主键生成方法及电子设备与流程
1.本技术属于数据库技术领域,具体涉及一种主键生成方法及电子设备。
背景技术:
2.随着企业业务快速发展,数据库中的单表数据量逐渐增大,访问性能变慢了,成为了系统瓶颈;针对于此,通过读写分离、高性能sdd盘、sql优化、参数调优、历史数据归档、数据异构等方式在一定程度上可以起到提高性能的作用,但是随着业务的增长,单机处理能力和数据库b+tree索引算法原理的短板,最终会遇到单机单库单表所能承载的数据量的极限,达到读写性能瓶颈。
3.相关技术中,为了解决由于单表数据量过大而导致数据库读写性能降低的问题,可采用分表处理的方式,即将原来一张表,通过一定的规则,拆分成若干表,使得单一数据表的数据量变小,从而达到提升数据库性能的目的。这种方式下,将原来一张表进行分表后需要指定路由规则,路由规则决定了当前数据写入分表后的哪一张表中,并可通过路由规则直接定位到数据写入了分表后的哪一张表中,以快速进行查询,而不会扫描每一张表,这大大提高了查询效率。这里的路由规则一般由片键(shardingkey)与分片逻辑组成。
4.常用的分片处理逻辑之一是通过时间维度对数据进行分片,例如按月、周、天,甚至是小时维度对表进行分片,这时候会在表中添加一个时间日期类型的创建时间(create_time)字段作为分片的shardinigkey,按照create_time字段进行分片后,那么表的命名则会加上月份分片信息,例如:xxx_202101、xxx_202202、xxx_202203,不同月份生成的数据就会根据路由策略写入到对应表名后缀的表里,在查询数据时,如果查询条件中带有create_time字段,可以根据create_time字段通过分片路由规则,直接定位到数据所在的表分片上,从而避免扫描全部的表分片,当没有create_time字段作为查询条件时,则需要查询每一张表分片,此时查询效率会非常差。
5.但在一些应用场景中,除了根据create_time字段查询某个时间段范围的数据,还会频繁根据数据的主键(数据表中数据记录具有的唯一的id)精确查询某条数据,这时候一般是不清楚这条数据的创建时间的,所以只将主键作为查询条件,就会导致扫描全部的表分片,如果表分片较少,可以保障查询效率,如果表分片很多,会导致查询效率很差,换言之,在时间分库分表的数据库应用场景中,存在以主键进行查询,查询效率低的问题。
6.上述内容仅用于辅助理解本发明的技术方案,并不代表承认上述内容是现有技术。
技术实现要素:
7.为至少在一定程度上克服相关技术中存在的问题,本技术提供一种主键生成方法及电子设备,基于具体的配置,在主键生成时包含时间信息,以解决在时间分库分表的数据库应用场景中,用主键进行查询相关操作,效率低的问题。
8.为实现以上目的,本技术采用如下技术方案:
9.第一方面,
10.本技术提供一种主键生成方法,该生成方法包括:
11.在入库处理时,基于当前系统时间戳信息处理生成第一标识序列;
12.以及基于获取到的待入库数据记录的创建日期信息处理生成第二标识序列;
13.基于所述第一标识序列和所述第二标识序列进行拼接处理,将处理得到的第三标识序列作为所述待入库数据记录的主键。
14.可选地,所述基于当前系统时间戳信息处理生成第一标识序列,包括:
15.获取表征当前系统时间戳信息的数据,并以所述数据对当前时间戳变量进行赋值更新;
16.在判断系统时间未回拨的情况下,进行是否发生毫秒切换的判断,
17.在发生毫秒切换的情况下,重置自增序列号变量,并以当前时间戳变量的值对上次获取时间戳变量进行更新,否则对自增序列号变量进行加一更新,并以当前时间戳变量的值对上次获取时间戳变量进行更新。
18.可选地,所述基于当前系统时间戳信息处理生成第一标识序列,还包括:
19.在以当前时间戳变量的值对上次获取时间戳变量进行更新之后,对当前时间戳变量的值进行压缩处理,得到压缩后的时间戳值;
20.基于所述压缩后的时间戳值和自增序列号变量的值,拼接生成由多位二进制数构成的第一标识序列;
21.其中,所述压缩后的时间戳值占据第一标识序列中的第一数目个位数,所述序列号变量的值占据第一标识序列的第二数目个位数。
22.可选地,所述对当前时间戳变量的值进行压缩处理,具体为:
23.将所述当前时间戳变量的值与表征基准时间节点时间戳信息的值进行求差处理,将得到的差值作为所述压缩后的时间戳值。
24.可选地,所述基于获取的待入库数据记录的创建日期信息处理生成第二标识序列,包括:
25.从系统业务日志中,获取表征待入库数据记录的创建年信息的第一数值、以及获取表征待入库数据记录的创建月信息的第二数值,基于所述第一数值和第二数值,拼接生成由多位二进制数构成的第二标识序列;
26.其中,所述第一数值占据第二标识序列中的第三数目个位数,所述第二数值占据第二标识序列中的4位。
27.可选地,所述主键生成方法应用于服务器集群;
28.所述基于所述第一标识序列和所述第二标识序列进行拼接处理的过程中,还包括将表征实际处理服务器标识信息的数值拼接入所述第三标识序列。
29.可选地,所述第三标识序列为64位的二进制序列,所述第三标识序列的第1位为正负位;
30.所述第一数目为36,所述第二数目为10,所述第三数目为7,所述表征实际处理服务器标识信息的数值为6位二进制数。
31.可选地,在当前时间戳变量的值大于等于上次获取时间戳变量时,判断系统未发生系统回拨情况;
32.所述进行是否发生毫秒切换的判断,具体为:
33.将当前时间戳变量与上次获取时间戳变量进行值比较,在当前时间戳变量的值等于上次获取时间戳变量的值时,判断未发生毫秒切换,在当前时间戳变量的值大于上次获取时间戳变量的值时,判断发生毫秒切换。
34.可选地,还包括:
35.在发生系统时间回拨的情况下,中止生成流程并输出报错信息;
36.以及在自增序列号变量进行加一更新后,进行自增序列号是否溢出判断,
37.在判断未发生溢出时,执行以当前时间戳变量的值对上次获取时间戳变量进行更新的步骤及后续步骤,
38.否则,重复获取表征当前系统时间戳信息的数据并与当前时间戳变量进行比较,直至比较结果表征系统时间至少前进1毫秒,并以此刻获取的表征当前系统时间戳信息的数据对当前时间戳变量进行更新,之后执行以当前时间戳变量的值对上次获取时间戳变量进行更新的步骤及后续步骤。
39.第二方面,
40.本技术提供一种电子设备,包括:
41.存储器,其上存储有可执行程序;
42.处理器,用于执行所述存储器中的所述可执行程序,以实现上述所述方法的步骤。
43.本技术采用以上技术方案,至少具备以下有益效果:
44.本技术的生成主键的技术方案中,在在入库处理时,基于当前系统时间戳信息处理生成第一标识序列;以及基于获取到的待入库数据记录的创建日期信息处理生成第二标识序列;基于第一标识序列和第二标识序列进行拼接处理,将处理得到的第三标识序列作为待入库数据记录的主键。本技术的技术方案中,该种方式生成的主键中包含时间戳信息,并包含数据记录的创建日期信息,该种方式生成的主键既可以保障主键的全局唯一性和全局单调性,又可从主键中提取按日期进行表分片的分片信息,进而在时间分库分表的数据库应用场景中,可实现在根据主键查询时高效精确的定位分片表。
45.本发明的其他优点、目标,和特征在某种程度上将在随后的说明书中进行阐述,并且在某种程度上,基于对下文的考察研究对本领域技术人员而言将是显而易见的,或者可以从本发明的实践中得到教导。
附图说明
46.附图用来提供对本技术的技术方案或现有技术的进一步理解,并且构成说明书的一部分。其中,表达本技术实施例的附图与本技术的实施例一起用于解释本技术的技术方案,但并不构成对本技术技术方案的限制。
47.图1为本技术一个实施例中主键生成方法的流程示意图;
48.图2为本技术一个实施例中处理生成第一标识序列的流程示意图;
49.图3为本技术一个实施例中处理生成第一标识序列的流程示意图;
50.图4为本技术一个实施例中生成主键的结构示意说明图;
51.图5为本技术一个实施例中主键生成方法的流程举例说明示意图;
52.图6为本技术一个实施例提供的电子设备的结构示意图。
具体实施方式
53.为使本技术的目的、技术方案和优点更加清楚,下面将对本技术的技术方案进行详细的描述。显然,所描述的实施例仅仅是本技术一部分实施例,而不是全部的实施例。基于本技术中的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所得到的所有其它实施方式,都属于本技术所保护的范围。
54.如背景技术中所述,常用的分片处理逻辑之一是通过时间维度对数据进行分片,例如按月、周、天,甚至是小时维度对表进行分片,这时候会在表中添加一个时间日期类型的创建时间(create_time)字段作为分片的shardinigkey,按照create_time字段进行分片后,那么表的命名则会加上月份分片信息,例如:xxx_202101、xxx_202202、xxx_202203,不同月份生成的数据就会根据路由策略写入到对应表名后缀的表里,在查询数据时,如果查询条件中带有create_time字段,可以根据create_time字段通过分片路由规则,直接定位到数据所在的表分片上,从而避免扫描全部的表分片,当没有create_time字段作为查询条件时,则需要查询每一张表分片,此时查询效率会非常差。
55.但在一些应用场景中,除了根据create_time字段查询某个时间段范围的数据,还会频繁根据数据的主键(数据表中数据记录具有的唯一的id)精确查询某条数据,这时候一般是不清楚这条数据的创建时间,所以只将主键作为查询条件,就会导致扫描全部的表分片,如果表分片较少,可以保障查询效率,如果表分片很多,会导致查询效率很差,换言之,在时间分库分表的数据库应用场景中,存在以主键进行查询,查询效率低的问题。
56.为帮助理解本技术中提出技术问题,下面对此进行一下举例说明:
57.例如,有一张订单表,表名为order,表结构主要字段如下表1所示:
58.表1
[0059][0060]
order表每个月都会生成两千万订单,为了防止order表的单表数据量过多,所以对order表按月份维度进行分表,sharding-key使用“下单时间”字段,当前时间为2022年7月,则生成的表分片的表名如下表2所示:
[0061]
表2
[0062]
表分片说明表创建时间order_202205历史月份5月表分片4月创建order_202206历史月份6月表分片5月创建order_202207当前月份7月表分片6月创建order_202208下个月份8月表分片7月创建
[0063]
针对order表的查询操作,有这样的业务场景“查询出7月7号申请退货的订单列表,审核后进行退货操作”。
[0064]
查询7月7号申请退货的订单列表的原始sql如下:
[0065]
select“订单id”,“订单状态”,“下单时间”from order
[0066]
where
[0067]“下单时间”》=“2022-07-07 00:00:00”[0068]
and“下单时间”《=“2022-07-07 23:59:59”[0069]
and“订单状态”=“申请退货”[0070]
而根据sql查询条件中的“下单时间”字段给出的时间范围即可定位到分片为order_202207的表,通过查询这一张表就可以取出7月7号申请退货的订单列表,此时查询sql会被改写为:
[0071]
select“订单id”,“订单状态”,“下单时间”from order_202207
[0072]
where
[0073]“下单时间”》=“2022-07-07 00:00:00”[0074]
and“下单时间”《=“2022-07-07 23:59:59”[0075]
and“订单状态”=“申请退货”[0076]
然后我们再根据查询出来的列表中订单的主键字段“order_id”去查询某个订单的详情,一般有两种实现方案,具体如下:
[0077]
方案1,按照正常的业务处理逻辑,编写的原始查询sql如下:
[0078]
select*from order
[0079]
where
[0080]“订单id”==“xxxxxxxxxxxxxxx”[0081]
仅通过“订单id”字段,无法判断这条记录在哪张表分片上,只能通过扫描order_202205、order_202206、order_202207、order_202208全部的表分片,才能找到这条记录,此时的查询sql会被分表组件改写为以下5条sql:
[0082]
select*from order_202205
[0083]
where
[0084]“订单id”==“xxxxxxxxxxxxxxx”[0085]
select*from order_202206
[0086]
where
[0087]“订单id”==“xxxxxxxxxxxxxxx”;
[0088]
select*from order_202207
[0089]
where
[0090]“订单id”==“xxxxxxxxxxxxxxx”;
[0091]
select*from order_202208
[0092]
where
[0093]“订单id”==“xxxxxxxxxxxxxxx”;
[0094]
最后将这五条sql查询返回的结果进行合并。如果分片表比较多,查询sql也会变多,导致查询效率低下。
[0095]
方案2,为了精确定位表分片,添加上“下单时间”字段查询条件,原始查询sql如下:
[0096]
select*from order
[0097]
where
[0098]“订单id”==“xxxxxxxxxxxxxxx”[0099]
and“下单时间”》=“2022-07-07 00:00:00”[0100]
and“下单时间”《=“2022-07-07 23:59:59”[0101]
此时通过“下单时间”字段,精准定位到表分片order_202207,然后再通过“订单id”找到这条记录,此时查询sql会被表分片组件改写为:
[0102]
select*from order_202207
[0103]
where
[0104]“订单id”==“xxxxxxxxxxxxxxx”[0105]
and“下单时间”》=“2022-07-07 00:00:00”[0106]
and“下单时间”《=“2022-07-07 23:59:59”[0107]
方案1、2相比,方案1查询效率低,但只需要传递主键;方案2查询效率高,但是除了传递主键,开发中还需要专门针对分表的场景传递“下单时间”字段,而如果不是针对分表进行特殊处理,正常情况下只需要通过主键查询,而不需要传递“下单时间字段”。
[0108]
为了让业务人员只关心业务,不用关心分表之后的sql写法,本技术提出一种技术方案,针对主键的生成算法做了特别处置,让主键中包含日期信息,从而不需要传递“时间”字段,使表分片组件也能够从主键中获取到年月分片信息,精准定位到表分片,提高查询效率。
[0109]
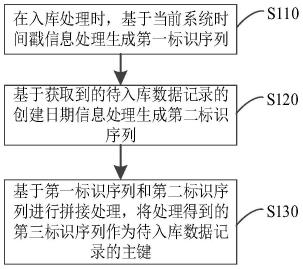
在一实施例中,如图1所示,本技术提出的主键生成方法包括如下步骤:
[0110]
步骤s110,在入库处理时,基于当前系统时间戳信息处理生成第一标识序列;
[0111]
容易理解的是,主键需保证全局唯一性和全局单调性(为保证b+tree索引算法性能),本技术基于此考虑,基于入库处理时的当前系统时间戳信息处理生成第一标识序列,以作为后续主键生成的依据之一。
[0112]
步骤s120,基于获取到的待入库数据记录的创建日期信息处理生成第二标识序列;
[0113]
该步骤中,是将数据记录的创建日期信息引入,并处理生成第二标识序列,作为后续主键生成的依据之一。
[0114]
最后,进行步骤s130,基于得到的第一标识序列和第二标识序列进行拼接处理,将处理得到的第三标识序列作为待入库数据记录的主键。
[0115]
本技术的技术方案中,采用具体的处理方式所生成的主键,其包含时间戳信息,并包含数据记录的创建日期信息,该种方式生成的主键既可以保障主键id的全局唯一性和全局单调性,又可从主键中提取按日期进行表分片的分片信息,进而在时间分库分表的数据库应用场景中,可实现在根据主键查询时高效精确的定位分片表。
[0116]
为便于理解本技术的技术方案,下面以另一实施例对本技术的技术方案进行介绍说明。
[0117]
在该实施例中,与前文的实施例类似,本技术提出的主键生成方法,同样包括:
[0118]
在入库处理时,基于当前系统时间戳信息处理生成第一标识序列;
[0119]
具体的,该实施例中,如图2所示,基于当前系统时间戳信息处理生成第一标识序
列,包括:
[0120]
步骤1,获取表征当前系统时间戳信息的数据,并以该数据对当前时间戳变量(例如,当前时间戳变量用curtimestamp表示)进行赋值更新,算法实现中的语句为curtimestamp=system.currenttimemillis();
[0121]
之后进行步骤2,进行是否发生系统时间回拨的判断,在判断系统时间未回拨的情况下,进一步进行步骤3,进行是否发生毫秒切换的判断,
[0122]
在发生毫秒切换的情况下,进行步骤4,重置自增序列号变量(举例而言,这里的自增序列号变量用sequence表示),步骤4的算法实现中的语句为sequence=0,之后再以当前时间戳变量的值对上次获取时间戳变量进行更新(对应于图2中步骤6,上次获取时间戳变量用lasttimestamp表示),步骤6对应的算法实现为lasttimestamp=curtimestamp,
[0123]
否则进行步骤5(即未发生毫秒切换分支),对自增序列号变量进行加一更新,步骤5对应的算法实现为sequence=sequence+1,之后同样进行步骤6,以当前时间戳变量的值对上次获取时间戳变量进行更新;
[0124]
容易理解的是,这里的自增序列号是为了实现对时间最小粒度(该实施例中为1毫秒)的进一步区分细化,即同一毫秒中可进一步区分多个数据记录(具体个数上限与自增序列号变量的溢出值相关)。
[0125]
该实施例中,如图2所示,基于当前系统时间戳信息处理生成第一标识序列,还包括:
[0126]
在以当前时间戳变量的值对上次获取时间戳变量进行更新之后(即步骤6之后),进行步骤7,对当前时间戳变量的值进行压缩处理,得到压缩后的时间戳值;
[0127]
本领域技术人员容易理解的是,一般而言,时间戳是指格林威治时间1970年01月01日00时00分00秒起至当下的总(毫)秒数,本技术中为了保证生成主键的整体数据长度满足数据类型要求(如64位的长整型),这里对当前时间戳变量的值(毫秒的计数值)进行压缩处理,具体的,该实施例中,压缩处理的方式为:
[0128]
将当前时间戳变量的值与表征基准时间节点时间戳信息的值进行求差处理,将得到的差值作为压缩后的时间戳值;
[0129]
例如,基准时间节点为2022年1月1号零点(容易理解的是,这个节点可以根据系统初始运行时的年份进行调整),其对应的时间戳为1640966400000,压缩后的时间戳值用compresstimestamp表示,而算法执行中curtimestamp=1658221716329(对应于2022-07-19 17:08:36时刻),则,
[0130]
compresstimestamp=1658221716329-1640966400000=17255316329,该值相比原始的时间戳值大大减少,可利用较少的数据长度来表示。
[0131]
继续回到图2,步骤7之后进行步骤8,基于压缩后的时间戳值和自增序列号变量的值,拼接生成由多位二进制数构成的第一标识序列;
[0132]
这里的压缩后的时间戳值占据第一标识序列中的第一数目个位数(如36位),序列号变量的值占据第一标识序列的第二数目个位数(如10位)。
[0133]
这里再对该实施例中,步骤2中的系统回拨判断,以及步骤3中的毫秒切换判断进行一下介绍说明:
[0134]
在本技术中,系统回拨指的是系统时钟发生了被回调的情况,由于本技术方案中
生成的主键的单一性与时间戳相关,在系统回拨的情况,单一性将无法保证,因此需要进行是否进行系统回拨的判断,具体的,该实施例中判断方式为:
[0135]
将当前时间戳变量与上次获取时间戳变量进行比较,在当前时间戳变量的值大于等于上次获取时间戳变量时,判断系统未发生系统回拨情况,否则,判断发生系统时间回拨,执行图2中步骤a分支,中止生成流程并输出报错信息。
[0136]
而结合前文中对自增序列号的相关介绍,容易理解的是,本技术中毫秒切换的判断正是实现该种进一步细分机制的前提,该实施例中,进行是否发生毫秒切换的判断,具体为:
[0137]
将当前时间戳变量与上次获取时间戳变量进行值比较,在当前时间戳变量的值等于上次获取时间戳变量的值时,判断未发生毫秒切换,在当前时间戳变量的值大于上次获取时间戳变量的值时,判断发生毫秒切换。
[0138]
进一步地,为保证生成方法的完备性,还需考虑自增序列号变量的溢出问题,举例而言,如图3所示,在自增序列号变量进行加一更新后,即步骤5之后,进行溢出判断及相关步骤(对应于图3中步骤b),步骤b中包括,
[0139]
进行自增序列号是否溢出判断,举例而言,自增序列号在第一序列中配置为10位二进制数,则其值最大为1024,这里将自增序列号变量与1024进行比较,当小于1024时,判断未溢出,否则判断发生溢出;
[0140]
而在判断未发生溢出时,执行以当前时间戳变量的值对上次获取时间戳变量进行更新的步骤及后续步骤(即步骤6及后续步骤),
[0141]
否则,重复获取表征当前系统时间戳信息的数据并与当前时间戳变量进行比较,直至比较结果表征系统时间至少前进1毫秒,并以此刻获取的表征当前系统时间戳信息的数据对当前时间戳变量进行更新,之后执行以当前时间戳变量的值对上次获取时间戳变量进行更新的步骤及后续步骤(步骤6及后续步骤)。
[0142]
此外,需要说明的,为提高处理效率并保证主键的唯一性,处理生成第一标识序列的过程中,以当前时间戳变量的值对上次获取时间戳变量进行更新的步骤及之前的步骤,采用多线程加锁方式处理进行。
[0143]
同样的,该实施例中,还包括基于获取的待入库数据记录的创建日期信息处理生成第二标识序列的步骤,具体的,该步骤中包括:
[0144]
从系统业务日志中,获取表征待入库数据记录的创建年信息的第一数值、以及获取表征待入库数据记录的创建月信息的第二数值,基于第一数值和第二数值,拼接生成由多位二进制数构成的第二标识序列;
[0145]
其中,第一数值占据第二标识序列中的第三数目个位数(例如占据7位),第二数值占据第二标识序列中的4位,即可表示1月至12月。
[0146]
该实施例中,最后基于得到的第一标识序列和第二标识序列进行拼接处理,将处理得到的第三标识序列作为待入库数据记录的主键。
[0147]
进一步的,在一具体的实施场景中,主键生成方法应用于服务器集群;相应的,在基于第一标识序列和第二标识序列进行拼接处理的过程中,还包括将表征实际处理服务器标识信息(如服务器实例id)的数值拼接入第三标识序列,以保证生成的主键的全局唯一性。
[0148]
具体的,该场景中,如图4所示,最终生成主键的第三标识序列为为64位的二进制序列,其中,第三标识序列的第1位为正负位,该位固定为0表示为正;
[0149]
第三数目为7,即创建年信息的数值占据7位,可表示128年,如在第三序列中的第2~8位,假设基准时间节点为2022年,则系统可以一直生成分布式id到2022+127=2149年;
[0150]
基于前文所述,创建月信息的数值占据4位,可标识12个月,如在第三序列中的第9~12位;
[0151]
第一数目为36,即压缩后的时间戳值占据36位,如在第三序列中的第13~48位,36位时间戳能支持68,719,476,736毫秒,2年内不溢出;
[0152]
表征实际处理服务器标识信息的数值为6位二进制数,即占据6位,如在第三序列中的第49~54位,其取值为0~63,能标识64台服务器;
[0153]
第二数目为10,即序列号变量的值占据10位,如在第三序列中的第55~64位,也即其能标识1024个id,或者说一毫秒内可生成1024个id;
[0154]
这种具体应用场景下,生成方法支持64台的服务器集群,可以使用128年,单机每毫秒生成1024个id,且保证每台服务器生成id不重复。
[0155]
且实际实现中,可以通过定时任务计算当年1月1号0点的时间戳,放入本地缓存来作为表征基准时间节点时间戳信息的值,每隔一定时间(如1分钟)更新一次,这样在系统运行中就不用担心跨年时由于获取不及时,而造成的运行异常的问题了。
[0156]
本技术中以上述方式生成如此结构形式的主键(或者说分布式id),该分布式id采用数据类型为64位的长整型,该id分成多段,加入表的分片年月时间信息、精简时间戳、服务器实例id、自增序列,保证生成单调递增不重复的长整型序列号;这样生成的主键id,既可以保障主键id的全局唯一性和全局单调性,又可提取按年月进行表分片的分片信息,在根据主键id查询时可精确定位分片表。
[0157]
图5所示为本技术一个实施例中主键生成方法的流程举例说明示意图,图5中所示方法流程已在前文的实施例中进行了相关说明,这里就不再详述了,图5中需说明的是开始后的环节为算法运行的一些基本参数的初始化或模拟设置,如将lasttimestamp设置为-1等,date模拟设置为2022-7-19 16:35:27等。
[0158]
图6为本技术一个实施例提供的电子设备的结构示意图,如图6所示,该电子设备400包括:
[0159]
存储器401,其上存储有可执行程序;
[0160]
处理器402,用于执行存储器401中的可执行程序,以实现上述方法的步骤。
[0161]
关于上述实施例中的电子设备400,其处理器402执行存储器401中的程序的具体方式已经在有关该方法的实施例中进行了详细描述,此处将不做详细阐述说明。
[0162]
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉该技术的人员在本发明所揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应该以权利要求的保护范围为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1