支持隐私保护的外包深度学习系统
1.本发明涉及的是一种信息安全领域的技术,具体是一种支持隐私保护的外包深度学习系统。
背景技术:
2.目前基于可信执行环境保护深度学习模型数据隐私的解决方案一般分为两种。一种是将模型完整地移植输入可信执行环境(如intel sgx的enclave),它的优势在于保证了计算机密性的同时并没有牺牲模型准确度,但通常情况下可信环境可开辟的内存有限,频繁换页导致该方案的计算性能较低。另一种方式是模型的部分移植,但目前已有的工作对于复杂模型涉及到几十次甚至上百次sgx enclave内外的接口交互,同样也产生了大量的性能损耗。
技术实现要素:
3.本发明针对现有技术计算时间长、不支持除法运算、导致密文噪音量的增加的不足以及存在的隐私泄漏和数据滥用的问题,提出一种支持隐私保护的外包深度学习系统,在可信执行环境内部实现数据隐私保护,在保证完整性和机密性的情况下外包至云端服务器进行高效的深度学习模型训练,使得用户能够将本地数据在可行执行环境中进行混淆扰乱,将脱敏后的数据进行共享,原始数据和混淆的过程对攻击者不可见。
4.本发明是通过以下技术方案实现的:
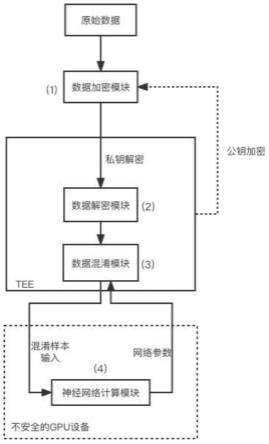
5.本发明涉及一种支持隐私保护的外包深度学习系统,包括:数据加密模块、位于可信执行环境中的数据解密模块和数据混淆模块以及位于不可信gpu设备中的神经网络计算模块,其中:数据加密模块和数据解密模块分别根据生成的公私钥对中的公钥和私钥进行数据加密和解密,数据混淆模块对来自数据解密模块的解密信息进行脱敏处理后输出脱敏数据至神经网络计算模块,神经网络计算模块根据脱敏数据进行神经网络模型的训练和测试,在神经网络反向传播的过程中得到混淆梯度参数并回传至数据混淆模块进行同步更新,提高整个训练系统的收敛速度和精度。
6.所述的脱敏处理是指:在可信执行环境中的数据混淆模块构建并初始化随机稀疏矩阵,数据脱敏的过程即为对原始数据作线性变换,对于原始数据xi,混淆输出其中:矩阵w即为随机生成的稀疏矩阵。随机稀疏矩阵初始化时,还需保证每行与每列至少有一个元素不为零,即原始数据的每一个元素都能够至少得到一次线性映射。技术效果
7.本发明通过在可信执行环境中部署基于随机稀疏矩阵的数据混淆模块,对原始数据进行脱敏处理达到信息隐藏的目的;同时通过基于可信执行环境+位于不可信gpu设备中神经网络训练框架,根据神经网络的梯度信息对可信执行环境中的数据混淆模块进行同步更新。相比现有技术,本发明能够在牺牲可控精度的基础上达到5%以内的精度损耗的同
时,在每次神经网络迭代过程中将可信执行环境内外的数据交互次数控制在2次,提高了训练效率。
附图说明
8.图1为本发明系统示意图;
9.图2为实施例数据脱敏处理示意图;
10.图3为实施例数据混淆模块同步更新示意图;
11.图4为实施例中参数传递示意图。
具体实施方式
12.如图1所示,为本实施例涉及一种支持隐私保护的外包深度学习系统,包括:数据加密模块、位于可信执行环境中的数据解密模块和数据混淆模块以及位于不可信gpu设备中的神经网络计算模块,其中:数据加密模块和数据解密模块分别根据生成的公私钥对中的公钥和私钥进行数据加密和解密,数据混淆模块对来自数据解密模块的解密信息进行脱敏处理后输出脱敏数据至神经网络计算模块,神经网络计算模块根据脱敏数据进行神经网络模型的训练和测试,得到混淆梯度参数并输出至数据混淆模块进行同步更新,提高整个训练系统的收敛速度和精度。
13.所述的数据混淆模块经过初始化后,在正向传播中通过随机稀疏矩阵并对原始数据进行线性变换,得到脱敏数据并输出至gpu中的神经网络计算模块;在反向传播中接收来自神经网络计算模块的混淆梯度参数并对随机稀疏矩阵单元进行同步更新。
14.所述的神经网络计算模块采用适用于卷积神经网络、图神经网络在内的多种深度神经网络模型,正向传播中接收来自数据混淆模块的脱敏数据作为网络输入,反向传播中发送混淆梯度参数至数据混淆模块。
15.如图1和图2所示,所述的脱敏处理是指:在可信执行环境中的数据混淆模块构建并初始化随机稀疏矩阵,数据脱敏的过程即为对原始数据作线性变换,对于原始数据xi,混淆输出其中:矩阵w即为随机生成的稀疏矩阵。随机稀疏矩阵初始化时,还需保证每行与每列至少有一个元素不为零,即原始数据的每一个元素都能够至少得到一次线性映射。
16.所述的随机稀疏矩阵的稀疏度由用户指定,稀疏度为0.5表示每列有50%的元素为零。
17.所述的脱敏数据,即解密后得到的原始数据输入神经网络计算模块进行按照梯度下降算法的训练,当神经网络反向更新时,位于可信执行环境的数据混淆模块接收来自模型第一层的梯度值和权重值并对数据混淆模块进行同步更新,使得在一次模型训练中,由于初始化的非零位置不同,最终训练得到的稀疏矩阵和位于不可信gpu设备中的神经网络模型结构都是不一样的,能够有效抵御差分攻击。
18.所述的同步更新,只对稀疏矩阵中非零元素所在的位置进行更新,零元素所在位置始终为零。
19.所述的随机稀疏矩阵相当于生成的随机密钥,通过该密钥将原始数据作线性变换映射为指定大小的随机化数据,该密钥的存储和数据的映射过程都收到可信执行环境保
护。
20.如图3所示,所述的同步更新是指:当该神经网络计算模块使用梯度下降算法进行更新,在每一轮神经网络的反向迭代的梯度信息δ0=(a)tδ1,其中:a
ij
为数据混淆模块中随机稀疏矩阵,δ1为位于不可信gpu设备中神经网络输入层的梯度;计算得到随机稀疏矩阵的梯度后,随机稀疏矩阵中非零元素更新为:
21.如图4所示,在神经网络训练的每个迭代(iteration)中,都涉及一次tee与gpu之间的来回参数传递以实现同步更新,具体包括:
22.1)tee内的数据混淆模块完成原始数据的混淆变换,将脱敏数据xi输出至位于不可信gpu设备中的神经网络计算模块;
23.2)神经网络计算模块完成一轮次的正向和反向传播,同时计算得到输入层梯度δ1;
24.3)神经网络计算模块将输入层梯度δ1输出至tee内的数据混淆模块,在tee内完成数据混淆模块的同步更新;
25.4)进行下一轮次的训练,重复步骤1)-步骤3)。
26.经过具体实际实验,采用intel sgx 2.8作为可信执行环境的实现,位于不可信gpu设备中神经网络模块使用pytorch c++版本作为实现,内核版本为2.3ghz intel core i5 processor,gpu版本为nvidia geforce gtx 1070。选择mnist和cifar作为实验数据集,采用lenet以及resnet20/resnet32作为位于不可信gpu设备中神经网络进行试验。得到的实验数据时,与不设置数据混淆模块的纯神经网络相比,对于mnist数据集本方案具有1%的精度下降,对于cifar数据集具有4%的精度下降,收敛速度没有明显的变化,均属于可接受的精度损失。另一方面,本方案采用皮尔逊相关系数来量化原始数据与脱敏数据之间的相关性,本方案中原始数据与脱敏数据的相关系数为0.168,其程度约等于差分隐私技术中隐私参数为0.7的laplace噪声所能提供的信息脱敏。
27.与tensorscone对比:tensorscone将机器学习模型完全移植到sgx安全区中,该系统支持在不受信任的基础设施上安全地完成模型的训练和预测。尽管优化了tensorscone架构,但sgx中的epc size有限,该方案的计算性能仍然较低,相较于tensorflow lite降低了30%。而本发明选择选择将神经网络仍置于gpu中进行训练,而在可信执行环境中完成对原始数据的混淆脱敏,在保证安全性的同时地缩短了模型训练需要的时间。
28.tensorscone由于进行了整个系统的移植,在保证了安全性的同时没有牺牲模型的精确度。而本发明对原始数据进行混淆,是在牺牲可控精度的情况下实现数据脱敏。在实验中,本发明针对minst数据集约有1%的精度损失,针对较复杂的cifar数据集约有4%的精度损失。
29.与occlum的对比:occlum同样是结合了tee和gpu的计算系统,区别在于其在可信和不可信设备之间有效的划分神经网络线性层与非线性层的计算,将非线性层置于安全区进行计算。这样做的缺点在于复杂的深度神经网络包含了几十甚至上百对“线性层+非线形层”结构,每一对线性层和非线形层都涉及在正向与反向传播时tee内外的接口交互。而本
发明只在位于不可信gpu设备中神经网络前添加数据混淆层,相当于在正向与反向传播时都只包含一次接口交互,提升了整体训练效率。occlum在安全区和非安全区之间切换时,选择使用加性扰动对数据进行脱敏;本发明采用矩阵惩罚,即线性变换的形式添加扰动,安全性更高。
30.occlum在安全区和分安全区切换时涉及加解密操作,整体来说不影响模型精度,而本发明需要牺牲可控的模型精度。
31.与现有技术相比,本发明通过基于随机稀疏矩阵的数据脱敏算法,原始数据经混淆折叠后,与原始数据相关性较小,攻击者无法从tee返回的数据中获取原始数据信息;另一方面,本发明在每一次神经网络迭代过程中只涉及到2次可信执行环境与gpu的交互,减少了接口交互带来的性能损失,而其他类似的方案中接口的交互次数与神经网络复杂程度成正比。
32.上述具体实施可由本领域技术人员在不背离本发明原理和宗旨的前提下以不同的方式对其进行局部调整,本发明的保护范围以权利要求书为准且不由上述具体实施所限,在其范围内的各个实现方案均受本发明之约束。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1