一种基于神经网络的股票价格分析方法
1.本发明属于计算机神经网络技术领域,应用于股票价格分析,具体涉及一种基于神经网络的股票价格分析方法。
背景技术:
2.股票市场价格不具有稳定性,经常会因为国家社会的政策而发生很大的跳动,这也使得股民在股市中实现投资盈利变得难以实现。伴随着人工智能的快速崛起,计算机处理一些数学问题也开始变得灵活,于是试着利用计算机这非凡的计算能力,从而对股票市场的走势进行一些分析和预测。针对股票价格预测的这一问题,过去在计算机领域经常用于股票预测的分析方法种类繁多(如:小波分析法;预测短期时间序列的马尔科夫预测法;混沌分析法;经典的预测时间序列的arima模型;svm方法;bp神经网络以及循环神经网络(rnn)等方法),但存在着以下缺陷之处:
3.(1)不平稳、非线性、噪声点多是金融时间序列的特性,股票时间序列也有上述特性,因此,当股票的噪声与所需学习的时间序列进行叠加时,传统的机器学习的方法就不能呈现出良好的分析效果。
4.(2)针对于长时间序列的股票数据的预测,传统模型(例如自回归积分滑动平均模型、小波分析法等)无法很好的学习长时间序列的训练特征。
5.(3)大部分的神经网络模型无法有效的处理数据遗忘和梯度爆炸问题。
6.可见高效的神经网络模型对预测股票的准确率产生了极大的影响,如何选取有效的神经网络、以及对该神经网络进行参数的调整,是目前长时间序列预测中迫切的需求,也为中长期股票的预测提供了一定的参考和指导。
技术实现要素:
7.本发明的目的就是提供一种基于神经网络的股票价格分析方法,基于卷积神经网络和长短期记忆神经网络对股票价格进行分析。
8.本发明具体包括如下步骤:
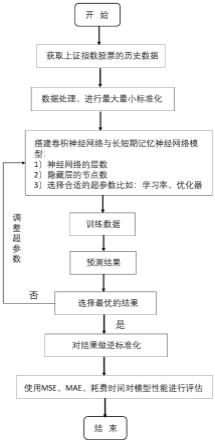
9.步骤一:数据采集与转化:从公开官网中获取包括日期、收盘价、最高价、最低价、开盘价以及成交量在内的上证股票的历史数据,将数据的格式转化为预测模型所需的输入序列格式的数据;
10.步骤二:对数据集进行归一化操作,并划分训练集和测试集,并分别对训练集和测试集的数据进行窗口的划分;
11.步骤三:搭建基于卷积神经网络和长短期记忆神经网络的股票价格分析网络,股票价格分析网络包括输入层、卷积神经网络、长短期记忆神经网络的隐藏层和输出层。
12.卷积神经网络包括卷积层和最大池化层,长短期记忆神经网络包括输入门、遗忘门、输出门,在长短期记忆神经网络模型中,第一阶段是遗忘门f
t
,遗忘层决定哪些信息需要从细胞状态中被遗忘;下一阶段是输入门i
t
,输入门确定哪些新信息能够被存放到细胞
状态中;最后一个阶段是输出门o
t
,输出门确定输出什么值。
13.输入层每次输入天数*数据个数的矩阵,然后再将结果依次送入二维卷积层、最大池化层、长短期记忆神经网络层,最后输出层输出预测的收盘价。
14.步骤四、模型优化:将训练集的数据输入模型,对其进行训练,通过网格搜索进行模型参数的调整和优化;
15.步骤五:将股票历史数据(日期、收盘价、最高价、最低价、开盘价以及成交量)输入模型,并得到预测的股价分析。
16.本发明通过对卷积神经网络与长短期时间记忆网络的结合,不仅可以准确的描绘股票在未来一定时间内的走向,而且发现在长短期时间记忆网络中添加卷积神经网络可以使得其计算时间远远小于长短期时间记忆网络(计算效率高)。
附图说明
17.图1为本发明的流程示意图;
18.图2为本发明使用的长短期记忆神经网络单元的原理图;
19.图3为卷积神经网络的网络结构图。
20.图4为遗忘门的原理图;
21.图5为输入门的原理图;
22.图6为细胞状态更新原理图;
23.图7为输出门的原理图。
具体实施方式
24.如图1所示,一种基于卷积神经网络和长短期记忆神经网络的股票价格分析方法,具体包括如下步骤:
25.步骤一:本实施例中所使用的数据集是通过网易财经上获取的上证指数的数据,该数据集一共包含12列,但本发明中只采用了其中的六列(日期、收盘价、最高价、最低价、开盘价以及成交量)。该数据集包含了从2012-01-04至2022-06-08的全部数据共有2532条,数据集的形式如下表1所示:
26.表1
[0027][0028]
步骤二:对数据集进行最小-最大(min-max)标准化操作,消除不同量纲所带来的影响,将所有数值类型的特征划分至[0,1]的一个区间范围内。之后将处理好的数据中的80%作为训练集,用于模型的训练;剩余20%作为测试集,用于测试模型的泛化误差。
[0029]
具体操作如下:其中,x
′i表示计算后的第个i变量;xi表示第i个变量;min(x)表示x的最小值、max(x)表示x的最大值;
[0030]
再对数据进行标准化操作后,分别对训练集和测试集的数据进行窗口的划分,下面展示训练集的数据划分后的格式(测试集同理):
[0031]
其中n是训练集中的条数数量,d为输入数据的维度;
[0032]
步骤三:搭建如图2所示的卷积神经网络和长短期记忆神经网络,包括输入层、二维卷积层、最大池化层、长短期记忆神经网络的隐藏层和全连接层。卷积神经网络包括卷积层和最大池化层。
[0033]
输入层是输入的矩阵的大小都是7*5的大小,其中的7代表一周的数值,5代表某一个工作日的所有输入特征。二维卷积层的卷积核大小为64,即深度为64;卷积核为2,步长为1,将padding设置成same,输入和输出的大小是一致的,会根据卷积的大小自动进行补0填充。
[0034]
下面的以7*5的输入数据(由于本文中的数据都是归一化后的结果,数值的范围都在0-1,在此讲解计算的过程会比较复杂,因此为了方便计算,选择使用随机的小于5的整数),和2*2的卷积核(该数值会随机生成)进行说明:
[0035]
输入数据(7*5)、卷积核(2*2):
[0036][0037]
然后根据卷积核,选定输入数据左上角的2*2矩阵,用卷积核与这个矩阵对应的位置相乘,得到的4个数,4个数再相加,最终得到一个结果6;具体操作如下:
[0038][0039]
然后把卷积核往右挪动一格,继续重复上述计算,再得到一个数字4;具体操作如下:
[0040][0041]
以此操作,直至此行结束,得到改行有4个结果数字。将padding设置为same,目的是让输出矩阵的大小和输入矩阵一致,因此,会自动在后面进行补0的操作。然后在于卷积核进行运算,得到结果为1;具体操作如下:
[0042][0043]
当前两行算完之后再往下移动一行,继续重复上述操作,直到整个7*5的输入图像全部计算完,得到的结果为6*5,同时设置了padding为same,在最下面的一行进行补0的操作,使得输出的矩阵大小为7*5,补0的操作如下:
[0044][0045]
得到了35个计算结果:
[0046][0047][0048]
接下来在卷积核的结果上进行最大池化层的操作,最大池化层的池化核大小为2,步长为1,将padding设置成same,保证了输出和输入大小的一致性,会根据池化的大小自动补0填充。
[0049]
继续拿上述卷积举例的结果进行说明:
[0050]
输入矩阵(7*5)、池化核(2*2)
[0051][0052]
取输入矩阵中的最大值作为输出,第一个加粗的黑色框代表最大池化操作,最左边池化的最大值为6,即第一个输出为6,后面以此类推;具体为:
[0053][0054]
在第一行操作结束时,得到4个数值,但是将padding设置成same后,输出的矩阵将会和输入的矩阵一样大,在补0后的加粗黑框中得到一个最大值为1;具体为:
[0055][0056]
同理,在最后一行时也会自动做补0的操作,如下所示。
[0057][0058]
最后得到最终的池化结果为:
[0059]
699617885110864110864110998110998477884
[0060]
长短期记忆神经网络作为拥有更强能力的循环神经网络系列,包括输入门、遗忘门、输出门,如图3所示,在长短期记忆神经网络模型中,第一阶段是遗忘门f
t
,遗忘层决定哪些信息需要从细胞状态中被遗忘;下一阶段是输入门i
t
,输入门确定哪些新信息能够被存放到细胞状态中;最后一个阶段是输出门o
t
,输出门确定输出什么值。
[0061]
标准长短期记忆神经网络模型结构的门控实现如下式所示:
[0062]ft
=σ(wf*[h
t-1
,x
t
]+bf);
[0063]it
=σ(wi*[h
t-1
,x
t
]+bi);
[0064][0065][0066]ot
=σ(wo*[h
t-1
,x
t
]+bo);
[0067]ht
=o
t
*tanh(c
t
);
[0068]
其中,t为当前时刻;h
t-1
是上一时间的输出;x
t
为当前时间节点的输入;wf,wi,wc,wo为权重矩阵;bf,bi,bc,bo为偏置向量;σ为sigmoid激活函数;f
t
为遗忘门的概率;i
t
表示输入门;tanh为激活函数;表示对输入信息的处理;c
t
为当前时刻的细胞状态;o
t
表示输出门的输出;h
t
表示lstm在t时刻的输出。
[0069]
第一步:如图4所示,遗忘门f
t
是用来决定什么信息能通过细胞门,f
t
=σ(wf*[h
t-1
,x
t
]+bf);将上一时刻的输出h
t-1
和当前输入x
t
送入sigmoid函数来产生一个0到1的f
t
值(概率),以此决定是否让上一时刻学到的信息c
t-1
通过或部分通过,即选择性过滤。
[0070]
第二步:如图5所示,输入门i
t
产生所需要更新的新信息,i
t
=σ(wi*[h
t-1
,x
t
]+bi);该步包含两个部分,第一部分为tanh函数构成的新的候选向量该步包含两个部分,第一部分为tanh函数构成的新的候选向量其中的每一项产生一个在[0,1]内的值,控制新信息被加入的多少;另一部分为sigmoid函数,用来控制新信息被加入的多少。根据这两部分产生的值来更新本记忆单元的单元状态。
[0071]
第三步:对原细胞门进行更新,如图6所示,首先将原细胞门乘以遗忘门f
t
来遗忘不需要的信息,然后再与i
t
与的积相加,得到了新的候选值c
t
:
[0072]
第四步:如图7所示,输出门o
t
用来控制当前的单元状态被过滤掉的数量,o
t
=σ(wo*[h
t-1
,x
t
]+bo);首先,将上一时刻的输出h
t-1
和当前输入x
t
送入sigmoid函数来产生一个0到1的o
t
值。然后将c
t
的值送入tanh函数,将值缩放到-1到1的范围内,再与o
t
相乘,从而得到模型的输出h
t
=o
t
*tanh(c
t
)。
[0073]
步骤四:将数据集的数据输入模型,并通过网格优化不断的调整模型的参数;本实施例中具体参数见表2;
[0074]
表2
[0075]
参数值kernel_size[1,2]pool_size[1,2]strides[1,2]长短期记忆神经网络层数[2,11]长短期记忆神经网络节点数[8,128]
全连接层的节点数[2,4]优化器[rmsprop,adam]
[0076]
步骤五:将测试集的数据输入模型,得到预测的结果;对预测的结果使用平均绝对误差、均方误差、均方根误差、模型所耗费的时间这四个指标评估预测模型的性能;
[0077]
平均绝对误差的计算公式为:
[0078]
均方误差的计算公式为:
[0079]
均方根误差的计算公式为:
[0080]
其中,y为真实值,为预测值,n为测试值的数量。
[0081]
在11th gen intel(r)core(tm)i7-117002.50ghz 32gb内存运行环境下,anaconda3中借助python对该模型进行的仿真实验:
[0082]
将预测模型与误差逆传递神经网络模型、门控循环单元神经网络模型以及长短期记忆神经网络模型进行对比发现,预测模型的预测结果表现良好,如表3所示在上证指数测试数据集上四个模型的评估指标比较结果,可以看出cnn+lstm在mae、mse、rmse的指标上是要优于bp和gru模型的。而其对比lstm来说,在mae、mse、rmse指标上数值的差距都很细微,但lstm所耗费的时间与cnn+lstm并非一个量级,lstm所需的时间约为cnn+lstm的4倍。若随着数据量的增大,lstm模型的层数加深,节点数增加的情况下,所耗费的时间将不可计算,同时,这也证明,若在lstm之前加入cnn将会极大的缩减模型对于特征的学习时间。
[0083]
表3
[0084]
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1