一种微表情识别方法及系统
本发明涉及图像处理和人工智能,具体涉及一种微表情识别方法系统。
背景技术:
1、微表情是人在经历强烈情绪时产生的快速、无意识的自发式面部动作,它是人在试图掩盖内在情绪时产生,既无法伪造也无法抑制,可以作为判断人主观情绪的重要依据。
2、微表情通常具有持续时间短、运动强度低等特点,一般持续1/25s到1/3s,并且动作幅度非常小,不会同时在上半脸和下半脸出现。
3、微表情具有很大的研究价值,在临床诊断、情绪智力、司法侦讯等领域有着重要应用,越来越多的研究者进入到这个领域对微表情进行研究。
4、传统手工特征提取主要依赖于手工设计的特征提取规则,得到的特征往往无法解释具体每一维的物理含义,需要专业知识和复杂的参数调整过程,同时泛化性能和鲁棒性较差。基于深度学习的方法存在参数量偏大、特征提取不充分等问题。
技术实现思路
1、发明目的:为了克服现有技术的不足,本发明提供一种微表情识别方法,该方法可以解决现有技术所存在的微表情样本不足、特征提取不充分的问题,本发明还提供一种微表情识别系统。
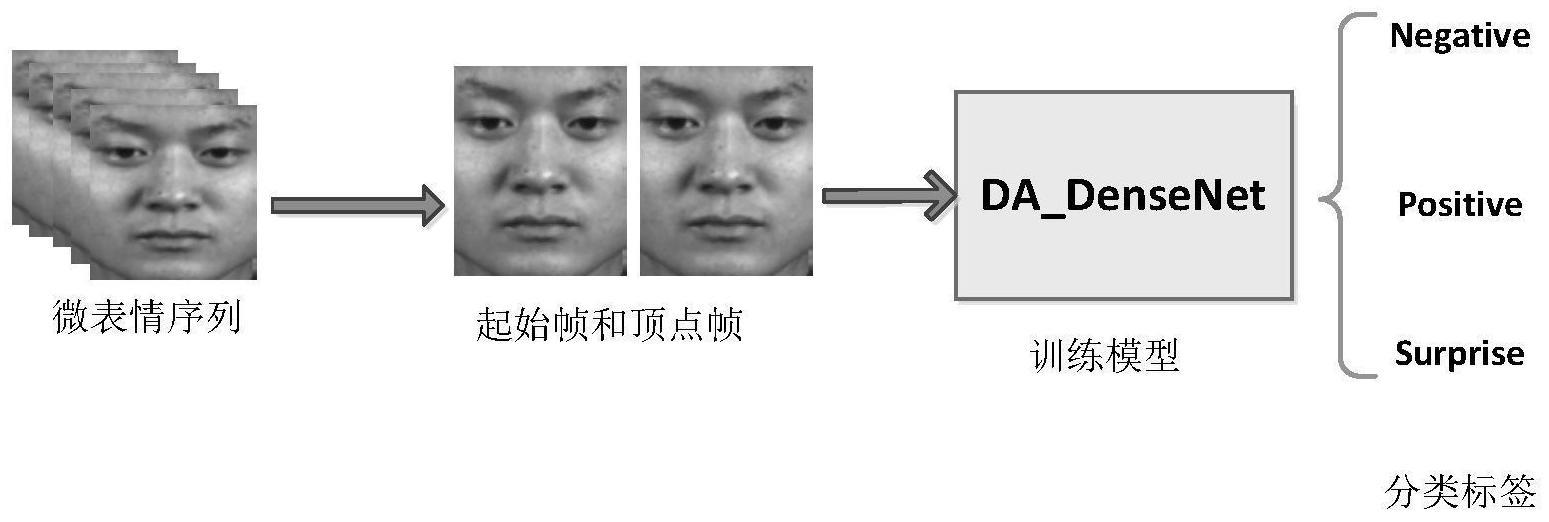
2、技术方案:一方面,本发明提供微表情识别方法,包括:
3、(1)对微表情视频序列进行预处理,得到人脸图像集,并将所述人脸图像集划分为训练集和测试集;
4、(2)搭建网络模型da_densenet,所述网络模型da_densenet采用densenet-121作为骨干网络,并在densenet-121的每一个dense block之后加入两个分支,一个分支是en-scse模块,第二个分支为triplet attention模块,对两个分支输出的特征图进行相乘融合;在每一个transition layer后加入triplet attention,在提取的特征最终进行分类之前,根据所分类的类数,加入特征细化模块;所述en-scse模块是通道级的注意力模块与通道压缩-空间激励模块的并联模块,所述triplet attention模块为不同维度的交互处理模块;
5、(3)采用训练集对所述网络模型da_densenet进行训练,执行分类任务并生成分类模型;
6、(4)采用测试集将训练好的网络模型da_densenet进行测试。
7、进一步的,包括:
8、所述步骤(1)中,对微表情视频序列进行预处理,包括:
9、(11)定位每个微表情视频序列的起始帧和顶点帧,并从定位到的起始帧和顶点帧中分割出人脸区域;并增加微表情顶点帧前后各两帧作为训练或者测试样本;
10、(12)采用随机裁剪,直接将微表情视频序列裁剪出固定大小的微表情样本,对微表情样本进行随机旋转,并对微表情样本进行色彩抖动操作以进行数据增强。
11、进一步的,包括:
12、所述步骤(2)中,en-scse模块的结构包括:
13、scse是cse模块和sse模块的并联;cse模块相当于通道级的注意力,其具体操作是将人脸图像u利用全局平均池化从[c,h,w]变为[c,1,1],再用两次1×1×1卷积运算,最终获得一个c维的向量,再利用sigmoid函数对其进行归一化,最后通过channel-wise相乘得到输出特征。
14、进一步的,包括:
15、在所述channel-wise之前增加了两个线性层并使用relu激活函数。
16、进一步的,包括:
17、所述sse是通道压缩和空间激励模块,它沿着通道压缩人脸图像u并在空间上激发,人脸图像利用1×1×1的卷积,从[c,h,w]变为[1,h,w],使用sigmoid函数激活,然后与原来的人脸图像进行相乘。
18、进一步的,包括:
19、所述sse还包括一支全局平均池化操作,与原来人脸图像特征相乘,空间内不重要的信息将会被抑制,更好地提取重要特征。
20、进一步的,包括:
21、所述步骤(2)中,triplet attention的结构为:
22、triplet attention由3个平行分支组成,第一个分支在h维度和c维度之间建立了交互,第二个分支在c维度和w维度建立了交互,第三个分支在h维度和w维度之间建立了交互,z-pool层负责将c维度的tensor缩减到2维,并将该维上的平均池化特征和最大池化特征连接起来,其公式为:
23、z-pool(x)=[maxpool0d(x),avgpool0d(x)]
24、其中,maxpool代表最大池化,avgpool表示平均池化,0d是发生最大和平均池化操作的第0维;
25、最终3个分支的输出使用平均进行聚合,公式为:
26、
27、其中,σ代表sigmoid激活函数,表示三个分支中由卷积核大小k定义的标准二维卷积层,分别表示第一、第三个分支旋转后的张量,分别表示第一、二分支通过卷积层之后的张量。
28、进一步的,包括:
29、所述步骤(2)中,特征细化模块的结构为:
30、每个特征细化分支由一个全局平均池化和两个全连接层组成,其中,全连接层起到分类的作用,全连接层后是激活层sigmoid;如果训练样本x的微表情样本是第k个类别,则第k个分支中的真值为1,其他分支的真值为0,允许网络为每类表情生成特定于表情的特征。
31、另一方面,本发明还提供一种微表情识别系统,包括:
32、预处理模块,用于对微表情视频序列进行预处理,得到人脸图像集,并将所述人脸图像集划分为训练集和测试集;
33、模型构建模块,用于搭建网络模型da_densenet,所述网络模型da_densenet采用densenet-121作为骨干网络,并在densenet-121的每一个dense block之后加入两个分支,一个分支是en-scse模块,第二个分支为triplet attention模块,对两个分支输出的特征图进行相乘融合;在每一个transition layer后加入triplet attention,在提取的特征最终进行分类之前,根据所分类的类数,加入特征细化模块;所述en-scse模块是通道级的注意力模块与通道压缩-空间激励模块的并联模块,所述triplet attention模块为不同维度的交互处理模块;
34、训练模块,用于采用训练集对所述网络模型da_densenet进行训练,执行分类任务并生成分类模型;
35、测试模块,用于采用测试集将训练好的网络模型da_densenet进行测试。
36、在上面的基础上,本发明还提供一种计算机存储介质,其上存储有计算机程序,所述计算机程序在被计算机处理器执行时实现上述所述的方法。
37、有益效果:(1)本发明采用densenet作为骨干网络,减轻了梯度消失问题,深层梯度可以直接传回浅层,加强了特征的传播,鼓励特征的reuse,每一层输出的特征都被后面的层所使用;(2)dense block之后嵌入增强的scse(en-scse)模块,来抑制无关信息,强调有效特征信息的提取,帮助网络提取更有效的特征信息;(3)tl层之后加入tripletattention模块,在几乎不增加参数的前提下,通过旋转操作和残差变换建立维度间依赖关系;(4)使用特征细化模块对不同类的表情进行特定的表情特征提取,提高分类精度。
- 还没有人留言评论。精彩留言会获得点赞!