一种用于识别人体行为的神经网络分类模型的训练方法
1.本发明涉及健康大数据、迁移学习领域,具体来说,涉及一种用于识别人体行为的神经网络分类模型的训练方法。
背景技术:
2.由于传感器体积小、功耗低、携带方便、数据所需存储空间小等优点,其被广泛应用于行为识别领域中。以帕金森震颤识别为例,被试者可以使用生活中常见的智能手机或手环(或者任何带有加速计和陀螺仪的电子设备)收集自身的姿势性震颤和静止性震颤数据,随后根据震颤幅度来诊断被试者的患病程度,这将极大的节省被试者和医生的时间成本。
3.然而,传感器数据集普遍面临着标定数据少且数据集质量不高的问题。与图片、音频、文字等可以很方便在采集数据后再进行标注的数据形式不同,对于人类来说,传感器数据往往是难以直接理解的,这使得传感器数据在数据采集后存在标定困难,大量的数据是无标记的。自迁移学习进入大众视野以来,因其可以将从一个领域学习到的知识应用到另一个新的领域而广泛应用于数据标注缺乏的人体行为识别领域之中。具体来说,它将来自专业人士标注过的数据视作源域,而将未标注过的数据视作目标域,通过实例变换、特征提取、寻找子空间等方法来找到源域和目标域的相似性,从而将源域学习到的模型应用于目标域。在迁移学习中,相似性可以通过度量源域和目标域中联合概率分布差异来计算。随着深度学习的兴起,主流的迁移学习算法通过深度神经网络提取源域和目标域的特征,并通过域判别器计算源域和目标域之间的边缘分布差异,以及类判别器来计算不同类别之间的条件分布差异,进而使得联合概率分布差异尽量小从而提高目标域的模型识别精度。
4.与此同时,传感器数据的采集时间一般持续较长,在数据采集期间容易受到干扰。这种干扰可能由传感器佩戴位置发生移位产生,也可能传感器采集对象自身的状态发生了变化,进而使得一条初始数据在不同时间段的数据分布不同,产生了时序分布差异的现象。与随机分布且仅影响少数数据点的噪声不同,时序分布差异遵循某种随着时间变化的分布,其会影响一个时间段内大量的数据点。同时,由于时序分布差异产生的原因具有不可预知性,拟合其分布是不可行的,这使得时序分布差异普遍存在于传感器数据集中且难以消除。因此,在对传感器时序数据进行迁移学习时,基于现有的迁移学习方法均难以取得像在对图像数据集上进行迁移学习一样良好的效果。
技术实现要素:
5.因此,本发明的目的在于克服上述现有技术的缺陷,提供一种用于识别人体行为的神经网络分类模型的训练方法。
6.本发明的目的是通过以下技术方案实现的:
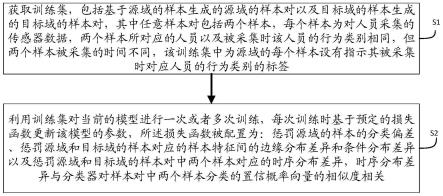
7.根据本发明的第一方面,提供一种用于识别人体行为的神经网络分类模型的训练方法,所述模型包括用于从样本提取样本特征的特征提取器和根据样本特征对样本进行分
类的分类器,所述方法包括利用源域中的样本以及标签对模型进行训练以得到初始的模型,并在初始的模型的基础上按照以下方式进行一轮或者多轮迭代训练:s1、获取训练集,包括基于源域的样本生成的源域的样本对以及目标域的样本生成的目标域的样本对,其中任意样本对包括两个样本,每个样本为对人员采集的传感器数据,两个样本所对应的人员以及被采集时该人员的行为类别相同,但两个样本被采集的时间不同,该训练集中为源域的每个样本设有指示其被采集时对应人员的行为类别的标签;s2、利用训练集对当前的模型进行一次或者多次训练,每次训练时基于预定的损失函数更新该模型的参数,所述损失函数被配置为:惩罚源域的样本的分类偏差、惩罚源域和目标域的样本对应的样本特征间的边缘分布差异和条件分布差异以及惩罚源域和目标域的样本对中两个样本对应的时序分布差异,时序分布差异与分类器对样本对中两个样本分类的置信概率向量的相似度相关。
8.在本发明的一些实施例中,时序分布差异按照以下方式确定:利用分类器根据样本的样本特征获取该样本在每种类别的置信概率并拼接成该样本对应的置信概率向量;根据样本对中两个样本对应的置信概率向量计算相似度,并根据一次训练时采用的所有样本对中两个样本对应的相似度确定时序分布差异。
9.在本发明的一些实施例中,在一次训练时,时序分布差异计算方式如下:
[0010][0011]
其中,ms表示进行一次训练时采用的源域的样本对总数,x
si
表示源域的第i个样本对,表示源域的第i个样本对x
si
中一个样本,表示源域的第i个样本对x
si
中另一个样本,sim(
·
)表示余弦相似度,c(
·
)表示分类器输出的针对每种类别的置信概率,f(
·
)表示特征提取器的输出,m
t
表示进行一次训练时采用的目标域的样本对总数,x
ti
表示目标域的第i个样本对,表示目标域的第i个样本对x
ti
中一个样本,表示目标域中第i个样本对x
ti
中另一个样本。
[0012]
在本发明的一些实施例中,所述惩罚源域和目标域的样本对应的样本特征间的条件分布差异,包括:根据每次训练时采用的源域和目标域的所有样本的样本特征、源域中所有样本的标签和目标域中所有样本的伪标签,确定源域和目标域的所有样本之间的条件分布差异,其中,所述伪标签为利用当前的模型对目标域中的样本进行分类得到的分类结果。
[0013]
在本发明的一些实施例中,在一次训练时,条件分布差异的计算方式如下:
[0014][0015]
其中,gc表示进行一次训练时采用的源域和目标域的所有样本间的条件分布差异,k表示类别的总数量,k表示第k个类别,表示在希尔伯特空间下距离的平方,ns表
示进行一次训练时源域的样本总数,示进行一次训练时源域的样本总数,示进行一次训练时源域的样本总数,表示源域中第k个类别的权重,表示源域中属于第k个类别的样本总数,φ(
·
)表示一种特征映射方法,f(
·
)表示特征提取器的输出,表示源域的第i个样本,n
t
表示进行一次训练时目标域的样本总数,表示进行一次训练时目标域的样本总数,表示进行一次训练时目标域的样本总数,表示目标域中第k个类别的权重,表示目标域中属于第k个类别的样本总数,表示目标域的第i个样本的伪标签,表示目标域的第i个样本。
[0016]
在本发明的一些实施例中,所述基于预定的损失函数更新该模型的参数包括:基于预定的损失函数计算得到的总损失更新该模型的参数,其中,在一次训练时,总损失的计算方式如下:
[0017][0018]
其中,j(
·
)表示进行一次训练时源域的样本的分类偏差,c(
·
)表示分类器输出的针对每种类别的置信概率,f(
·
)表示特征提取器的输出,xs表示源域中的样本,ys表示源域的样本的标签,α表示边缘分布差异对应的权重数值,gm(
·
)表示进行一次训练时采用的源域和目标域的所有样本间的边缘分布差异,x
t
表示目标域中的样本,β表示条件分布差异对应的权重数值,gc(
·
)表示进行一次训练时采用的源域和目标域的所有样本间的条件分布差异,σ表示时序分布差异对应的权重数值,g
t
(
·
)表示进行一次训练时采用的源域和目标域的所有样本对的两个样本间的时序分布差异,xi表示第i个样本对,表示样本对xi中的一个样本,表示同一样本对xi中的另一个样本,α+β+σ=1。
[0019]
在本发明的一些实施例中,所述每个样本对中的两个样本被采集的时间不同且间隔小于等于预定时长。
[0020]
在本发明的一些实施例中,样本对通过以下方式生成:获取源域和目标域的数据集,其包括多个从不同人员的不同行为类别下采集的预定时长的初始传感器数据;将源域和目标域的每个初始传感器数据均按预定数据长度分割,得到每个初始传感器数据对应的多段传感器数据;在源域的每个初始传感器数据对应的多段传感器数据中随机选择一段数据作为一个样本,在该样本所属的初始传感器数据对应的多段传感器数据中随机选择另一段数据作为另一个样本,并将选择的两个样本组成源域的样本对,且为该样本对中的每个样本设置与其所属的初始传感器数据的标签相同的标签;在目标域的每个初始传感器数据对应的多段传感器数据中随机选择一段数据作为一个样本,在该样本所属的初始传感器数据对应的多段传感器数据中随机选择另一段数据作为另一个样本,并将选择的两个样本组成目标域的样本对。
[0021]
在本发明的一些实施例中,所述识别人体的行为类别包括识别帕金森震颤的行为类别,其中,帕金森震颤的行为类别包括无震颤、轻度震颤、中度震颤和重度震颤。
[0022]
在本发明的一些实施例中,所述识别人体的行为类别包括识别人体日常活动的行为类别,其中,人体日常活动的行为类别包括行走、上楼梯、下楼梯和静坐。
[0023]
根据本发明的第二方面,提供一种识别人体行为的方法,包括:获取从人体中采集的待识别的传感器数据;利用本发明第一方面所述训练方法得到的用于识别人体行为的神经网络分类模型的特征提取器对待识别的传感器数据进行特征提取,并通过其分类器根据提取的特征识别人体行为,得到人体的行为类别。
[0024]
根据本发明的第三方面,提供一种电子设备,包括:一个或多个处理器;以及存储器,其中存储器用于存储可执行指令;所述一个或多个处理器被配置为经由执行所述可执行指令以实现本发明第一方面以及本发明第二方面所述方法的步骤。
[0025]
与现有技术相比,本发明的优点在于:
[0026]
本发明中训练集包括源域和目标域的样本对,任意样本对包括两个样本,每个样本为对人员采集的传感器数据,两个样本所对应的人员以及被采集时该人员的行为类别相同,但两个样本被采集的时间不同,在利用该训练集训练神经网络分类模型时,利用的损失函数不仅考虑了分类偏差、迁移学习时存在的边缘分布差异和条件分布差异,还增加了计算样本对中两个样本对应的时序分布差异(time series distribution discrepancy),基于包括计算有时序分布差异的损失函数多次训练更新模型,使模型在一定程度上消除样本对的两个样本由于采集时间不同所对应的人员自身状态不同而导致的样本特征差异,提高模型对从可穿戴传感器中采集的传感器数据进行识别分类的能力。
附图说明
[0027]
以下参照附图对本发明实施例作进一步说明,其中:
[0028]
图1为根据本发明一个实施例的用于识别人体行为的神经网络分类模型结构示意图;
[0029]
图2为根据本发明一个实施例的源域的样本的生成过程示意图;
[0030]
图3为根据本发明一个实施例的训练神经网络分类模型的方法流程图;
[0031]
图4为根据本发明一个实施例的训练神经网络分类模型时的数据处理过程及原理示意图。
具体实施方式
[0032]
为了使本发明的目的,技术方案及优点更加清楚明白,以下结合附图通过具体实施例对本发明进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
[0033]
如在背景技术部分提到的,传感器数据的采集时间一般持续较长,在数据采集期间容易受到干扰。进而使得同一条数据在不同时间段的数据分布不同,产生了时序差异的现象。同时,由于时序分布差异产生的原因具有不可预知性,拟合其分布是不可行的,这使得时序分布差异普遍存在于传感器数据集中且难以消除,导致在对传感器时序数据进行迁移学习时,基于现有的迁移学习方法均难以取得良好的效果。
[0034]
为了解决以上问题,发明人提供一种用于识别人体行为的神经网络分类模型的训练方法中,其利用的训练集包括由源域样本构成的多个样本对和目标域的样本构成的多个
样本对,任意一个样本对包括两个样本,其中每个样本为对人员采集的传感器数据,两个样本所对应的人员以及被采集时该人员的行为类别相同,但两个样本被采集的时间不同。在利用该训练集训练神经网络分类模型时,不仅考虑了迁移学习时存在的边缘分布差异和条件分布差异,还增加了计算样本对中两个样本对应的时序分布差异(time series distribution discrepancy),时序分布差异与分类器对样本对中两个样本分类的置信概率向量的相似度相关,基于包括计算有时序分布差异的损失函数多次训练更新模型,使模型在一定程度上消除样本对的两个样本由于采集时间不同所对应的人员自身状态不同而导致的样本特征差异,提高模型对从可穿戴传感器中采集的传感器数据进行识别分类的能力。
[0035]
为了更好地理解本发明,下面结合附图以及实施例从模型结构、训练集、模型训练、应用场景四个方面对本发明进行详细说明。
[0036]
一、模型结构
[0037]
根据本发明的一个实施例,参见图1,本发明提供一种用于识别人体行为的神经网络分类模型,该模型包括用于从样本提取样本特征的特征提取器和根据样本特征对样本进行分类的分类器,如从目标域target中获取一个样本进行特征提取获得样本特征f
t
,分类器根据样本特征获得分类结果。其中,特征提取器可以采用现有的神经网络,例如resnet1d、lstm、convlstm、cnn1d等神经网络。分类器包括为一层的全连接神经网络层和softmax层,一层的全连接神经网络层用于对样本的样本特征进行线性变换以得到分类特征,softmax层用于根据样本的分类特征计算各类别的置信概率。分类器也可以为多层的全连接神经网络层和softmax层组成。分类器最终输出置信概率最高的类别作为预测的分类结果。本发明的模型结构为图1所示结构,但后续为了更清楚地理解本发明在训练该模型时如何计算各个部分的损失,后续以图4所示的形式来说明模型的训练过程以及训练过程中如何计算各个部分的损失,最终以训练结束后的特征提取器和分类器组成该神经网络分类模型。
[0038]
二、训练集
[0039]
根据本发明的一个实施例,本发明可以采用现有的传感器数据集生成训练集,该训练集包括基于源域的样本生成的源域的样本对以及基于目标域的样本生成的目标域的样本对。每个样本对包括两个样本,每个样本为对人员采集的传感器数据,两个样本所对应的人员以及被采集时该人员的行为类别相同,但两个样本被采集的时间不同且间隔小于等于预定时长。源域的每个样本设有指示其被采集时对应人员的行为类别的标签。
[0040]
根据本发明的一个实施例,所述基于源域的样本生成的源域的样本对以及目标域的样本生成的目标域的样本对包括通过以下步骤a1、a2、a3和a4生成:
[0041]
在步骤a1中,获取源域和目标域的数据集,其包括多个从不同人员的不同行为类别下采集的预定时长的初始传感器数据。
[0042]
根据本发明的一个实施例,针对不同的人体行为应用场景,选择的传感器数据集不同。例如,针对人体日常活动,源域采用ucihar数据集(human activity recognition using smartphones dataset),该数据集从年龄分布为19-48岁的30名被试者中收集,将一个手机绑在被试者的腰部并以50hz采样频率采集加速计传感器数据,与此同时一个录像机实时进行录像以用于事后对数据打标签,在实验中使用其中的加速计传感器数据作为源域
的初始传感器数据;目标域采用wisdm数据集(wireless sensor data miniing),该数据集在29名被试者的裤子口袋中放置手机并以20hz的采样频率收集被试者行走、慢跑、爬楼梯、坐和站立时的加速计传感器数据作为目标域的初始传感器数据。源域也可采用pamap2数据集(physical activity monitoring dataset),该数据集从9位被试者中收集了18种活动动作,包含3个加速计传感器数据(分别位于手臂,胸部和脚踝)以及1个心率传感器数据,本发明使用了位于手臂的加速计传感器数据作为源域的初始传感器数据,且其采样频率为100hz,目标域也可采用ucihar数据集(human activity recognition using smartphones dataset)。其中,在以上三种数据集ucihar、wisdm、pamap2中可以任选一个作为源域的数据集,并在剩下的两个数据集中任选一个作为目标域的数据集。又例如,针对帕金森震颤,源域采用tim-tremor数据集(technology in motion tremor),该数据集从使用粘贴在患者手背上的加速计传感器收集了55位患者的姿势性震颤和静止性震颤数据以及视频录像。目标域采用pdassist数据集(objective and quantified symptom assessment of parkinson’s disease via smartphonm),该数据集创建者通过其开发的手机助手,数百名病患左右手手持静止性震颤测试的加速计传感器,并以50hz的采样频率收集病患的帕金森震颤数据;目标域也可采用imu-wild数据集(imu data captured unobtrusively in-the-wild by parkinson’s disease patients and healthy controls),该数据集在户外条件下采集被试者在“打电话”动作时的震颤数据,包括以50hz的采样频率收集了45位被试者在与帕金森疾病相关联的震颤发生时的加速计和陀螺仪数据,其中包括31名患者和14名健康人;目标域也可采用pd-biostamp数据集(parkinson’s disease accelerometry dataset from five wearable sensor study)。其中,对于帕金森震颤,在以上四种数据集tim-tremor、pdassist、imu-wild、pd-biostamp中,只选取tim-tremor数据集作为源域的数据集,剩余数据集的采集类别不平衡,在剩余数据集中任选一个作为目标域的数据集。
[0043]
在步骤a2中,将源域和目标域的每个初始传感器数据按预定数据长度分割,得到每个初始传感器数据对应的多段传感器数据。
[0044]
根据本发明的一个实施例,在训练前,将源域的数据集的数据和标签以及目标域的数据集的数据共同作为训练数据集,在训练时,利用源域的数据集(例如ucihar数据集)的数据和标签和目标域的数据集(例如wisdm数据集)的数据训练模型预测目标域的数据集(wisdm数据集)的数据的标签,在测试时将目标域的数据集(wisdm数据集)的数据和标签作为测试数据集,并以预测的目标域的数据集(wisdm数据集)的数据的标签正确性作为评判标准。其中,训练前还需将源域和目标域采用的数据集通过线性插值的方式将各个数据集的采样频率统一为50hz,再分割源域和目标域各自统一采样频率后的初始传感器数据,其中,分割的预定数据长度可根据经验设定。例如,本发明按照步长为2.56秒不重叠对源域和目标域各自的初始传感器数据进行分割,每段传感器数据包括128个数据点的标准长度,则当采集每段初始传感器数据的时间为10秒时,样本对中的两个样本被采集的时间间隔小于等于预定时长7.44秒。本发明对数据集中的初始数据集进行该实施例中按照预定数据长度分割的处理方式,以避免数据段过长且长短不一,导致模型难以学习,缺乏泛化性和鲁棒性。
[0045]
在步骤a3中,在源域的每个初始传感器数据对应的多段传感器数据中随机选择一段数据作为一个样本,在该样本所属的初始传感器数据对应的多段传感器数据中随机选择
另一段数据作为另一个样本,并将选择的两个样本组成源域的样本对,并为每个样本设置与其所属的初始传感器数据的标签相同的标签。
[0046]
根据本发明的一个示例,说明源域的样本对的生成方式。参见图2,图2为源域的样本的生成过程,首先获取一个人员的一个行为类别下采集的预定时长的初始传感器数据,该初始传感器数据的标签可以为1,用于指示其被采集时对应人员的一种行为类别;将该初始传感器数据按预定数据长度分割得到三段传感器数据,随机选择第一段传感器数据作为一个样本1,再随机选择第二段传感器数据作为另一个样本2,将样本1和样本2组成样本对,由于两个样本所属的初始传感器数据的标签为1,因此为两个样本的标签设置为1,也可以将选择的第一段传感器数据和第三段传感器数据分别作为样本1和样本3组成样本对,或是将选择的第二段传感器数据和第三段传感器数据分别作为样本2和样本3组成样本对,由于样本1、样本2和样本3所属的初始传感器数据的标签为1,因此为三个样本的标签均设置为1。
[0047]
在步骤a4中,在目标域的每个初始传感器数据对应的多段传感器数据中随机选择一段数据作为一个样本,在该样本所属的初始传感器数据对应的多段传感器数据中随机选择另一段数据作为另一个样本,并将选择的两个样本组成目标域的样本对。本发明实施例中根据以上方式组成目标域的样本对,使目标域的样本对的两个样本在没有设置标签的情况下,依然可以确定目标域的样本对的两个样本应该为同一标签,以更好地训练神经网络分类模型识别不同时间段采集的来自同一人员的同一行为类别下的传感器数据。
[0048]
三、模型训练
[0049]
根据本发明的一个实施例,参见图3,本发明提供一种用于识别人体行为的神经网络分类模型的训练方法,所述方法包括利用源域中的样本以及标签对模型进行训练以得到初始的模型,该初始的模型可以实现对样本进行识别和分类,并在初始的模型的基础上按照以下步骤s1和s2进行一轮或者多轮迭代训练。为了更好地理解本发明,下面结合具体的实施例针对每一个步骤分别进行详细说明。
[0050]
在步骤s1中,获取训练集,包括基于源域的样本生成的源域的样本对以及目标域的样本生成的目标域的样本对,其中任意样本对包括两个样本,每个样本为对人员采集的传感器数据,两个样本所对应的人员以及被采集时该人员的行为类别相同,但两个样本被采集的时间不同,该训练集中为源域的每个样本设有指示其被采集时对应人员的行为类别的标签。
[0051]
在步骤s2中,利用训练集对当前的模型进行一次或者多次训练,每次训练时基于预定的损失函数更新该模型的参数,所述损失函数被配置为:惩罚源域的样本的分类偏差、惩罚源域和目标域的样本对应的样本特征间的边缘分布差异和条件分布差异以及惩罚源域和目标域的样本对中两个样本对应的时序分布差异,时序分布差异与分类器对样本对中两个样本分类的置信概率向量的相似度相关。
[0052]
根据本发明的一个实施例,参见图4,图4为训练神经网络分类模型时的数据处理过程,在训练神经网络分类模型时,引入了迁移学习模块和时序分布自适应网络,迁移学习模块用于计算边缘分布差异和条件分布差异,时序分布自适应网络用于计算时序分布差异,时序分布自适应网络中示出的分类器实际即为神经网络分类模型中的分类器;换言之,时序分布自适应网络中的分类器仅为示意,此处分类器是用于理解时序分布差异是基于该
分类器对样本对中两个样本分类得到的置信概率向量计算得到的。在每次训练时,在源域和目标域的多个样本对中选择一次训练所需要的样本对并输入模型中进行训练,以源域和目标域的一个样本对对模型的数据处理过程进行说明,将源域中的样本对的两个样本和以及目标域中的样本对的两个样本和依次输入特征提取器中进行特征提取后,输出源域的样本对特征fs和目标域样本对的特征f
t
,其中,fs包括样本的样本特征和样本x
s2
的样本特征f
lsi
,f
t
包括样本的样本特征f
jti
和样本x
t2
的样本特征f
lti
,源域的样本的样本特征f
jsi
和f
lsi
输入模型中的分类器中进行分类得到其分类结果,根据源域的样本分类结果及该样本的标签确定源域的样本的分类偏差,目标域的样本的样本特征f
jti
和f
lti
输入模型中的分类器中进行分类得到目标域的每个样本的分类结果,并将当前目标域的样本的分类结果作为该样本的伪标签,迁移学习模块用于根据源域和目标域的样本的样本特征确定源域和目标域的样本对应的样本特征之间的边缘分布差异和条件分布差异,时序分布自适应网络用于根据源域和目标域的样本对的两个样本的样本特征确定源域和目标域的样本对中两个样本对应的时序分布差异。其中,时序分布自适应网络通过分类器基于样本对中两个样本的样本特征,输出两个样本在每个类别下的置信概率,将样本在每种类别的置信概率并拼接成该样本对应的置信概率向量,如样本种类别的置信概率并拼接成该样本对应的置信概率向量,如样本和各自对应的置信概率向量为和根据输出的置信概率向量得到样本对的两个样本对应的时序分布差异。每次训练,通过以上方式计算的损失来更新模型,拉近了目标域和源域的数据集之间对应的边缘分布差异和条件分布差异,并在一定程度上减少样本对中两个样本对应的时序分布差异。
[0053]
根据本发明的一个实施例,在进行一次或者多次训练中,一次训练是指一个批次的训练。例如,一个批次采用的源域的样本对以及目标域的样本对均为32个,则输入128个样本进行一次训练,训练时计算总损失并根据总损失更新模型,同时,下一次训练时,时序分布自适应网络中的分类器采用模型更新后对应的分类器。
[0054]
根据本发明的一个实施例,在一次训练时,源域的样本的分类偏差采用交叉熵损失函数计算,计算方式如下:
[0055][0056]
其中,j(
·
)表示进行一次训练时所有源域的样本的分类偏差,c(
·
)表示分类器输出的针对每种类别的置信概率,f(
·
)表示特征提取器的输出,xs表示源域中的样本,ys表示源域的样本的标签,ns表示进行一次训练时采用的源域的样本总数,k表示类别总数,p表示概率,表示源域的第i个样本,表示分类器输出该样本为第k类的置信概率,k)表示样本的标签属于第k类时,为1,样本的标签不属于第k类时,为0,表示源域的第i个样本的标签。
[0057]
根据本发明的一个实施例,在一次训练时,源域和目标域的样本对应的样本特征间的边缘分布差异采用最大均值差异(maximum mean discrepancy,mmd距离)的平方作为
损失函数进行计算,计算公式如下:
[0058][0059]
其中,gm(
·
)表示进行一次训练时采用的源域和目标域的所有样本间的边缘分布差异,x
t
表示目标域的样本,表示在希尔伯特空间下距离的平方,ns表示进行一次训练时源域的样本总数,φ(
·
)表示一种特征映射方法,在mmd距离中使用的是核方法,表示源域的第i个样本,n
t
表示进行一次训练时目标域的样本总数,表示目标域的第i个样本,h为可再生核希尔伯特空间(reproducing kernel hilbert space,rkhs)。本发明实施例可以在使用较少的有标签数据通过迁移学习模块计算的边缘分布差异,使目标域的数据分布特征更靠近源域的数据分布特征,提高模型对目标域中的无标签数据的分类预测精度。
[0060]
根据本发明的一个实施例,所述惩罚源域和目标域的样本对应的样本特征间的条件分布差异,包括:根据每次训练时采用的源域和目标域的所有样本的样本特征、源域中所有样本的标签和目标域中所有样本的伪标签,确定源域和目标域的所有样本之间的条件分布差异,其中,所述伪标签为利用当前的模型对目标域中的样本进行分类得到的分类结果。
[0061]
根据本发明的一个实施例,在一次训练时,源域和目标域的样本对应的样本特征间的条件分布差异计算公式如下:
[0062][0063]
其中,gc表示进行一次训练时采用的源域和目标域的所有样本间的条件分布差异,k表示类别的总数量,k表示第k个类别,异,k表示类别的总数量,k表示第k个类别,表示源域中第k个类别的权重,表示源域中属于第k个类别的样本总数,表示源域中属于第k个类别的样本总数,表示目标域中第k个类别的权重,表示目标域中属于第k个类别的样本总数,表示目标域的第i个样本的伪标签。其中,源域由于每个样本的标签已知,所以可以统计源域中每个类别标签的数量;由于目标域的真实标签是不可知的,所以通过当前的模型的分类器得到一次训练中目标域的所有样本的伪标签并根据一次训练中采用的目标域的所有样本的伪标签统计目标域中每个类别标签的数量并使用来近似替代本发明实施例通过计算条件分布差异,使得源域和目标域在每种类别上的样本分布比例近似或相同,使经过迁移学习后的模型能对目标域中的无标签数据进行较好的分类预测。
[0064]
根据本发明的一个实施例,所述时序分布差异按照以下方式确定:利用分类器根据样本的样本特征获取该样本在每种类别的置信概率并拼接成该样本对应的置信概率向
量;根据样本对中两个样本对应的置信概率向量计算相似度,并根据一次训练时采用的所有样本对中两个样本对应的相似度确定时序分布差异。使样本对中来自同一人员的同一行为类别下的两个样本对应的置信概率向量相似度更高,样本对的两个样本获得同一分类结果的概率更大,提高模型对被采集时人员的自身状态不同但行为类别相同的两个传感器数据的识别能力。
[0065]
根据本发明的一个实施例,根据每次训练时采用的源域和目标域中样本对的两个样本对应的置信概率向量计算两个置信概率向量的余弦相似度,余弦相似度值越小,代表两个置信概率向量间的相似度越大,即表示样本对中两个样本的样本特征相似度越大,因此,直接将两个置信概率向量的余弦相似度作为时序分布差异,即在一次训练时,所述时序分布差异计算方式如下:
[0066][0067][0068]
其中,ms表示进行一次训练时采用的源域的样本对总数,x
si
表示源域的第i个样本对,表示源域的第i个样本对x
si
中一个样本,表示源域的第i个样本对x
si
中另一个样本,sim(
·
)表示余弦相似度,c(
·
)表示分类器输出的针对每种类别的置信概率,f(
·
)表示特征提取器的输出,m
t
表示进行一次训练时采用的目标域的样本对总数,x
ti
表示目标域的第i个样本对,表示目标域的第i个样本对x
ti
中一个样本,表示目标域中第i个样本对x
ti
中另一个样本。表示样本对应的置信概率向量,表示样本对应的置信概率向量,表示样本对应的置信概率向量,表示样本对应的置信概率向量。其中,样本对应的置信概率向量为将分类器输出的该样本在每种类别下的置信概率拼接得到的,例如,置信概率向量的,例如,置信概率向量表示样本属于第一种类别的置信概率0.1,属于第二种类别的置信概率0.08,第三种类别的置信概率0.12,属于第四种类别的置信概率0.7拼接得到。本发明实施例针对传感器数据增加了特有的时序分布差异计算,进一步提高本发明基于传感器数据识别人体行为的模型的分类预测精度。
[0069]
根据本发明的另一个实施例,在一次训练时,所述时序分布差异还可通过如下方式进行计算:
[0070][0071]
其中,上述时序分布差异计算方式对全部样本对的总时序分布差异进行求平均,获得源域的每个样本对的平均时序分布差异以及目标域的每个样本对的平均时序分布差异,通过源域和目标域的平均时序分布差异之和作为时序分布差异,以避免样本对越多导致时序分布差异更大而影响模型训练速度。
[0072]
根据本发明的另一个实施例,在一次训练时,所述时序分布差异还可通过如下方式进行计算:
[0073][0074]
其中,γ表示源域的时序分布差异对应的权重数值,δ表示目标域的时序分布差异对应的权重数值,γ+δ=1。
[0075]
由于样本对的两个样本虽来自同一人员的同一行为类别,但两个样本采集时间不同,而被采集时人员在不同时间其自身状态存在差异会导致两个样本存在样本特征差异,因此,本发明通过以上实施例计算得到所有样本对的两个样本间的时序分布差异,使模型在训练更新时考虑样本对的时序分布差异,提高模型对样本对中来自同一人员的同一行为类别下的两个样本的分类精度。
[0076]
根据本发明的一个实施例,所述基于预定的损失函数更新该模型的参数包括:基于预定的损失函数计算得到的总损失更新该模型的参数,其中,在一次训练时,总损失的计算方式如下:
[0077][0078]
其中,j(
·
)表示进行一次训练时源域的样本的分类偏差,c(
·
)表示分类器输出的针对每种类别的置信概率,f(
·
)表示特征提取器的输出,xs表示源域中的样本,ys表示源域的样本的标签,α表示边缘分布差异对应的权重数值,gm(
·
)表示进行一次训练时采用的源域和目标域的所有样本间的边缘分布差异,x
t
表示目标域中的样本,β表示条件分布差异对应的权重数值,gc(
·
)表示进行一次训练时采用的源域和目标域的所有样本间的条件分布差异,σ表示时序分布差异对应的权重数值,g
t
(
·
)表示进行一次训练时采用的源域和目
标域的所有样本对的两个样本间的时序分布差异,xi表示第i个样本对,表示样本对xi中的一个样本,表示同一样本对xi中的另一个样本,α+β+σ=1。通过本发明预定的损失函数计算的总损失包括边缘分布差异、条件分布差异以及针对传感器数据增加了特有的时序分布差异,并对三个差异进行加权计算,可根据实际需求单独针对时序分布差异设置更高的权重数值,提高本发明基于相应传感器数据识别人体行为的模型的分类预测精度。
[0079]
根据本发明的一个实施例,当使用与帕金森震颤相关的传感器数据集对上述实施例中的神经网络分类模型进行训练时,所得到的神经网络分类模型用于识别人体的帕金森震颤的行为类别,其中,帕金森震颤的行为类别包括无震颤、轻度震颤、中度震颤和重度震颤。
[0080]
根据本发明的一个实施例,当使用与人体日常活动相关的传感器数据集对上述实施例中的神经网络分类模型进行训练时,所得到的神经网络分类模型用于识别人体的日常活动的行为类别,其中,人体日常活动的行为类别包括行走、上楼梯、下楼梯和静坐。本发明的方法可以基于相应的传感器数据应用于多种不同的人体行为识别任务,适用范围广。
[0081]
四、应用场景
[0082]
根据本发明的一个实施例,本发明还提供一种识别人体行为的方法,包括:获取从人体中采集的待识别的传感器数据;利用上述实施例所述训练方法得到的用于识别人体行为的神经网络分类模型的特征提取器对待识别的传感器数据进行特征提取,并通过其分类器根据提取的特征识别人体行为,得到人体的行为类别。
[0083]
为了验证本发明的效果,发明人进行了以下实验。
[0084]
首先,选择数据集,一方面针对人体日常活动识别进行实验,选择三个人体日常活动识别(rar)数据集:pamap2数据集(记为数据集p)、wisdm数据集(记为数据集w)和ucihar数据集(记为数据集u)。另一方面针对人体帕金森震颤识别进行实验,选择四个帕金森震颤识别(pd)数据集:tim-tremor数据集(记为数据集ti)、pdassist数据集(记为数据集pa)、imu-wild数据集(记为数据集iw)和pd-biostamp数据集(记为数据集bi)。
[0085]
其次,按照上述实施例中的方式对数据集进行处理。
[0086]
然后,选择与本发明进行对比的训练方法。选取了多种不同的迁移学习算法,将它们与本发明上述实施例中增加用于计算的时序分布差异的时序分布自适应网络(time series domain adaptation model,记为tsan插件)或其他可用于计算时序分布差异的插件进行结合以验证本发明训练方法的有效性,同时,使用了不在目标域上进行训练的resnet(resn)作为基线模型,检验是否发生了负迁移的现象。其中,实验中选取的主流迁移学习算法如下表1所示:
[0087]
表1:迁移学习方法
[0088][0089]
最后,得到实验结果如下表2和表3所示:
[0090]
表2:人体日常活动识别的结果
[0091]
[0092][0093]
表3:帕金森震颤识别的结果
[0094]
[0095][0096]
上述表格2中的u-》w表示源域采用数据集u且目标域采用数据集w,u-》p表示源域采用数据集u且目标域采用数据集p,w-》u表示源域采用数据集w且目标域采用数据集u,w-》p表示源域采用数据集w且目标域采用数据集p,p-》u表示源域采用数据集p且目标域采用数据集u,p-》w表示源域采用数据集p且目标域采用数据集u;表格3中的ti-》bi表示源域采用数据集ti且目标域采用数据集bi,ti-》pa表示源域采用数据集ti且目标域采用数据集pa,ti-》iw表示源域采用数据集ti且目标域采用数据集iw。
[0097]
根据上述表格2和表格3中的每种方法在相应迁移学习任务下均对应一个识别精度,且v_avg表示该任务上所有算法的识别精度的平均值,h_avg表示该算法对于所有任务的识别精度平均值;无插件对应的识别精度表示使用原本的迁移学习算法的识别精度,tsan插件表示原本的迁移学习算法加上本发明设计的用于计算时序分布差异的tsan插件后的识别精度。实验得到的每种方法的识别精度为三次不同随机种子上取平均的结果,识别精度中的
±
符号后面的数字为标准差。对于人体日常活动识别数据集上验证了6个任务,
包括u-》w、u-》p、w-》u、w-》p、p-》u、p-》w。其中对于单一任务,加入tsan插件后的预测精度被提升了2.4%到11%。对于每个迁移学习方法,加入tsan插件后的预测精度被提升了2.9%到8.5%。对所有迁移学习方法在所有任务上,加入tsan插件后的预测精度被平均提高了5.4个百分点。对于帕金森震颤识别数据集上验证了3个任务,包括ti-》bi、ti-》pa、ti-》iw。其中对于单一任务而言,加入tsan插件后的预测精度被提升了1.5%到3.2%。对于单个迁移学习方法而言,加入tsan插件后的预测精度被提升了1.5%到3%。对所有迁移学习方法在所有任务上,加入tsan插件后的预测精度被平均提高了2.2个百分点。可以得知加上本发明增加的用于计算时序分布差异的tsan插件后迁移学习算法的识别精度均比未计算时序分布差异的原本的迁移学习算法的识别精度高,本发明的方法也可以很方便的与各种主流迁移学习算法相结合以更好适用于人体行为识别任务。
[0098]
需要说明的是,虽然上文按照特定顺序描述了各个步骤,但是并不意味着必须按照上述特定顺序来执行各个步骤,实际上,这些步骤中的一些可以并发执行,甚至改变顺序,只要能够实现所需要的功能即可。
[0099]
本发明可以是系统、方法和/或计算机程序产品。计算机程序产品可以包括计算机可读存储介质,其上载有用于使处理器实现本发明的各个方面的计算机可读程序指令。
[0100]
计算机可读存储介质可以是保持和存储由指令执行设备使用的指令的有形设备。计算机可读存储介质例如可以包括但不限于电存储设备、磁存储设备、光存储设备、电磁存储设备、半导体存储设备或者上述的任意合适的组合。计算机可读存储介质的更具体的例子(非穷举的列表)包括:便携式计算机盘、硬盘、随机存取存储器(ram)、只读存储器(rom)、可擦式可编程只读存储器(eprom或闪存)、静态随机存取存储器(sram)、便携式压缩盘只读存储器(cd-rom)、数字多功能盘(dvd)、记忆棒、软盘、机械编码设备、例如其上存储有指令的打孔卡或凹槽内凸起结构、以及上述的任意合适的组合。
[0101]
以上已经描述了本发明的各实施例,上述说明是示例性的,并非穷尽性的,并且也不限于所披露的各实施例。在不偏离所说明的各实施例的范围和精神的情况下,对于本技术领域的普通技术人员来说许多修改和变更都是显而易见的。本文中所用术语的选择,旨在最好地解释各实施例的原理、实际应用或对市场中的技术改进,或者使本技术领域的其它普通技术人员能理解本文披露的各实施例。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1