一种基于特征交互和分数集成的CTR推荐方法
一种基于特征交互和分数集成的ctr推荐方法
技术领域
1.本发明涉及ctr推荐,尤其涉及基于特征交互和分数集成的多域ctr推荐方法。
背景技术:
2.click-throughrate(ctr)预测是推荐领域最常见的任务之一。然而,人工对于用户的偏好进行预测是非常困难的。因此,使用深度学习技术进行ctr预测,这有益于电子商务平台对用户展示更人性化的推荐内容。像mmoe、cgc、ple等网络已经被专门提出用于各种推荐任务的预测,这些方法在许多大型数据集上也取得了不错的性能,证明了深度学习技术在推荐领域中的有效性。从根本上说,ctr预测可以看作是将用户的特征和商品的特征作为输入,最终网络输出用户点击此商品的概率,可以隐式地反映用户对商品的喜好程度。然而,将其转换到多域推荐中并非易事,因为用户分布的不同决定了在跨境电子商务场景中用户行为的显著多样性、数据的稀疏性和不均匀分布,使得多域ctr预测任务相当困难。
3.传统的方法是在所有域上联合构建一个单一的模型,或者在每个域上独立构建模型。然而,将传统方法直接应用于多域推荐会存在一些问题:1)由于地理、文化等方面的差异,不同领域的用户在购物偏好上可能存在显著差异。而联合训练可能会消除每个领域的特有信息;2)不同领域的可用数据量极不平衡,许多领域仅包含少量数据。而独立训练忽略了领域之间的潜在相关性,无法对数据量少的领域进行有效的训练。
4.本发明提出了一种新的模型结构,可以实现更为准确的多域ctr预测。
技术实现要素:
5.本发明提供了一种基于特征交互和分数集成的ctr推荐模型。首先,通过特征交互学习局部场景和全局场景之间的组合特征,明确增强了多域学习中的特征表示。然后将特征拼接起来,输入到公共专家和特定专家网络中生成公共的和特定的特征表示,用门控机制整合公共特征和特定特征,得到各个视图的高级融合特征。最后输入到对应的mlp中得到各个视图的分数,再使用门控机制集成各个视图的分数得到最终ctr预测分数。整个模型包括场景交互细化模块、专家投影模块和多视图分数集成模块。
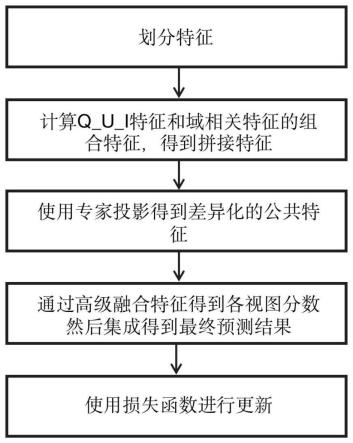
6.一种基于特征交互和分数集成的ctr推荐方法,其步骤如下:
7.步骤(1)、将数据集中的特征分为4个类型:历史行为特征、q_u_i特征、域相关特征、域id特征。
8.步骤(2)、通过设计的场景交互细化模块来区分不同领域中不同分布的局部特征。
9.步骤(3)、通过设计的专家投影模块提取差异化的公共特征,并引入自适应残差连接来加速学习,实现更灵活的投影。
10.步骤(4)、利用设计的多视图分数集成模块首先提取高级融合特征,然后通过分数集成输出结果。
11.步骤(5)、对损失函数进行改进,有效避免过拟合。
12.进一步的,步骤(1)所述的4种特征类型具体划分如下:
13.1.历史行为特征:表示用户历史行为的集合,包含序列及序列相关特征,具体公式如下,其中|g|表示历史行为特征的数量:
14.g={g1,g2,...,g
|g|
}
ꢀꢀꢀ
(公式1)
15.2.q_u_i特征:表示查询、用户和商品特征的集合,包含查询特征、用户特征和商品特征,在不同的领域中这些特征的分布不一致,存在领域差异。具体公式如下,其中|l|表示q_u_i特征的数量:
16.l={l1,l2,...,l
|l|
}
ꢀꢀꢀ
(公式2)
17.3.域相关特征:表示与域相关的特征的集合,包含商品曝光特征、商品点击特征和域高度相关的特征。具体公式如下,其中|s|表示域相关特征的数量:
18.s={s1,s2,...,s
|s|
}
ꢀꢀꢀ
(公式3)
19.4.域id特征:表示域的id信息的集合,每一个特征是一个由one-hot向量生成的embedding特征,具体公式如下,其中|r|表示域的数量:
20.r={r1,r2,...,r
|r|
}
ꢀꢀꢀ
(公式4)
21.由|r|个领域组成的数据集的表示如下:
22.d={d1,d2,...,d
|r|
}
ꢀꢀꢀ
(公式5)
[0023][0024]
其中,di表示第i个领域的样本数据,|di|表示第i个领域的样本数量。
[0025]
表示第i个领域的第|di|个样本的特征,表示第i个领域的第|di|个样本的ctr标签。
[0026]
因此,一个样本的4种类型特征的集合表示如下:
[0027][0028]
其中,表示第i个领域的第j个样本的样本特征,分别表示第i个领域的第j个样本的历史行为特征、q_u_i特征、域相关特征,ri表示第i个领域id的embedding向量。
[0029]
步骤(2)中所述的场景交互细化模块具体如下:
[0030]
不同领域的q_u_i特征是独立的,因此在不同领域它们的分布并不完全相同,这些差异反映了不同领域中用户的偏好。我们显式构造了一个<q_u_i特征,域相关特征》组合特征,强制融合域相关特征和q_u_i特征,用于表示局部场景和全局场景之间的特征交互。
[0031]
因为q_u_i特征维度一般较大,因此首先降低其维度。然后执行q_u_i特征和域相关特征的特征交互操作得到组合特征,具体公式如下:
[0032][0033][0034]
其中,σ表示非线性激活函数,ω
l
、b
l
分别表示全连接层的权重和偏置,t表示矩阵的转置,表示外积操作,lr表示降维后的q_u_i特征。
[0035]
其中,s表示非线性激活函数,ω
l
、b
l
分别表示全连接层的权重和偏置,t表示矩阵的转置,表示外积操作,lr表示降维后的q_u_i特征。
[0036]
接着,将此组合特征m展开成一维向量,使用全连接层提取出全局差异化特征c,具
体公式如下:
[0037][0038]
其中,ωc、bc分别表示组合特征m的全连接层的权重和偏置,flatten()表示多维展开成一维向量的函数,如reshape。
[0039]
最后,使用concat操作将g、l、s、c特征组合起来,作为backbone网络的输入,具体公式如下:
[0040]
i=concat(g|l|s|c)
ꢀꢀꢀ
(公式11)
[0041]
其中,i∈rm。i是backbone网络的输入,rm是输入的维度,即g、l、s、c特征维度的总和。
[0042]
步骤(3)中所述的专家投影模块具体如下:
[0043]
在多域学习中,多专家网络不能像理论中那样对公共特征的差异进行建模,因为在多域场景下,数据极度不平衡,对数据量大的领域进行建模的专家梯度信息较大,将比其他专家学习到更好的表示。这样限制了大多数专家的表达能力。因此提出一个专家投影模块降低专家学习的难度,提高专家的整体表达能力。
[0044]
由主导专家提供训练有素的参数,该方法是让其他专家通过学习主导专家的参数的投影而不是直接学习专家的参数,明确地建模了由差异引起的映射偏移,具体公式如下:
[0045][0046]
其中,w
base
∈rm×n表示主导专家提供的基础权重,和和分别表示第i个投影的权重和偏置。表示通过投影得到的第i个投影专家的权重。所述的主导专家是指提供基础权重和参数投影的专家。所述的主导专家是指对数据量大的领域进行建模的专家。
[0047]
因为此方式比没有投影的情况下会多出一项,导致学习速度下降以及梯度的减小,为了解决这个问题,引入了残差连接,此方法还有助于控制初始化参数。具体公式如下:
[0048][0049]
其中,αi表示第i个自适应参数值,且没有任何边界限制。
⊙
表示element-wise的乘积操作。
[0050]
每一个投影专家类似于真正的专家一样都和输入特征i进行交互,其中i∈rm,然后加上额外的偏置得到差异化的公共特征具体公式如下:
[0051][0052]
步骤(4)所述的多视图分数集成模块具体如下:
[0053]
在提取出差异化的公共特征之后,还需要提取域的特定特征每个视图都有一个特定的专家,专门用于提取有区别的特征。每个视图拥有一个门控网络,具体公式如下:
[0054][0055]
[0056][0057]
其中,r表示样本相应的域id特征,表示从第j个视图中提取的特定特征,mlp表示多层感知机,n
comm
表示专家投影模块中投影专家的数量。和分别表示第j个视图的门控网络的权重和偏置,其中k∈[0,n
comm
]。表示第j个视图对于第k个特征的门控值,k=0时,表示特定特征,k∈[1,n
comm
]时,表示公共特征。hj表示第j个视图的高级融合特征,j∈[1,n
view
]。
[0058]
最后,每个视图的高级融合特征通过对应的mlp得到多个分数,再通过门控机制集成这些分数,最后通过sigmoid函数得到最终ctr预测结果具体公式如下:
[0059][0060][0061][0062]
其中,rj∈r1表示得分,和分别是门控网络的权重和偏置,j∈[1,n
view
],n
view
表示视图的数量(域的数量),即n
view
=|r|。
[0063]
步骤(5)的损失函数具体设计如下:
[0064]
通过调整损失函数使我们的模型可以端到端训练,具体公式如下:
[0065][0066]
其中第一项表示损失的计算公式,可以是cross-entropy、mean square error等。第二项是一个正则化项,λj是第j个视图的超参数,用于控制正则化的能力。
[0067]
本发明有益效果:
[0068]
本发明基于特征交互和分数集成对多域ctr任务进行预测,为了明确增强多领域学习中的特征表示,使用场景交互细化模块来得到q_u_i特征及域相关特征的组合特征,使之代表嵌入特征的局部场景和全局场景之间的特征交互。为了缓解不同场景下特征的显著多样性、数据的不均匀分布和稀疏性,使用专家投影模块,生成差异化的公共特征表示。最后为了增强对标签数据分布稀疏性的拟合能力,使用多视图分数集成模块自适应地组合多分支网络的输出分数。此网络能够捕获特征空间和标签空间中固有的相关性信息,提高多域ctr预测的正确率。
附图说明
[0069]
图1是本发明方法的具体流程示意图。
[0070]
图2是本发明方法中的整个模型框架示意图。
具体实施方式
[0071]
下面结合附图对本发明做进一步具体说明:
[0072]
如图1所示,基于特征交互和分数集成的模型,具体包括如下步骤:
[0073]
附图2展示了本发明的整体模型框架图,接下来根据附图2来分别说明各个模块的细节,具体实施步骤如下:
[0074]
步骤(1)、将特征划分为4部分,主要分为历史行为特征、q_u_i特征、域相关特征和域id特征,分别用g、l、s、r表示,每一个样本集合可以表示为:其中,r使用one-hot向量的embedding特征表示。
[0075]
步骤(2)、设计了一个场景交互模块,先使用一层全连接将维度较高的q_u_i特征进行降维,使用降维后的特征和域相关特征进行外积操作得到组合特征,然后将组合特征展开为一维向量,经过一层全连接提取出全局差异化特征c。将g、l、s、c特征进行concat操作得到i∈rm作为之后backbone的输入。
[0076]
步骤(3)、设计了专家投影模块,将每个领域设置为一个特定专家,三个投影专家。先创建一个基础权重w
base
∈rm×n,为每个投影创建一个权重和偏置:和通过投影的权重和基础权重矩阵相乘后加上投影的偏置后得到投影专家的权重然后加上一个残差连接αi⊙wbase
提高学习速度,并有助于控制初始化参数。最后与输入特征i相乘后再加上投影专家的偏置得到差异化的公共特征
[0077]
步骤(4)、设计多视图分数集成模块,为每一个域设计一个视图,得到了公共特征之后,还需要提取出特定领域特征每一个视图各使用一个mlp,由concat后的拼接特征i作为输入,输出对应领域的特定特征。然后对于三个公共特征和每一个特定特征使用门控机制进行加权求和,得到第j个视图的高级融合特征hj。最后,每个视图的高级融合特征通过各自mlp得到对应视图的多个分数,再通过门控机制加权和,使用sigmoid函数得到最终多域ctr预测结果。
[0078]
步骤(5)、对损失函数进行了改进。第一项使用传统的cross-entropy或者mean square error,其中真实值是标签,预测值是最终ctr的预测结果。在第一项之后加上了一个正则化项,此项用于对每个视图的得分各使用一个cross-entropy损失,其中真实值是标签值,预测值是每个视图的得分。然后乘一个超参数,用于控制正则化的能力,防止模型出现过拟合。
[0079]
如表1所示,选取了公开数据集aliccp,此数据集来自淘宝推荐系统地真实流量日志。数据集包含点击标签和购买标签,在本发明中仅使用点击标签进行多域ctr预测任务。将不同的业务场景视为域,此数据集包含三个域,这三个域中的样本极不平衡。数据集的统计信息如表1所示,domain1,domain2,domain3的数据量差距极大,而且点击率稀疏:
[0080]
表1
[0081][0082]
实验采用的对比模型包括现有的多任务模型和多域模型,所有模型都以预测多个域的ctr为任务。表2中auc是推荐系统中的一个常用指标,auc定义为roc曲线下的面积。其含义是:随机选择一对正负样本,auc是预测正样本为true的概率大于预测负样本为true的概率。auc越高,表示模型的性能越好。
[0083]
表2
[0084][0085]
从表2中可以看出,本发明的方法基于特征交互和分数集成的多域ctr预测模型在多域ctr推荐系统中取得了明显的效果。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1