一种定制化生产企业客户画像构建方法
1.本发明涉及定制化生产制造的技术领域,更具体地,涉及一种定制化生产企业客户画像构建方法。
背景技术:
2.客户画像是建立在一系列真实目标客户数据之上,有针对性的对客户属性特征进行抽取和提炼、从而挖掘和识别客户重要特征、形成有代表性的标签化模型。
3.随着大数据技术的不断应用,利用大数据进行精细化分析和智慧决策的方法逐渐成为研究热点。客户画像作为勾画目标客户、提高决策效率的有效工具,现已在各领域得到广泛应用。相关学者主要从社交网络、电商消费、移动通信、图书馆资源、银行理财等领域的真实数据集建立模型,抽取客户的有效特征、抽象出不同客户群体的行为轮廓,从而针对特定的客户群体开展精准服务,提高服务效率。
4.企业在进行产品或服务的设计、研发时,关注的往往并不是某一个客户的偏好,而是某一类或几类客户的偏好,因此只开展单客户画像不仅不能提供足够丰富的客户需求信息,而且运行计算量十分庞大,难以满足商业应用的实际需要。
5.当前对定制化生产制造企业的客户画像相关研究尚不丰富,在工业互联网、人工智能、智慧农业、农业机械化蓬勃发展的大环境下,农业装备零部件、电子元器件等定制化生产制造企业开始快速崛起,与之相对的是企业之间的竞争也愈加激烈;而客户是企业产生价值收入的来源,维持良好的客户关系管理提升服务水平,对于企业保持行业内的竞争优势是至关重要的。由数据组成的画像可以再现客户的全貌,这是企业挖掘客户需求与价值、进行客户细分实施精准营销的基础,可以预见将画像技术用到定制化生产制造领域,可以极大帮助业务人员深入了解客户,差异化管理不同的客户,从而更好的挖掘客户潜在价值,为企业带来利益。
6.现有技术公开了一种基于聚类分析的客户分群实现方法,包括以下步骤:建立标签画像系统;获取待分群的客户数据集;选择客户标签,生成初始客户标签库;配置聚类数目k,并选择是否对初始客户标签库的标签进行降维;利用主成分分析法对待分析客户标签库中的连续型标签进行降维处理,对类别型标签进行one-hot编码,生成最终客户标签库;于最终客户标签库,利用k-means算法进行聚类分析,生成聚类结果并进行展示。现有技术能够让业务人员从客户标签体系中筛选出客户标签作为聚类特征,并进行简单配置后,即可自动完成客户聚类分群,将聚类分群结果展示到前台,呈现给业务人员,然而,该方案中,业务人员将需要进行分群的客户名单上传以获取待分群的客户数据集,操作冗杂耗时长,且客户信息挖掘不足,不能提供足够丰富的客户需求信息,难以满足商业应用的实际需要。
技术实现要素:
7.本发明的目的在于克服现有技术的不足,提供一种定制化生产企业客户画像构建方法,丰富了生产企业客户画像,深度挖掘获取足够丰富的客户需求信息,以便更好地挖掘
客户潜在价值,满足商业应用的实际需要。
8.为解决上述技术问题,本发明采用的技术方案是:
9.提供一种定制化生产企业客户画像构建方法,包括以下步骤:
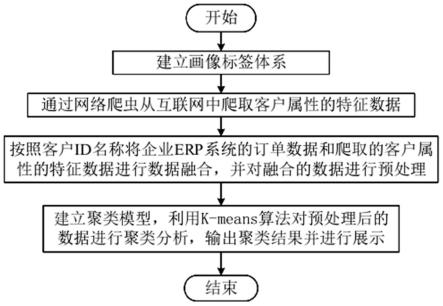
10.s1:建立画像标签体系;
11.s2:通过网络爬虫从互联网中爬取客户属性的特征数据;
12.s3:按照客户id名称将企业erp系统的订单数据和步骤s2中爬取的客户属性的特征数据进行数据融合,并对融合的数据进行预处理;
13.s4:建立聚类模型,利用k-means算法对步骤s3预处理后的数据进行聚类分析,输出聚类结果并进行展示。
14.本发明的定制化生产企业客户画像构建方法,首先建立画像标签体系,采用网络爬虫手段从互联网中爬取客户相关的属性特征,融合企业erp系统数据与网络爬虫数据并进行预处理,深度挖掘获取足够丰富的客户需求信息,丰富了生产企业客户画像,以便更好地挖掘客户潜在价值,采用k-means聚类进行聚类分析,可将具有相似特征的多个客户划分呈若干客户群体,最终输出聚类结果并展示,辅助业务人员进行决策,满足商业应用的实际需要。
15.优选地,步骤s1中,建立画像标签体系的过程为:梳理和分析定制化生产企业客户画像场景的领域特征。
16.优选地,步骤s2中,网络爬虫的工作流程包括:
17.s21:建立url列表;
18.s22:判断url列表是否为空,若是,结束数据爬取,若否,进入步骤s23;
19.s23:依次取出列表中的url,并根据url地址向服务器发送网络请求,服务器根据请求方式进行响应;
20.s24:解析服务器返回的数据,提取相关字段信息,并存入到数据库中,返回步骤s22。
21.优选地,步骤s3的具体过程为:
22.s31:将企业erp系统订单数据与网络爬虫数据融合;
23.s32:对融合后的数据进行数据清洗;
24.s33:对数据进行时间戳转换;
25.s34:构造画像标签;
26.s35:对画像标签中的文本型标签采用独热编码进行标签转化与编码处理;
27.s36:对标签数据进行相关性分析;
28.s37:对标签数据进行归一化处理。
29.优选地,步骤s4中,对数据进行聚类分析的过程为:
30.s41:选择k个样本点作为k-means的初始聚类中心{c1,c2,
…
,ck};
31.s42:计算每一个样本点到聚簇中心的欧式距离,将样本点划分到距离最近的聚簇中心,得到k个聚簇{s1,s2,
…
,sk};
32.s43:重新计算每个聚簇样本点到聚簇中心距离的均值,作为新的聚簇中心cj:
[0033][0034]
式中,m
′
表示第j个聚簇中样本点数;θ表示第j个聚簇中的样本点;sj表示第j个聚簇;
[0035]
s44:判断聚簇中心是否发生变化,若是,重复步骤s42和步骤s43;若否,进入步骤s45;
[0036]
s45:计算聚类评价指标;
[0037]
s46:判断是否选择到最佳聚簇数k,若是,输出聚簇和各簇聚类中心;若否,更改聚簇数k,返回步骤s41。
[0038]
优选地,步骤s42中,样本点到聚簇中心的欧式距离的计算如下:
[0039][0040]
式中,θi表示第i个样本点,1≤i≤m,m为样本个数;cj表示第j个聚簇中心;n表示样本点的维度;θ
it
表示第i个样本点的第t个维度特征;c
jt
表示第j个聚簇中心的第t个维度特征。
[0041]
优选地,步骤s44中,通过计算聚类误差平方和是否稳定来判断聚簇中心是否发生变化,聚类误差平方和的计算过程为:
[0042][0043]
式中,sse为聚类误差平方和。
[0044]
优选地,步骤s45中,聚类评价指标包括轮廓系数sc和chi指数,具体计算方法为:
[0045][0046][0047]
式中,m为样本数;ai表示样本点与同簇的其他样本点的平均欧式距离;bi表示样本点与其他簇内样本点的平均距离;bk表示簇间样本数据的协方差矩阵;wk表示簇内样本数据的协方差矩阵;tr表示矩阵的迹,即矩阵的主对角线元素的总和;sc越接近1,chi越大,模型聚类效果越好。
[0048]
优选地,步骤s4中,利用可视化操作系统提供一个可视化查询操作界面用于展示聚类结果。
[0049]
优选地,可视化操作系统的操作流程为:登录可视化操作系统;可视化操作查询界面;可视化关联分析;退出可视化操作系统。
[0050]
本发明的定制化生产企业客户画像构建方法与背景技术相比,产生的有益效果为:
[0051]
采用网络爬虫手段从互联网中爬取客户相关的属性特征,融合企业erp系统数据与网络爬虫数据并进行预处理,深度挖掘获取足够丰富的客户需求信息,丰富了生产企业客户画像,以便更好地挖掘客户潜在价值,采用k-means聚类进行聚类分析,可将具有相似特征的多个客户划分呈若干客户群体,最终输出聚类结果并展示,辅助业务人员进行决策,满足商业应用的实际需要。
附图说明
[0052]
图1为本发明实施例一中定制化生产企业客户画像构建方法流程图;
[0053]
图2为本发明实施例一中网络爬虫的工作流程图;
[0054]
图3为本发明实施例二中对数据进行融合和预处理的流程图;
[0055]
图4为本发明实施例三中对数据进行聚类分析的流程图;
[0056]
图5为本发明实施例三中可视化操作系统的操作流程图。
具体实施方式
[0057]
下面结合具体实施方式对本发明作进一步的说明。
[0058]
实施例一
[0059]
一种定制化生产企业客户画像构建方法,如图1所示,包括以下步骤:
[0060]
s1:建立画像标签体系;
[0061]
s2:通过网络爬虫从互联网中爬取客户属性的特征数据;
[0062]
s3:按照客户id名称将企业erp系统的订单数据和步骤s2中爬取的客户属性的特征数据进行数据融合,并对融合的数据进行预处理;
[0063]
s4:建立聚类模型,利用k-means算法对步骤s3预处理后的数据进行聚类分析,输出聚类结果并进行展示。
[0064]
上述的定制化生产企业客户画像构建方法,首先建立画像标签体系,采用网络爬虫手段从互联网中爬取客户相关的属性特征,融合企业erp系统数据与网络爬虫数据并进行预处理,深度挖掘获取足够丰富的客户需求信息,丰富了生产企业客户画像,以便更好地挖掘客户潜在价值,采用k-means聚类进行聚类分析,可将具有相似特征的多个客户划分呈若干客户群体,最终输出聚类结果并展示,辅助业务人员进行决策,满足商业应用的实际需要。
[0065]
步骤s1中,分析定制化生产企业客户画像场景的领域特征,进行业务梳理,建立画像标签体系。
[0066]
生产企业的客户往往自身也是企业而不是个人客户,是一种典型的企业对企业的交易模式,其客户相对较少,交易对象相对固定,在实践中客户规模、经济实力、行业、规模地区影响力也是业务人员事项差异化管理的重要考虑因素,使得生产企业的客户画像标签构成更为复杂。步骤s2中,网络爬虫是按照一定的规则模拟人工登录的方式,自动抓取网页数据的程序,可便于爬取客户属性的特征数据,网络爬虫的工作流程如图2所示,包括:
[0067]
s21:建立url列表;
[0068]
s22:判断url列表是否为空,若是,结束数据爬取,若否,进入步骤s23;
[0069]
s23:依次取出列表中的url,并根据url地址向服务器发送网络请求,服务器根据
请求方式进行响应;
[0070]
s24:解析服务器返回的数据,提取相关字段信息,并存入到数据库中,返回步骤s22。
[0071]
实施例二
[0072]
本实施例与实施例一类似,所不同之处在于,步骤s3的具体过程如图3所示,包括以下步骤:
[0073]
s31:将企业erp系统订单数据与网络爬虫数据融合;
[0074]
s32:对融合后的数据进行数据清洗;
[0075]
s33:对数据进行时间戳转换;
[0076]
s34:构造画像标签;
[0077]
s35:对画像标签中的文本型标签采用独热编码进行标签转化与编码处理;
[0078]
s36:对标签数据进行相关性分析;
[0079]
s37:对标签数据进行归一化处理。
[0080]
步骤s35中,画像标签中的部分文本型标签不能直接带入聚类模型进行计算,需要做相关编码处理,将文本型标签转换成数值型标签,标签转化与编码采用独热编码,其方法是使用n为状态寄存器来对n个状态进行编码,每个状态都有独立的寄存器位,并且在任意时候,其中只有一位有效,即只有一位是1,其余都是0。独热编码是利用0和1表示一些参数,使用n为状态寄存器来对n个状态进行编码,使用独热编码,将离散特征的取值扩展到了欧式空间,离散特征的某个取值就对应欧式空间的某个点,将离散型特征使用独热编码,会让特征之间的距离计算更加合理。
[0081]
步骤s36中,设标签数据中的两个变量x、y,相关性分析涉及到的公式如下:
[0082][0083]
式中,r表示皮尔逊相关系数,表示变量x、y的协方差;表示变量x的标准差;表示变量y的标准差;r的绝对值越大,相关性越强,即相关系数越接近1或-1,相关度越强;相关系数越接近0,相关度越弱,通过以下取值范围判断变量的相关强度:0.8-1.0为极强相关;0.6-0.8为强相关;0.4-0.6为中等程度相关;0.2-0.4为弱相关;0.0-0.2为极弱相关或无相关。
[0084]
由于各画像标签通常具有不同的量纲和数量级,当各指标间的水平相差很大时,如果直接用原始指标值进行分析,就会突出数值较高的指标在综合分析中的作用,相对削弱数值水平较低指标的作用,因此,为了保证结果的可靠性,需要对标签数据进行归一化处理,设标签数据为xi和xj,数据归一化处理后为x
ij
:
[0085][0086]
数据归一化不改变原始样本数据分布特征,将所有样本数据线性映射到[0,1]区间。
[0087]
实施例三
[0088]
本实施例与实施例二类似,所不同之处在于,步骤s4中,k-means算法实现原理简
单、收敛速度较快、聚类效果较优,如图4所示,对数据进行聚类分析的过程为:
[0089]
s41:选择k个样本点作为k-means的初始聚类中心{c1,c2,
…
,ck};
[0090]
s42:计算每一个样本点到聚簇中心的欧式距离,将样本点划分到距离最近的聚簇中心,得到k个聚簇{s1,s2,
…
,sk};其中,样本点到聚簇中心的欧式距离的计算如下:
[0091][0092]
式中,θi表示第i个样本点,1≤i≤m,m为样本个数;cj表示第j个聚簇中心;n表示样本点的维度;θ
it
表示第i个样本点的第t个维度特征;c
jt
表示第j个聚簇中心的第t个维度特征;
[0093]
s43:重新计算每个聚簇样本点到聚簇中心距离的均值,作为新的聚簇中心cj:
[0094][0095]
式中,m
′
表示第j个聚簇中样本点数;θ表示第j个聚簇中的样本点;sj表示第j个聚簇;
[0096]
s44:通过计算聚类误差平方和是否稳定来判断聚簇中心是否发生变化,聚类误差平方和的计算过程为:
[0097][0098]
式中,sse为聚类误差平方和;
[0099]
若sse不稳定,重复步骤s42和步骤s43;若sse稳定,进入步骤s45;
[0100]
s45:计算聚类评价指标;聚类评价指标包括轮廓系数sc和chi指数,具体计算方法为:
[0101][0102][0103]
式中,m为样本数;ai表示样本点与同簇的其他样本点的平均欧式距离;bi表示样本点与其他簇内样本点的平均距离;bk表示簇间样本数据的协方差矩阵;wk表示簇内样本数据的协方差矩阵;tr表示矩阵的迹,即矩阵的主对角线元素的总和;sc越接近1,chi越大,模型聚类效果越好;
[0104]
s46:判断是否选择到最佳聚簇数k,若是,输出聚簇和各簇聚类中心;若否,更改聚簇数k,返回步骤s41。
[0105]
步骤s4中,利用可视化操作系统提供一个可视化查询操作界面用于展示聚类结果。如图5所示,可视化操作系统的操作流程为:登录可视化操作系统;可视化操作查询界面;可视化关联分析;退出可视化操作系统。其中,可视化操作系统是客户画像表示(雷达
图、柱状图、饼状图)的扩展,可视化操作系统直观的展示,辅助业务人员指定相关决策。
[0106]
在上述具体实施方式的具体内容中,各技术特征可以进行任意不矛盾的组合,为使描述简洁,未对上述各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
[0107]
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1