一种基于元属性学习的事件检测方法
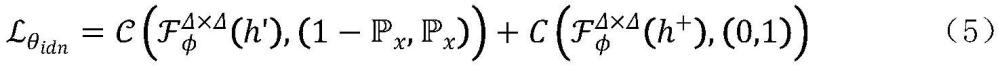
本发明涉及自然语言处理,具体为一种基于元属性学习的事件检测方法。
背景技术:
1、事件检测旨在检测句子中的触发词(标记特定事件发生的单词),并将其分类为预定义的事件类别,这有助于许多应用,例如知识图构建和对话系统中的意图检测。
2、作为一项长期的研究任务,某些语料库上的事件检测方法由于文本表示的发展和丰富的知识库(如词汇知识或常识知识)而取得了优异的性能。此外,为了适应新的事件类别,一些研究还提出了基于原型和事件训练的少样本方法。随着深度学习的发展,现有的基于表示的事件检测方法表现出了优异的性能。其利用单词嵌入和各种神经网络结构,如卷积神经网络、递归神经网络、图卷积网络和预训练语言模型来获得语义丰富的单词表示。
3、一些工作采用教师-学生形式的架构来过滤数据中的噪声或增强鉴别信息。研究人员在远程监督或知识蒸馏框架下引入额外的训练语料库或大规模的外部知识,以丰富现有信息。一些工作利用gpt-2自动生成的训练数据来提高模型的性能。最近,少样本事件检测被提出并引起了人们的关注。少样本事件检测的核心思想是为新的事件类别引入一些示例,并使用它们获得原型。样本的事件类别可以根据其表示和原型之间的相似度来确定。一些工作制定了少样本事件检测任务,并利用动态记忆网络学习更好的事件类别原型。一些工作提出了簇内匹配和簇间信息来为少样本事件检测提供更多的训练信号。之后,研究人员探索各种信息,如事件类别相关性和词汇知识,以增强原型的表示。一些工作提出对跨任务信息进行建模,以解决抽样偏差和离群值问题。然而,由于表示学习和分类过程中不同事件类别之间的明显差距,它们很容易受到数据稀疏性和不平衡性的影响。
4、由于固有的数据稀疏性和不平衡性,在相对较大的类别集中有效地检测训练样本稀缺的事件类别是一项艰巨的任务。以ace2005数据集为例,触发词所占比例不到2%(5649/301229),此外,一些事件类别的比例甚至更低。有1629起袭击事件的样本,而无罪释放、引渡和赦免事件总共只有16起,仅为前者的1%。很难同时获得足够的训练样本和均衡分布,这可能导致某些事件类别很难正确识别和分类。
5、现有的大多数方法都不能很好地解决这个问题。其中一个原因是,其本质上将每个事件视为一个独立的类别,并使用带标注的样本训练分类器对每种类别样本特征的“记忆”,或者通过余弦相似度学习每种类别及其所包含样本的表示。因此,分类器的“记忆”或类别表示的性能主要受样本数量和比例的影响:样本太少无法提供足够的信息,不平衡的样本可能会导致表示和分类偏离某些类别。相比之下,所有类别的样本都拥有一些共同的属性,本发明将其称为“元属性”。如果一个事件类别只有几个样本,它仍然可以从其它类别的样本提供的信息中获益。因此,这些属性受数据分布的影响较小,可能有助于缓解数据稀疏性和不平衡性。
6、考虑到触发词的两个元属性:(i)每个触发词都可以抽象为一种类别,即“事件”,无论它是什么类别的事件;(ii)每个触发词与相同类别的触发词更相似,而不是其它触发词。这些属性由每种类别的样本所持有,仅受样本总数的影响,而不受不平衡分布的影响。
技术实现思路
1、本发明的目的是克服现有基于深度学习技术的事件检测方法中的不足,提供一种能够缓解训练数据标注稀疏和类别分布不均衡的元属性学习事件检测方法。
2、所提出的基于元属性的方法包括:(i)学习用于触发词识别的元属性,假设每个触发词都可以抽象为一种类别,即“事件”,无论它是什么具体的类别,以解决数据稀疏性,以及(ii)学习用于触发词分类的元属性,即触发词更类似于相同类别的触发词,而不是其它类别的触发词,以解决不平衡性。具体而言,所提出的触发词分类方法本质上是完整的事件检测,因为将非事件视为预定义的类别,并且它集成了部分识别组件。因此,本发明提出了基于元属性的事件检测方法,试图对触发词的上述两个属性进行建模。对于(i),将每个触发词替换为保留其上下文的特殊符号(即[trigger]),并通过称为类别无关投影层的多层感知机(multi layer perception,mlp)网络使触发词和特殊符号的表示相似。这种学习到的表示可以看作是“触发词”的类别无关语义,而不是具体的类别具象特征,更容易与非事件词的表示区别开来。对于(ii),在事件类别和输入样本之间建立了一个可学习的度量模型。对于每种事件类别,获取其样本表示,该样本表示提供了类别的语义信息,并引入了其标签表示作为补充。后者对于样本太少而无法准确表示其语义的类别至关重要。对于要确定其类别的输入样本,将其表示与上述类别的表示拼接起来,并通过另一个称为度量层的多层感知机网络将组合转换为相似度分数进行分类。最后,为了解决“非事件”类别缺乏明确的类别语义的问题,将样本的类别无关语义集成到分类方法中,并构建了最终的融合模型。
3、本发明的目的通过以下技术方案实现:
4、一种基于元属性学习的事件检测方法,具体包括以下步骤:
5、(101)样本的语义表示:在本说明书中,样本指的是上下文中的触发词或非事件词。将所有样本视为候选触发词(称为输入样本,用x表示)。操作εφ表示文本编码过程,可以是任何先进的文本表示技术,例如bert或roberta。如公式(1)所示,通过文本编码获取所有样本(用h表示)的表示向量,文本编码用于后续步骤。
6、h=εφ(x) (1)
7、(102)触发词的类别无关语义:每个触发词都包含与事件相关的语义,通常充当句子中的关键谓语或主语、宾语。因此,即使掩盖掉句子中具体的触发词,也可以预测该位置的词语暗示了某个事件的发生。预训练语言模型可以通过掩盖某些特定的单词来预测其所在位置可能的所有单词,原因是强大的注意力机制可以借助上下文获得特定位置单词的表示。受此启发,可以将所有触发词替换为一个特殊符号,例如[trigger](由表示),保留其上下文,然后使用其表示形式作为类别无关的触发词语义(由h+表示),如公式(2)所示。
8、
9、(201)类别无关投影层:在这个过程中,触发词的表示试图模仿类别无关的触发词语义h+。试图通过一个称为类别无关投影层的mlp来约束触发词的表示向量,使其与特殊符号的表示尽可能相似,如公式(3)所示(mlp由表示,其中α和b分别是其输入和输出的维数,是其参数。常数δ表示向量的维数)。投影后的表示向量用h'表示。
10、如公式(4)所示,计算均方误差(mse)损失(以表示)作为优化目标,以更新类别无关投影层的参数(记为θtap)。包括非触发词在内的所有样本在训练和测试期间都被投影,但只有触发词参与了训练期间的损失计算。
11、
12、
13、(202)识别分数:对这两种表示向量(h'和h+)进行二分类,作为触发词识别。在此过程中,如公式(5)所示,计算交叉熵损失(用表示,其中第一项经过softmax操作)作为优化目标,以更新二分类器的参数(用θidn表示)。符号是一个指示符号,如果样本x是触发词,则其值为1,否则为0。
14、
15、最后,通过将公式(4)和公式(5)中的联合训练损失相加,构建整体识别损失函数,如公式(6)所示。
16、
17、(301)类别的样本表示:为了计算输入样本和事件类别之间的相似度,获取类别k的所有样本的表示(由xk∈xk表示,xk表示类别k的样本集合),并使用它们的平均值作为事件类别的表示(由pk表示),如公式(7)所示。
18、
19、类别的标签表示:由于某些类别的标签(由lk表示)提供了额外的类别相关信息,直观上,它们有助于提供补充语义信息,尤其是对于样本非常稀少,无法准确表示类别语义的类别。因此,还获得了标签的表示(由bk表示),如公式(8)所示。
20、bk=εφ(lk) (8)
21、(302)度量层:计算样本x和事件类别k的相似度(由表示),即通过度量层计算上述三种表示h,pk和bk组合的相似度,如公式(9)所示。运算[·,...,·]表示向量的拼接。样本类别的预测结果是相似度最高的类别。在此过程中,计算交叉熵损失作为优化目标,以更新度量层的参数(用θmeas表示),如公式(10)所示。符号是一个指示符号,如果x标注的事件类别为k,则的值为1,否则为0。
22、
23、
24、(401)融合模型与联合训练:最后,将识别组件集成到分类方法中,即,额外将样本表示(公式(3))和类别的样本表示(公式(11))两者的类别无关语义拼接到公式(12)中的组合中,以替换公式(9)。只有当输入样本和类别的原始语义和类别无关语义都一致时,它们才被视为相同的类别。这减少了将事件触发词误分类为“非事件”类别,或将非事件词分类为任何一种事件类别的概率。
25、
26、
27、完整事件检测模型的最终损失函数是通过将公式(4)和(10)中的损失相加来构建的,用于联合训练,如公式(13)所示。
28、
29、与现有技术相比,本发明的技术方案所带来的有益效果是:
30、(1)定义一类事件触发词的共同特性,称为元属性,具体包括触发词的类别无关统一抽象语义和公用相似度度量,能够触发词缓解触发词类别不平衡和数据稀疏所带来的负面效果;
31、(2)提出一种类别无关投影层结构,将具体触发词的语义表示向量映射为抽象的类别无关语义表示,并用于触发词识别,从而缓解数据稀疏问题;
32、(3)提出一种触发词样本与类别的公用可学习度量层,对所有类别的相似度度量进行训练和计算,并用于触发词的分类,从而缓解类别分布不平衡问题;
33、(4)融合以上两种方法,将样本和类别表示的原始语义和类别无关语义,以及类别的标签表示拼接,同时进行触发词的识别和分类作为完整的检测模型,提高事件检测的准确率;
34、(5)在英文真实事件检测数据上进行了实验,实验结果证明了本发明的有效性,并证明了事件元属性学习对于缓解数据稀疏以及类别分布不平衡问题具有重要作用。
- 还没有人留言评论。精彩留言会获得点赞!