一种面向大数据平台的远程缓存替换方法及装置
1.本发明涉及互联网技术领域,尤其涉及一种面向大数据平台的远程缓存替换方法及装置。
背景技术:
2.随着互联网的深入发展,互联网上的数据呈现出类型多样化,大小海量化的趋势。为了应对新型数据特点带来的挑战,大数据平台架构设计复杂度与日俱增。现代大数据平台系统常常划分为计算层和数据库存储层。计算层负责建立多主机计算节点,将作业拆分为多个任务并行计算。例如mapreduce,spark和flink等热门分布式计算引擎。数据库存储层常常由多种不同类型的数据库作为存储组件,构建异构存储体系。例如文档型数据放入mongodb数据库,关系型数据放入mysql数据库,大文件类型放入分布式文件系统hdfs,小文件放入hbase数据库。如图1所示,用户通过访问计算层建立工作任务。在用户访问数据时,通过路由网络向数据库发起查询请求。由于数据库请求带来较大的资源开销,当用户多次访问相同的数据时,查询的数据结果将被存储到应用缓存层,以便后续访问时直接读取。应用缓存层是一块由内存构建的存储区域,常见的缓存架构有本地缓存和远程缓存,本地缓存将数据存储在本地节点服务器,能够极快的响应数据查询请求。但是,本地缓存在不同主机之间无法共享缓存数据,存储资源有限且不具有横向扩展能力。远程缓存将数据存储在缓存服务器上,数据访问通过网络远程访问缓存数据结果,有效扩展缓存容量且实现数据共享能力。redis、apach ignite、ehcache等分布式缓存解决方案提供了一整套高可用远程访问接口,被许多应用程序当做远程缓存服务组件。然而,这些分布式缓存解决方案缺少面向大数据平台的远程缓存替换策略。
3.实践证明,缓存替换优化策略是降低作业执行时间的有效路径。发明人从缓存数据权重生成、缓存替换算法方面深入调研,总结得到目前面向大数据平台的远程缓存替换策略研究主要面临以下挑战:
4.第一,缓存数据淘汰权重通常以用户访问数据的频率为度量标准,优先将频繁访问的数据保留内存里。然而其他代价,例如查询响应时间、数据大小不同程度地影响着缓存命中率。在大数据场景下,缓存数据出现新的特点,包括中间计算结果数据量大,查询响应时间长,占用缓存空间大。因此,查询响应时间和占用缓存空间成为衡量缓存权重不可缺少的影响因素。
5.第二,现代大数据平台出现比以往更为明显的热点集中效应。在一段时间内,近期热点数据的缓存命中率处理高位状态,且随着时间流逝,旧的数据逐渐成为死亡状态。缓存数据的时间损耗特点被提出,需要建立缓存数据时间损耗函数描述权重变化。
6.第三,缓存替换算法在缓存空间不足时启动,它清理旧的缓存数据,装入新的缓存数据,提升缓存空间利用率。目前,缓存替换算法研究已经有大量成果,但是现有缓存替换算法权重计算方法很难契合大数据平台的场景,解决大数据平台的缓存替换算法需要采用全新的权重计算方法。
技术实现要素:
7.在大数据场景下,针对大数据平台更为明显的热点集中效应,为了能够降低远程缓存的查询响应时间和/或在一定程度上有效减少缓存占用空间,本发明提供一种面向大数据平台的远程缓存替换方法及装置。
8.一方面,本发明提供一种面向大数据平台的远程缓存替换方法,包括:
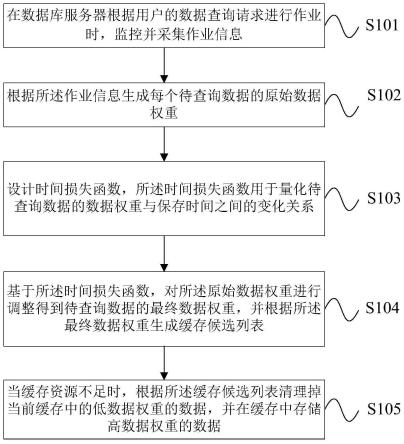
9.步骤1:在数据库服务器根据用户的数据查询请求进行作业时,监控并采集作业信息;所述作业信息包括数据库服务器对数据查询请求的数据响应时间、每个待查询数据在设定时间段内的被查询次数和每个待查询数据的数据大小;
10.步骤2:根据所述作业信息生成每个待查询数据的原始数据权重;
11.步骤3:设计时间损失函数,所述时间损失函数用于量化待查询数据的数据权重与保存时间之间的变化关系;
12.步骤4:基于所述时间损失函数,对所述原始数据权重进行调整得到待查询数据的最终数据权重,并根据所述最终数据权重生成缓存候选列表;
13.步骤5:当缓存资源不足时,根据所述缓存候选列表清理掉当前缓存中的低数据权重的数据,并在缓存中存储高数据权重的数据。
14.进一步地,在步骤1之前还包括:
15.根据用户的输入信息生成并向数据库服务器发送数据查询请求。
16.进一步地,步骤1中,具体包括:
17.采集所有数据库服务器对所述数据查询请求的数据响应时间,将其中最大的数据响应时间作为最终的数据响应时间,记作t
query
:
18.t
query
=max(t
subreq 1
,t
subreq 2
,...,t
subreqk
)
ꢀꢀ
(1)
19.其中,t
subreq 1
,t
subreq 2
,...,t
subreqk
分别表示数据库服务器1,2,
…
,k对数据查询请求的数据响应时间。
20.进一步地,步骤2中,根据所述作业信息生成每个待查询数据的原始数据权重,具体包括:
21.按照公式(2)计算用户访问待查询数据的总时间代价t
cost
:
22.t
cost
=numq
×
t
query
ꢀꢀ
(2)
23.其中,numq表示待查询数据在设定时间段内的被查询次数;
24.按照公式(3)计算原始数据权重weight_ori:
[0025][0026]
其中,size表示数据大小。
[0027]
进一步地,步骤4具体包括:基于所述时间损失函数t
loss
,按照公式(4)对所述原始数据权重进行调整得到待查询数据的数据权重f:
[0028]
f=weight_ori
×
t
loss
ꢀꢀ
(4)。
[0029]
其中,weight_ori为原始数据权重。
[0030]
进一步地,所述时间损失函数如公式(5)所示:
[0031][0032]
其中,y表示控制时间损失影响的调节系数,t
start
表示待查询数据保存在缓存中的
时间,t
last
表示最后一次命中缓存的时间,t
recent
表示当前的作业运行时长。
[0033]
进一步地,步骤5具体包括:
[0034]
步骤5.1:从当前缓存中删除数据权重最小的数据,并更新得到当前可用缓存资源;
[0035]
步骤5.2:在不超过当前可用缓存资源的条件下,将缓存候选列表中数据权重最大的数据存储至缓存中;
[0036]
步骤5.3:重复步骤5.1至步骤5.2,直至缓存候选列表为空。
[0037]
另一方面,本发明提供一种面向大数据平台的远程缓存替换装置,包括:
[0038]
状态监控和收集模块,用于在数据库服务器根据用户的数据查询请求进行作业时,监控并采集作业信息;所述作业信息包括数据库服务器对数据查询请求的数据响应时间、每个待查询数据在设定时间段内的被查询次数和每个待查询数据的数据大小;
[0039]
权重生成模块,用于根据所述作业信息生成每个待查询数据的原始数据权重,设计时间损失函数,所述时间损失函数用于量化待查询数据的数据权重与保存时间之间的变化关系;以及基于所述时间损失函数,对所述原始数据权重进行调整得到待查询数据的最终数据权重,并根据所述最终数据权重生成缓存候选列表;
[0040]
缓存替换模块,用于当缓存资源不足时,根据所述缓存候选列表清理掉当前缓存中的低数据权重的数据,并在缓存中存储高数据权重的数据。
[0041]
进一步地,还包括:数据服务模块,用于根据用户的输入信息生成并向数据库服务器发送数据查询请求。
[0042]
本发明的有益效果:
[0043]
本发明主要从缓存数据权重生成算法(cwg)、缓存替换算法(crep)这两部分出发进行了改进;其中,cwg根据大数据平台任务特点,建立全新的缓存数据权重生成模型,包括先通过考虑查询数据库响应时间、查询次数、数据大小被建立原始数据权重;然后提出时间损失函数,去定义时间损耗产生的缓存数据权重变化。crep则根据cwg算法生成缓存数据的最终权重来定义缓存替换的优先级,权重值较低的,被缓存的优先级则较低,反之较高。当缓存资源不足时,低优先级的缓存数据被高优先级的数据替换。最终,crep使用贪心策略保证缓存数据总权重最大化。为了验证本发明的有效性,基于redis实现rcrep策略,并部署在12台物理节点主机上。实验数据从snap数据集中选取,基准测试程序为pagerank、k-means、wordcount。实验证明,与大量先进的缓存管理算法相比,rcrep在大数据平台上缓存加速效果更明显。因为rcrep独立于spark平台,所以也可以在其他大数据平台(例如hadoop、flink、storm等等)中充当远程缓存组件。
附图说明
[0044]
图1为现有技术中的向spark集群添加缓存层的示意图;
[0045]
图2为现有技术中的数据查询流程;
[0046]
图3为本发明实施例提供的一种面向大数据平台的远程缓存替换方法的流程示意图;
[0047]
图4为本发明实施例提供的一种面向大数据平台的远程缓存替换装置的结构示意图;
[0048]
图5为本发明实施例提供的本发明与现有的5种方法在三种基准作业类型的作业执行效率示意图。
具体实施方式
[0049]
为使本发明的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0050]
在介绍本发明之前,为了更好地理解本发明的技术方案,下面先对数据查询的过程进行简要介绍。
[0051]
如图2所示,用户发起数据查询请求后,将创建数据库查询任务,流程如下:首先,请求从指定的数据库服务器获取查询结果。其次,由于会重复查询某些结果,因此重要的查询结果会写入远程缓存服务器。最后,当再次访问查询结果时,由于缓存服务器返回的结果具有较高的i/o速度,因此请求会被发送到远程服务器。
[0052]
实施例1
[0053]
如图3所示,本发明实施例提供一种面向大数据平台的远程缓存替换方法(简称rcrep),包括以下步骤:
[0054]
s101:在数据库服务器根据用户的数据查询请求进行作业时,监控并采集作业信息;所述作业信息包括数据库服务器对数据查询请求的数据响应时间、每个待查询数据在设定时间段内的被查询次数和每个待查询数据的数据大小;
[0055]
具体地,可以直接接收来自外部的数据查询请求并向数据库发送该数据查询请求;或者,根据用户的输入信息先生成数据查询请求,然后再向数据库发送该数据查询请求。采集到的作业信息可以记录在哈希表中。
[0056]
需要说明的是,在实际应用中,一般可能会存在多个数据库服务器,因此,用户的数据查询请求可能会被同时发送至该多个数据库服务器。在这种情况下,每个单独的数据库服务器的请求可以视为用户的数据查询请求(为方便叙述,数据查询请求也称query)的一个子请求(为方便叙述,子请求也称subreq),即query={subreq1,subreq2,
…
,subreqk}。而由于所有的子请求都是并行执行的,所以数据查询请求query的响应时间t
query
是所有子请求的响应时间中的最长响应时间,即
[0057]
t
query
=max(t
subreq 1
,t
subreq 2
,...,t
subreqk
)
ꢀꢀ
(1)
[0058]
其中,t
subreq 1
,t
subreq 2
,...,t
subreqk
分别表示数据库服务器1,2,
…
,k对数据查询请求的数据响应时间。
[0059]
s102:根据所述作业信息生成每个待查询数据的原始数据权重;
[0060]
具体地,在一段时间内,一个待查询数据可能会被多次访问,基于该情况,将待查询数据在设定时间段内的被查询次数记为numq,则用户访问该待查询数据的总时间代价t
cost
可由公式(2)计算得到:
[0061]
t
cost
=numq
×
t
query
ꢀꢀ
(2)
[0062]
可以理解,远程缓存服务器的i/o速度高于数据库服务器,因此如果待查询数据在缓存中被命中,查询结果的时间将减少。因此,当我们考虑应该保留哪些待查询数据时,待
查询数据的总时间代价t
cost
是一个积极因素。相反,由于缓存资源有限,若数据越大,缓存可用资源越少,因此数据大小size则是一个负面因素。基于上述情况,本实施例按照公式(3)计算原始数据权重weight_ori:
[0063][0064]
s103:设计时间损失函数,所述时间损失函数用于量化待查询数据的数据权重与保存时间之间的变化关系;
[0065]
具体地,发明人通过监视大量作业,发现旧数据在缓存中的命中概率会逐渐降低。即在某一点程序代码片段时间内,缓存数据会被频繁访问,但是当程序运行时间超出该代码片段之后,该代码片段内的缓存访问次数将逐渐降低。基于该情况,本实施例为了描述时间上下文信息和缓存数据权重之间的关系,在权重生成模型中创新性地引入了时间损失函数t
loss
,所述时间损失函数用于量化待查询数据的数据权重与保存时间之间的变化关系。
[0066]
s104:基于所述时间损失函数,对所述原始数据权重进行调整得到待查询数据的最终数据权重,并根据所述最终数据权重生成缓存候选列表;
[0067]
具体地,基于所述时间损失函数t
loss
,按照公式(4)对所述原始数据权重进行调整得到待查询数据的数据权重f:
[0068]
f=weight_ori
×
t
loss
ꢀꢀ
(4)
[0069]
作为一种可实施方式,本实施例中的时间损失函数t
loss
采用exp函数来拟合时间比和原始数据权重的变化关系,如公式(5)所示:
[0070][0071]
其中,y表示控制时间损失影响的调节系数,t
start
表示待查询数据保存在缓存中的时间,t
last
表示最后一次命中缓存的时间,t
recent
表示当前的作业运行时长。
[0072]
结合公式(4)和公式(5),本实施例的最终数据权重计算公式如下:
[0073][0074]
本发明实施例还提供了数据权重生成的算法(简称cwg算法)伪代码,如表1所示。
[0075]
表1
[0076][0077][0078]
其中,y是控制时间损失影响的调节系数;hashmap<queryid,frequency>tasklist是每个数据查询请求的记录频率列表,frequency即为numq;restspace:表示可用缓存资源,即缓存中可用空间的大小;maxspace表示缓存空间的总大小;queryreq:用于生成数据查询请求的是请求包装器;数据查询请求将从queryreq中被读取。list《queryreq,weight》candidates为最终生成的缓存候选列表。
[0079]
s105:当缓存资源不足时,根据所述缓存候选列表清理掉当前缓存中的低数据权重的数据,并在缓存中存储高数据权重的数据。反之,若缓存资源充足,则直接将待查询数据存储至缓存服务器中即可。
[0080]
具体地,本实施例中将缓存替换优化问题定义为式(6),即用高权重数据替换低权重数据,以最大化缓存权重之和:
[0081][0082][0083]
从式(6)可知,本实施例中定义的缓存替换优化问题是一个非线性整数规划问题。在多项式时间内很难获得精确的解。基于该请情况,作为一种可实施方式,采用贪心算法来求解式(6);根据贪心算法原理,可以将式(6)的子问题定义为式(7),即寻找在不超过可用缓存资源的条件下存储尽可能多的候选数据:
[0084]
max(f
1th
,f
2th
,f
3th
,...,f
kth
)
[0085]
[0086]
其中,f
1th
为缓存候选列表中数据权重最大值,也是第一个数据权重;f
2th
为缓存候选列表中的数据权重次大值,也是第二个数据权重;以此类推,f
kth
为缓存候选列表中的数据权重最小值,也是第k个数据权重;candidatesize表示候选数据的大小。
[0087]
基于上述内容,本步骤具体包括以下子步骤:
[0088]
s1051:从当前缓存中删除数据权重最小的数据,并更新得到当前可用缓存资源;
[0089]
s1052:在不超过当前可用缓存资源的条件下,将缓存候选列表中数据权重最大的数据存储至缓存中;
[0090]
s1053:重复步骤s1051至步骤s1052,直至缓存候选列表为空。
[0091]
本发明实施例还提供了缓存替换的算法(简称cwg算法)伪代码,如表2所示。
[0092]
表2
[0093][0094]
其中,restspace、maxspace、queryreq、list《queryreq,weight》candidates的意义已在上文中介绍,此处不再赘述。cachedatalist为当前缓存中存储的数据列表。
[0095]
随着互联网数据量急速增长,大数据处理平台性能优化问题吸引越来越多的研究人员的关注。优化缓存替换策略是提升大数据平台性能的有效途径。本发明实施例提供的一种面向大数据平台远程缓存替换方法,主要包括缓存权重生成算法(cwg)和缓存替换算法(crep)两部分;其中,cwg从数据查询响应时间、查询次数、数据大小三个主要因素建立原始数据权重,然后通过时间损失函数降低旧的数据权重,增强时间上下文感知能力。crep依据数据权重模型,生成候选数据列表,通过贪心思想淘汰低权重数据保证程序执行过程中缓存空间总权重最大化。实验选取snap数据集,使用pagerank、k-means、wordcount作为基准程序,选取作业执行时间为主要度量指标。实验证明,与大量先进的分布式缓存管理策略相比,rcrep执行时间最大提升29.5%,实验数据将下文中给出,此处不再赘述
[0096]
实施例2
[0097]
对应上述的方法,如图4所示,本发明实施例提供一种面向大数据平台的远程缓存替换装置,包括:数据服务模块、状态监控和收集模块、权重生成模块和缓存替换模块;
[0098]
其中,数据服务模块用于根据用户的输入信息生成并向数据库服务器发送数据查询请求;状态监控和收集模块用于在数据库服务器根据用户的数据查询请求进行作业时,监控并采集作业信息;所述作业信息包括数据库服务器对数据查询请求的数据响应时间、每个待查询数据在设定时间段内的被查询次数和每个待查询数据的数据大小;权重生成模
块用于根据所述作业信息生成每个待查询数据的原始数据权重,设计时间损失函数,所述时间损失函数用于量化待查询数据的数据权重与保存时间之间的变化关系;以及基于所述时间损失函数,对所述原始数据权重进行调整得到待查询数据的最终数据权重,并根据所述最终数据权重生成缓存候选列表;缓存替换模块,用于当缓存资源不足时,根据所述缓存候选列表清理掉当前缓存中的低数据权重的数据,并在缓存中存储高数据权重的数据。
[0099]
需要说明的是,本发明实施例提供的装置是为了实现上述方法实施例的,其功能具体可参考上述方法实施例,此处不再赘述。
[0100]
为了验证本发明的有效性,还提供有下述实验。
[0101]
(一)实验环境
[0102]
为了验证rcrep在作业执行期间的有效性,rcrep作为远程缓存的服务在reids上实现。spark平台将运行基准作业来测试rcrep的性能。实验启动了8个计算节点和4个缓存服务器。实验环境的配置如表3所示。选择hdfs作为数据库服务。基准作业包括pagerank、k-means和wordcount。作业的基准工作负载如表4所示。实验的主要指标是作业执行时间。snap提供了三个标准数据集,即web-berkstan、web-google和cit-patents。为了增加缓存资源的压力,web berkstan、web google和cit patents分别扩展为500gb、1tb和2tb。
[0103]
表3实验环境的配置信息
[0104][0105]
表4作业的基准工作负载
[0106][0107]
(二)性能评估
[0108]
为了测试rcrep的有效性,本节设置了三组基准工作来观察加速效应。基准作业pagerank、k-means和wordcount的执行时间分别如图5(a)、图5(b)和图5(c)所示。设置了高级缓存替换算法,包括gd-wheel[1]、wcsrp[2]、lwr[3]、wacr[4]和erac[5]。在图5中,x轴表示数据集的类型,y轴表示执行时间。对于web-berkstan和web-google数据集,gd-wheel的执行时间最长,rcrep最短,执行时间分别降低了21.2%,17.1%。随着数据集规模的增加,rcrep的执行时间明显短于其他算法。对于cit-patents,wacr的执行时间最长,rcrep的执行时间最小,执行时间降低了29.5%。图5(a)的结果表明,rcrep确实优化了pagerank的执行时间。图5(b)进一步验证了crep的最佳性能。在web-berkstan、web-google、cit-patents
三个数据集上,rcrep将k-means执行时间分别降低了11.7%,17.2%,23.9%。在图5(c)中,计算密集型作业wordcount的优化效果并没有pagerank和k-means好。在web-berkstan、web-google、cit-patents三个数据集上,rcrep将k-means执行时间分别降低了4.5%,5.2%,5.3%。结合源代码分析这一现象,发明人认为,wordcount与缓存资源的交互比pagerank和k-means少。因此,它对缓存压力不敏感,rcrep对它的优化效果有限。从上面讨论的内容可以看出,rcrep对于非计算密集型任务具有更好的优化效果。
[0109]
本发明中涉及到相关现有文献如下:
[0110]
[1]li c,cox a l,"gd-wheel:a cost-aware replacement policy for key-value stores"the tenth european conference on computer systems,acm,2015.
[0111]
[2]liu heng,tanliang,"new rdd partition weight cache replacement algorithm in spark,"journal of chinese computer systems,vol.39,2018.
[0112]
[3]bianc,yuj,ying c t et al,"self-adaptive strategy for cache management in spark,"actaelectronica sinica,2017.
[0113]
[4]kun jiang,shaofeng du,fu zhao et al,"effective data management strategy and rdd weight cache replacement strategy in spark,"computer communications,vol.194,pp.66-85,2022.
[0114]
[5]wei yun,dingyuchen,"research on efficient rdd self-cache replacement strategy in spark,"application research of computers,vol.37,2022.
[0115]
最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1