基于多层特征融合的FasterR-cnn上下文机制优化方法与流程
本发明属于目标识别,涉及一种优化的上下文机制(基于多层特征融合的faster r-cnn上下文机制)的目标检测方法。
背景技术:
1、在一些高空监控的场景中,一些无源监控对于环境的捕捉在很长一段时间内是处于静态的,处于静态的摄像头捕捉到的画面相比于动态摄像头有捕捉到的画面在每一帧的分别上更具有长期的高度一致性。在捕捉到的视野中,处于不同月份不同天数的画面可能也具有十分的相似性,例如,轨道交通摄像头用于捕捉画面,在对收集到的画面进行分析处理时,尝试用距离这些画面相近的一段时间内的相关信息来帮助决定以及判断当前情况下的情境。这些通过包含过去记忆数据的注意力机制来完成。
2、视频目标检测架构建立在单帧模型之上,并通过合并来拟合其他帧的上下文线索(如传统hypernet方式),来处理视频数据中其余的问题,例如运动模糊、遮挡和罕见的姿势。这类处理方法有类似流的概念来聚合特征,或者使用相关性将当前时间步上的特征和相邻时间步紧密关联。上述大多数的视频检测方法都不太适合目标设置稀疏、不规则帧率的问题。例如,基于流的方法、3d卷积以及lstms这些通常比较密集、规则的帧率采样方法。
3、传统hypernet方式。cnn通过输入图像进行提取特征,得到对应feature maps,对其输入rpn网络后产生得到对应的候选框,并实现对候选框的分类,分类包含对候选框内内容进行判别,判别其是图片背景还是另外前景内容,判别后剔除背景候选内容,只取前景。但是传统方式中,浅层信息中的特征语义信息薄弱,并不能完整的描述对于小目标的表达,而采用上采样的方式对特征图采样后与其他层特征融合,这一方式不仅会导致信息的遗失和遗漏,不利于对于小目标的检测,影响算法对于不同目标的检测速度。
4、反卷积,作为卷积层中的上采样方法,又被称作转置卷积。作为传统的卷积方式,它会在得到产生的图像中导致棋盘效应。因此在上采样方法中用反池化的方法替代,使棋盘化效应得到解决。
5、因此,亟需一种新的上下文机制优化方案来解决现有静态视频目标检测不准确的问题。
技术实现思路
1、有鉴于此,本发明的目的在于提供一种基于多层特征融合的faster r-cnn上下文机制优化方法,利用静态摄像机的长期位置不发生改变的特点,使用一种特征冻结方式创建长期的记忆库,存储受探测者长期以来的习惯性行为。在结构中增加短期注意力机制,将正例和假正例也加入进学习的范围之内,修正识别结果,提高模型对于识别静止不动物体的正确率。
2、为达到上述目的,本发明提供如下技术方案:
3、一种基于多层特征融合的faster r-cnn上下文机制优化方法,在传统的使用hypernet提取预选框特征向量的基础上,将基于不同于传统方式改进的多层特征融合模块加入模型中,对图像不同层次的语义信息进行提取;并将传统采样方式改进为反池化,避免棋盘化问题。然后,将得到的特征向量与上下文注意力机制融合得到多信息特征向量,最终进行识别分类。
4、该方法具体包括以下步骤:
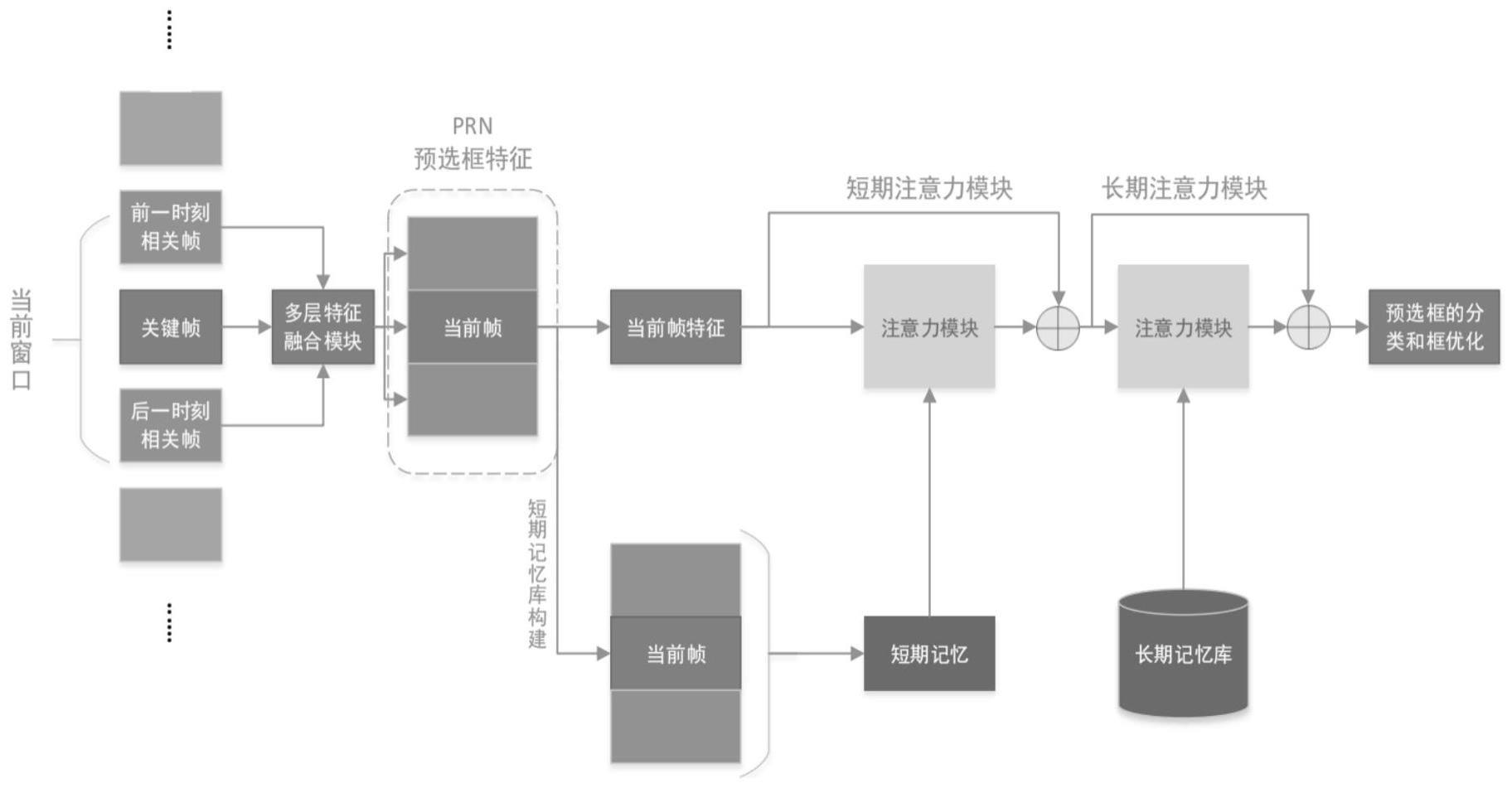
5、s1:将当前关键帧与相关上下文帧输入多层特征融合模块,对其提取预选框特征向量;
6、s2:多层特征融合模块中卷积层深层次采用反池化进行上采样;
7、s3:对于通过多层特征融合模块输出的当前关键帧与相关上下文帧的预选框特征向量,将其分别输入到注意力模块和构建短期记忆库的模块中;
8、s4:当前关键帧的预选框特征向量经过长短期注意力模块,完成上下文相关特征的合并;
9、s5:收集所得到的处理后的预选框特征向量,对其进行分类与框优化。
10、进一步,步骤s1中,将当前帧作为关键帧,与和当前作为关键帧的前后相关帧一同被抽取分别输入到多层特征融合模块中,多层特征融合模块是基于改进的hypernet方法,基于vgg网络,对卷积层的不同深度层次采用不同方式提取特征,更好结合各层的语义信息。具体方法是:将传统方式中对于将传统的第1、3、5层的特征层选取,改进为分别将1、2、5层特征联合,并将1、4、5层的深层特征联合,最后将两层特征进行通道拼接,以获得更详细的语义信息;然后,整个模块通过卷积层转发并生成聚集分层的特征图,然后将它们压缩到一个统一的空间,即超特征;最后,构建一个生成预选框网络,产生大约100个预选框作为输出返回各个帧提取到的预选框特征向量。
11、更进一步,步骤s1中,多层特征融合模块接收到当前输入的帧,模块以vggnet作为它的基础网络,将1、2、5三个特征层进行抽取,对其进行特征拼接。对于第1层特征,首先将其通过卷积层以此减小通道数来达到减小计算量,同样将第2、5层特征通过卷积层后通过一个进行上采样,之后采用反池化将第二、三层特征的像素变成与第一层相同,以便于融合。
12、同样的操作类比于第1、4、5层的深层特征,对于第1层特征,同样将其通过卷积层以此减小通道数来达到减小计算量,同样将第四、五层特征通过卷积层后通过一个进行上采样,之后采用反池化将此第4、5层特征的像素变成与第一层相同,以便于融合。
13、进一步,步骤s2中,将多层特征融合模块中使用的传统的反卷积上采样方式更替为反池化,以解决前者带来的棋盘化问题,池化将不重要的信息舍去,保留主要的信息。反池化是池化的逆操作;从池化后的数据还原出原始的数据值时,运用补位操作来对还原出的数据中缺失的数据进行补位,实现数据完整的最大化操作。
14、进一步,步骤s3~s4中,将当前帧预选框特征向量通过两个分别基于不同记忆库的注意力模块,这些模块以不同的方式索引到记忆库中,使得其中短期记忆库将上下文帧的特征纳入到此记忆库中;这些基于注意力的模块返回一个基于上下文的特征向量,并输入到下一步进行对预选框的分类与框优化。
15、进一步,步骤s3中,相关上下文的预选框特征向量输入短期记忆模块中,构建短期记忆库;当前关键帧的预选框特征向量分别经过长、短期记忆模块中,将其汇总为与短期特征和长期特征相关的特征向量。
16、进一步,步骤s5中,获取经过注意力模块处理后的关键帧及相关上下文帧的预选框特征向量,送入分类模块中,在传统fc-dropout-fc-dropout的层次设计基础上,在全连接层前添加一个3×3×63的卷积层,通过卷积层将特征维度减少一半后输入全连接层,优化之后各层的计算,其次将dropout ratio降低为原来的一半,减少过拟合的现象。即预选框通过池化层后增加一层卷积,其余与传统模型大同小异;通过池化和卷积层对预选框进行分类,完成目标检测输出。
17、本发明的有益效果在于:本发明首先对传统模型中hypernet进行改进,即改进hypernet在上下文注意力模型中的融合,能够获得更详细的语义信息。其次,本发明对传统特征融合中上采样方式的改进。以上方法相结合,运用到高空静态摄像头识别场景,有利于增强对小目标识别的效果,提升检测精度。
18、本发明的其他优点、目标和特征在某种程度上将在随后的说明书中进行阐述,并且在某种程度上,基于对下文的考察研究对本领域技术人员而言将是显而易见的,或者可以从本发明的实践中得到教导。本发明的目标和其他优点可以通过下面的说明书来实现和获得。
- 还没有人留言评论。精彩留言会获得点赞!