一种自适应视线估计方法、系统、电子设备及存储介质
1.本发明涉及视线估计技术领域,特别是涉及一种基于多尺度特征融合的自适应视线估计方法、系统、电子设备及存储介质。
背景技术:
2.视线估计广泛应用于人机交互、心理学、疾病诊断等领域。凝视作为人类获取外部信息的主要手段,可以揭示人类的认知加工和认知加工缺陷。学者们通过视线估计研究各种心理障碍,如:抑郁症、孤独症等。
3.在过去的几十年里,已经提出了许多视线估计方法。例如:基于3d人眼模型的视线估计方法,依赖于一些专用设备,如:红外摄像机、深度摄像机、高分辨率摄像机等,已经开发了许多穿戴式的眼动追踪设备;基于外观的视线估计方法,只需要一个网络摄像头来捕获图像,并直接学习从图像到凝视方向的映射关系。因为对硬件设备要求低,并且智能手机、平板电脑等带有网络摄像头的移动设备逐渐普及,所以基于外观的视线估计方法更具有应用前景。
4.基于外观的视线估计方法,是从脸部图像或眼部图像进行视线估计。卷积神经网络(cnn)由于其强大的特征提取能力,在计算机视觉的各个领域都有应用。一些基于外观的视线估计方法,使用cnn从单个眼部图像或两个眼部图像进行视线估计,一些基于外观的视线估计方法是从脸部图像进行视线估计,一些基于外观的视线估计方法是同时使用脸部图像和眼部图像进行视线估计。然而,这些方法使用简单的技术来融合来自脸部图像和眼部图像的信息,例如,通过简单的连接或完全连接的层。由于视线估计本质上是一项具有挑战性的任务,因此简单的特征拼接操作不利于脸部图像和眼部图像交互建模,忽略了脸部和眼部的内在关系。
技术实现要素:
5.本发明的目的是提供一种自适应视线估计方法、系统、电子设备及存储介质,充分利用脸部和眼部之间内在的特征关系,达到自适应视线估计目的。
6.为实现上述目的,本发明提供了如下方案:
7.第一方面,本发明提供的一种基于多尺度特征融合的自适应视线估计方法,包括:
8.获取目标人员的脸部图像;
9.对所述目标人员的脸部图像进行处理,得到所述目标人员的眼脸位置信息;所述眼脸位置信息包括脸部边界框信息、左眼边界框信息和右眼边界框信息;
10.将目标人员信息输入至自适应视线估计模型,得到目标人员的注视线估计结果;所述目标人员信息包括目标人员的脸部图像和眼脸位置信息;
11.所述自适应视线估计模型为利用第一样本输入数据以及所述第一样本输入数据对应的样本实测结果对基于多尺度特征融合的自适应视线估计网络进行训练,利用眼指导网络对所述基于多尺度特征融合的自适应视线估计网络中的平移参数和缩放参数进行更
新后得到的模型;
12.所述眼指导网络用于采用深度学习算法对所述第一样本输入数据对应的第二样本输入数据进行处理,得到平移参数和缩放参数;
13.所述第一样本输入数据为作为模型训练时所需的脸部图像和眼脸位置信息;所述第二样本输入数据为作为模型训练时所需的左眼图像、右眼图像和眼脸位置信息;所述样本实测结果为作为模型训练时所需的注视线实测结果。
14.可选地,所述自适应视线估计模型的训练过程为:
15.构建样本数据集;所述样本数据集包括多个样本数据;所述样本数据包括第一样本输入数据以及对应的第二样本输入数据和样本实测结果;
16.将第一样本输入数据输入至基于多尺度特征融合的自适应视线估计网络中,得到样本预测结果;
17.利用样本预测结果和样本实测结果计算网络损失值;
18.利用网络损失值对所述基于多尺度特征融合的自适应视线估计网络的网络参数进行更新,利用眼指导网络对更新后的网络参数中的平移参数和缩放参数进行更新,得到更新后的多尺度特征融合的自适应视线估计网络,迭代循环优化,直到迭代次数达到最大迭代次数或者网络损失值小于设定阈值,并将最后一个更新后的多尺度特征融合的自适应视线估计网络确定为自适应视线估计模型。
19.可选地,所述基于多尺度特征融合的自适应视线估计网络包括依次连接的卷积层、无平移参数和缩放参数的全局平均池化层、第一平移缩放层、通道维度拼接层、第一多尺度注意力模块、第二平移缩放层、第二多尺度注意力模块和全连接层;其中,所述第一平移缩放层中的平移参数和缩放参数是由所述眼指导网络确定的;所述第二平移缩放层中的平移参数和缩放参数是由所述眼指导网络确定的;所述全连接层包括第一全连接块和第二全连接块以及第三全连接块;所述第一全连接块用于输入眼脸位置信息,所述第二全连接块用于输入所述第二多尺度注意力模块输出的特征;所述第三全连接块的输入端分别与所述第一全连接块的输出端和所述第二全连接块的输出端;所述卷积层用于输入脸部图像。
20.可选地,所述眼指导网络包括第一分支网络、第二分支网络、第三分支网络、以及与第一分支网络的输出端、第二分支网络的输出端、第三分支网络的输出端均连接的全连接层模块;所述第一分支网络包括依次连接的第一卷积块、通道维度拼接层和全连接层;所述第一卷积块用于输入右眼图像;所述第二分支网络包括依次连接的第二卷积块、交叉视图池化层和全连接层;所述第二卷积块用于输入左眼图像;所述第三分支网络用于输入眼脸位置信息;所述全连接层模块用于输出平移参数和缩放参数。
21.可选地,所述第一多尺度注意力模块的结构和所述第二多尺度注意力模块的结构相同;
22.所述第一多尺度注意力模块包括spc模块、se模块、空间注意力图获取模块以及汇总模块;
23.所述spc模块的输入端用于输入通道维度拼接层输出的特征,所述spc 模块的输出端与所述se模块的输入端连接,所述se模块的第一输出端与所述汇总模块的第一输入端连接,所述se模块的第二输出端与所述空间注意力图获取模块的输入端连接,所述空间注意力图获取模块的输出端与所述汇总模块的第二输入端连接,所述汇总模块的第三输入端
用于输入通道维度拼接层输出的特征;所述汇总模块用于输出带有不同感受野下多尺度信息的特征图。
24.可选地,所述空间注意力图获取模块,用于:
25.对所述se模块输出的特征图进行卷积、全局平均池化以及维度变换,得到第一特征子图和第二特征子图;
26.对所述第一特征子图进行归一化操作后,与第二特征子图进行二维张量相乘,得到二维特征;
27.对二维特征进行维度变换和激活操作,得到空间注意力图。
28.可选地,所述对所述目标人员的脸部图像进行处理,得到目标人员的眼脸位置信息,具体包括:
29.对所述目标人员的脸部图像进行处理,得到目标人员的左眼图像和右眼图像;
30.根据所述目标人员的左眼图像、右眼图像和脸部图像,得到目标人员的眼脸位置信息。
31.第二方面,本发明提供了一种基于多尺度特征融合的自适应视线估计系统,包括:
32.脸部图像获取模块,用于获取目标人员的脸部图像;
33.眼脸位置信息计算模块,用于对所述目标人员的脸部图像进行处理,得到所述目标人员的眼脸位置信息;所述眼脸位置信息包括脸部边界框信息、左眼边界框信息和右眼边界框信息;
34.注视线估计结果预测模块,用于将目标人员信息输入至自适应视线估计模型,得到目标人员的注视线估计结果;所述目标人员信息包括目标人员的脸部图像和眼脸位置信息;
35.所述自适应视线估计模型为利用第一样本输入数据以及所述第一样本输入数据对应的样本实测结果对基于多尺度特征融合的自适应视线估计网络进行训练,利用眼指导网络对所述基于多尺度特征融合的自适应视线估计网络中的平移参数和缩放参数进行更新后得到的模型;
36.所述眼指导网络用于采用深度学习算法对所述第一样本输入数据对应的第二样本输入数据进行处理,得到平移参数和缩放参数;
37.所述第一样本输入数据为作为模型训练时所需的脸部图像和眼脸位置信息;所述第二样本输入数据为作为模型训练时所需的左眼图像、右眼图像和眼脸位置信息;所述样本实测结果为作为模型训练时所需的注视线实测结果。
38.第三方面,本发明提供了一种电子设备,包括存储器及处理器,所述存储器用于存储计算机程序,所述处理器运行所述计算机程序以使所述电子设备执行根据第一方面所述的自适应视线估计方法。
39.第四方面,本发明提供了一种计算机可读存储介质,其存储有计算机程序,所述计算机程序被处理器执行时实现第一方面所述的自适应视线估计方法。
40.根据本发明提供的具体实施例,本发明公开了以下技术效果:
41.本发明通过基于多尺度特征融合的自适应视线估计网络输出视线估计结果,更好地挖掘脸部图像的全局特征。眼指导网络将双眼图像特征融合,提取更专注于注视点的特征参数,动态指导脸部图像的特征提取,从而实现自适应地视线估计。
附图说明
42.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
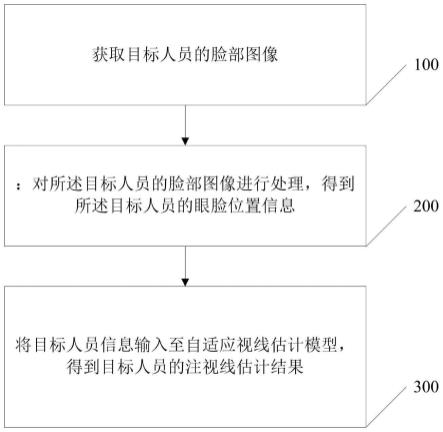
43.图1为本发明基于多尺度特征融合的自适应视线估计方法的流程示意图;
44.图2为本发明基于多尺度特征融合的自适应视线估计网络的结构图;
45.图3为本发明眼指导网络的结构图;
46.图4为本发明多尺度注意力模块的结构图;
47.图5为本发明spc模块的结构图;
48.图6为本发明基于多尺度特征融合的自适应视线估计系统的结构示意图。
具体实施方式
49.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
50.由于脸部图像相比眼部图像来说,具有更丰富的全局信息,而眼部图像则更聚焦于视线落点,为了充分利用脸部和眼部之间内在的特征关系,本发明提供了基于多尺度特征融合的自适应视线估计方法、系统、电子设备及存储介质。
51.为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。
52.实施例一
53.本实施例提供了基于多尺度特征融合的自适应视线估计方法,该实施例主要发明点为:
54.1、脸部特征提取网络作为主干网络输出视线估计结果,并引入多尺度的注意力机制,更好地挖掘脸部图像的全局特征。
55.2、眼部特征提取网络作为指导网络,将双眼图像特征融合,提取更专注于注视点的特征参数,动态指导脸部图像的特征提取,从而实现自适应地视线估计。
56.如图1所示,本实施例提供了基于多尺度特征融合的自适应视线估计方法,具体包括:
57.步骤100:获取目标人员的脸部图像。
58.步骤200:对所述目标人员的脸部图像进行处理,得到所述目标人员的眼脸位置信息;所述眼脸位置信息包括脸部边界框信息、左眼边界框信息和右眼边界框信息。
59.步骤300:将目标人员信息输入至自适应视线估计模型,得到目标人员的注视线估计结果;所述目标人员信息包括目标人员的脸部图像和眼脸位置信息。
60.所述自适应视线估计模型为利用第一样本输入数据以及所述第一样本输入数据对应的样本实测结果对基于多尺度特征融合的自适应视线估计网络进行训练,利用眼指导网络对所述基于多尺度特征融合的自适应视线估计网络中的平移参数和缩放参数进行更
新后得到的模型。
61.所述眼指导网络用于采用深度学习算法对所述第一样本输入数据对应的第二样本输入数据进行处理,得到平移参数和缩放参数。
62.所述第一样本输入数据为作为模型训练时所需的脸部图像和眼脸位置信息;所述第二样本输入数据为作为模型训练时所需的左眼图像、右眼图像和眼脸位置信息;所述样本实测结果为作为模型训练时所需的注视线实测结果。
63.其中,所述自适应视线估计模型的训练过程为:
64.(1)构建样本数据集;所述样本数据集包括多个样本数据;所述样本数据包括第一样本输入数据以及对应的第二样本输入数据和样本实测结果。
65.(2)将第一样本输入数据输入至基于多尺度特征融合的自适应视线估计网络中,得到样本预测结果。
66.(3)利用样本预测结果和样本实测结果计算网络损失值。
67.(4)利用网络损失值对所述基于多尺度特征融合的自适应视线估计网络的网络参数进行更新,利用眼指导网络对更新后的网络参数中的平移参数和缩放参数进行更新,得到更新后的多尺度特征融合的自适应视线估计网络,迭代循环优化,直到迭代次数达到最大迭代次数或者网络损失值小于设定阈值,并将最后一个更新后的多尺度特征融合的自适应视线估计网络确定为自适应视线估计模型。
68.一个示例为:通过以下步骤确定所述自适应视线估计模型的训练过程。
69.步骤1:分别选择gazecapture数据集和mpiifacegaze数据集对模型进行训练和测试。从gazecapture数据集的1400多个样本中(共240多万张脸部图片),按照7:2:1的比例随机划分为训练集、验证集、测试集。训练集用于模型学习图像与注视点之间的映射关系,验证集在训练过程中优化模型,测试集用于评估模型对注视点预测的性能。训练集、验证集与测试集中的图片均无重合。从mpiifacegaze数据集的15个样本中(共37667张脸部图片),选取13个样本为训练集,2个样本为测试集。因为该数据集样本数较少,为了更好的验证模型性能,在mpiifacegaze数据集上进行交叉验证 (所有样本都做一次测试集),进行8次实验取平均值。
70.步骤2:根据数据集提供的眼框坐标和脸框坐标,对gazecapture数据集和mpiifacegaze数据集中的脸部图片进行预处理,裁剪出左右眼图像并得到左右眼图像相对于脸部图像的位置信息,将脸部图像尺寸处理为 224*224*3,左右眼图像处理为112*112*3(分别代表图像的长,宽,rgb 三通道数),像素值从[0,255]归一化到[0,1]区间内。
[0071]
步骤3:将上述预处理后的图像输入基于多尺度特征融合的自适应视线估计网络进行训练,基于多尺度特征融合的自适应视线估计网络(即脸部特征提取网络)的结构如图2所示,眼指导网络的结构如图3所示。
[0072]
脸部特征提取网络的输入包括,脸部图像、脸部边界框信息及左右眼边界框信息;眼指导网络的输入为左眼图像、右眼图像、脸部边界框信息及左右眼边界框信息。
[0073]
脸部特征提取网络作为主干网络,输入为脸部图像,脸部特征由多层卷积层进行提取,由平移参数(pa参数)和缩放参数(pm参数)进行自适应调整后,输入多尺度注意力模块,最后由全连接层与眼脸位置信息(左右眼图像的边界框的坐标信息和脸部图像的边界框的坐标信息)拼接,输出注视点坐标;眼指导网络将左右眼图像和眼脸位置信息输入,由
卷积层进行特征提取后,将特征块进行融合,最终通过全连接层输出pa,pm两个参数,动态指导脸部特征提取。
[0074]
所述基于多尺度特征融合的自适应视线估计网络包括依次连接的卷积层、无平移参数和缩放参数的全局平均池化层、第一平移缩放层、通道维度拼接层、第一多尺度注意力模块、第二平移缩放层、第二多尺度注意力模块和全连接层;其中,所述第一平移缩放层中的平移参数和缩放参数是由所述眼指导网络确定的;所述第二平移缩放层中的平移参数和缩放参数是由所述眼指导网络确定的;所述全连接层包括第一全连接块和第二全连接块以及第三全连接块;所述第一全连接块用于输入眼脸位置信息,所述第二全连接块用于输入所述第二多尺度注意力模块输出的特征;所述第三全连接块的输入端分别与所述第一全连接块的输出端和所述第二全连接块的输出端;所述卷积层用于输入脸部图像。
[0075]
脸部图像由卷积层特征提取后,将低维特征和高维特征中包含缩放操作和平移操作的归一化层替换成不带缩放参数和平移参数的全局平均池化层,使用眼指导网络生成的两个参数代替平移参数和缩放参数,实现自适应地重新提取脸部特征。之后将调整后的低维特征和高维特征按通道维度拼接,并输入多尺度注意力模块,有效地利用不同尺度特征的空间信息,同时建立特征各通道之间的依赖关系,更好地捕获面部图像的全局信息。最后再经过一次自适应调整和多尺度注意力模块,由全连接层与眼脸位置信息拼接输出注视点坐标。其中,图2中的gn(.)表示无平移参数和缩放参数的全局平均池化层,stack表示通道维度拼接层,fc表示全连接层。
[0076]
所述眼指导网络包括第一分支网络、第二分支网络、第三分支网络、以及与第一分支网络的输出端、第二分支网络的输出端、第三分支网络的输出端均连接的全连接层模块;所述第一分支网络包括依次连接的第一卷积块、通道维度拼接层和全连接层;所述第一卷积块用于输入右眼图像;所述第二分支网络包括依次连接的第二卷积块、交叉视图池化层和全连接层;所述第二卷积块用于输入左眼图像;所述第三分支网络用于输入眼脸位置信息;所述全连接层模块用于输出平移参数和缩放参数。
[0077]
眼指导网络:因为左右眼的形状和结构相似,所以对左右眼图像进行特征融合。将右眼图像和进行水平翻转后的左眼图像输入网络模型,将低维特征和高维特征按通道维度拼接,从较低层提取的特征图保留了更多的空间信息,而从较高层提取的特征图具有更强的表示能力。之后,分别将左右眼融合的特征进行按通道维度拼接和交叉视图池化操作,最后与脸眼位置信息经全连接层,输出pa、pm两个参数,对脸部特征提取进行动态指导调整。图 3中的cv-pool为交叉视图池化层。
[0078]
所述第一多尺度注意力模块的结构和所述第二多尺度注意力模块的结构相同。现以第一多尺度注意力模块为例进行说明。
[0079]
所述第一多尺度注意力模块包括spc模块、se模块、空间注意力图获取模块以及汇总模块;所述spc模块的输入端用于输入通道维度拼接层输出的特征,所述spc模块的输出端与所述se模块的输入端连接,所述se模块的第一输出端与所述汇总模块的第一输入端连接,所述se模块的第二输出端与所述空间注意力图获取模块的输入端连接,所述空间注意力图获取模块的输出端与所述汇总模块的第二输入端连接,所述汇总模块的第三输入端用于输入通道维度拼接层输出的特征;所述汇总模块用于输出带有不同感受野下多尺度信息的特征图。
[0080]
所述空间注意力图获取模块,用于:
[0081]
对所述se模块输出的特征图进行卷积、全局平均池化以及维度变换,得到第一特征子图和第二特征子图;
[0082]
对所述第一特征子图进行归一化操作后,与第二特征子图进行二维张量相乘,得到二维特征;
[0083]
对二维特征进行维度变换和激活操作,得到空间注意力图。
[0084]
如图4和图5所示,spc模块将输入特征x(大小:c
×h×
w)进行不同卷积核大小的卷积(卷积核大小分别为:3
×
3,5
×
5,7
×
7,9
×
9。卷积后特征大小:c/4
×h×
w),以获取不同尺度的感受野,提取不同尺度的信息,之后在通道维度上拼接。再通过se模块(在通道维度进行全局平均池化操作,压缩为c
×1×
1的向量)提取每组的通道的加权值,最后进行softmax归一化后与特征在通道维度相乘,从而对通道加权。重新缩放的特征图xc聚焦于有用的通道,但同一通道中的像素仍共享相同的权重。因此,在空间维度进一步基于xc计算。
[0085]
如图所示,将特征xc送入1
×
1的卷积层,进行全局平均池化和维度变换,分别得到特征图q(1
×
c/2)、v(c/2
×
hw)。对q进行softmax归一化后与v进行二维张量相乘,得到1
×
hw的二维特征,再经过维度变换和 sigmoid激活函数得到空间注意力图as(1
×h×
w)。最后,将as和xc空间维度进行矩阵相乘后,与原始输入特征x相加,最终输出带有不同感受野下多尺度信息的特征图。
[0086]
实验设置:在高性能计算平台上完成实验:系统windows10,cpu amd5800x,gpu rtx3080,内存32g。
[0087]
自适应的视线估计方法
[0088]
该方法充分利用人脸和眼睛之间的特征关系,脸部特征提取网络作为主干网络输出视线估计结果,眼睛特征提取网络作为指导网络,将双眼图像特征融合,提取更专注于注视点的特征参数,动态指导面部的特征提取,从而实现自适应地视线估计。
[0089]
多尺度注意力机制
[0090]
针对全脸图像包含更丰富的全局信息,设计了多尺度注意力模块,有效地利用不同尺度特征的空间信息,同时建立特征各通道之间的依赖关系,更好地捕获面部图像的全局信息。
[0091]
表1:对比实验表
[0092][0093]
实验结果:在mpiifacegaze数据集和gazecapture数据集上进行了对比实验,与主流的基于外观的视线估计方法对比,我们提出的自适应的视线估计方法达到了最优的性能。mpiifacegaze数据集我们提出的方法达到了 3.8cm的误差;gazecapture数据集采集设备分为手机和平板电脑,我们的方法分别达到了2.68cm和3.14cm的误差。
[0094]
实施例二
[0095]
为了执行上述实施例一对应的方法,以实现相应的功能和技术效果,下面提供一种基于多尺度特征融合的自适应视线估计系统。
[0096]
如图6所示,本实施例提供的基于多尺度特征融合的自适应视线估计系统,包括:
[0097]
脸部图像获取模块1,用于获取目标人员的脸部图像;
[0098]
眼脸位置信息计算模块2,用于对所述目标人员的脸部图像进行处理,得到所述目标人员的眼脸位置信息;所述眼脸位置信息包括脸部边界框信息、左眼边界框信息和右眼边界框信息;
[0099]
注视线估计结果预测模块3,用于将目标人员信息输入至自适应视线估计模型,得到目标人员的注视线估计结果;所述目标人员信息包括目标人员的脸部图像和眼脸位置信息;
[0100]
所述自适应视线估计模型为利用第一样本输入数据以及所述第一样本输入数据对应的样本实测结果对基于多尺度特征融合的自适应视线估计网络进行训练,利用眼指导网络对所述基于多尺度特征融合的自适应视线估计网络中的平移参数和缩放参数进行更新后得到的模型;
[0101]
所述眼指导网络用于采用深度学习算法对所述第一样本输入数据对应的第二样本输入数据进行处理,得到平移参数和缩放参数;
[0102]
所述第一样本输入数据为作为模型训练时所需的脸部图像和眼脸位置信息;所述第二样本输入数据为作为模型训练时所需的左眼图像、右眼图像和眼脸位置信息;所述样本实测结果为作为模型训练时所需的注视线实测结果。
[0103]
实施例三
[0104]
本发明实施例提供一种电子设备包括存储器及处理器,该存储器用于存储计算机
程序,该处理器运行计算机程序以使电子设备执行实施例一的自适应视线估计方法。
[0105]
可选地,上述电子设备可以是服务器。
[0106]
另外,本发明实施例还提供一种计算机可读存储介质,其存储有计算机程序,该计算机程序被处理器执行时实现实施例一的自适应视线估计方法。
[0107]
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的系统而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
[0108]
本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处。综上所述,本说明书内容不应理解为对本发明的限制。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1