一种基于网络社交平台的热点事件知识图谱链接估计方法
1.本发明属于网络社交平台预测技术领域,具体涉及一种基于网络社交平台的热点事件知识图谱链接估计方法。
背景技术:
2.随着语义搜索、智能匹配等网络社交平台技术的深入发展,热点事件知识图谱作为结构化的语义知识库已经成为了一种重要的网络舆情表达形式。由于热点事件的知识图谱的数据量巨大,人工验证己无法保证知识图谱的完整性,链接评估也成为热点事件的知识图谱补全的重要任务之一。链接评估是评估已经存在热点事件知识图谱的实体之间缺少关系的任务,即通过热点事件知识图谱的网络结构中已知的实体和实体之间已有的关联关系,从而来预测网络结构中无边相连的两个实体间存在连接的可能性。目前大多数估计方法只能在混合时间信息后识别实体,但不能分别识别实体和时间。此外,大多数方法忽略了时间集的完整性和相关性,导致对不同时间跨度的数据集使用统一的时间单位。而网络热点事件存在着较强的时间依赖,在构建本地热点事件知识图谱的同时,需要对事件触发设备,设备属性以及设备漏洞进行建模,形成热点事件知识图谱。因此,目前迫切需要一种准确的估计方法,对热点事件进行估计。
技术实现要素:
3.本发明的目的在于提供一种具有时间效用和热点事件属性补效果的基于网络社交平台的热点事件知识图谱链接估计方法。
4.本发明的目的是这样实现的:
5.一种基于网络社交平台的热点事件知识图谱链接估计方法,包括如下步骤:
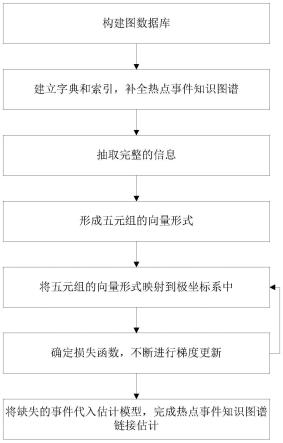
6.(1)获取热点事件相关领域的历史数据,进行数据清洗、信息抽取、信息整合、构建图数据库;
7.(2)通过数据预处理建立字典和索引,对数据进行训练,得到补全模型,补全热点事件知识图谱;
8.(3)从热点事件安全知识图谱中抽取完整的信息,分别采集热点事件的头实体u和尾实体e,头实体和尾实体之间的关系g,事件的开始时间ηf和结束时间ηr,实体的时间跨度[ηf,ηr],形成以热点事件为基础的五元组集合(u,e,g,[ηf,ηr]);头实体u和尾实体e属于实体集r,头实体和尾实体之间的关系g属于关系集e;
[0009]
(4)以向量形式均匀初始化所有实体、关系、时间戳,形成五元组的向量形式(u,e,g,[ηf,ηr]);
[0010]
(5)将五元组的向量形式映射到极坐标系中,分为模长部分和角部分;
[0011]
模长部分以向量方式表示为(uz,ez,gz,[η
f,z
,η
r,z
]),通过约束条件映射函数]),通过约束条件映射函数将时间无关事件转换为时间约束事件;通过模长奖励函数
确定模长部分得分;角标z代表向量的模长分量;
[0012]
角部分分量以向量方式表示为(un,en,gn,[η
f,n
,η
r,n
]),通过时间约束u
η,n
=mod3π(un+η
f,n
),g
η,n
=mod5π(gn+η
r,n
)区分具有相同模量的时间约束事件;通过角奖励函数s
η,n
=||sin((gn+e
n-u
η,n
)/3||1确定角部分得分;角标n代表向量的角分量;
[0013]
评分函数为s
η
[(u,e)]=η1s
η,z
+η2s
η,n
,η1、η2为用来调整两种分量嵌入的比例;
[0014]
(6)确定损失函数,不断进行梯度更新,得到最终的关系信息向量;
[0015]
(7)将缺失的事件代入估计模型,根据现有实体集输出所有候选实体补全当前事件的概率,并按照需求,选择相应概率的候选实体完成热点事件知识图谱链接估计。
[0016]
所述的步骤(1)包括:
[0017]
(1.1)采用网络爬虫、公开数据集的方式获取热点事件相关领域的原始数据;
[0018]
(1.2)对原始数据进行数据清洗,删除无效数据;所述的无效数据包括不相关数据和重复数据;
[0019]
(1.3)从完成清洗的数据中抽取构建知识图谱所需的实体信息、关系信息、属性信息、属性值信息以及实体之间的关系;
[0020]
(1.4)对抽取的构建知识图谱所需的实体信息整合成<头实体-关系-尾实体><开始时间-事件跨度-结束时间>形式的三元组,存放到图数据库中,完成热点事件领域的知识图谱的构建。
[0021]
所述的步骤(2)包括:
[0022]
(2.1)对热点事件的原始数据进行数据清洗,得到需要的语料;
[0023]
(2.2)对语料依次进行格式化、分词、稀疏词处理、构建词典、建立索引和词向量训练;
[0024]
建立索引时,将每个词语映射成定长的向量,并通过向量间的距离表示词之间的相关程度;设某词在词典中索引位置为q,中心词j
p
的向量iv在词典中索引为p,背景词jb的向量hv词典中索引为b,条件概率为
[0025][0026]
词典索引集合v={0,1,
…
,|v|-1},当背景词为m时,词向量训练模型的似然函数为:
[0027][0028]
(2.3)对(2.2)中得到的数据按照设定比例划分训练集和验证集,训练补全模型,直到模型对给定输入的残缺的三元组信息,通过模型输出得到相关联的结果,补全三元组,构建成热点事件知识图谱;
[0029]
在训练补全模型过程中,选择词粒度作为单元特征,采用jieba进行分词,使用负采样将需要输出的词语作为正样本,在除了正样本外的剩余词语中采用噪声分布ca(j)选取负样本,通过损失函数评估预测结果和正确值之间的误差,损失函数为:
[0030][0031]
其中,jo为正样本,为正样本对应参数的转置,f为解码器的隐藏状态,j
neg
为负样本的集合,ζ是sigmoid函数;
[0032]
采用lstm网络作为补全模型。
[0033]
所述的步骤(6)包括:
[0034]
(6.1)确定损失函数:
[0035][0036]
为第i个负五元组,β为固定边界,σ为sigmoid函数;
[0037]
(6.2)计算链接预测概率得到,其中ξ为温度采样;
[0038]
(6.3)重复步骤(5)到步骤(6),持续更新五元组的评分函数,得到概率分布,直到遍历该搜索任务中全部的五元组,完成训练,生成热点事件知识图谱链接估计模型。
[0039]
本发明的有益效果在于:首先本发明针对热点事件知识图谱中可能存在的元组关系缺失或者知识图谱规模较小等问题,从算法逻辑角度构建神经网络模型,将知识图谱和神经网络模型融合,将知识图谱中相近的实体和关系或者知识图谱中缺失的信息作为模型的输入,利用神经网络模型的输出更新存储到图数据库中达到知识图谱自动补全和更新的目的,可以为知识图谱的后续操作提供支撑。
[0040]
此外,本发明将知识图谱时间格式统一为开始时间和结束时间,通过时序知识图谱嵌入模型时间变化表示为极坐标形式,解决了知识图谱的时间格式不一致和重复嵌入的问题;采用极坐标系统中映射嵌入模型,使用系数和角度来区分不同时间约束实体的嵌入,以避免在单一维度中嵌入产生相似的时间约束实体,以解决时序嵌入的相似性问题。最后通过将热点事件分割成五元组并映射到极坐标,使本发明相比于传统方法更加充分的捕捉事件和关系之间的交互信息,从而达到更准确的链接估计效果。
附图说明
[0041]
图1为本发明的流程示意图;
[0042]
图2为本发明所采用的知识图谱信息节点实例图。
具体实施方式
[0043]
下面结合附图对本发明做进一步描述。
[0044]
一种基于网络社交平台的热点事件知识图谱链接估计方法,包括如下步骤:
[0045]
(1)获取热点事件相关领域的历史数据,进行数据清洗、信息抽取、信息整合、构建图数据库;
[0046]
(1.1)采用网络爬虫、公开数据集的方式获取热点事件相关领域的原始数据;
[0047]
(1.2)对原始数据进行数据清洗,删除无效数据;所述的无效数据包括不相关数据
和重复数据;
[0048]
(1.3)从完成清洗的数据中抽取构建知识图谱所需的实体信息、关系信息、属性信息、属性值信息以及实体之间的关系;
[0049]
(1.4)对抽取的构建知识图谱所需的实体信息整合成《头实体-关系-尾实体》《开始时间-事件跨度-结束时间》形式的三元组,存放到图数据库中,完成热点事件领域的知识图谱的构建;
[0050]
(2)通过数据预处理建立字典和索引,对数据进行训练,得到补全模型,补全热点事件知识图谱;
[0051]
(2.1)对热点事件的原始数据进行数据清洗,得到需要的语料;
[0052]
(2.2)对语料依次进行格式化、分词、稀疏词处理、构建词典、建立索引和词向量训练;
[0053]
建立索引时,将每个词语映射成定长的向量,并通过向量间的距离表示词之间的相关程度;设某词在词典中索引位置为q,中心词j
p
的向量iv在词典中索引为p,背景词jb的向量hv词典中索引为b,条件概率为
[0054][0055]
词典索引集合v={0,1,
…
,|v|-1},当背景词为m时,词向量训练模型的似然函数为:
[0056][0057]
(2.3)对(2.2)中得到的数据按照设定比例划分训练集和验证集,训练补全模型,直到模型对给定输入的残缺的三元组信息,通过模型输出得到相关联的结果,补全三元组,构建成热点事件知识图谱;
[0058]
在训练补全模型过程中,选择词粒度作为单元特征,采用jieba进行分词,使用负采样将需要输出的词语作为正样本,在除了正样本外的剩余词语中采用噪声分布ca(j)选取负样本,通过损失函数评估预测结果和正确值之间的误差,损失函数为:
[0059][0060]
其中,jo为正样本,为正样本对应参数的转置,f为解码器的隐藏状态,j
neg
为负样本的集合,ζ是sigmoid函数;
[0061]
采用lstm网络作为补全模型;
[0062]
相比于现有技术,本发明针对热点事件知识图谱中可能存在的元组关系缺失或者知识图谱规模较小等问题,从算法逻辑角度构建神经网络模型,将知识图谱和神经网络模型融合,将知识图谱中相近的实体和关系或者知识图谱中缺失的信息作为模型的输入,利用神经网络模型的输出更新存储到图数据库中达到知识图谱自动补全和更新的目的,可以为知识图谱的后续操作提供支撑
[0063]
(3)从热点事件安全知识图谱中抽取完整的信息,分别采集热点事件的头实体u和
尾实体e,头实体和尾实体之间的关系g,事件的开始时间ηf和结束时间ηr,实体的时间跨度[ηf,ηr],形成以热点事件为基础的五元组集合(u,e,g,[ηf,ηr]);头实体u和尾实体e属于实体集r,头实体和尾实体之间的关系g属于关系集e;
[0064]
(4)以向量形式均匀初始化所有实体、关系、时间戳,形成五元组的向量形式(u,e,g,[ηf,ηr]);
[0065]
(5)将五元组的向量形式映射到极坐标系中,分为模长部分和角部分;
[0066]
模长部分以向量方式表示为(uz,ez,gz,[η
f,z
,η
r,z
]),通过约束条件映射函数]),通过约束条件映射函数将时间无关事件转换为时间约束事件;通过模长奖励函数将时间无关事件转换为时间约束事件;通过模长奖励函数确定模长部分得分;角标z代表向量的模长分量;
[0067]
角部分分量以向量方式表示为(un,en,gn,[η
f,n
,η
r,n
]),通过时间约束u
η,n
=mod3π(un+η
f,n
),g
η,n
=mod5π(gn+η
r,n
)区分具有相同模量的时间约束事件;通过角奖励函数s
η,n
=||sin((gn+e
n-u
η,n
)/3||1确定角部分得分;角标n代表向量的角分量;
[0068]
评分函数为s
η
[(u,e)]=η1s
η,z
+η2s
η,n
,η1、η2为用来调整两种分量嵌入的比例;
[0069]
(6)确定损失函数,不断进行梯度更新,得到最终的关系信息向量;
[0070]
(6.1)确定损失函数:
[0071][0072]
为第i个负五元组,β为固定边界,σ为sigmoid函数;
[0073]
(6.2)计算链接预测概率得到,其中ξ为温度采样;
[0074]
(6.3)重复步骤(5)到步骤(6),持续更新五元组的评分函数,得到概率分布,直到遍历该搜索任务中全部的五元组,完成训练,生成热点事件知识图谱链接估计模型;
[0075]
(7)将缺失的事件代入估计模型,根据现有实体集输出所有候选实体补全当前事件的概率,并按照需求,选择相应概率的候选实体完成热点事件知识图谱链接估计。
[0076]
本发明将知识图谱时间格式统一为开始时间和结束时间,通过时序知识图谱嵌入模型时间变化表示为极坐标形式,解决了知识图谱的时间格式不一致和重复嵌入的问题;采用极坐标系统中映射嵌入模型,使用系数和角度来区分不同时间约束实体的嵌入,以避免在单一维度中嵌入产生相似的时间约束实体,以解决时序嵌入的相似性问题。最后通过将热点事件分割成五元组并映射到极坐标,使本发明相比于传统方法更加充分的捕捉事件和关系之间的交互信息,从而达到更准确的链接估计效果。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1