一种财务报告舞弊检测方法及系统
本发明涉及数据处理,尤其涉及一种财务报告舞弊检测方法及系统。
背景技术:
1、在上市公司的财务舞弊检测中,反舞弊最关键、最困难的环节即对舞弊迹象的识别。
2、早期的研究主要偏向使用财务报表等结构化数据对公司舞弊进行识别。随着自然语言处理技术的快速发展,学者们开始聚焦于利用非结构化数据,通过分析上市公司年报中的管理层讨论与分析章节(management discussion and analysis,md&a)来区分舞弊公司和非舞弊公司。
3、但是,由于年报md&a中存在专业词汇、单个词语数量较多且多次重复出现等特性,常规的自然语言处理方法无法将其有效的分开。同时现有的研究也存在对非结构化数据信息利用不足的问题,主要体现在利用自然语言处理方法对整个文本进行向量化时,无法捕捉文本结构的语义特征,使得文本向量化后损失了语义信息,进而导致对公司舞弊识别无法达到最佳效果。
技术实现思路
1、鉴于上述的分析,本发明实施例旨在提供一种财务报告舞弊检测方法及系统,用以解决现有因无法有效区分md&a语义导致舞弊检测不精确的问题,同时也引入了一种全新的方法实现更为全面的衡量md&a文本可读性,进而补充自然语言处理方法造成的文本语义丢失问题。
2、一方面,本发明实施例提供了一种财务报告舞弊检测方法包括如下步骤:
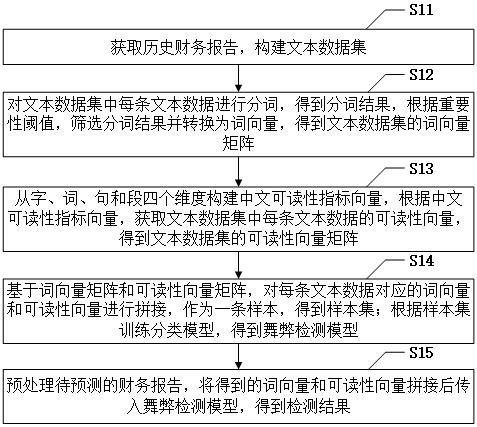
3、获取历史财务报告,构建文本数据集;
4、对文本数据集中每条文本数据进行分词,得到分词结果,根据重要性阈值,筛选分词结果并转换为词向量,得到文本数据集的词向量矩阵;
5、从字、词、句和段四个维度构建中文可读性指标向量,根据中文可读性指标向量,获取文本数据集中每条文本数据的可读性向量,得到文本数据集的可读性向量矩阵;
6、基于词向量矩阵和可读性向量矩阵,对每条文本数据对应的词向量和可读性向量进行拼接,作为一条样本,得到样本集;根据样本集训练分类模型,得到舞弊检测模型;
7、预处理待预测的财务报告,将得到的词向量和可读性向量拼接后传入舞弊检测模型,得到检测结果。
8、基于上述方法的进一步改进,获取历史财务报告,构建文本数据集,包括:
9、获取历史各年度和各季度财务报告中的md&a文本,以及历史舞弊记录;根据每条历史舞弊记录中的公司和年度,将该公司当年和上一年的年度财务报告,及对应年度的各季度财务报告的md&a文本都设置为舞弊的分类标签;其它的md&a文本设置为非舞弊的分类标签;
10、将每条md&a文本作为一条文本数据与对应的分类标签,放入文本数据集中。
11、基于上述方法的进一步改进,对文本数据集中每条文本数据进行分词,得到分词结果,包括:
12、使用正则表达式去除文本数据中的英文字符、空字符和无用标点符号,无用标点符号是除句号、中文问号、中文感叹号、中文分号、中文逗号和中文冒号之外的标点符号;
13、使用jieba库的精确模式进行分词,并根据停用词表去除停用词,得到分词结果。
14、基于上述方法的进一步改进,根据重要性阈值,筛选分词结果并转换为词向量,包括:
15、将每条文本数据的分词结果作为特征,分类标签作为响应变量,采用随机森林模型构建多棵决策树;按分词结果中各词汇的重要性从高到低排序分词结果;根据重要性阈值,从每条文本数据的排序后的分词结果中按顺序选取相同数量的词汇;
16、采用hash trick方法,将每条文本数据选取的词汇转换为词向量。
17、基于上述方法的进一步改进,从字、词、句和段四个维度构建中文可读性指标向量,包括:基于中文文本语言结构特征,根据常用字比率构建字的中文可读性指标;根据常用词比率、成语比率、专业词汇比率、逆接关系连接词比率和否定词比率构建词的中文可读性指标;根据平均句长和陈述句比率构建句的中文可读性指标;根据段落平均数字数量构建段的中文可读性指标;将字的中文可读性指标、词的中文可读性指标、句的中文可读性指标和段的中文可读性指标组合为中文可读性指标向量。
18、基于上述方法的进一步改进,根据中文可读性指标向量,获取文本数据集中每条文本数据的可读性向量,包括:
19、对文本数据集中每条文本数据,按中文可读性指标向量,分别计算出字、词、句和段的中文可读性指标值,得到四维向量;对四维向量进行l2范数的正则化处理后,得到当前文本数据对应的可读性向量。
20、基于上述方法的进一步改进,字、词、句和段的中文可读性指标值,根据各指标项及其各自的权重,分别通过下列各式计算得到:
21、
22、
23、
24、
25、其中,表示字的中文可读性指标值,表示常用字比率;表示词的中文可读性指标值,表示常用词比率,表示成语比率,表示专业词汇比率,表示逆接关系连接词比率,表示否定词比率;表示句的中文可读性指标值,表示平均句长,表示陈述句比率;表示段的中文可读性指标值,表示段落平均数字数量;分别表示对应指标项的权重。
26、基于上述方法的进一步改进,样本集划分为训练集和测试集,并采用过采样方法对训练集进行平衡处理,使训练集中各分类标签的训练样本数量一致。
27、基于上述方法的进一步改进,分类模型是支持向量机分类模型。
28、另一方面,本发明实施例提供了一种财务报告舞弊检测系统,包括:
29、数据预处理模块,用于获取历史财务报告,构建文本数据集;
30、词向量生成模块,用于对文本数据集中每条文本数据进行分词,得到分词结果,根据重要性阈值,筛选分词结果并转换为词向量,得到文本数据集的词向量矩阵;
31、可读性向量生成模块,从字、词、句和段四个维度构建中文可读性指标向量,根据中文可读性指标向量,获取文本数据集中每条文本数据的可读性向量,得到文本数据集的可读性向量矩阵;
32、模型训练模块,基于词向量矩阵和可读性向量矩阵,对每条文本数据对应的词向量和可读性向量进行拼接,作为一条样本,得到样本集;根据样本集训练分类模型,得到舞弊检测模型;
33、舞弊检测模块,用于预处理待预测的财务报告,将得到的词向量和可读性向量拼接后传入舞弊检测模型,得到检测结果。
34、与现有技术相比,本发明至少可实现如下有益效果之一:
35、1、基于中文文本语言结构特征,把中文财务报告结构分解为四个维度:字、词、句、段,分别构建字的中文可读性指标、词的中文可读性指标、句的中文可读性指标和段的中文可读性指标。并在此基础上,将四种指标值组成可读性向量对财务报告的md&a文本可读性信息进行衡量,然后将其作为哈希转化的词向量缺失的语义补充,与词向量共同构建模型,同时也反映出不同财务报告的文本可读性之间无法比较的问题。实现了对财务报告文本可读性的综合考量,提高了舞弊检测的精确率。
36、2、通过分别建立可读性向量和hash过后的md&a文本向量,综合考量了金融类上市公司md&a文本特征的,进一步提高了模型的性能,解决了金融类上市公司md&a文本数据在向量化时文本语义无法分开、以及语义丢失的问题。将中文文本分析技术引入财务审计领域,为数字化、智能化审计提供一个新视角新思路,帮助了审计人员进一步提高审计效率。
37、本发明中,上述各技术方案之间还可以相互组合,以实现更多的优选组合方案。本发明的其他特征和优点将在随后的说明书中阐述,并且,部分优点可从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过说明书以及附图中所特别指出的内容中来实现和获得。
- 还没有人留言评论。精彩留言会获得点赞!