基于相关系数和改进熵的概率语言多属性群决策方法
本发明涉及多属性群决策领域,尤其涉及一种基于相关系数和改进熵的概率语言多属性群决策方法。
背景技术:
1、决策信息以语言变量或不确定语言变量形式给出的决策问题广泛存在于现实生活中,如军事系统效能评估、智慧医疗等。在决策过程中,由于客观事物的复杂性和不确定性、以及人类思维的模糊性,对于诸如武器装备的性能、智慧医疗项目开展等决策对象进行评估时,决策者难以用精确定量的形式对其进行评价,往往会直接给出定性的评估信息,如“优”,“良”,“中”,“差”等自然语言形式。因此,对于该类问题的研究不仅具有重要的理论意义,而且具有广阔的应用背景,从而引起了国内外学者的高度关注。
2、当面临复杂不确定环境时,决策者无法确定哪个语言术语最准确,可能权衡在多个术语之间犹豫不决而无法做出选择。2016年pang等人在《probabilistic linguisticterm sets in multi-attribute group decision making》一文中基于语言分布评估首先提出了概率语言术语集的概念,引起了国内外众多学者对概率语言术语集研究的关注。概率语言术语集中包含语言信息和语言术语的概率信息,相比犹豫模糊语言术语集,概率语言术语集考虑到了不同语言变量的重要程度,此外,其不确定性测度也更加复杂,决策者要做出合理决策是建立在对决策信息综合考量的基础之上,往往倾向于依据可靠度更高的决策信息做出决策判断,可靠度越高,相应的属性权重也应越高。因此,属性权重的确定是概率语言多属性群决策过程中的一个关键问题。属性权重的计算方法一般包括最大离差化法,熵权法等。pang等人在《probabilistic linguistic term sets in multi-attributegroup decision making》一文中,利用欧式距离对不同的概率语言术语集进行距离度量,然后根据最大离差化思想,建立线性规划模型,对其进行求解,获得属性权重,但是该方法没有考虑各个方案在不同属性下的评价信息的不确定性。毛小兵在《基于概率语言相关系数的多属性群决策模型》一文中,利用相关系数测量概率语言术语集间的相关性,再根据最大离差化思想,建立线性规划模型,对其进行求解,得到属性的权重,但是该方法没有考虑各个方案在不同属性下的评价信息的不确定性,可能导致决策结果不准确。lu等人在《topsis method for probabilistic linguistic magdm with entropy weight and itsapplication to supplier selection of new agricultural machinery products》一文中,利用熵值理论描述各个方案在不同属性下的评价信息的不确定性,但是如果基础数据中存在数据变异的情况,熵本身并不能完全反应指标在解决实际问题中的重要性,并且没有考虑决策信息间的差异性,会导致决策结果不准确。
技术实现思路
1、本发明的目的是提供一种基于相关系数和改进熵的概率语言多属性群决策方法,可以有效地对属性权重完全未知的方案选择决策问题做出合理的决策。
2、本发明采用的技术方案为:
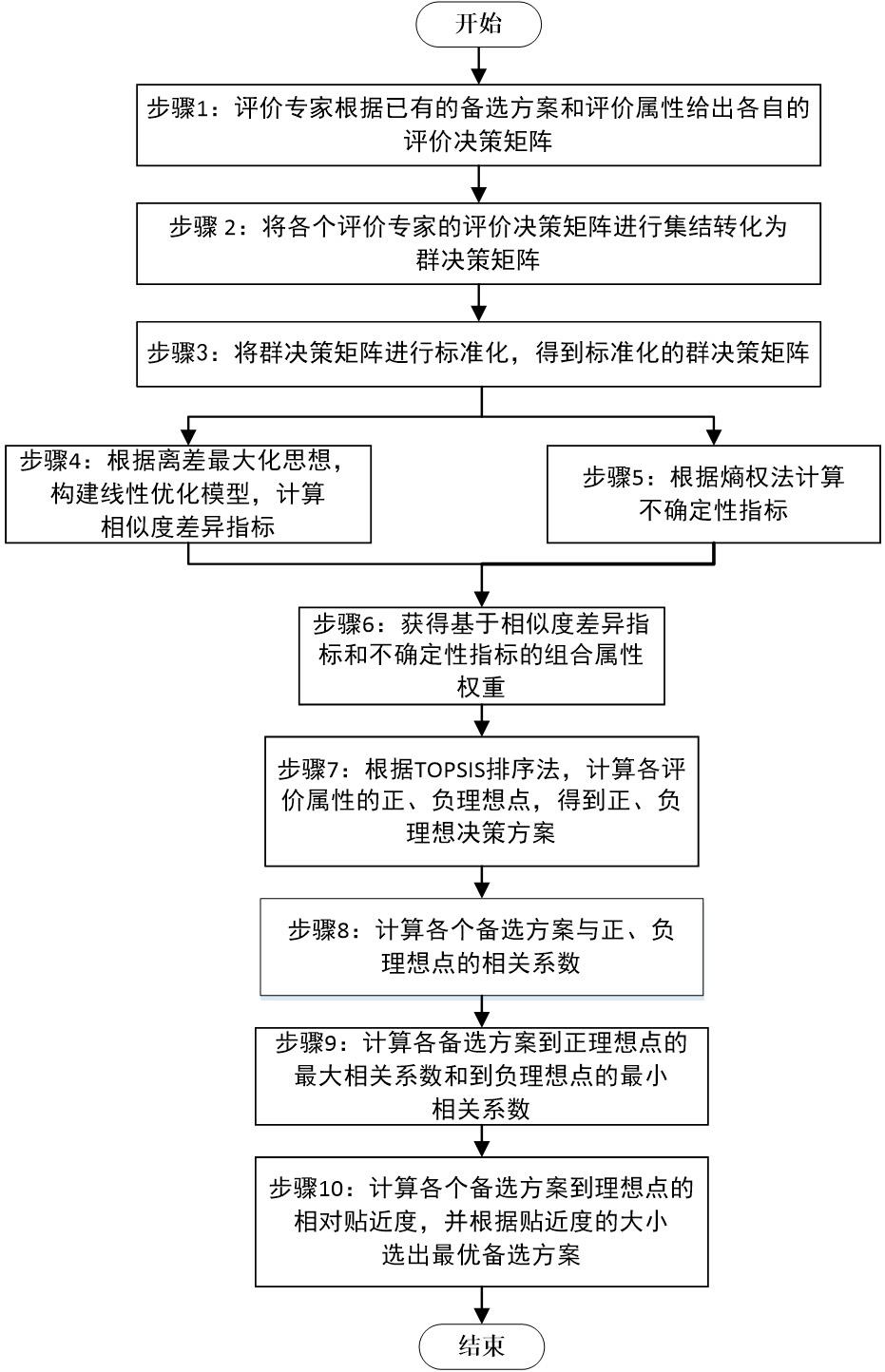
3、基于相关系数和改进熵的概率语言多属性群决策方法,包括以下几个步骤:
4、步骤1:针对方案选择问题,假设有m个备选方案,构成方案集a={ai,i=1,2,…,m},n个评价属性构成属性集c={cj,j=1,2,…,n},评价专家组有q个评价专家d={ds,s=1,2,…,q},由评价专家组根据评价属性对备选方案进行评价,得到由所有的属性评价值构成的语义评价矩阵rs=[lijs]m×n,其中,lijs表示专家ds对备选方案ai在属性cj上的原始语义评价值,评价专家对各个备选方案的原始语义评价值用语言变量表示;
5、步骤2:根据评价专家组给出的语义评价矩阵,将评价专家给出的原始语义评价值转化为概率语言术语,得到概率语言群决策矩阵在概率语言术语集中语言术语个数不同时,根据其中最多语言术语的个数,需补充其他概率语言术语集,规则是:添加概率语言术语集中下标最小的语言术语,并规定其概率为零,使所有的概率语言术语集中语言术语个数相同,再进行标准化,得到标准化的概率语言群决策矩阵r=[lij(p)]m×n,其中,lij(p)表示评价专家组对备选方案ai在评价属性cj下的意见评价值;
6、步骤3:根据离差最大化思想,利用概率语言群决策矩阵和概率语言相关系数公式,建立线性规划模型,通过对线性规划模型的求解获得属性的相似度差异指标αj,即其中,i表示备选方案的个数,j表示评价属性的个数;
7、对于任意的概率语言术语集l1(p)和l2(p)的相关系数满足以下性质:
8、(1)0≤sim(l1(p),l2(p))≤1
9、(2)sim(l1(p),l2(p))=sim(l2(p),l1(p))
10、(3)若l1(p)和l2(p)完全相同,即l1(p)=l2(p),则sim(l1(p),l2(p))=1
11、证明:
12、(1)设概率语言术语集l1(p)和l2(p)分别为和其中,#l1(p)和#l2(p)分别表示概率语言术语集l1(p)和l2(p)的个数,#l1(p)=#l2(p),表示l1(k)的下标,s={sα|α=0,1,…,τ}是一个语言术语集,可以分别看成两个向量和所以由柯西不等式可知|<l1,l2>|≤|l1||l2|,当且仅当l1=l2时取等号,所以因为l1和l2各个分量的值均为非负数,所以<l1,l2>=l1l2t≥0,所以0≤sim(l1(p),l2(p))≤1。
13、(2)显然sim(l1(p),l2(p))=sim(l2(p),l1(p))成立。
14、(3)当l1(p)和l2(p)完全相同时,即l1(p)=l2(p),
15、步骤4:根据概率语言群决策矩阵信息和信息熵公式计算各个评价属性的熵,用熵的最大值lnm对熵进行归一化处理,得到归一化的信息熵其中ln表示以自然常数e为底数的对数函数,e是一个约等于2.71828182845904523536……的无理数,为了防止原始数据损失的发生,利用改进熵公式减弱信息熵对决策结果的影响,再根据熵权法计算属性的不确定性指标βj,得到不确定性指标为
16、改进的概率语言熵有以下性质:
17、(1)非负性,即ej≥0
18、(2)极值性
19、证明:
20、设为概率语言术语集,其中,i=1,2,…,m,j=1,2,…,n,s={sα|α=0,1,…,τ}表示一个语言术语集,τ为正整数,lij(k)(pij(k))表示备选方案ai关于评价属性cj的语言术语及其相应的概率pij(k),#lij(p)为lij(p)中概率语言术语的个数,rij(k)表示lij(k)的下标,在计算信息熵的公式中fi表示在同一评价属性下,对每个备选方案对应的效用值进行归一化的结果,即在评价属性cj下的信息熵为
21、(1)由概率语言术语集的概念可知,0≤pij(k)≤1,0≤rij(k)≤τ,所以所以所以因此改进的概率语言信息熵具有非负性,即ej≥0成立。
22、(2)当某个属性条件下每个备选方案所对应的效用值占比相等时,即此时该属性条件下的熵值最大,即此时达到最大值,改进的概率语言熵也达到最大值。因此改进的概率语言熵ej具有极值性。
23、步骤5:由相似性差异指标和不确定性指标得到属性权重的计算公式如下所示:wj*=αjβj,对属性权重进行归一化得到组合权重为
24、步骤6:根据topsis排序法,利用群决策信息获取备选方案的正理想点q+=(q1+,q2+,…,qn+)和负理想点q-=(q1-,q2-,…,qn-),其中q+和q-分别定义为和其中rij(k)表示lij(k)的下标,pij(k)表示lij(k)对应的概率;
25、步骤7:计算每个备选方案与正理想点和负离想点的加权相关系数分别为和
26、步骤8:计算每个备选方案与正理想点的最大相关系数和与负理想点的最小相关系数,结果如下所示:
27、步骤9:同时考虑备选方案与正理想点和与负理想点的相关系数,计算每个备选方案的贴近度,公式如下所示:
28、步骤10:由计算得到的各备选方案对应的贴近度的大小,对备选方案进行排序,贴近度ci(ai)越大说明其对应的备选方案ai越好,最后得到各备选方案的优先序,选出最优的备选方案
29、随着科技的发展,互联网与各产业的结合成为一种趋势。为了更好地改善人们的生活,互联网与医疗保健的结合,产生了智能医疗,智能医疗为人们治疗疾病提供了极大的便利。因此,引进智能医疗是医院未来的发展方向。本发明以专家的语义评价信息为基础的智能医疗项目的评估问题为应用背景,在此基础上进行了语义评价信息与概率语言术语集的转化,针对目前属性权重确定方法过程中存在的不足,综合考虑决策信息间的相似度差异指标和不确定性指标,然后通过改进的计算权重的方法和topsis排序法对群决策矩阵进行处理,得到最终的排序结果对医院进行排序,选出最适合建设智能医疗项目的医院,提高了对医院是否适合建设智能医疗项目评估的准确性,具有重要的理论意义和应用价值。
- 还没有人留言评论。精彩留言会获得点赞!