数据集,分别为cat2dog、apple2orange和man2woman数据集,也就是源域为狗对应目标域为猫、源域为苹果对应目标域为橘子以及源域为女生对应目标域为男生的数据集。对于cat2dog数据集而言,训练数据包括771张小猫图像和1264张小狗图像,测试数据包含100张小猫图像和100张小狗图像;对于apple2orange数据集而言,训练数据包括955张苹果图像和1019张橘子图像,测试数据包含266张苹果图像和248张橘子图像;对于man2woman数据集而言,训练数据包括1200张男士图像和1200张女士图像,测试数据包含115张男士图像和115张女士图像。
[0071]
实验设置,生成器和多尺度判别器均使用relu(rectified linear units)作为激活函数,并将该激活函数的斜率设置为0.2,将adam(adaptive moment estimation,适应性矩估计)作为优化器,该优化器的学习率为0.0001,以0.5概率对输入图像进行水平随机翻转,输入图像的大小调整为286*286,并随机裁剪为256*256。生成器模型和多尺度判别器模型均进行100000次的迭代训练,将对抗损失函数、循环一致性损失函数和重构损失函数的权重分别设置为1、10以及10,将重量传递机制的传递速率设置为0.9,批量大小设置为1。
[0072]
实验结果,从定性和定量的角度进行评估,本实施例从3个数据集角度与多个现有主流无监督图像翻译方法进行无监督图像翻译的翻译图像进行比较,多个现有主流无监督图像翻译方法包括iegan、nicegan、u-gat-it、cyclegan、unit以及munit,该比较结果包括源域为小猫对应目标域为小狗、源域为小狗对应的目标域为小猫、源域为苹果对应目标域为橘子以及源域为女生对应目标域为男生的数据集。对于源域为小猫对应的目标域为小狗的数据集,本实施例与多个现有主流无监督图像翻译方法进行无监督图像翻译的翻译图像的对比结果如图6所示;对于源域为小狗对应的目标域为小猫的数据集,本实施例与多个现有主流无监督图像翻译方法进行无监督图像翻译的翻译图像的对比结果如图7所示;对于源域为苹果对应目标域为橘子以及源域为女生对应目标域为男生的数据集,本实施例与多个现有主流无监督图像翻译方法进行无监督图像翻译的翻译图像的对比结果如图8所示。图6、图7和图8展示了本实施例在和多个现有主流无监督图像翻译方法在3种不同数据集上进行图像翻译的fid值和kid值,fid值和kid值越小,合成图像的生成效果越好,也就是翻译图像的图像质量越高。至此,根据3个对比结果可知,基于生成式自我注意机制的无监督图像翻译方法相比现有的多个现有主流无监督图像翻译方法存在一定程度优势,其有效提高了翻译图像的翻译质量和翻译的准确性。
[0073]
以上所述实施例仅用以说明本技术的技术方案,而非对其限制;尽管参照前述实施例对本技术进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本技术各实施例技术方案的范围,均应包含在本技术的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1