基于Lush多层特征融合偏置网络的地物识别方法
基于lush多层特征融合偏置网络的地物识别方法
技术领域
1.本发明涉及地物识别方法。
背景技术:
2.高光谱图像(hyperspectral images,hsis)是通过搭载在不同空间平台上的高光谱传感器获取得到,蕴含着土地覆盖表面的丰富光谱信息和空间信息[1]。随着高光谱成像技术的快速发展,所获取的光谱与空间信息越来越丰富,这使得准确识别和区分地物覆盖类别成为可能。目前,高光谱图像分类(hyperspectral image classification,hsic)是遥感领域的一个主要研究方向。高光谱分类技术广泛应用在军事侦察[2]、地质灾害[3]、植被和生态监测[4]以及其他领域[5]。
[0003]
在hsi分类任务的早期研究中,对于hsi的光谱特征的提取方法被相继提出,例如,卷积神经网络(convolutional neural networks,cnns)[6]、支持向量机(support vector machine,svm)[7]等。虽然这些方法充分利用了hsi的光谱信息,但是由于没有考虑到空间信息,所得到的结果并不理想。为了提高对高光谱图像分类的能力,一些研究利用多种形态运算来构建高光谱图像的光谱空间特征[8]。基于光谱和空间特征提取的经典方法包括,复合核[9]、形态核[10]等多核学习方法。此外,为了改善分类性能,在[11],稀疏表示作为一种强大的信号处理工具,可用于分析hsi中相邻的空间信息。根据纹理的相似性[12],将hsi分割成多个超像素来探索空间的一致性。上述传统算法大多基于传统机器学习。其中,传统机器学习主要包括特征提取和分类器两个步骤[13],在hsic任务中很难取得较好的分类效果。
[0004]
在高光谱图像分类方法研究中,基于深度学习的分类方法得到广泛的应用。其中,用于提取hsi的空间信息的自动堆叠编码器(sae)[14]和递归自解码器(raes)[15]被提出,能很好地解决手工特征的问题。hu等人[16],通过堆叠一维神经网络(one-dimensional convolutional neural network,1-d cnn)来提取高光谱图像的光谱特征。sae、raes以及1-d cnn只能用来提取一维向量,这就导致hsis的空间信息被破坏。一些基于光谱和空间的二维神经网络的方法相继被提出,并得到令人满意的分类性能。例如,二维自动堆叠编码器(two-dimensional stacked autoencoder,2-d sae)[17]、二维卷积神经网络(two-dimensional convolutional neural network,2-d cnn)[18]等等。chen等人[19]提出了监督三维卷积神经网络(3d-cnn),来弥补2d-cnn的缺点。song等人[20],通过考虑不同层之间的强互补关系,提出了一种深度特征融合网络(dffn)来缓解深度卷积网络存在的过拟合和梯度消失问题。roy等人[21]提出将2d-cnn与3d-cnn结合以降低3d-cnn的复杂度(hybrid-sn)。在[22]中,shi等人提出一种反馈膨胀卷积网络(fecnet),该网络采用膨胀卷积在不增加额外参数的情况下,扩大了卷积感受野,并且获得更具有判别能力的特征。
[0005]
近年来,注意力机制在高光谱图像分类任务中得到广泛的应用。注意力机制可以看作人类视觉的模仿,倾向于强调更重要的信息,而忽视其他信息。ma等人[23],提出了一种双分支多注意机制网络(double-branch multiattention,dbma)来提取空间和光谱信
息。li等人[24]在dbma的基础上提出了一种双注意力机制网络(dbda)。dbda通过空间和光谱两个分支分别提取特征,并且在两个分支中加入了空间注意力机制和通道注意力机制,获得了较好的分类性能。而在[25],shi等人提出一种基于3d协同网络注意力机制的3d-camnet,该网络通过获取hsis空间中垂直方向和水平方向的长距离依赖关系以及不同光谱波段之间的重要性差异,最终提高了分类性能。
[0006]
一个合适的激活函数对于神经网络模型的训练起着至关重要的作用。上述方法中svm、ssrn、dffn等方法都使用了relu[26]作为激活函数。特别地,dbda使用了一种自正则化非单调激活函数:mish[27]。其中relu是一个分段函数,当输入为负时,输出为0。当输入为正时,输入等于输出。相比sigmod和tanh,relu虽然能克服梯度消失的问题,加快训练速度,但是不适合较大的梯度输入,且在参数更新以后,relu的神经元不会再被激活。为了解决relu在输入为负时神经元无法激活的局限性,在relu的基础上,he等人[28]提出一种参数校正线性单元(prelu)。在负数区域内,prelu能保持一个很小的斜率,这样能避免神经元无法激活的问题。此外,由relu改进的渗漏型整流线性单元激活函数(lrelu)[29]、扩展型指数线性单元激活函数(selu)[30]等一系列激活函数也被相继提出。google brain在sigmod的基础上提出了swish[31],该激活函数具有不饱和性、光滑非单调的特点,且能在较深的网络中表现出良好的性能。同样地,mish也具有光滑、非单调、不饱和性,但swish和mish都存在计算量过大、无法缓解网络网络模型过拟合等问题。在本文中,我们提出一种新的激活函数,并命名为lush。
[0007]
在cnn模型的训练中,偏置是一个非常重要的参数。通常,使用梯度下降算法(随机梯度下降算法)对每个偏置进行更新。然而,随机梯度下降算法容易出现梯度爆炸和梯度消失的问题,这不利于偏置的更新。为更好的让神经网络学习更新到最佳偏置,我们提出了一种新的偏置更新方式。
[0008]
在高光谱图像分类任务中,虽然有很多优秀的分类方法,但在分类性能的提升上还有一定局限性。以往的研究中,没有考虑到不同特征层次之间的强互补关系,且如何将深层特征和浅层特征更加有效的融合也是一个难点。
技术实现要素:
[0009]
本发明的目的是为了解决现有方法在地物分类任务中,过深的网络结构往往会导致过拟合现象,而传统的激活函数无法有效解决这个问题;以及随着网络模型的加深,还可能会出现梯度爆炸或梯度消失,这不利于网络模型参数中偏置的更新的问题;以及没有考虑不同特征层次之间的强互补关系,以及如何将深层特征和浅层特征进行有效融合,导致地物分类准确率低的问题,而提出基于lush多层特征融合偏置网络的地物识别方法。
[0010]
基于lush多层特征融合偏置网络的地物识别方法具体过程为:
[0011]
一、建立基于lush多层特征融合偏置网络lmffbnet,基于训练集获得训练好的基于lush多层特征融合偏置网络lmffbnet;
[0012]
所述训练集为采集的高光谱图像;
[0013]
二、将待测高光谱图像输入训练好的基于lush多层特征融合偏置网络lmffbnet,完成对待测高光谱图像的分类;
[0014]
所述基于lush多层特征融合偏置网络lmffbnet包括输入层、前端子网络、后端子
网络、sfb模块、mffb模块、第一卷积模块、第二卷积模块、cam模块、bn层、第一平均池化层、fc层、分类层;
[0015]
所述基于lush多层特征融合偏置网络lmffbnet连接关系为:
[0016]
图像输入前端子网络,前端子网络输出结果分别输入后端子网络和mffb模块;
[0017]
后端子网络输出结果输入mffb模块;
[0018]
将mffb模块输出结果和后端子网络输出结果进行融合,得到融合后特征;
[0019]
融合后特征输入第一卷积模块,第一卷积模块输出输入第二卷积模块;
[0020]
第二卷积模块输出输入cam模块,将cam模块输出结果和第二卷积模块输出结果进行点乘;
[0021]
点乘结果依次经过bn层、第一平均池化层、fc层、分类层,得到最终分类结果。
[0022]
本发明的有益效果为:
[0023]
本发明提出了一种lmffbnet方法。它主要由三个模块组成,分别是多层特征融合模块(multi layer feature fusion block,mffb)、类反馈模块(similar feedback block,sfb)和通道注意力模块(channel attention module,cam)。首先mffb模块通过对前端子网络提取浅层特征和后端子网络提取的深层特征进行分通道融合,再进行不同尺度卷积操作,来充分提取融合特征。其次,为进一步增强特征的传播,本发明引入sfb模块。最后,本发明引入通道注意力模块,来提取通道间的特征差异。
[0024]
本发明的主要贡献总结如下:
[0025]
1)过深的网络结构往往会导致过拟合现象,而传统的激活函数无法有效解决这个问题。为了缓解过拟合问题,本发明提出一种自正则化参数校正非单调激活函数(self-regularization parameter correction non-monotone activation function),并命名为lush。该激活函数不仅可以解决网络过拟合问题,还能提高网络模型的鲁棒性,且通过一系列实验验证了lush优于其他激活函数。
[0026]
2)随着网络模型的加深,还可能会出现梯度爆炸或梯度消失的问题,这不利于网络模型参数中偏置的更新。为了解决这个问题,本发明提出一种新的偏置更新方式,该方式可以解决随机梯度下降算法可能会出现的梯度消失和爆炸所带来偏置无法有效更新的问题。
[0027]
3)为了更好地将不同层次间特征有效融合,本发明提出一种基于lush多层特征融合偏置网络(lmffbnet)。该网络通过将浅层特征的位置、细节信息和深层特征的语义信息更加充分地融合,得到具有更强判别能力的特征,从而提高高光谱图像的分类性能。
[0028]
本发明提出一个自正则化参数校正非单调激活函数:lush。它具有非单调性,不饱和性,分段光滑等特点。不仅能通过学习调整正则化效果,还可以提高网络模型的鲁棒性。接着,本发明提出一种新的偏置更新方法,该方法不仅能解决梯度下降算法的缺点,还能自适应的分配各通道的偏置,从而更好的适应网络。针对高光谱分类任务,本发明提出了一种基于lush和自适应偏置方法,即lmffbnet,它主要由三个模块组成,分别是mffb模块、sfb模块和通道注意力模块。首先,mffb模块通过对前端子网络提取浅层特征和后端子网络提取的深层特征进行分通道融合,再进行不同尺度卷积操作,来充分提取融合特征。其次,为进一步增强特征的传播,本发明引入sfb模块。最后,引入通道注意力模块,来提取通道间的特征差异。此外,为验证本发明提出方法的有效性,本发明在8个数据集上进行了一系列实验。
实验结果证明,相比于其他激活函数,lush的计算量适中,且能明显提高网络模型的分类性能。相比于传统更新方法,自适应偏置不会出现因梯度消失或梯度爆炸而导致无法更新的问题,并且能自适应的分配各通道的偏置,能更好的适应网络。在高光谱分类任务中,与其他先进方法相比,提出的lmffbnet方法具有更强的鲁棒性,且分类性能更高。大量的实验充分证明了本发明提出的lush、自适应偏置及lmffbnet的有效性。
附图说明
[0029]
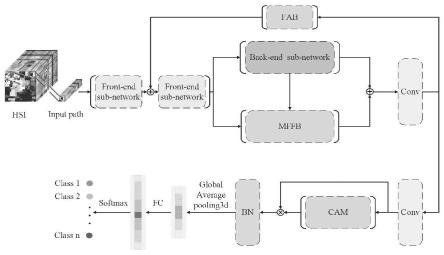
图1为本发明lmffbnet的整体框架图;
[0030]
图2为本发明提出的lush与relu和mish的比较图,(a)为本发明提出的lush与relu的比较图,(b)为本发明提出的lush与mish的比较图;
[0031]
图3为α取不同值时lush函数和lush导数示意图,α=1.0、0.5、0.1,(a)为α取不同值时lush函数示意图,(b)为α取不同值时lush导数示意图;
[0032]
图4为改进后的新的偏置示意图;
[0033]
图5为高斯函数及其以及一阶导数示意图,(a)为高斯函数,(b)为高斯一阶导函数;
[0034]
图6为mffb模块的框图;
[0035]
图7为类反馈机制模块结构(sfb)图;
[0036]
图8为通道注意模块(cam)结构图;
[0037]
图9为不同激活函数在mnist数据集上的比较图;(a)为随着网络层数的增加,不同激活函数对网络分类测试精度的比较图;(b)为随着输入高斯噪声的增加,不同激活函数对测试损失的比较图;testing accuarcy为准确率,testing loss为损失值,number of layers为网络层数,stand deviation of input gaussian noise为输入高斯噪声;
[0038]
图10为使用不同激活函数时,提出的lmffbnet在不同高光谱数据集上得到的oa值示意图;
[0039]
图11为使用不同偏置设置在不同高光谱数据集上的oa值示意图;
[0040]
图12为不同方法在ip数据集上的分类地图;(a)为真实标签;(b)为svm(68.70%);(c)为hybrid-sn(68.88%);(d)为dbda(89.32%);(e)为ssrn(89.88%);(f)为dbma(89.62%);(g)dffn(96.62%);(h)3d-camnet(94.76%);(i)fecnet(96.26%);(j)proposeed(97.47%);
[0041]
图13为不同方法在sv数据集上的分类地图;(a)为真实标签;(b)为svm(86.88%);(c)为hybrid-sn(86.32%);(d)为dbda(93.66%);(e)为ssrn(93.24%);(f)为dbma(94.22%);(g)为dffn(97.48%);(h)为3d-camnet(97.32%);(i)为fecnet(96.86%);(j)为proposeed(98.71%);
[0042]
图14为不同方法在ksc数据集上的分类地图;(a)为真实标签;(b)为svm(88.90%);(c)为hybrid-sn(86.41%);(d)为dbda(96.79%);(e)为ssrn(96.14%);(f)为dbma(94.92%);(g)为dffn(99.77%);(h)为3d-camnet(98.83%);(i)为fecnet(98.84%);(j)为proposeed(99.94%);
[0043]
图15为不同方法在up数据集上的分类地图;(a)为真实标签;(b)为svm(84.53%);(c)为hybrid-sn(83.17%);(d)为dbda(94.92%);(e)为ssrn(93.59%);(f)为dbma
(91.74%);(g)为dffn(97.52%);(h)为3d-camnet(96.08%);(i)为fecnet(96.77%);(j)为proposeed(98.26%);
[0044]
图16为不同方法在ht数据集上的分类地图;(a)为真实标签;(b)为svm(84.12%);(c)为hybrid-sn(88.12%);(d)为dbda(92.35%);(e)为ssrn(88.22%);(f)为dbma(91.69%);(g)为dffn(96.07%);(h)为3d-camnet(97.23%);(i)为fecnet(97.59%);(j)为proposeed(98.31%);
[0045]
图17为不同融合层数在不同数据集上得到的oa值示意图;
[0046]
图18为不同输入大小k
×
k时样本比例与oa的关系图;(a)为ip数据集;(b)为ksc数据集;(c)为ht数据集;(d)为up数据集;(e)为sv数据集;
[0047]
图19为lmffbnet使用不同激活函数在ip数据集上得到的oa值示意图。
具体实施方式
[0048]
具体实施方式一:本实施方式基于lush多层特征融合偏置网络的地物识别方法具体过程为:
[0049]
lmffbnet的整体框架
[0050]
高光谱图像(hsi)数据为x={x1,x2,......xn},则高光谱图像(hsi)数据对应的类别标签为y={y1,y2,y3,......yn};
[0051]
从原始hsi数据中提取i个大小为v∈rh×w×
l
的立方体,其中h
×
w为立方体的空间大小,而l为光谱波段数。
[0052]
设计的lmffbnet主要由三部分构成,lmffbnet的整体框架如图1所示。首先,输入图像经过前端子网络提取浅层特征。接着,使用一个网络结构较深的后端子网络提取深层特征。其次,为了更加充分的融合深层特征和浅层特征,设计了一种多层特征融合模块(mffb),将融合特征向后传递与其后端网络提取的特征进行融合。为了进一步增强浅层特征和深层特征的传播,我们设计了一种sfb模块。接着,通过通道注意力模块得到加权特征图后,采用bn层和dropout层来增强数值稳定性和克服过拟合。最后得到最终的分类结果。
[0053]
接下来,将详细介绍lmffbnet中的三个主要模块的原理和框架。
[0054]
一、建立基于lush多层特征融合偏置网络lmffbnet,基于训练集获得训练好的基于lush多层特征融合偏置网络lmffbnet;
[0055]
所述训练集为采集的高光谱图像(hsi);
[0056]
二、将待测高光谱图像(hsi)输入训练好的基于lush多层特征融合偏置网络lmffbnet,完成对待测高光谱图像的分类;
[0057]
所述基于lush多层特征融合偏置网络lmffbnet包括输入层、前端子网络、后端子网络、sfb模块、mffb模块、第一卷积模块、第二卷积模块、cam模块、bn层、第一平均池化层、fc层、分类层;
[0058]
所述基于lush多层特征融合偏置网络lmffbnet连接关系为:
[0059]
图像输入前端子网络,前端子网络输出结果分别输入后端子网络和mffb模块;
[0060]
后端子网络输出结果输入mffb模块;
[0061]
将mffb模块输出结果和后端子网络输出结果进行融合,得到融合后特征;
[0062]
融合后特征输入第一卷积模块,第一卷积模块输出输入第二卷积模块;
[0063]
第二卷积模块输出输入cam模块,将cam模块输出结果和第二卷积模块输出结果进行点乘;
[0064]
点乘结果依次经过bn层、第一平均池化层、fc层、分类层,得到最终分类结果。
[0065]
具体实施方式二:本实施方式与具体实施方式一不同的是,所述前端子网络依次包括第一卷积层、第二卷积层、lush激活函数;
[0066]
所述后端子网络依次包括第三卷积层、第四卷积层、第五卷积层、第六卷积层、lush激活函数;
[0067]
所述第一卷积模块依次包括第七卷积层、lush激活函数;
[0068]
所述第二卷积模块依次包括第八卷积层、lush激活函数。
[0069]
所述第一层卷积核大小为1*1*7,步长为2;
[0070]
所述第二层卷积核大小为1*1*1,步长为1;
[0071]
所述第三层卷积核大小为1*1*3,步长为1;
[0072]
所述第四层卷积核大小为1*1*5,步长为1;
[0073]
所述第五层卷积核大小为1*1*7,步长为1;
[0074]
所述第六层卷积核大小为1*1*1,步长为1。
[0075]
其它步骤及参数与具体实施方式一相同。
[0076]
具体实施方式三:本实施方式与具体实施方式一或二不同的是,所述mffb模块包括第三卷积模块、第四卷积模块、第五卷积模块、第六卷积模块;
[0077]
所述mffb模块连接关系为:
[0078]
将前端子网络输出特征a均分为特征a1、特征a2、特征a3、特征a4;
[0079]
将后端子网络输出特征b均分为特征b1、特征b2、特征b3、特征b4;
[0080]
将特征a1和特征b1进行融合(加法操作)得到特征c1,将特征c1输入第三卷积模块输出特征c2;
[0081]
将特征c2、特征a2和特征b2进行融合(加法操作)得到特征f1,将特征f1输入第四卷积模块输出特征c3;
[0082]
将特征c3、特征a3和特征b3进行融合(加法操作)得到特征f2,将特征f2输入第五卷积模块输出特征c4;
[0083]
将特征c4、特征a4和特征b4进行融合(加法操作)得到特征f3,将特征f3输入第六卷积模块输出特征f;
[0084]
将特征f与后端子网络输出特征b进行融合(加法操作)得到mffb模块输出结果;
[0085]
所述第三卷积模块依次包括第九卷积层、第十卷积层、第十一卷积层、第十二卷积层、lush激活函数;
[0086]
所述第四卷积模块依次包括第十三卷积层、第十四卷积层、第十五卷积层、第十六卷积层、lush激活函数;
[0087]
所述第五卷积模块依次包括第十七卷积层、第十八卷积层、第十九卷积层、第二十卷积层、lush激活函数;
[0088]
所述第六卷积模块依次包括第二十一卷积层、第二十二卷积层、第二十三卷积层、第二十四卷积层、lush激活函数。
[0089]
其它步骤及参数与具体实施方式一或二相同。
进行级联操作得到特征x3;将特征x3输入第三平均池化层,得到特征x;对特征x进行卷积操作得到校准矩阵y;即
[0107]
y=lush(f(x)=xk+b)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)
[0108]
式(18)中,f(
·
)表示卷积函数,b表示卷积偏置项,k表示卷积核,lush表示lush激活函数;所述x0为2c个rh×w×
l
,其中h
×
w为立方体的空间大小,l为光谱维度,c为通道数。
[0109]
sfb模块:
[0110]
为了更好地融合浅层和深层特征,受到[54]的启发。本文设计了一种sfb模块,来进一步加强特征的融合。该模块具体结构如图7所示。假设中间的输入x0为2c个rh×w×
l
,其中h
×
w为立方体的空间大小,l为光谱维度,c为通道数。x0经过一个最大池化层和平均池化层之后生成两个映射,分别为x1和x2。为了平衡局部信息与全局不变性,将所得的x1和x2映射进行级联操作得到x3。然后,将结果经过一个全局平均池化层后得到x。最后,x和k进行卷积操作得到校准矩阵y,即
[0111]
y=lush(f(x)=xk+b)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4)
[0112]
式(18)中,f(
·
)表示卷积函数,b表示卷积偏置项。
[0113]
其它步骤及参数与具体实施方式一至四之一相同。
[0114]
具体实施方式六:本实施方式与具体实施方式一至五之一不同的是,所述cam模块的连接关系为:
[0115]
假设输入为a
′
∈rh×w×1,通道数为c,经过向量化操作将rh×w×c转化为rn×c;
[0116]
其中n=h
×
w表示空间域的像素数量,c表示通道数;
[0117]
将rn×c与rn×c的转置矩阵rc×n相乘得到矩阵rc×c;
[0118]
将得到的矩阵rc×c经过softmax激活函数,得到通道注意力图b
′
∈rc×c:
[0119][0120]
式(19)中,ai′
和aj′
分别是第i个和第j个通道的特征图;bj′i表示第i个通道对第j个通道的影响;
[0121]
将b
′
和a
′
进行矩阵乘法,并将得到的结果重塑为rh×w×1;
[0122]
将重塑为rh×w×1的结果乘以参数β并与a
′
执行逐元素求和运算以获得最终输出e;
[0123]
第i个通道的输出特征可表示为
[0124][0125]
其中,β表示从0逐渐学习的一个权重,由式(20)可知,每个通道的最终特征是所有通道的特征和原始特征的加权和;通过这种方式,建立特征之间的长距离语义依赖关系,从而提高特征的判别能力。
[0126]
注意力机制在卷积神经网络(cnn)中能够有效增强对特征的判别能力,故在高光谱图像分类中得到广泛应用。在提取特征时,不同通道的语义响应彼此关联。通过挖掘通道映射之间的相互依赖关系,可以强调相互依赖的特征映射,改进特定语义的特征表示。因此,我们采用一个通道注意力模块来描述通道之间的依赖关系。通道注意力模块结构如图8所示。
[0127]
其它步骤及参数与具体实施方式一至五之一相同。
[0128]
具体实施方式七:本实施方式与具体实施方式一至六之一不同的是,
[0129]
所述lush激活函数表达式为:
[0130]
lush激活函数
[0131]
在对激活函数的理论研究中,类似于swish、mish的属性一直在被反复讨论,如非单调性、能保留较小的负值流入、不饱和性等。一个合适的激活函数对于神经网络模型的训练、理解非线性起着至关重要的作用。在对不同激活函数的探究中发现,一个具有非单调性、不饱和性、能保留较小的负值流入,以及能解决过拟合问题的非线性激活函数能够有效提高网络性能。因此,本发明提出了lush激活函数。首先,原始lush激活函数可表示为
[0132][0133]
其中,x表示输入,α表示超参数;
[0134]
图2给出了lush与常用的relu及mish的比较。从图(a)可以看出,当学习参数α=1.0且x≥0时,lush(x)=relu,即输出等于输入。从图(b)可以看出,当学习参数α=1.0且x<0时,lush(x)=mish(x),mish和lush都能保持较小的负值流入,从而稳定网络梯度流。对于激活函数来说,有下界能实现正则化效果,lush的上下界范围为[≈-0.31
×
α,∞)。
[0135]
当α不同时,lush函数及对应的导数如图3所示。可见,不同的学习率使lush有不同的下界范围和正则化效果。lush函数的微分可表示为
[0136][0137]
其中,λ=2e
x
+e
2x
+2。
[0138]
为了优化原始lush激活函数,我们引入一个可学习参数αi,来调节lush的正则化效果;其中i表示第i个通道的系数;引入学习参数后的lush可表示为:
[0139][0140]
其中xi是第i个通道上非线性激活的输入,αi是控制lush的下界,0≤αi≤1;
[0141]
当αi=1时且xi<0,lush为mish激活函数;
[0142]
当αi=0时,lush将变为relu激活函数;
[0143]
在更新αi时,本发明采用动量法更新αi,更新过程表示为
[0144][0145]
其中μ表示动量,λ表示学习率,“:=”左边的αi示更新后的学习率,ε表示lush激活函数,“:=”右边的αi表示初始学习率;
[0146]
特别地,在更新αi时没有使用权重衰减(l2正规化)。权重衰减会使αi趋向于零,从而使lush偏向于relu。
[0147]
此外,lush可以使用反向传播进行训练,并与其它lush层同时优化;每个lush层的
αi梯度可表示为
[0148][0149]
其中ε表示目标函数,表示遍历所有通道特征图,是从更深层传播的梯度,lush的梯度可表示为
[0150][0151]
在这里,我们可将αi设置为通道共享系数β,这样每个lush层中只需引入一个额外的参数β;对于通道共享系数β的梯度可表示为
[0152][0153]
其中表示对所有通道求和;
[0154]
公式(5)是不同通道使用不同的学习参数αi(即每个通道的学习参数不一样,具体来说,假设一共有i个通道就会有i个学习参数,并且每个学习参数值不同);
[0155]
公式(7)是不同通道共享一个学习参数β(即每个通道的学习参数是一样,具体来说,假设一共有i个通道就会也有i个学习参数,但每个学习参数的值是相同的,也就是说β是通道共享参数);
[0156]
此外,在实验中,设置初始学习率αi=1,使用通道共享系数β。
[0157]
lush能保留较小的负值流入,达到正则化效果。特别地,学习率αi的引入,能自适应地调节正则化效果。lush无上界,这样可以避免训练急剧下降的梯度饱和,加快训练过程。
[0158]
其它步骤及参数与具体实施方式一至六之一相同。
[0159]
具体实施方式八:本实施方式与具体实施方式一至七之一不同的是,
[0160]
所述卷积偏置项b表达式为:
[0161]
自适应偏置
[0162]
感知机是多层感知机和人工神经网络的前身,它是一种用于监督学习的仿生算法,实质上是一个线性分类器。偏置的作用就是调整神经元被激活的容易程度。在cnn中,偏置的存在是为了更好地拟合数据,能更好地处理复杂的分类问题。
[0163]
在多层神经网络中对于输入可表示为
[0164][0165]
其中表示第l层第i
′
个神经元的输出,表示第l层的第i
′
个神经元的权重,
[0166]
表示第l层的第i
′
个神经元的偏置,表示第l层第i
′
个神经元的输入;
[0167]
在反向传播中,损失函数关于偏置的偏导可表示为
[0168]
[0169]
其中loss表示神经网络的损失函数;
[0170]
在反向传播时,偏置的更新可表示为
[0171][0172]
其中表示第l层的第i
′
个神经元的偏置,η表示学习率;
[0173]
当cnn使用随机梯度下降算法算法时,存在梯度爆炸和梯度消失的问题,会使偏置等参数无法有效地进行更新。为了缓解此问题,本发明提出一种新的偏置更新方式。接下来,通过推导分析出新的偏置更新公式。
[0174]
在公式(10)中,当固定学习率为η时,分析对偏置的影响,可表示为
[0175][0176]
其中,b
loss
为更新后的偏置值c为初始化的偏置值;
[0177]
当时,b
loss
随着自变量的减小而减小,b
loss
随着自变量增大而增大;
[0178]
当时,b
loss
随着自变量的减小而增大;
[0179]
同样,在公式(10)中,当固定时,分析η对偏置的影响,通常,0<η<1且逐渐减小;当学习率η为自变量时,即b
loss
是随着自变量η的减小而增大;
[0180]
最后,由公式(12),当以为自变量时,即将x看作单一变量时,改进后的偏置公式可表示为
[0181]
b=-x
·
exp(-(x)2)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(18)
[0182]
改进后的偏置如图4所示;
[0183]
通常,将hsi数据处理成高斯分布输入网络中,如图5中(a)所示,高斯函数的一阶导数如图5中(b)所示。如上所述,偏置是为了更好地拟合数据,而反向传播算法的过程,就是对其求导的过程。对于网络输入呈高斯分布,反向传播时,呈现高斯一阶导函数形式。对比图4和图5中(a),可知新的偏置等于高斯偏导函数。
[0184]
考虑到通道间特征的差异性,通过引入一个相关系数υ,来合理的分配各通道的偏置值;相关系数和各通道偏置值可表示为
[0185][0186]
[0187]
其中表示第l层的第i个通道的偏置值,表示第l层的第i个通道的特征,表示第l层的第i个通道的全局平局特征,表示与的协方差,表示的方差,表示的方差,υ表示相关系数;loss为loss函数的输出值;
[0188]
相关系数表示第l层的第i个通道与该层的全局平均特征的相关程度;当|υ|越大,第l层的第i个通道与该层的全局平均特征相关程度越大;特别地,|υ|≤1;通道间的υ越接近,偏置值也越接近。
[0189]
其它步骤及参数与具体实施方式一至七之一相同。
[0190]
实验与分析
[0191]
为了验证提出的lmffbnet的分类性能,将使用四类据集进行一系列实验。所有的实验将在相同的配置上实现,即intel(r)core(tm)i9-9900k cpu、nvidia geforce rtx2080ti gpu和32gb随机存取内存的服务器。实验软件平台基于windows 10 vscode操作系统,包括cuda10.2、pytorch1.8.0和python3.6.5。设计的网络全部采用pytorch框架设计与实现,内容包括:实验设置、lush的有效性验证、自适应偏置的有效性验证、实验结果、讨论。
[0192]
a、实验设置
[0193]
1)高光谱图像数据集介绍:在本文中,选择了五个使用广泛的高光谱图像数据集,包括由机载可见红外成像光谱仪(aviris)传感器捕获生成的印度松树(indian pines,ip)、肯尼迪航空中心(kennedy space center,ksc)以及萨利纳斯山谷(salinas valley,sv)数据集。由反射光学光谱成像系统(rosis-3)传感器获取的帕维亚大学(pavia university,up)数据集。由紧凑型机载光谱成像仪(casi)传感器获取的休斯顿大学(houston,ht)数据集。
[0194]
ip数据集:空间大小为145
×
145,空间分辨率约为20m。光谱波段数共有220个,由于其中有20吸水波段,因此用于实验的光谱波段数为200个。共有16个地物覆盖类别(如表ⅰ所示)。
[0195]
表ⅰip数据集地物覆盖具体类别
[0196]
[0197][0198]
sv数据集:空间大小为512
×
217,空间分辨率为3.7m。光谱波段数共有224个,由于其中也有20个吸水波段,因此用于实验的光谱波段数为204个,共有16个地物覆盖类别(如表ⅱ所示)。
[0199]
表ⅱsv数据集地物覆盖具体类别
[0200][0201]
ksc数据集:空间大小为512
×
614,空间分辨率为18m。光谱波段数共有224个,除去吸水波段和低信噪比频段后,被用于实验的光谱波段数为176个,共有13个地物覆盖类别(如表ⅲ所示)。
[0202]
表ⅲksc数据集地物覆盖具体类别
[0203][0204][0205]
up数据集:空间大小为610
×
340,空间分辨率为1.3m。光谱波段数共为115个,其中12个波段由于受到噪声影响被去除,则被用于实验的光谱波段数为103个。共有9个地物覆盖类别(如表ⅳ所示)。
[0206]
表ⅳup数据集地物覆盖具体类别
[0207][0208]
ht数据集:空间大小为349
×
1905,空间分辨率为2.5m。被用于实验的光谱波段数为114个,共有15个地物覆盖类别(如表
ⅴ
所示)。
[0209]
表
ⅴ
ht数据集地物覆盖具体类别
[0210][0211][0212]
2)参数设置:在本文提出的leffbnet中,批处理大小设置为16,最大训练轮次为200。实验训练过程中优化器采用adam。学习率采用0.0005。采用交叉熵损失函数来衡量真实概率分布与预测概率分布之间的差异。为了消除随机性,我们在相同实验配置下,取30次实验结果的平均值作为最终的实验结果。
[0213]
3)评价指标:
[0214]
对于高光谱分类任务,采用三种评估指标来衡量每种方法的分类性能,包括整体精度(oa)、平均准确度(aa)和卡帕系数(kappa)。具体来说,oa代表了整个像素的真实分类比例。aa表示所有类别的平均准确度。而kappa系数反映了地面真实度与分类结果的一致性。
[0215]
b、lush有效性验证
[0216]
在本节中,为了验证lush激活函数的有效性,分别在mnist数据集[32]、cifar-10[33]数据集、imagenet-2012[34]数据集,以及五个高光谱数据集上进行实验分析。
[0217]
1)lush激活函数对网络模型鲁棒性影响
[0218]
网络模型的鲁棒性,可以通过增加网络层数和加入噪声进行验证。本文为了验证所提出的激活函数的鲁棒性,在mnist数据集上进行了两个实验,包括不同层数下的网络性能实验,以及加入高斯噪声后的网络性能实验。
[0219]
首先,受[35]启发,构建了一个层数为15的初始卷积网络,网络深度线性增加。使用sgd优化器,初始学习率全部设置为0.0001,批量大小设置为128。为了减少初始化的影响,使用了batchnormailization[36]层和dropout层。随着神经网络层数的增加,对分别采用relu、prelu、swish、mish和lush激活函数的网络分类精度进行比较。从图9(a)中可以看出,在18层之后,采用relu和swish的分类准确率急剧下降。24层之后,采用mish和prelu的分类准确率也逐渐大幅度下降。然而,lush在网络模型层数较多时,依然保持着较高的分类准确率。
[0220]
接下来,进行了加入高斯噪声后的网络性能实验。由于简单的网络模型能减少其他因素干扰,且网络模型的鲁棒性较差,我们构建了一个只有5层卷积的简单神经网络,以更好地观察不同激活函数对网络模型鲁棒性的影响。其他参数设置均与网络深度实验相同。通过在输入的mnist数据中加入以“0”为分布中心,标准差由0逐渐增加到10的高斯噪声,观察网络的损失,以评估不同激活函数在噪声影响下对网络模型鲁棒性的影响。从图9(b)可以看出,在输入高斯噪声逐渐增加的情况下,相比其他激活函数,lush始终保持着较低的损失值。图11显示的实验结果表明,本文提出的lush不仅能缓解过拟合问题,还能增强网络模型的鲁棒性。
[0221]
2)lush激活函数对网络模型性能的影响
[0222]
在cifar-10数据集上,通过在不同的网络框架上更换激活函数来比较不同激活函数的性能。其中,网络框架包括resnet-20[37]、simplenet[38]、xceptionnet[39]、capsulenet[40]、inception resnet v2[41]、densenet-121[42]、mobilenet-v2[43]、shufflenet-v1[44]、inception v3[45]和efficient net b0[46]。在保持网络参数和训练参数不变的条件下,通过使用不同的激活函数,来比较各网络模型在cifar-10数据集上的图像分类性能。分类结果如表ⅵ所示,粗体表示最高的分类精度。可以看出,相比于其他激活函数,采用lush作为激活函数有利于得到更高的图像分类性能。
[0223]
为了进一步比较不同激活函数对网络性能影响,在被认为计算机视觉领域最具挑战性和最重要的分类任务之一的imagenet 2012数据上,将relu、prelu、swish、mish、lush进行比较。imagenet 2012数据集共有1000个类别,1280000幅训练图像。实验采用50000幅图像组成的验证集来评估采用不同激活函数的网络模型的分类性能。对于imagenet2012数据集[34],我们使用top-1 error和top-5 error两种评估指标。top-1 error是网络模型只输出一个预测结果且分类错误的概率。top-5 error是网络模型输出五个预测结果,且五个预测结果中没有一个为分类正确的概率。top-5 error是imagenet large scale visual recognition challenge(ilsvrc)中使用的主要评价标准。采用7个主流的网络模型,包括alexnet[47]、overfeat[48]、zfnet[49]、googlenet[50]、resnet-110[51]、senet[52]和vgg[53],对这些激活函数进行评估,分类结果如表ⅶ所示。其中,swish激活函数在googlenet和senet模型上能获得较低的top-1 error和top-5 error,但在其他网络模型上得到的top-1 error和top-5 error相对较高,这表明swish并不能适用所有模型框架。同样的,使用relu和prelu作为激活函数,各模型的分类性能也不是一直理想。而mish,虽然能在各模型中均表现较好的性能,但相比于lush,mish给网络模型带来的分类增益更低。采用lush的网络模型,其top-1 error和top-5 error均低于采用其他激活函数的网络模型的top-1 error和top-5 error。实验结果表明,lush可以适用于所有主流的神经网络模型,并提高模型的分类性能。
[0224]
表ⅵ在cifar-10数据集上采用不同激活函数的网络模型的分类结果
[0225][0226]
表ⅶ在imagenet-2012数据集上采用不同激活函数的网络模型的分类结果
[0227][0228]
3)采用lush激活函数的lmffbnet分类性能
[0229]
在提出的lmffbnet中,采用不同的激活函数,比较该方法在不同高光谱数据集上获得的分类性能。其中lush和prelu的初始学习率αi都设为0.25,表viii中,给出了lush在lmffbnet上学习得到的部分参数。从表viii可以看出,lush学习到的参数不会超过1,这说明lush不使用权重衰减,也能很好的调整lush中的参数。图10给出了lmffbnet使用不同激活函数在不同高光谱数据集上得到的oa值。从图10可以看出,在使用relu作为激活函数时,lmffbnet方法在in、up、ksc、ht数据集上获得的oa值最低。使用mish作为激活函数,可以在一定程度上提高oa值。使用lush作为激活函数时,提出的lmffbnet在所有数据集上都能获得的最高的oa值。
[0230]
表viii在lmffbnet中,lush学习到的部分参数(b:batch size,c:输出通道数,k:卷积核大小,s:步长)
[0231][0232]
c、自适应偏置的有效性验证
[0233]
传统的偏置初始化方法是使用高斯分布生成随机值,并使用梯度下降算法进行网络模型参数更新。这种初始化参数更新方法缺乏对提取的特征图间的相关性进行考虑,且采用随机梯度下降算法更新算法可能会出现梯度消失或梯度爆炸的问题。假设bais为偏置
变量,为了验证自适应偏置的有效性,在高光谱数据集上,分别设置bais为常数c、无偏置、训练模型得到的偏置,以及自适应偏置,来分别比较lmffbnet在不同偏置下在不同高光谱数据上获得的oa值。提出方法在不同偏置设置下在不同高光谱数据集上得到的oa值如图11所示。由图11可知,当设置bais为c=1时,提出的lmffbnet方法在所有高光谱数据集上得到的oa值均最低。与设置无偏置相比,lmffbnet方法使用偏置能提高网络的分类性能。然而,传统的偏置更新与初始化,并没有考虑到通道间的差异性。这可能会使通道间存在相似特征的情况下,由于初始偏置的随机分配而导致提取的特征不能有效融合,进而降低lmffbnet的分类性能。当采用自适应偏置时,从图11可以看出,lmffbnet方法在所有高光谱数据集中均能获得最高的oa值。结合表ix,可以看到,在相关系数υ越接近的情况下,偏置值也就越接近。也就是说,通道间的特征越相似,偏置值就越接近,因此合理的分配偏置值可以提高网络的分类性能。从表ix中还可以看出,传统方法出现了梯度消失或梯度爆炸问题,导致偏置没有得到有效的更新。相比于传统方法,本文提出的自适应偏置方法不仅能更合理地分配偏置,还能解决梯度消失和梯度爆炸导致的偏置无法有效更新的问题。
[0234]
表ix训练模型得到的偏置和自适应偏置的比较
[0235][0236]
d、实验结果
[0237]
在本节中,为了评估提出的lmffbnet的性能,将提出方法与其它先进的分类方法进行比较,包括svm[7],hybrid-sn[21],dbda[24],ssrn[9],dbma[23],dffn[20],3d-camnet[25],fecnet[22]。
[0238]
svm是对于径向基函数(rbf)核的向量机,这是直接对输入的每个像素进行分类的方法。hybrid-sn设计了一种基于混合光谱的分类方法,先采用3d-cnn提取光谱-空间特征后,再采用2d-cnn提取空间特征。dbma和dbda设计了光谱分支和空间分支分别提取hsis的光谱特征和空间特征,并在两个分支分别采用注意力机制强调通道特征和空间特征。ssrn设计了空间和光谱的3d-cnn残差块来提取空间特征和光谱特征。dffn设计了一种基于残差结构的深度特征融合网络,通过较深的网络来提取hsi的特征,并融合不同层的输出来进一步提高分类精度。3d-camnet设计了一种三维协同注意力机制网络,获取高光谱图像空间中垂直方向和水平方向的长距离依赖关系,对不同光谱波段之间的差异进行提取。fecnet设计了带有类反馈模块的膨胀卷积网络,利用膨胀卷积将卷积的感受野扩大,从而更好的提取上下文特征。本文设计了一种lmffbnet模型,通过将浅层特征的位置、细节信息和深层特征的语义信息更加充分的融合,得到具有更强判别能力的特征,从而提高分类性能。
[0239]
表x-xiv给出了所有方法在ip、sv、ksc、up以及ht数据集上的分类精度,粗体表示最高分类精度。在表x中可以看出,无论是oa、aa和kappa,还是单个类别的分类精度,与其他方法相比,本文提出的方法均有较大优势。在表xi中,对于sv数据集,由于各地物覆盖类别分布较为规律,所有类别的分类精度均较高。ksc数据集与ip数据集具有相同的类别数量,
且地物覆盖物分布较为分散。尽管如此,从表xii中可以看到,提出的方法不仅是获得了较高的oa、aa以及kappa,且所有地物覆盖类别也都取得了最好的分类精度。其他数据集相比,up数据集的类别较少。从表xiii可知,提出的方法分类精度均较高。对于分布较复杂且类别较多的ht数据集,从表xiv中可以看到,相对于其他方法,我们所提出的lmffbnet方法仍然可以获得较高的分类精度。
[0240]
为了进一步证明提出方法的有效性,图12-16给出了所有方法的分类可视化结果。可以看出,svm、hybrid-sn、ssrn不能有效的提取空间特征和光谱特征,导致对高光谱图像的分类效果差,噪声较多。对于dbda、dbma、3d-camnet,由于采用了不同的注意力机制网络,分类性能有一定提升,但分类结果图中依然有许多分类错误的情况,且图像不够平滑。对于也采用特征融合思想的dffn,该方法只在ksc数据集上获得了较为满意的分类结果,但分类结果图中依然存在着许多噪声和分类错误。本文提出的lmffbnet方法不仅在分类精度上优于其他先进的分类方法,而且分类地图更为平滑,更接近真实地物图。这充分验证了提出的方法的优越性。
[0241]
综上所述,本文提出的lmffbnet在五个高光谱图像数据集中的oa、aa、kappa均比其他先进方法更高,这充分证明了提出方法具有很强的泛化能力。此外,在所有方法的分类地图中,本文方法能够得到更加平滑且接近真实地物图的可视化结果。
[0242]
表x.不同方法在ip数据集上的分类结果(%).
[0243][0244][0245]
表xi不同方法在sv数据集上的分类结果(%).
[0246][0247]
表xii不同方法在ksc数据集上的分类结果(%)
[0248][0249]
表xiii不同方法在up数据集上的分类结果(%)
[0250][0251]
[0252]
表xiv不同方法在ht数据集上的分类结果(%).
[0253][0254]
e、讨论
[0255]
在本节中,将详细的讨论影响提出方法性能的模块,包括采用不同的输入与不同样本比例对分类精度oa的影响、lmffbnet中不同模块的消融实验、不同方法以及使用不同激活函数在ip数据集上运行时间和参数的比较。
[0256]
1)采用不同数量的特征融合层对分类精度oa的影响:
[0257]
特征融合层的数量n是lmffbnet的一个重要的超参数,在输入空间大小和训练样本比例相同的情况下,特征融合层数的改变对分类性能的影响比较大。其中,输入的空间大小为:9
×
9,ip数据集训练样本比例为:3.0%,ksc数据集训练样本比例为:5.0%,ht数据集训练样本比例为:3.0%,up数据集训练样本比例为:0.5%,sv数据集训练样本比例为:0.5%。为进一步验证特征融合层数对网络分类性能的影响,采用不同的特征融合层数:3、4、5、6,以探索lmffbnet方法的最佳融合层数。图15中给出了lmffbnet在所有数据集上采用给定的空间大小和数据集训练样本比例,使用不同数量的特征融合层n得到的oa结果。从图17中可以看出,随着融合层数n的增加,提出方法在各数据集上获得的oa值也在增加。当n=3时,在五个数据集上得到的oa值均较低,而当n=4、5、6时,在五个数据集上得到的oa值均较高。但当n=4时,各数据集的oa值就已经达到了最佳,继续增加融合层所带来的增益并不大,还会增加参数量和运行时间。因此,mffb模块最佳融合层为4。
[0258]
2)不同的空间输入大小与样本比例对分类精度oa的影响:
[0259]
不同的空间输入尺度和训练样本比例p都能对网络的分类性能产生较大的影响。为了进一步验证不同输入大小k
×
k与不同样本比例p对性能的影响,选择输入的空间大小k为:5
×
5,7
×
7,9
×
9,11
×
11和13
×
13。其中训练比例p指的是网络采用训练样本的比例。在ip、ksc和ht数据集上的训练样本比例p为:{1.0%,2.0%,3.0%,4.0%,5.0%},由于up和sv数据集样本数相对ip、ksc、ht数据集样本要多,所以在up和sv数据集上练样本比例p取值为:{0.5%,1.0%,1.5%2.0%,2.5%}。图18给出了lmffbnet在五个数据集上采用不同的输入大小k与不同训练比例p的oa结果,红色为等高线最大区域,深蓝色为等高线最小区域。
从图18中可以看出,当输入空间大小k=5时,五个数据集的样本比例p最小时,提出的方法得到的oa值均最低。而随着训练样本比例p的增长,oa缓慢增长。当输入空间大小k=9时,提出的方法能得到最佳分类结果。当ip、ksc、ht、up和sv的训练样本比例p分别为3.0%、3%、5%、0.5%以及0.5%时,提出的方法能得到较高的分类结果。
[0260]
3)所提出lmffbnet中不同模块的有效性
[0261]
为了验证提出方法的有效性,我们对提出方法中比较重要的三个模块,进行了消融实验,模块包括mffb、sfb和cam,结果如表xv所示。可以看出,当mffb、sfb和cam均存在时,在ip数据集上取得的oa值最高。相反,当这三个模块均不存在时,在ip数据集上取得的oa值最低。通过逐渐增加模块,整体oa值逐渐提高。通过消融实验可以看出:1)基础网络的分类性能最低,但随着模块逐渐增加,整体oa值逐渐提高。2)消融实验充分验证了mffb、sfb和cam的有效性。
[0262]
表xv lmffbnet中不同模块组成的oa值(%)
[0263][0264]
4)lmffbnet使用不同激活函数在ip数据集运行时间和参数的比较:
[0265]
表xvi给出提出的lmffbnet方法分别使用relu、prelu、swish、mish、lush作为激活函数,在ip数据集上的训练时间和测试时间,以及参数量。其中输入块大小统一为:9
×9×
200。由表xvi可知,运行时间最长的是使用mish,而使用lush仅次于运行时间较短的relu和prelu。为了进一步比较不同激活函数给lmffbnet带来的整体分类增益。我们给出了lmffbnet使用不同激活函数,在ip数据集上得到的oa值,如图19所示。由图19可见,与swish、mish相比,lush所需运行时间更短,且能得到更高的oa值;与relu和prelu相比,在运行时间相差很小的情况下,lush所带来的oa增益分别为1.05%和1.99%。实验结果表明,本文提出的lush激活函数不仅复杂度较适中,且相比其他激活函数,能明显提高网络的分类性能。
[0266]
表xvi lmffbnet使用不同激活函数在ip数据集上运行的时间和参数的比较
[0267][0268][0269]
参考文献
[0270]
[1]li,z.;huang,l.;he,j.a multiscale deep middle-level feature fusion network for hyperspectral classifification.remote sens.2019,11,695.
[0271]
[2]p.w.yuen and m.richardson,“an introduction to hyperspectral imaging and its application for security,surveillance and target acquisition,”imag.sci.j.,vol.58,no.5,pp.241
–
253,oct.2010.
sensing images with support vector machines,”ieee trans.geosci.remote sens.,vol.42,no.8,pp.1778
–
1790,aug.2004.
[0285]
[16]b.rasti et al.,“feature extraction for hyperspectral imagery:the evolution from shallow to deep,”ieee geosci.remote sens.mag.,vol.8,no.4,pp.60
–
88,dec.2020.
[0286]
[17]x.zhang,y.liang,c.li,n.huyan,l.jiao,and h.zhou,“recursive autoencoders-based unsupervised feature learning for hyperspectral image classification,”ieee geosci.remote sens.lett.,vol.14,no.11,pp.1928
–
1932,nov.2017.
[0287]
[18]w.hu,y.huang,l.wei,f.zhang,and h.li,“deep convolutional neural networks for hyperspectral image classification,”j.sensors,vol.2015,jul.2015,art.no.258619.
[0288]
[19]y.chen,z.lin,x.zhao,g.wang,and y.gu,“deep learning-based classification of hyperspectral data,”ieee j.sel.topics appl.earth observ.remote sens.,vol.7,no.6,pp.2094
–
2107,jun.2014.
[0289]
[20]k.makantasis,k.karantzalos,a.doulamis,and n.doulamis,“deep supervised learning for hyperspectral data classification through convolutional neural networks,”in proc.ieee int.geosci.remote sens.symp.(igarss),jul.2015,pp.4959
–
4962.
[0290]
[21]w.song,s.li,l.fang,and t.lu,“hyperspectral image classifification with deep feature fusion network,”ieee trans.geosci.remote sens.,vol.56,no.6,pp.3173
–
3184,jun.2018.
[0291]
[22]m.he,b.li,and h.chen,“multi-scale 3d deep convolutional neural network for hyperspectral image classifification,”in proc.ieee int.conf.image process.(icip),sep.2017,pp.3904
–
3908.
[0292]
[23]s.k.roy,g.krishna,s.r.dubey,and b.b.chaudhuri,“hybridsn:exploring 3-d
–
2-d cnn feature hierarchy for hyperspectral image classification,”ieee geosci.remote sens.lett.,vol.17,no.2,pp.277
–
281,feb.2020.
[0293]
[24]c.shi,d.liao,t.zhang and l.wang,"hyperspectral image classification based on expansion convolution network,"in ieee transactions on geoscience and remote sensing,doi:10.1109/tgrs.2022.3174015.
[0294]
[25]w.ma,q.yang,y.wu,w.zhao,and x.zhang,“double-branch multiattention mechanism network for hyperspectral image classification,”remote sens.,vol.11,no.11,p.1307,jun.2019.[online].available:https://www.mdpi.com/2072-4292/11/11/1307.
[0295]
[26]r.li,s.zheng,c.duan,y.yang,and x.wang,“classification of hyperspectral image based on double-branch dual-attention mechanism network,”remote sens.,vol.12,no.3,p.582,feb.2020.[online].available:https://www.mdpi.com/2072-4292/12/3/582
convolutions.in proceedings ofthe ieee conference on computer vision and pattern recognition,pages 1251
–
1258,2017.
[0310]
[41]sara sabour,nicholas frosst,and geoffrey e hinton.dynamic routing between cap-sules.in advances in neural information processing systems,pages 3856
–
3866,2017.
[0311]
[42]christian szegedy,wei liu,yangqing jia,pierre sermanet,scott reed,dragomir anguelov,dumitru erhan,vincent vanhoucke,and andrew rabinovich.going deeper with convolutions.in proceedings ofthe ieee conference on computer vision and pat-tern recognition,pages1
–
9,2015.
[0312]
[43]gao huang,zhuang liu,laurens van der maaten,and kilian qweinberger.denselyconnected convolutional networks.in proceedings ofthe ieee conference on computer vision and pattern recognition,pages 4700
–
4708,2017.
[0313]
[44]andrew g howard,menglong zhu,bo chen,dmitry kalenichenko,weijunwang,tobias weyand,marco andreetto,and hartwig adam.mobilenets:efi-cient convolutional neural networks for mobile vision applications.arxiv preprintarxiv:1704.04861,2017.
[0314]
[45]xiangyu zhang,xinyu zhou,mengxiao lin,and jian sun.shuflenet:an extremely eficient convolutional neural network for mobile devices.in proceedings ofthe ieee conference on computer vision and pattern recognition,pages 6848
–
6856,2018.
[0315]
[46]christian szegedy,wei liu,yangqing jia,pierre sermanet,scott reed,dragomiranguelov,dumitru erhan,vincent vanhoucke,and andrew rabinovich.going deeperwith convolutions.in proceedings ofthe ieee conference on computer vision and pat-tern recognition,pages 1
–
9,2015.
[0316]
[47]mingxing tan and quoc v le.eficientnet:rethinking model scaling for convolu-tional neural networks.arxiv preprint arxiv:1905.11946,2019.
[0317]
[48]krizhevsky a,sutskever i,hinton g e.imagenet classification with deep convolutionalneural networks.curran associates inc.2012:1097-1105.
[0318]
[49]xiang zhang michael mathieu rob fergus yann lecun.overfeat:integrated recognition,localization and detection using convolutional networks.arxiv:1312.6229v4,2014.
[0319]
[50]matthew d.zeiler visualizing and understanding convolutional networks.arxiv:1311.2901v3,2013.[51]c.szegedy,w.liu,y.jia,p.sermanet,s.reed,d.anguelov,d.erhan,v.vanhoucke,and a.rabinovich.going deeper with convolutions.arxiv:1409.4842,2014.
[0320]
[52]jie hu.li,shen.gang sun..squeeze-and-excitation networks.arxiv:1709.01507v1,2017.
[0321]
[53]k.simonyan and a.zisserman.very deep con-volutional networks for large-scale image recognition.arxiv:1409.1556,2014.
[0322]
本发明还可有其它多种实施例,在不背离本发明精神及其实质的情况下,本领域技术人员当可根据本发明作出各种相应的改变和变形,但这些相应的改变和变形都应属于本发明所附的权利要求的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1