一种数据处理方法、装置、设备、存储介质及产品与流程
本技术涉及计算机,具体涉及一种数据处理方法、一种数据处理装置、一种计算机设备、一种计算机可读存储介质及一种数据处理产品。
背景技术:
1、随着科技研究的进步,人工智能技术飞速发展,并已经被广泛应用在各个领域;例如,人工智能围棋、视频处理、文本处理、信号处理、医疗检测等等。针对不同的应用领域,可以采用不同的训练数据对相应的模型进行训练,来得到该领域的人工智能模型。研究发现,虽然训练后的模型可以在一定程度上为人们的生产和生活提供便捷,但在模型训练的过程中,常常出现模型收敛速度较慢的情况。
技术实现思路
1、本技术实施例提供了一种数据处理方法、装置、设备、计算机可读存储介质及产品,能够提高模型的收敛速度。
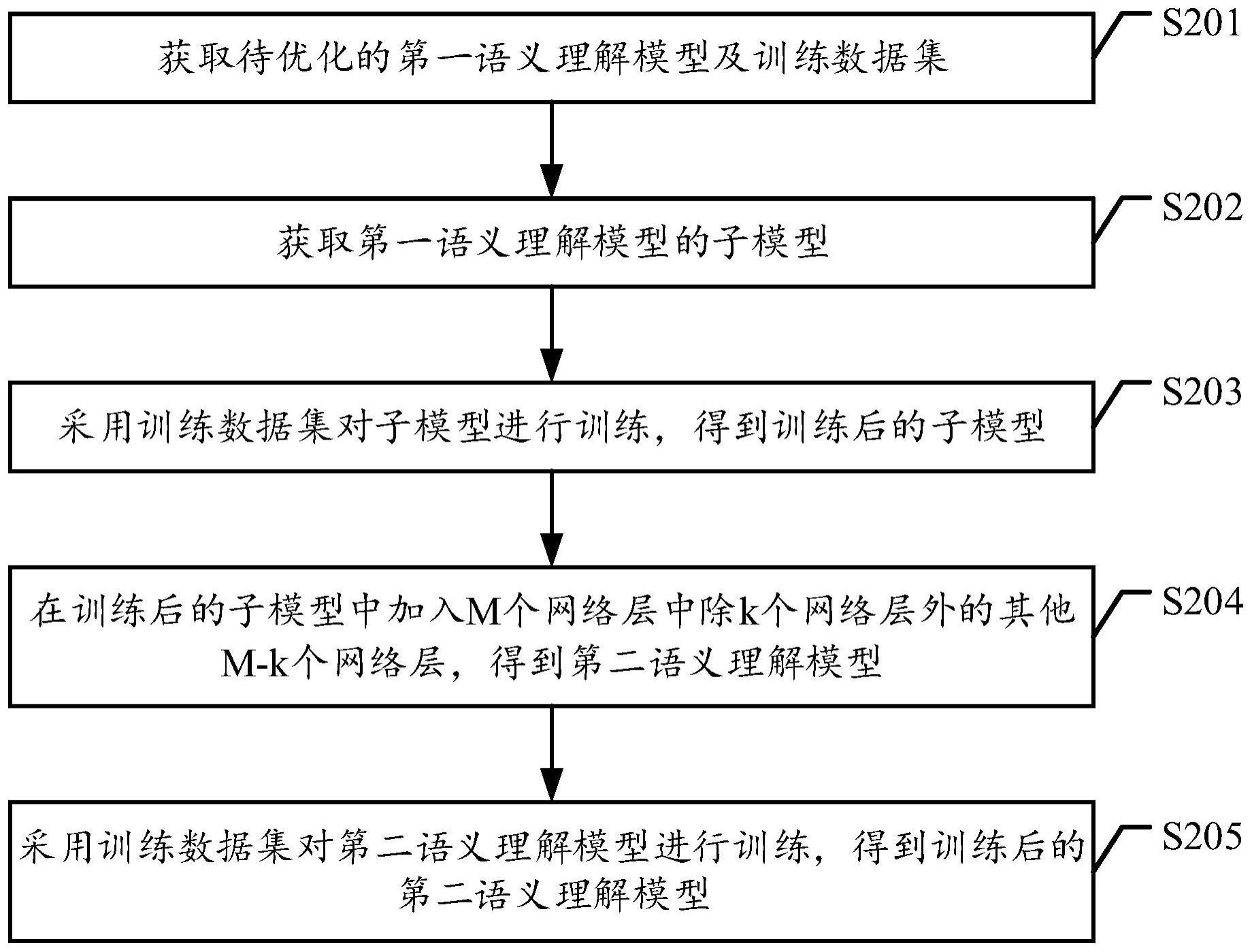
2、一方面,本技术实施例提供了一种数据处理方法,包括:
3、获取待优化的第一语义理解模型及训练数据集;待优化的第一语义理解模型包括m个网络层,m为大于1的整数;训练数据集包含p条自然语言样本,p为正整数;
4、获取第一语义理解模型的子模型,子模型包括m个网络层中的k个网络层,k为大于1且小于m的整数;
5、采用训练数据集对子模型进行训练,得到训练后的子模型;
6、在训练后的子模型中加入m个网络层中除k个网络层外的其他m-k个网络层,得到第二语义理解模型;
7、采用训练数据集对第二语义理解模型进行训练,训练后的第二语义理解模型用于对自然语言样本进行语义理解处理。
8、一方面,本技术实施例提供了一种数据处理装置,该数据处理装置包括:
9、获取单元,用于获取待优化的第一语义理解模型及训练数据集;待优化的第一语义理解模型包括m个网络层,m为大于1的整数;训练数据集包含p条自然语言样本,p为正整数;
10、以及用于获取第一语义理解模型的子模型,子模型包括m个网络层中的k个网络层,k为大于1且小于m的整数;
11、处理单元,用于采用训练数据集对子模型进行训练,得到训练后的子模型;
12、以及用于在训练后的子模型中加入m个网络层中除k个网络层外的其他m-k个网络层,得到第二语义理解模型;
13、以及用于采用训练数据集对第二语义理解模型进行训练,训练后的第二语义理解模型用于对自然语言样本进行语义理解处理。
14、在一种实施方式中,处理单元用于,采用训练数据集对第二语义理解模型进行训练,具体用于:
15、在通过训练数据集对第二语义理解模型进行训练的过程中,对m-k个网络层的参数进行优化,得到训练后的第二语义理解模型;
16、其中,第二语义理解模型包含的训练后的子模型中的k个网络层的参数在训练过程中保持不变。
17、在一种实施方式中,第一语义理解模型还包括输出层,子模型包括输出层;
18、第二语义理解模型包含的训练后的子模型中的输出层的参数,在第二语义理解模型的训练过程中保持不变;
19、训练后的第二语义理解模型的第k个网络层和第m个网络层与输出层连接。
20、在一种实施方式中,k个网络层为m个网络层中的前k个网络层,且k个网络层的排列顺序与m个网络层中的前k个网络层的排列顺序匹配;
21、m-k个网络层分为p次加入训练后的子模型,每次加入至少一个网络层,p为小于等于m-k的正整数;
22、第i+1次加入的网络层,是在中间模型完成训练后加入中间模型的,中间模型是训练后的子模型在第i次加入网络层后得到的,i为小于p的正整数;
23、中间模型的训练过程包括通过训练数据集对第i次加入的网络层进行训练;
24、第i次加入的网络层与训练后的子模型的输出层连接。
25、在一种实施方式中,处理单元还用于:
26、在训练后的第二语义理解模型的输出层之后加入置信度预测模块,得到更新后的第二语义理解模型;
27、其中,置信度预测模块的数量为至少一个,每个置信度预测模块关联第k+1个网络层至第m个网络层中的一个网络层,与目标网络层关联的置信度预测模块用于预测输出层的输出结果相较于目标网络层对应的输出结果的置信度,目标网络层为第k+1个网络层至第m个网络中的任一个网络层。
28、在一种实施方式中,与目标网络层关联的置信度预测模块的训练过程包括:
29、调用与目标网络层关联的置信度预测模块对模块训练数据进行置信度分析,得到模块训练数据的预测置信度;
30、获取模块训练数据的校准置信度;
31、基于校准置信度和预测置信度之间的损失值,对与目标网络层关联的置信度预测模块进行优化训练,得到优化后的与目标网络层关联的置信度预测模块。
32、在一种实施方式中,模块训练数据为至少一个样本特征组成的样本特征序列;处理单元用于,调用与目标网络层关联的置信度预测模块对模块训练数据进行置信度分析,得到模块训练数据的预测置信度,具体用于:
33、调用与目标网络层关联的置信度预测模块对每个样本特征的线性处理结果进行激活处理,得到每个样本特征的权重;
34、调用与目标网络层关联的置信度预测模块对各个样本特征的权重进行加权平均处理,得到模块训练数据的全局特征;
35、将模块训练数据的全局特征的线性处理结果,确定为模块训练数据的预测置信度;
36、其中,每个样本特征的维度是基于模块训练数据中样本特征的数量,模块训练数据中样本特征的最大序列长度和输出层的输出通道数计算得到的。
37、在一种实施方式中,模块训练数据包括调用更新后的第二语义理解模型的输出层,基于第s个网络层输出的待处理数据的特征,得到的输出结果,s为大于k小于m的整数;处理单元用于,获取模块训练数据的校准置信度,具体用于:
38、获取目标网络层对应的输出结果,目标网络层对应的输出结果为目标网络层对应的预测结果是调用更新后的第二语义理解模型的输出层,基于目标网络层输出的待处理数据的特征,得到的输出结果;
39、基于目标网络层对应的输出结果和模块训练数据的损失值,计算模块训练数据的校准置信度。
40、在一种实施方式中,处理单元还用于:
41、调用更新后的第二语义理解模型的前k个网络层对待处理的自然语言进行语义理解处理,得到待处理的自然语言的语义理解结果;
42、通过目标网络层关联的置信度预测模块对待处理的自然语言的语义理解结果进行置信度分析,得到待处理的自然语言的语义理解结果的置信度;
43、基于置信度与网络层数量的对应关系,确定处理待处理的自然语言所需的网络层数量q,q为大于等于k,且小于等于m的整数。
44、在一种实施方式中,处理单元还用于:
45、采用训练后的第二语义理解模型中的q个网络层对待处理的自然语言进行语义理解处理,得到待处理的自然语言的语义理解结果;以及,
46、基于待处理的自然语言的语义理解结果,输出目标内容;
47、其中,语义理解处理包括以下至少一种:摘要提取、文本分类、文本翻译、关键词标记、文本解释;目标内容包括以下至少一项:待处理的自然语言的语义、待处理的自然语言的多媒体文件、待处理的自然语言中的关键字、待处理的自然语言的类型、待处理的自然语言的摘要、待处理的自然语言的翻译结果。
48、在一种实施方式中,处理单元用于,采用训练数据集对子模型进行训练,得到训练后的子模型,具体用于:
49、将p条自然语言样本划分为至少一个集合,每个集合包含至少一条自然语言样本,每个集合中各条自然语言样本之间的序列长度差小于长度阈值;
50、调用子模型分别对每个集合进行预测处理,得到每个集合对应的预测结果,并将各个集合对应的预测结果确定为训练数据集的预测结果;
51、基于训练数据集的校准数据和预测结果之间的差异,对子模型进行优化,得到训练后的子模型。
52、在一种实施方式中,第一语义理解模型包含原始词表,原始词表包括至少一个分词和每个分词的嵌入特征;处理单元还用于:
53、获取训练数据集对应的子词表,子词表中的分词包含于原始词表;
54、基于子词表中的每个分词在子词表中的位置和在原始词表中的位置,确定该分词的映射关系;
55、根据子词表中的每个分词的映射关系和该分词在原始词表的嵌入特征,确定子词表中各个分词的嵌入特征;
56、将原始词表替换为子词表。
57、在一种实施方式中,处理单元还用于:
58、获取训练后的子词表;
59、根据训练后的子词表中各个分词的嵌入特征和每个分词的映射关系,更新该分词在原始词表的嵌入特征;
60、将训练后的子词表替换为更新后的原始词表。
61、在一种实施方式中,处理单元用于,获取训练数据集对应的子词表,具体用于:
62、按照原始词表对训练数据集中的自然语言样本进行划分,得到第一分词集合,第一分词集合包括至少一个分词;
63、从原始词表中获取第一分词集合中每个分词关联的至少一个分词,得到第二分词集合;
64、获取第三分词集合,第三分词集合包含至少一个预设的分词;
65、对第一分词集合,第二分词集合和第三分词集合进行合并,得到训练数据集对应的子词表。
66、在一种实施方式中,m个网络层包括至少一个编码网络层,每个编码网络层的输入特征包括第一向量和第二向量;每个编码网络层确定输入特征的注意力的过程包括:
67、对第一向量和第二向量分别进行归一化处理,得到第一归一化结果和第二归一化结果;
68、对第一归一化结果和第二归一化结果进行内积计算,得到内积结果;
69、获取第一参数,并对第一参数与内积结果的积进行归一化处理,得到输入特征的注意力;第一参数是通过训练数据集训练得到的。
70、在一种实施方式中,m个网络层包括至少一个编码网络层;每个编码网络层的残差连接是基于输入特征,以及输入特征的非线性变换与第二参数的积计算得到的;第二参数是通过训练数据集训练得到的。
71、相应地,本技术提供了一种计算机设备,该计算机设备包括:
72、存储器,存储器中存储有计算机程序;
73、处理器,用于加载计算机程序实现上述数据处理方法。
74、相应地,本技术提供了一种计算机可读存储介质,计算机可读存储介质存储有计算机程序,该计算机程序适于由处理器加载并执行上述数据处理方法。
75、相应地,本技术提供了一种计算机程序产品或计算机程序,该计算机程序产品或计算机程序包括计算机指令,该计算机指令存储在计算机可读存储介质中。计算机设备的处理器从计算机可读存储介质读取该计算机指令,处理器执行该计算机指令,使得该计算机设备执行上述数据处理方法。
76、本技术实施例中,获取包括m个网络层的第一语义理解模型及训练数据集,并获取包括m个网络层中的k个网络层的第一语义理解模型的子模型,采用训练数据集对子模型进行训练,得到训练后的子模型;在训练后的子模型中加入m个网络层中除k个网络层外的其他m-k个网络层,得到第二语义理解模型;采用训练数据集对第二语义理解模型进行训练,训练后的第二语义理解模型用于对自然语言样本进行语义理解处理。可见,通过对第一语义理解模型中的网络层进行分批次的训练,可以减少每次训练时训练数据集的迭代次数,进而提高模型的收敛速度。
- 还没有人留言评论。精彩留言会获得点赞!