基于ApacheCalcite数据血缘和影响分析的方法及系统与流程
基于apache calcite数据血缘和影响分析的方法及系统
技术领域
1.本发明涉及数据分析技术领域,具体地,涉及基于动态数据管理框架apache calcite的数据血缘分析和影响分析的方法及系统。
背景技术:
2.数据血缘分析和影响分析是数据管理和数据治理工具的核心功能,通过建立数据之间的血缘关系,一方面可以追溯下游数据的来源与加工逻辑,另一方面可以快速分析上游数据发生变化时的影响范围,从而能够及时的进行变更影响预警及配套改造。apache calcite是提供了标准sql语言、多种查询优化和连接各种数据源的基础框架,能够接入多种数据并实现使用sql查询。但是,apache calcite只支持解析常规sql,对于不同类型数据库的sql解析会报错或者解析结果不完全。
技术实现要素:
3.针对现有技术中的缺陷,本发明的目的是提供一种基于apache calcite的数据血缘分析和影响分析的方法及系统。
4.根据本发明提供的一种基于apache calcite数据血缘和影响分析的方法,包括:
5.步骤s1:根据采集的元数据,获取元数据信息,其中,所述元数据信息包括表、字段;
6.步骤s2:集成apache calcite,对所述元数据信息的sql字符串进行词法和语法分析,转化为抽象语法树ast;
7.步骤s3:利用抽象语法树ast获取表、字段之间的关系图谱;
8.步骤s4:根据所述关系图谱,进行表级、字段级的血缘分析与影响分析。
9.优选地,所述步骤2包括如下步骤:
10.步骤s2.1:对greenplum、gaussdb等数据库中的特殊语法进行改造适配,将sql语句解析为抽象语法树ast;
11.步骤s2.2:利用自定义解析器,解析抽象语法树ast的节点对象,获取字段血缘依赖关系,写入指定的数据表中,所述解析包括:
12.对抽象语法树ast中查询、关联节点解析,获取字段与表之间的血缘依赖关系以及依赖详情;
13.对子查询中的字段,递归解析字段所属物理表信息,获取血缘依赖关系;
14.其中,通过calcite将sql语句不同部分解析封装为不同的节点对象,通过解析节点对象信息从而获取对应的血缘依赖关系。
15.优选地,所述自定义解析器包括calcite sql解析器;在生成calcite sql解析器的过程中,调整config.fmpp文件,以支持所需关键字;其中,config.fmpp文件是calcite模板配置文件,完成freemarker和javacc的相关配置;调整templates文件夹中的parser.jj文件中的解析规则来适应所需数据库解析,使用自定义解析函数满足特殊语法规则解析;
其中,parser.jj文件是javacc解析器所需要的解析核心文件;fmpp根据配置文件、模板文件和附加模板文件,自动生成解析文件parser.jj,经过编译后生成sql解析器。
16.优选地,基于apache calcite,在元数据层面建立起技术元数据和业务元数据的关系,实现了字段级、表级的关系穿透,进行不同粒度的血缘分析与影响分析;调用calcite解析sql;生成解析后的抽象语法树sqlnode;根据sqlnode的类型调用不同的解析器解析依赖关系。
17.根据本发明提供的一种基于apache calcite数据血缘和影响分析的系统,包括:
18.模块m1:根据采集的元数据,获取元数据信息,其中,所述元数据信息包括表、字段;
19.模块m2:集成apache calcite,对所述元数据信息的sql字符串进行词法和语法分析,转化为抽象语法树ast;
20.模块m3:利用抽象语法树ast获取表、字段之间的关系图谱;
21.模块m4:根据所述关系图谱,进行表级、字段级的血缘分析与影响分析。
22.优选地,所述步骤2包括如下步骤:
23.模块m2.1:对greenplum、gaussdb等数据库中的特殊语法进行改造适配,将sql语句解析为抽象语法树ast;
24.模块m2.2:利用自定义解析器,解析抽象语法树ast的节点对象,获取字段血缘依赖关系,写入指定的数据表中,所述解析包括:
25.对抽象语法树ast中查询、关联节点解析,获取字段与表之间的血缘依赖关系以及依赖详情;
26.对子查询中的字段,递归解析字段所属物理表信息,获取血缘依赖关系;
27.其中,通过calcite将sql语句不同部分解析封装为不同的节点对象,通过解析节点对象信息从而获取对应的血缘依赖关系。
28.优选地,所述自定义解析器包括calcite sql解析器;在生成calcite sql解析器的过程中,调整config.fmpp文件,以支持所需关键字;其中,config.fmpp文件是calcite模板配置文件,完成freemarker和javacc的相关配置;调整templates文件夹中的parser.jj文件中的解析规则来适应所需数据库解析,使用自定义解析函数满足特殊语法规则解析;其中,parser.jj文件是javacc解析器所需要的解析核心文件;fmpp根据配置文件、模板文件和附加模板文件,自动生成解析文件parser.jj,经过编译后生成sql解析器。
29.优选地,基于apache calcite,在元数据层面建立起技术元数据和业务元数据的关系,实现了字段级、表级的关系穿透,进行不同粒度的血缘分析与影响分析;调用calcite解析sql;生成解析后的抽象语法树sqlnode;根据sqlnode的类型调用不同的解析器解析依赖关系。
30.根据本发明提供的一种存储有计算机程序的计算机可读存储介质,所述计算机程序被处理器执行时实现所述的基于apache calcite数据血缘和影响分析的方法的步骤。
31.根据本发明提供的一种电子设备,包括存储器、处理器及存储在所述存储器上且可在所述处理器上运行的计算机程序,所述计算机程序被处理器执行时实现所述的基于apache calcite数据血缘和影响分析的方法的步骤。
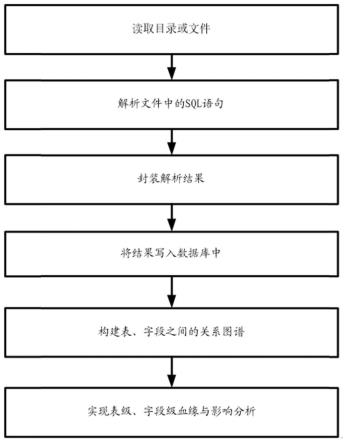
32.与现有技术相比,本发明具有如下的有益效果:
33.1、本发明基于apache calcite,在元数据层面建立起技术元数据和业务元数据的关系,实现了字段级、作业级、表级的关系穿透,进而通过不同粒度的血缘分析与影响分析更好的理解数据和使用数据。
34.2、本发明通过对抽象树中查询、关联节点解析,获取字段与表之间的血缘依赖关系以及依赖详情;另外对于子查询中的字段,递归解析字段所属物理表信息,从而获取依赖关系。其中,通过calcite将sql语句不同部分解析封装为不同的节点对象,通过解析节点对象信息从而获取对应的血缘依赖关系。
35.3、本发明解析greenplum、gaussdb等多种不同类型数据库sql,不同数据库有着不同的关键字、函数等特殊语法,使得本发明能够支持解析多种数据库的特殊语法。
附图说明
36.通过阅读参照以下附图对非限制性实施例所作的详细描述,本发明的其它特征、目的和优点将会变得更明显:
37.图1为解析的实现流程步骤示意图。
38.图2为生成解析器的原理示意图。
39.图3为解析sql语句的流程步骤示意图。
具体实施方式
40.下面结合具体实施例对本发明进行详细说明。以下实施例将有助于本领域的技术人员进一步理解本发明,但不以任何形式限制本发明。应当指出的是,对本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变化和改进。这些都属于本发明的保护范围。
41.本发明基于apache calcite,在元数据层面建立起技术元数据和业务元数据的关系,实现了字段级、作业级、表级的关系穿透,进而通过不同粒度的血缘分析与影响分析更好的理解数据和使用数据。
42.本发明通过对抽象树中查询、关联节点解析,获取字段与表之间的血缘依赖关系以及依赖详情;另外对于子查询中的字段,递归解析字段所属物理表信息,从而获取依赖关系。其中,通过calcite将sql语句不同部分解析封装为不同的节点对象,通过解析节点对象信息从而获取对应的血缘依赖关系。
43.本发明作为血缘分析工具具备多个优势,通过分析sql脚本中的ddl、dml语句,能够迅速、精确地识别出字段与字段的直接映射关系(包括字段间的依赖关系和转换操作)、表字段间关联、过滤条件等依赖关系,使数据处理更加便捷高效。本发明作为血缘分析工具包括集成apache calcite sql解析框架将sql语句解析为抽象语法树和自定义解析器进行血缘关系解析。
44.根据本发明提供的一种基于apache calcite数据血缘和影响分析的方法,包括:
45.步骤1:采集元数据,根据所述元数据获取表、字段等元数据信息;
46.步骤2:集成apache calcite,对表、字段等元数据信息的sql字符串进行词法和语法分析,转化为ast(抽象语法树,abstract syntax tree);
47.步骤3:利用ast获取表、字段之间的关系图谱;
48.步骤4:通过生成的关系图谱完成表级、字段级的血缘分析与影响分析;
49.步骤5:通过生成的关系图谱完成表级、作业级、字段级的血缘分析与影响分析。
50.所述步骤2包括如下步骤:
51.步骤2.1:对greenplum、gaussdb等数据库中的部分特定语法进行改造适配,将其中的sql语句解析为抽象语法树;
52.步骤2.2:利用自定义解析器,解析抽象语法树节点对象,获取字段依赖关系数据,生成解析结果并写入指定的数据源中。其实现流程如图1所示。
53.所述自定义解析器包括calcite sql解析器。在生成calcite sql解析器的过程中,所需要的相关文件均放在codegen文件夹中,包括includes文件夹中的guassparserimpls.ftl,gpparserimpls.ftl,parserimpls.ftl,tcl.ftl等自定义解析文件;config.fmpp文件和templates文件夹中的parser.jj文件。guassparserimpls.ftl,gpparserimpls.ftl,parserimpls.ftl,tcl.ftl等文件是附加语法模板文件,parser.jj文件是javacc解析器所需要的解析核心文件(比如增加函数时的主要修改文件),config.fmpp文件是calcite模板配置文件,完成freemarker和javacc的相关配置;fmpp根据配置文件、模板文件和附加模板文件,自动生成fmpp/javacc文件夹的终极解析文件parser.jj,经过编译后生成sql解析器javacc/*。生成解析器的具体流程如图2所示。本发明解析gp、gauss等多种不同类型数据库sql,不同数据库有着不同的关键字、函数等特殊语法,使得本发明能够支持解析多种数据库的特殊语法。本发明对apache calcite框架源码、配置做相应调整,例如调整config.fmpp,使其支持更多关键字,调整优化parser.jj中解析规则来适应多种数据库解析,使用自定义解析函数满足特殊语法规则解析。
54.使用血缘分析工具解析sql语句的核心过程如图3所示,包括:调用calcite解析sql;生成解析后的抽象语法树sqlnode;根据sqlnode的类型(create update等)调用不同的解析器解析依赖关系。
55.本发明还提供一种基于apache calcite数据血缘和影响分析的系统,所述基于apache calcite数据血缘和影响分析的系统可以通过执行所述基于apache calcite数据血缘和影响分析的方法的流程步骤予以实现,即本领域技术人员可以将所述基于apache calcite数据血缘和影响分析的方法理解为所述基于apache calcite数据血缘和影响分析的系统的优选实施方式。具体地,根据本发明提供的一种基于apache calcite数据血缘和影响分析的系统,包括:
56.模块m1:根据采集的元数据,获取元数据信息,其中,所述元数据信息包括表、字段;
57.模块m2:集成apache calcite,对所述元数据信息的sql字符串进行词法和语法分析,转化为抽象语法树ast;
58.模块m3:利用抽象语法树ast获取表、字段之间的关系图谱;
59.模块m4:根据所述关系图谱,进行表级、字段级的血缘分析与影响分析。
60.所述步骤2包括如下步骤:
61.模块m2.1:对greenplum、gaussdb等数据库中的特殊语法进行改造适配,将sql语句解析为抽象语法树ast;
62.模块m2.2:利用自定义解析器,解析抽象语法树ast的节点对象,获取字段血缘依
赖关系,写入指定的数据表中,所述解析包括:对抽象语法树ast中查询、关联节点解析,获取字段与表之间的血缘依赖关系以及依赖详情;对子查询中的字段,递归解析字段所属物理表信息,获取血缘依赖关系;其中,通过calcite将sql语句不同部分解析封装为不同的节点对象,通过解析节点对象信息从而获取对应的血缘依赖关系。
63.所述自定义解析器包括calcite sql解析器;在生成calcite sql解析器的过程中,调整config.fmpp文件,以支持所需关键字;其中,config.fmpp文件是calcite模板配置文件,完成freemarker和javacc的相关配置;调整templates文件夹中的parser.jj文件中的解析规则来适应所需数据库解析,使用自定义解析函数满足特殊语法规则解析;其中,parser.jj文件是javacc解析器所需要的解析核心文件;fmpp根据配置文件、模板文件和附加模板文件,自动生成解析文件parser.jj,经过编译后生成sql解析器。
64.基于apache calcite,在元数据层面建立起技术元数据和业务元数据的关系,实现了字段级、表级的关系穿透,进行不同粒度的血缘分析与影响分析;调用calcite解析sql;生成解析后的抽象语法树sqlnode;根据sqlnode的类型调用不同的解析器解析依赖关系。
65.根据本发明提供的一种存储有计算机程序的计算机可读存储介质,所述计算机程序被处理器执行时实现所述的基于apache calcite数据血缘和影响分析的方法的步骤。
66.根据本发明提供的一种电子设备,包括存储器、处理器及存储在所述存储器上且可在所述处理器上运行的计算机程序,所述计算机程序被处理器执行时实现所述的基于apache calcite数据血缘和影响分析的方法的步骤。
67.本领域技术人员知道,除了以纯计算机可读程序代码方式实现本发明提供的系统、装置及其各个模块以外,完全可以通过将方法步骤进行逻辑编程来使得本发明提供的系统、装置及其各个模块以逻辑门、开关、专用集成电路、可编程逻辑控制器以及嵌入式微控制器等的形式来实现相同程序。所以,本发明提供的系统、装置及其各个模块可以被认为是一种硬件部件,而对其内包括的用于实现各种程序的模块也可以视为硬件部件内的结构;也可以将用于实现各种功能的模块视为既可以是实现方法的软件程序又可以是硬件部件内的结构。
68.以上对本发明的具体实施例进行了描述。需要理解的是,本发明并不局限于上述特定实施方式,本领域技术人员可以在权利要求的范围内做出各种变化或修改,这并不影响本发明的实质内容。在不冲突的情况下,本技术的实施例和实施例中的特征可以任意相互组合。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1