跨领域文本分类模型的训练方法、分类方法和装置与流程
本发明涉及人工智能,具体涉及一种跨领域文本分类模型的训练方法、分类方法和装置。
背景技术:
1、文本分类是自然语言处理的一个基本问题,利用算法对文本集按照一定的分类体系或标准进行自动分类或标记,目前已有诸多应用,如文档组织、新闻过滤、内容审核等。跨领域是指源领域(训练集)和目标领域(测试集)在数据分布上存在显著差异,通常的解决办法是通过域适应等手段,充分利用源域知识和充足的带标签数据,从而在无标签数据的情况下提高对于目标域的预测性能。
2、现有方案存在如下问题:现有模型难以捕获源域和目标域共有的文本分布特征,从而降低跨领域的分类准确率;未考虑不同领域内同一类文本之间的数量上的差异性,由此会产生类别不平衡的问题,一定程度上对模型由源域向目标域的迁移性能产生负面影响;未充分考虑和评估不同源域对于目标域的可迁移性能,若存在不可靠的源域信息,则会对模型造成负迁移的不利影响。
技术实现思路
1、鉴于上述问题,提出了本发明以便提供一种克服上述问题或者至少部分地解决上述问题的跨领域文本分类模型的训练方法、分类方法和装置。
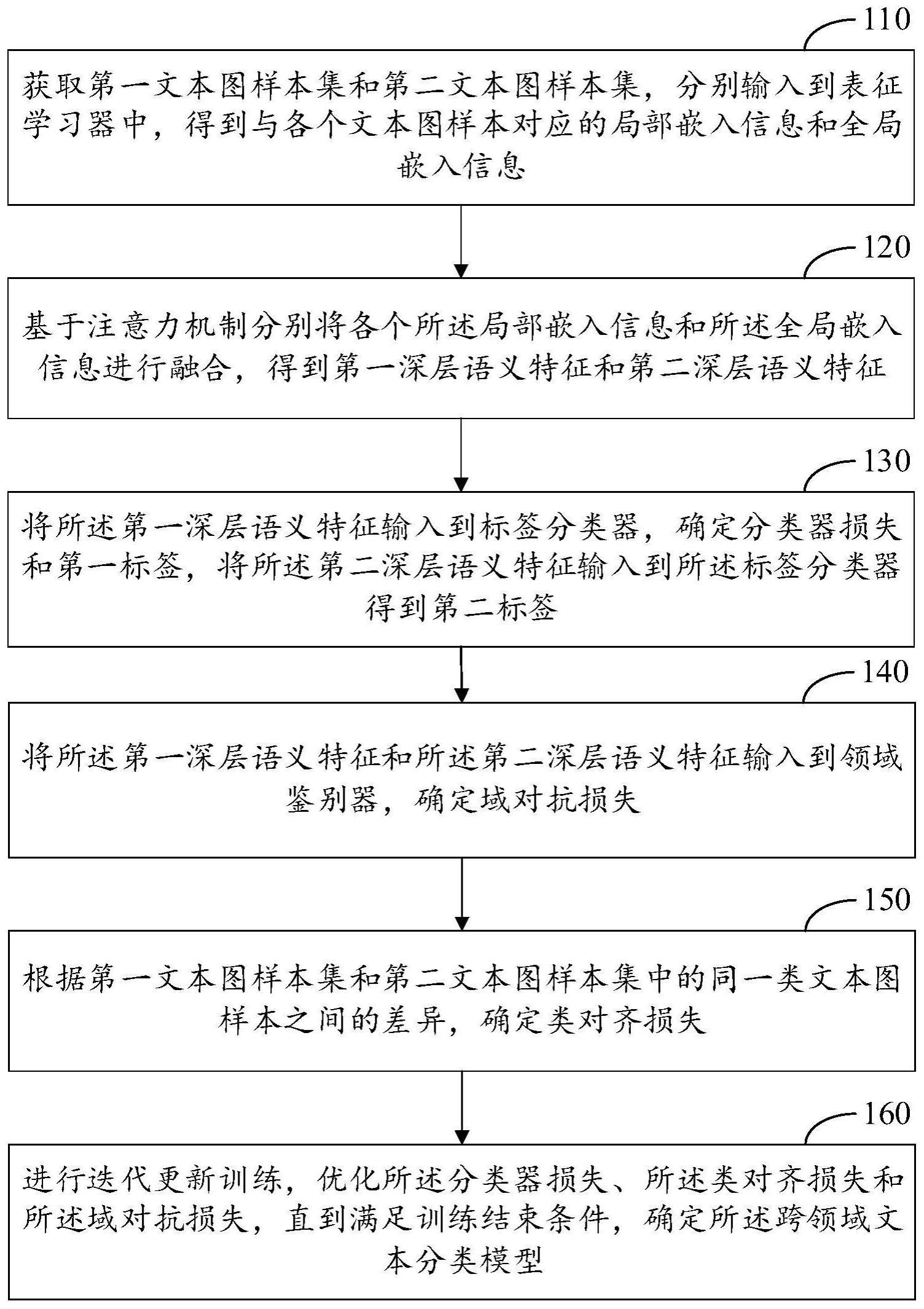
2、根据本发明的一个方面,提供了一种跨领域文本分类模型的训练方法,所述方法包括:
3、获取第一文本图样本集和第二文本图样本集,分别输入到表征学习器中,得到与各个文本图样本对应的局部嵌入信息和全局嵌入信息;
4、基于注意力机制分别将各个所述局部嵌入信息和所述全局嵌入信息进行融合,得到第一深层语义特征和第二深层语义特征;
5、将所述第一深层语义特征输入到标签分类器,确定分类器损失和第一标签,将所述第二深层语义特征输入到所述标签分类器得到第二标签;
6、将所述第一深层语义特征和所述第二深层语义特征输入到领域鉴别器,确定域对抗损失;
7、根据第一文本图样本集和第二文本图样本集中的同一类文本图样本之间的差异,确定类对齐损失;
8、进行迭代更新训练,优化所述分类器损失、所述类对齐损失和所述域对抗损失,直到满足训练结束条件,确定所述跨领域文本分类模型。
9、可选的,所述获取第一文本图样本集和第二文本图样本集,分别输入到表征学习器中,得到与各个文本图样本对应的局部嵌入信息和全局嵌入信息包括:
10、利用基于图邻接矩阵的卷积计算各所述文本图样本内各节点的局部嵌入信息;
11、利用随机游走方式计算各所述文本图样本内各节点之间的语义相似度,得到频率矩阵;基于所述频率矩阵,计算正点互信息矩阵;基于所述正点互信息矩阵的卷积计算各所述节点的全局嵌入信息。
12、可选的,所述基于注意力机制分别将各个所述局部嵌入信息和所述全局嵌入信息进行融合,得到第一深层语义特征和第二深层语义特征包括:
13、利用图注意力机制,通过分别聚合所述第一文本图样本集和所述第二文本图样本集中各文本图样本内各节点的局部嵌入信息和全局嵌入信息,生成所述第一深层语义特征和所述第二深层语义特征。
14、可选的,所述将所述第一深层语义特征输入到标签分类器,确定分类器损失和第一标签包括:
15、将所述第一深层语义特征输入到标签分类器中得到第一标签的预测值;
16、根据所述预测值和所述第一文本图样本集中的带有标签的节点的真实值确定交叉熵损失,并将所述交叉熵损失作为分类器损失;
17、所述将所述第二深层语义特征输入到所述标签分类器得到第二标签包括:
18、将所述第二深层语义特征输入到所述标签分类器中得到相应各节点的输出编码,并根据所述输出编码确定所述第二标签;
19、所述将所述第一深层语义特征和所述第二深层语义特征输入到领域鉴别器,确定域对抗损失包括:
20、将所述第一深层语义特征和所述第二深层语义特征输入到领域鉴别器得到领域标签值;
21、根据所述领域标签值和土方移动距离计算得到第一文本图样本集和第二文本图样本集之间的域对抗损失。
22、可选的,所述根据第一文本图样本集和第二文本图样本集中的同一类文本图样本之间的差异,确定类对齐损失包括:
23、分别计算第一文本图样本集和第二文本图样本集中各个相同类别第一深层语义特征和第二深层语义特征的协方差;
24、计算各个所述相同类别的第一深层语义特征和第二深层语义特征的协方差的距离,将各个所述距离的和作为类对齐损失。
25、可选的,所述进行迭代训练,优化所述分类器损失、所述类对齐损失和所述域对抗损失,直到满足训练结束条件,确定所述跨领域文本分类模型包括:
26、基于所述分类器损失、所述类对齐损失和所述域对抗损失构建目标损失函数;
27、利用所述第一文本图样本集和第二文本图样本集进行迭代训练,更新所述跨领域文本分类模型中的参数;
28、当所述目标损失函数最小或者迭代训练的次数达到预设值时,停止训练,确定当前跨领域文本分类模型为训练好的跨领域文本分类模型。
29、根据本发明的另一方面,提供了一种跨领域文本的分类方法,所述方法包括:
30、接收待检测的文本;
31、将所述待检测的文本输入到跨领域文本分类模型中的标签分类器中,得到所述待检测的文本的分类标签;其中,所述跨领域文本分类模型是根据上述任一项所述的方法训练得到的。
32、根据本发明的又一方面,提供了一种跨领域文本分类模型的训练装置,所述装置包括:
33、嵌入信息获取模块,适于获取第一文本图样本集和第二文本图样本集,分别输入到表征学习器中,得到与各个文本图样本对应的局部嵌入信息和全局嵌入信息;
34、语义特征提取模块,适于基于注意力机制分别将各个所述局部嵌入信息和所述全局嵌入信息进行融合,得到第一深层语义特征和第二深层语义特征;
35、分类标签获取模块,适于将所述第一深层语义特征输入到标签分类器,确定分类器损失和第一标签,将所述第二深层语义特征输入到所述标签分类器得到第二标签;
36、对抗损失确定模块,适于将所述第一深层语义特征和所述第二深层语义特征输入到领域鉴别器,确定域对抗损失;
37、对齐损失确定模块,适于根据第一文本图样本集和第二文本图样本集中的同一类文本图样本之间的差异,确定类对齐损失;
38、分类模型确定模块,适于进行迭代更新训练,优化所述分类器损失、所述类对齐损失和所述域对抗损失,直到满足训练结束条件,确定所述跨领域文本分类模型。
39、根据本发明的再一方面,提供了一种计算设备,包括:处理器、存储器、通信接口和通信总线,所述处理器、所述存储器和所述通信接口通过所述通信总线完成相互间的通信;
40、所述存储器用于存放至少一可执行指令,所述可执行指令使所述处理器执行上述跨领域文本分类模型的训练方法或跨领域文本的分类方法对应的操作。
41、根据本发明的又一方面,提供了一种计算机存储介质,所述存储介质中存储有至少一可执行指令,所述可执行指令使处理器执行如上述跨领域文本分类模型的训练方法或跨领域文本的分类方法对应的操作。
42、根据本发明的跨领域文本分类模型的训练方案,构建了基于对偶图卷积多语义对齐的跨领域文本分类的训练方法,通过对偶图卷积网络和注意力机制捕获并融合不同域文本图的局部嵌入信息和全局嵌入信息,通过同时考虑分类器损失、类对齐损失和域对抗损失,将不同域文本图的深层语义特征进行多重对齐,尽可能提高分类模型在跨领域场景下的文本分类性能,从而实现跨领域场景下的文本分类。
43、上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,而可依照说明书的内容予以实施,并且为了让本发明的上述和其它目的、特征和优点能够更明显易懂,以下特举本发明的具体实施方式。
- 还没有人留言评论。精彩留言会获得点赞!