基于深度学习的蛋鸡舍噪声应激源识别分类方法
1.本发明属于深度学习鸡舍周围声音识别技术领域,尤其涉及基于深度学习的蛋鸡舍噪声应激源识别分类方法。
背景技术:
2.近年来,我国畜牧业得到迅速发展,占农业经济的比重越来越大,其现代化、集约化程度愈来愈高,其中蛋鸡产业在畜牧生产中占有很大的比例。2021年,中国蛋鸡存栏量约18亿只,在产蛋鸡存栏量约为13亿只,是保证全国鸡蛋供给和农民就业的基础。由于蛋鸡天性敏感,在其饲养过程中,易受噪声影响而诱发应激反应,致使产蛋性能下降,免疫力降低,易患多种疾病甚至诱发死亡。药物防治是抗应激的常用手段,但也会带来鸡蛋中药物残留和耐药细菌产生的问题。随着全球畜禽养殖向福利化、无抗化养殖的转型升级,蛋鸡生产也承受着提高蛋鸡鸡体健康和福利,减少药物使用的压力。在此背景下,如何做到有效防控蛋鸡应激,以减少或避免药物的使用,保障鸡蛋产品的安全,已成为当前蛋鸡产业面临的一个重要问题。
3.目前声音的识别与分类主要采用bp神经网络和svm(支持向量机)模型进行操作。对于bp神经网络来说,处理大数据量声音文件的能力较弱,并且提取的特征不够精确;对于svm(支持向量机)来说,此算法需要手工提取特征,然后将提取的特征放入算法中进行分类,对声音的分类结果容易受主观因素影响。因此,设计一种自动化、精确的蛋鸡舍噪声应激源辨识方法,可为噪声应激源实时预警奠定基础,对我国蛋鸡的安全高效养殖以及噪声应激源的物理手段防治具有十分重要的意义。
技术实现要素:
4.本发明的目的在于提出基于深度学习的蛋鸡舍噪声应激源识别分类方法,利用深度学习方法,通过resnet34网络模型对鸡舍周围环境声音的训练,自动学习各种声音的特征,然后实现对声音的识别与分类。
5.为实现上述目的,本发明提供了基于深度学习的蛋鸡舍噪声应激源识别分类方法,包括以下步骤:
6.获取蛋鸡舍周围噪声的声音文件,对所述声音文件进行预处理,获得待识别声音文件,对所述待识别声音文件进行短时傅里叶变换获得声谱图;
7.基于所述声谱图,对所述预处理后的声音文件进行降噪处理,获得降噪后的数据集并划分为训练集和测试集;
8.构建resnet34网络模型,基于所述训练集对所述resnet34网络模型进行训练,采用所述测试集对所述resnet34网络模型进行测试,获得蛋鸡舍噪声应激源识别模型,利用所述蛋鸡舍噪声应激源识别模型进行蛋鸡舍周围噪声应激源识别分类。
9.可选的,对所述声音文件进行预处理,具体包括:
10.将所述声音文件的文件时长裁剪为1s-3s,频率转变为44.1khz。
11.可选的,对所述待识别声音文件进行短时傅里叶变换获得声谱图具体包括:
12.所述预处理后的声音文件为一维时域信号,通过所述短时傅立叶将所述一维时域信号转换为二维频域信号,获得声谱图。
13.可选的,基于所述声谱图,对所述预处理后的声音文件进行降噪处理具体包括:
14.基于所述声谱图提取声音频谱信息,对所述声音频谱信息取绝对值或平方值,通过mel滤波将所述声音频谱信息转换为mel域,通过取对数对所述声音频谱信息增强低频,最后通过dct变换获得预处理后的声音文件的梅尔频谱倒谱系数,完成降噪。
15.可选的,将所述数据集按照8:2的比例划分为训练集和测试集。
16.可选的,所述resnet34网络模型具体包括:
17.先对输入的数据进行卷积核大小为7x7的卷积操作,初步获取输入数据的特征;然后进行池化核大小为3x3最大池化操作,用于扩大感受野、降维去除冗余信息;再通过4组不同卷积核的大小和卷积核个数的残差结构,每组残差结构分别重复3、4、6、3次,用于获取输入数据的更深层特征;在经过残差结构后,进行一次平均池化操作进行下采样;最后通过全连接层组合卷积操作提取的不同特征并进行分类。
18.可选的,所述残差结构包括卷积网络结构和直连操作。
19.可选的,基于所述训练集对所述resnet34网络模型进行训练,采用所述测试集对所述resnet34网络模型进行测试,完成蛋鸡舍周围噪声应激源识别分类,具体方法包括:
20.利用所述resnet34网络模型对所述训练集进行训练,学习声音特征;获得蛋鸡舍噪声应激源识别模型,将待识别分类的蛋鸡舍周围噪声文件输入所述resnet34网络模型中进行测试,实现蛋鸡舍周围噪声应激源识别分类。
21.本发明技术效果:本发明公开了基于深度学习的蛋鸡舍噪声应激源识别分类方法,只需输入声音文件,网络模型自动提取声音特征,首先,通过短时傅里叶变换,将一维时域信号转换为二维频域信号,并得到声谱图;然后通过提取声音的梅尔频谱倒谱系数,会将一些干扰声音去除,最终保留的特征几乎都是有效特征;最后通过深度学习中的resnet34网络模型中进行训练,实现鸡舍周围声音的分类。最终分类的准确率均能够达到80%以上,其中对警报声、电锯声、着火声、狗叫声、烟花声、直升机声、雷声和风声8种声音的分类准确率均在90%以上。对于bp神经网络来说,处理大数据量声音文件的能力较弱,并且提取的特征不够精确;对于svm(支持向量机)来说,这个算法需要手工提取特征,然后将提取的特征放入算法中进行分类,对声音的分类结果容易受主观影响,容易产生误识别现象。本发明具有普适性,能够对鸡舍周围环境的大量声音进行识别分类,并且整个过程只需手动输入声音文件,网络模型能够自动实现对声音特征的学习,通过对鸡舍周围声音的识别分类,达到对鸡的应激声音的判断,无需人工干预。
附图说明
22.构成本技术的一部分的附图用来提供对本技术的进一步理解,本技术的示意性实施例及其说明用于解释本技术,并不构成对本技术的不当限定。在附图中:
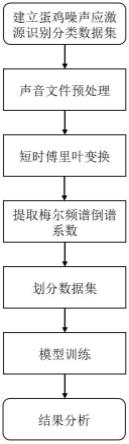
23.图1为本发明实施例基于深度学习的蛋鸡舍噪声应激源识别分类方法的流程示意图;
24.图2为本发明实施例提取声音文件的梅尔频谱倒谱系数流程图;
25.图3为本发明实施例采用的数据集各类别数量统计图;
26.图4为本发明实施例采用的数据集每类样本的功率谱图;
27.图5为本发明实施例采用的数据集每类样本的波形图;
28.图6为本发明实施例残差结构示意图;
29.图7为本发明实施例采用的模型结构图;
30.图8为本发明实施例各类别声音识别分类精度图。
具体实施方式
31.需要说明的是,在不冲突的情况下,本技术中的实施例及实施例中的特征可以相互组合。下面将参考附图并结合实施例来详细说明本技术。
32.需要说明的是,在附图的流程图示出的步骤可以在诸如一组计算机可执行指令的计算机系统中执行,并且,虽然在流程图中示出了逻辑顺序,但是在某些情况下,可以以不同于此处的顺序执行所示出或描述的步骤。
33.如图1-8所示,本实施例中提供基于深度学习的蛋鸡舍噪声应激源识别分类方法,包括以下步骤:
34.获取蛋鸡舍周围噪声的声音文件,对所述声音文件进行预处理,获得待识别声音文件,对所述待识别声音文件进行短时傅里叶变换获得声谱图;
35.基于所述声谱图,对所述预处理后的声音文件进行降噪处理,获得降噪后的数据集并划分为训练集和测试集;
36.构建resnet34网络模型,基于所述训练集对所述resnet34网络模型进行训练,采用所述测试集对所述resnet34网络模型进行测试,获得蛋鸡舍噪声应激源识别模型,利用所述蛋鸡舍噪声应激源识别模型进行蛋鸡舍周围噪声应激源识别分类。
37.进一步优化方案,对所述声音文件进行预处理,具体包括:
38.将所述声音文件的文件时长裁剪为1s-3s,频率转变为44.1khz。
39.进一步优化方案,对所述待识别声音文件进行短时傅里叶变换获得声谱图具体包括:
40.所述预处理后的声音文件为一维时域信号,通过所述短时傅立叶将所述一维时域信号转换为二维频域信号,获得声谱图。
41.进一步优化方案,基于所述声谱图,对所述预处理后的声音文件进行降噪处理具体包括:
42.基于所述声谱图提取声音频谱信息,对所述声音频谱信息取绝对值或平方值,通过mel滤波将所述声音频谱信息转换为mel域,通过取对数对所述声音频谱信息增强低频,最后通过dct变换获得预处理后的声音文件的梅尔频谱倒谱系数,完成降噪。
43.进一步优化方案,将所述数据集按照8:2的比例划分为训练集和测试集。
44.进一步优化方案,所述resnet34网络模型具体包括:
45.先对输入的数据进行卷积核大小为7x7的卷积操作,初步获取输入数据的特征;然后进行池化核大小为3x3最大池化操作,用于扩大感受野、降维去除冗余信息;再通过4组不同卷积核的大小和卷积核个数的残差结构,每组残差结构分别重复3、4、6、3次,用于获取输入数据的更深层特征;在经过残差结构后,进行一次平均池化操作进行下采样;最后通过全
连接层组合卷积操作提取的不同特征并进行分类。
46.进一步优化方案,所述残差结构包括卷积网络结构和直连操作。
47.进一步优化方案,基于所述训练集对所述resnet34网络模型进行训练,采用所述测试集对所述resnet34网络模型进行测试,完成蛋鸡舍周围噪声应激源识别分类,具体方法包括:
48.利用所述resnet34网络模型对所述训练集进行训练,学习声音特征;获得蛋鸡舍噪声应激源识别模型,将待识别分类的蛋鸡舍周围噪声文件输入所述resnet34网络模型中进行测试,实现蛋鸡舍周围噪声应激源识别分类。
49.本发明的技术方案主要包括如下步骤:
50.步骤1.收集噪声文件,建立蛋鸡舍噪声应激源识别分类数据集;其中部分数据来自公共数据集esc-50(该数据集有2000个样本数,50个类别)选取其中与蛋鸡舍声音应激有关的环境声,同时对数据集进行了补充,最终形成了包含雷声、风声、下雨声、直升机声等共12类声音,共计1605个声音样本;
51.步骤2.对数据集进行预处理操作。将数据集中的文件时长裁剪为1s-3s,频率转变为44.1khz;
52.步骤3.对声音文件进行短时傅里叶变换(stft)。将一维时域信号转换为二维频域信号,并得到声谱图:
53.3.1将一个声音文件进行分帧操作,然后截取窗长度的信号,并和窗函数相乘;
54.3.2对每一帧做傅里叶变换(fft);
55.3.3滑窗得到每个时刻的stft,把结果沿另一个维度堆叠起来,得到二维的声谱图。
56.步骤4.提取声音文件的梅尔频谱倒谱系数(mfcc):
57.4.1输入一个声音文件,首先通过fft变换,提取声音频谱信息,即将声音的时域序列转换到频域表示;
58.4.2然后取绝对值或平方值。如果取绝对值得到的是幅度谱,取平方值得到的是功率谱,通常取平方值;
59.4.3进行mel滤波,将声音转换到mel域表示,使其更加符合人耳听觉特性,这步是对频率轴进行操作,和时间轴无关;
60.4.4取对数,增强声音的低频表示。因为声音的很多特性是隐藏在低频信息中的,同时在做dct变换的时候可以把频谱的包络和细节区分开;
61.4.5dct变换。实际上是做了fourier的逆变换,通过离散余弦变换来实现,dct变换后会得到一些系数向量,称之为倒谱系数;
62.4.6为了得到更加丰富的信息,沿时间轴做一阶偏微分,得到delta信息,做两次偏微分就得到delta-delta信息。
63.步骤5.将数据集按照8:2的比例划分为训练集和测试集;
64.步骤6.使用resnet34网络模型对声音数据集中的训练集进行训练,该模型首先通过一个7x7卷积核大小的卷积层(conv)和一个3x3卷积核大小的池化层(pool),再通过一系列的残差结构(residual block),最后通过一个平均池化下采样操作和一个全连接层输出。其中残差结构(residual block)共包括两部分:第一部分分别卷积核大小为1x1,3x3,
1x1卷积操作;第二部分是直连操作,将输入部分直接连接到第一部分的第三次卷积操作后。如果输入和输出的通道不一致,或其步长不为1,就需要有一个专门的单元将二者转成一致,使其可以相加。
65.步骤7.利用训练后生成的蛋鸡舍噪声应激源识别模型,输入测试集所需测试的声音文件,实现对蛋鸡舍噪声应激源的识别与分类。
66.通过上述步骤,实现蛋鸡舍噪声应激源的识别与分类,然后可利用测试集进行测试。
67.本发明首先收集鸡舍周围环境的声音文件,然后将声音文件时长裁剪成1s-3s,频率转变为44.1khz;然后将文件送入深度学习的resnet34模型中,自动将声音文件通过短时傅里叶变换将一维时域信号转换为二维频域信号,然后提取出每类声音的特征,并通过梅尔倒谱系数处理,排除一些干扰声,然后通过模型对每类声音特征的学习,实现鸡舍周围环境声音的识别与分类。
68.虽然目前分类模型被应用于声音的分类中,但应用在鸡舍周围环境下进行蛋鸡舍噪声应激源的识别与分类的研究较少,通过此方法,对蛋鸡舍噪声应激源的准确率均能够达到80%以上,其中对警报声、电锯声、着火声、狗叫声、烟花声、直升机声、雷声和风声8种声音的分类准确率均在90%以上,很好的解决了bp神经网络处理大数据量声音文件的能力较弱,提取的特征不够精确和svm(支持向量机)模型需要手工提取特征,不能实现自动化、对声音的识别与分类的准确率易受主观因素影响的问题。本发明能够自动实现蛋鸡舍噪声应激源的识别与分类,并且适用于鸡舍周围环境中大量数据的识别,具有一定的鲁棒性。
69.图1为本发明所采用的流程图。首先收集声音,建立数据集;然后将数据集中的文件时长裁剪为1s-3s,频率转变为44.1khz;其次经过短时傅里叶变换转换为二维频域信号;然后提取声音的梅尔频谱倒谱系数;最后将整个数据集划分为训练集和验证集,利用网络模型对训练集进行训练,利用测试集进行测试和结果分析。
70.图2为提取声音文件的梅尔频谱倒谱系数流程图。首先将输入的声音文件进行fft变换,提取声音频谱信息;然后取绝对值或平方值,并通过mel滤波,将声音转换到mel域表示;通过取对数操作,增强声音的低频表示;最后通过dct变换,得到倒谱系数;再通过偏微分操作,得到更丰富的信息。
71.图3为本发明采用的数据集各类别数量统计图。共包括警报声、电锯声、钟声、着火声、狗叫声、烟花声、直升机声、雨声、鸡叫声、打喷嚏声、雷声、风声12类声音。
72.图4为本发明采用的数据集每类样本的功率谱图。从图中可以发现,打喷嚏声和雷声的功率谱较为相似。
73.图5为本发明采用的数据集每类样本的波形图。从图中可以发现,在某些片段下,直升机声、雨声和雷声的波形较为相似。
74.图6为残差结构图。图中左边部分是普通的卷积网络结构,右边是直接相连接,如果输入和输出的通道不一致,或其步长不为1,就需要有一个专门的单元将二者转成一致,使其可以相加。
75.图7为本发明采用的模型结构图。整个模型首先通过一个7x7卷积核大小的卷积层(conv),然后通过一个池化层(pool),再通过一系列的残差结构(residualblock),最后通过一个平均池化下采样操作和一个全连接层输出。
76.图8为本发明最终各类别声音识别分类精度图。对钟声的识别效果最差,准确率为81.54%;对风声的识别效果最好,准确率为99.36%;除了对钟声、雨声、鸡叫声和打喷嚏声的识别准确率在80%-90%之间,其余8种声音的识别准确率均在90%以上。
77.本发明公开了基于深度学习的蛋鸡舍噪声应激源识别分类方法,只需输入声音文件,网络模型自动提取声音特征,首先,通过短时傅里叶变换,将一维时域信号转换为二维频域信号,并得到声谱图;然后通过提取声音的梅尔频谱倒谱系数,会将一些干扰声音去除,最终保留的特征几乎都是有效特征;最后通过深度学习中的resnet34网络模型中进行训练,实现鸡舍周围声音的分类。最终分类的准确率均能够达到80%以上,其中对警报声、电锯声、着火声、狗叫声、烟花声、直升机声、雷声和风声8种声音的分类准确率均在90%以上。对于bp神经网络来说,处理大数据量声音文件的能力较弱,并且提取的特征不够精确;对于svm(支持向量机)来说,这个算法需要手工提取特征,然后将提取的特征放入算法中进行分类,对声音的分类结果容易受主观影响,容易产生误识别现象。本发明具有普适性,能够对鸡舍周围环境的大量声音进行识别分类,并且整个过程只需手动输入声音文件,网络模型能够自动实现对声音特征的学习,通过对鸡舍周围声音的识别分类,达到对鸡的应激声音的判断,无需人工干预。
78.以上所述,仅为本技术较佳的具体实施方式,但本技术的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本技术揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本技术的保护范围之内。因此,本技术的保护范围应该以权利要求的保护范围为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1