基于隐私计算的分布式图卷积网络训练方法与流程
1.本发明涉及隐私计算技术领域,具体为基于隐私计算的分布式图卷积网络训练方法。
背景技术:
2.随着网络技术和物联网技术的不断发展,用户隐私问题引发持续关注。大量用户日常数据被收集和分析甚至在网络上被非法上传,在这方面目前主流的技术为:可信执行环境,安全多方计算和联邦学习。在这三种技术中,联邦学习的优点是其较低的实现成本,其核心是利用分布式的数据共同训练一个集中的模型,同时可集成差分隐私、安全多方计算,同态加密等多种加密算法,提供更强的安全性。
3.在深度学习中,图卷积神经网络(gcn)已广泛应用于多个领域,如推荐系统,精确分类以及实体间关系预测等,其可以充分利用图中节点的邻接关系,为图中的每个节点学习一个精确的语义表达,提升后续分类或者推荐的准确度。如社交网络可以看成是一个图,其中的每个节点代表一个人,节点可以有自己的特征,如职业,年龄,性别等等,互相认识的两个人之间有一条边连接。但是,如果图中的各个节点分属于不同的组织,考虑到隐私保护问题,我们在做图卷积运算时需要的邻居节点信息由于隐私保护的原因而缺失时,图卷积神经网络为图中每个节点所学习的语义表达的精确度就会显著降低,严重影响了后续任务的准确度。当前基于图神经网络的联邦学习研究,主要还是基于联邦学习框架,对图数据进行分割,重点解决图数据分割的方法与效率问题以及分割图数据中的非独立同分布问题。而由于隐私保护考虑,当一个大图中各个节点的特征数据分属于不同组织或者结构,不能集中起来进行图卷积神经网络训练时,如何提升图卷积神经网络学习效率的问题,尚未被提出,也未有高效的解决方案。
技术实现要素:
4.本发明的目的在于提供基于隐私计算的分布式图卷积网络训练方法,以解决上述背景技术中提出的问题。
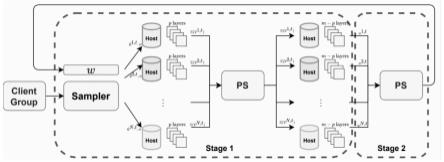
5.为实现上述目的,本发明提供如下技术方案:基于隐私计算的分布式图卷积网络训练方法,训练方法分为两个阶段:阶段一:采样机将子图发送至主机,主机将不可见节点特征设置为零,进行图神经网络的第一层计算,以生成每个节点的嵌入,并将节点嵌入推送到as;主机从as查询不可见节点的嵌入,再从as接收到不可见节点的嵌入后,主机将第一层的输出输入到图卷积神经网络的第二层继续进行计算;阶段二:主机将本轮循环结束后图卷积神经网络的模型参数发送到as,as收集齐所有主机的模型参数,进行加权平均后将结果发送回各主机,形成一轮循环。
6.优选的,训练方法的两个阶段形成一个训练循环,并根据训练结果进行重复循环训练。
7.优选的,整个训练过程的主要部件由客户组、主机、采样器和汇聚服务器构成;客
户组用于负责管理和记录所有图数据的信息,保存了图数据每个节点的信息及信息的特征属性,以及主机的归属序号。
8.优选的,主机用于分配的子图进行图卷积神经网络训练,对于因隐私保护原因不可见的节点特征,主机都会初始化为零,主机可以与as通信交换embedding和模型参数。
9.优选的,采样器作为工作分配器,将整个大图划分为子图并将它们分发给每个主机,其应尽可能消除采样偏差,提高训练效率。
10.优选的,汇聚服务器用于收集每个主机发来的节点的embedding信息以及模型参数,并负责模型参数的加权平均计算和反馈给各个主机。
11.优选的,图卷积神经网络采用2-3层结构,用于大图数据分割后在多个主机进行分布式训练,通过参数汇聚服务器共享图卷积神经网络第一层输出的解决方案。
12.优选的,主机经过大图经采样器后得到多个子图,子图被分配到多个主机进行图卷积神经网络模型训练。
13.优选的,在每个训练轮次,主机将图卷积神经网络第一层的输出发送到as,然后从as获得由于隐私保护而不可见的节点在as上的embedding,然后继续图卷积神经网络第二层以后的计算。
14.优选的,每个host上的图卷积神经网络模型参数wi在每轮过后发送到as进行加权平均,然后将平均后的参数w发回各个host更新本地模型参数。
15.与现有技术相比,本发明的有益效果是:本发明解决了在一个大图中节点分属于不同组织时,各个组织对数据的使用有强烈的隐私保护需求的情况下,通过分布式训练的方式,训练一个统一的图卷积神经网络模型,能够精确和高效的学习图中每个节点的语义表达的问题。
附图说明
16.图1为本发明的图卷积神经网络训练流程示意图;
17.图2为本发明的方案总体实现示意图;
18.图3为本发明的共享嵌入流程示意图;
19.图4为本发明的共享参数权重流程示意图;
20.图5为本发明的ppi、flickr和reddit执行数据图;
21.图6为本发明的主机节点设置参数调节数据图。
具体实施方式
22.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
23.请参阅图1至图6,本发明提供的三种实施例:
24.实施例一:
25.基于隐私计算的分布式图卷积网络训练方法,训练方法分为两个阶段:阶段一:采样机将子图发送至主机,主机将不可见节点特征设置为零,进行图神经网络的第一层计算,
以生成每个节点的嵌入,并将节点嵌入推送到as;主机从as查询不可见节点的嵌入,再从as接收到不可见节点的嵌入后,主机将第一层的输出输入到图卷积神经网络的第二层继续进行计算;阶段二:主机将本轮循环结束后图卷积神经网络的模型参数发送到as,as收集齐所有主机的模型参数,进行加权平均后将结果发送回各主机,形成一轮循环。训练方法的两个阶段形成一个训练循环,并根据训练结果进行重复循环训练。整个训练过程的主要部件由客户组、主机、采样器和汇聚服务器构成;客户组用于负责管理和记录所有图数据的信息,保存了图数据每个节点的信息及信息的特征属性,以及主机的归属序号。主机用于分配的子图进行图卷积神经网络训练,对于因隐私保护原因不可见的节点特征,主机都会初始化为零,主机可以与as通信交换embedding和模型参数。采样器作为工作分配器,将整个大图划分为子图并将它们分发给每个主机,其应尽可能消除采样偏差,提高训练效率。汇聚服务器用于收集每个主机发来的节点的embedding信息以及模型参数,并负责模型参数的加权平均计算和反馈给各个主机。图卷积神经网络采用2-3层结构,用于大图数据分割后在多个主机进行分布式训练,通过参数汇聚服务器共享图卷积神经网络第一层输出的解决方案。经过大图经采样器后得到多个子图,子图被分配到多个主机进行图卷积神经网络模型训练,在每个训练轮次,主机将图卷积神经网络第一层的输出发送到as,然后从as获得由于隐私保护而不可见的节点在as上的embedding,然后继续图卷积神经网络第二层以后的计算,每个host上的图卷积神经网络模型参数wi在每轮过后发送到as进行加权平均,然后将平均后的参数w发回各个host更新本地模型参数。
26.实施例二:
27.在三个主流的图数据集下做了仿真并通过与基线模型的对比展示了其能力。
28.三个数据集分别为:ppi、flickr和reddit。ppi数据集是人体组织蛋白质-蛋白质关联网络的集合,其中图的边代表蛋白质之间的直接蛋白质-蛋白质相互作用或间接关联。flickr和reddit数据集是由flickr和reddit的用户相应构建的社交网络。
29.flickr在具有相同属性,例如地理位置、提交的画廊、公共标签等的图像之间形成边。
30.reddit是一个帖子后图网络,如果两个帖子由同一用户发表评论,则它们被连接起来。多分类任务在ppi上执行,而单分类任务在flickr和reddit上执行,参阅说明书附图图5。
31.提出了两种基线:
32.一、具有不同采样器机制(
“‑
node”、
“‑
edge”、
“‑
rw”、
“‑
mrw”)的graphsaint模型,主机以隔离的方式执行任务,即既不共享嵌入也不共享权重矩阵;
33.二、graphsaint-sw,实现了简单的联邦学习,在
“‑
node”、
“‑
edge”、
“‑
rw”、
“‑
mrw”中针对不同的主机号,以最佳采样器机制共享权重矩阵,但其不共享嵌入。我们设定了两个主机不可见节点的比例,分别为40%和60%,参阅说明书附图图6。
34.使用分类任务的综合指标f1-micro来衡量模型性能,其均值和置信区间在相同的超参数下通过三轮以上测量。更重要的是,对于有多个主机的实验,最终得分是所有主机得分的平均值。可以看出,在三个数据集上都取得了最好的分类结果,在ppi和reddit数据集上实现了显著的准确性提高,在flickr数据集上略有优势。比较两种基线,可以在表中发现,简单实现联邦学习(基线2)带来的积极影响非常有限,有时甚至比独立训练(基线1)还
要差。因此,我们可以证明:在隐私保护前提下,只是对图数据利用联邦学习进行分布式训练效果差;只有通过我们的方案,分享不可见节点的嵌入,才能实现更高效和更精确的学习效果。
35.实施例三:
36.基于隐私计算的分布式图卷积网络训练方法算法如下:
37.输入:
38.g(υ,ε):训练图
39.m:神经网络总层数
40.p:共享嵌入索引
41.x
υ
:输入,y
υ
:输出
42.n:主机数,t:迭代轮次
43.输出:
44.wi:模型参数
45.随机初始化w
46.for t∈{1,2...,t}do
47.g
n,t
(υ
n,t
,ε
n,t
)
←
从g(υ,ε)中采集子图
48.for all n∈{1,2,...,n}parallel do:
49.w
n,t
←w50.x
υ
←
0forυ∈{v
n,t
\h(n)}
51.e(v
n,t
)
←
前馈传播p层神经网路
52.将e(v
n,t
)推送到as中
53.end
54.将e(v
t
)从as中拉取回来
55.for all n∈{1,2,...,n}parallel do
56.从e(v
t
)中拉取e(v
n,t
)
57.←
前馈传播m层神经网络,υ∈v
n,t
58.w
n,t
←
反向传播
59.将w
n,t
推送到as中
60.end
61.w
←
as(w
1,t
,w
2,t
,...,w
n,t
)
62.end
63.m:神经网络总层数;p:共享嵌入索引;xy:输入;y:输出;n:主机数;t:迭代轮次廿输出。
64.对于本领域技术人员而言,显然本发明不限于上述示范性实施例的细节,而且在不背离本发明的精神或基本特征的情况下,能够以其他的具体形式实现本发明。因此,无论从哪一点来看,均应将实施例看作是示范性的,而且是非限制性的,本发明的范围由所附权利要求而不是上述说明限定,因此旨在将落在权利要求的等同要件的含义和范围内的所有变化囊括在本发明内。不应将权利要求中的任何附图标记视为限制所涉及的权利要求。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1