面向无人机目标检测的动态上下文关系采集网络结构
1.本发明属于智能无人系统、人工智能以及计算机视觉技术领域,涉及一种面向无人机目标检测的动态上下文关系采集网络结构。
背景技术:
2.挂载可见光相机的无人机平台已经受到广泛的关注。该平台能够快速、低成本地部署在各种新型应用中,例如,航空摄影和航空视频监控。自动识别无人机图像或者视频数据的感兴趣目标,具有强烈的应用需求。得益于深度神经网络在遥感图像处理领域的发展,以无人机为视角的目标检测(无人机目标检测)算法已经取得了一定的进展。
3.主流的无人机目标检测算法,通常会设计一个上下文关系采集模块,通过采集目标周围的上下文关系,从而丰富低质量的目标所在区域的信息。该类方法虽然可以有效地提升已有检测算法的准确率,但将其部署在无人机平台并实现机载处理,依然存在诸多问题。其中,最为棘手的问题是,算法本身巨额的计算开销与无人机平台极其有限的计算能力之间的矛盾。
4.绝大多数无人机目标检测算法均采用静态架构。如图1所示,面对不同识别难度的输入图像,均采用上下文关系采集模块处理。显然,对简单的图像,依然执行该采集模块,会造成计算资源的巨大浪费。
技术实现要素:
5.本发明的目的是提供一种面向无人机目标检测的动态上下文关系采集网络结构,该结构能够自动地区分不同难度的图像,自主地选择是否执行上下文采关系采集模块,从而达到减少检测算法开销的目标。
6.本发明所采用的技术方案是,面向无人机目标检测的动态上下文关系采集网络结构,包括骨干网络,骨干网络通过动态上下文采集器连接顶到底通路,顶到底通路连接检测头。
7.本发明的特点还在于:
8.动态上下文采集器包括动态门,动态门用于学习从输入图像特征图ci至门信号的映射函数,动态门包括门网络和激活函数。
9.门网络的结构包括依次连接的一个全局平均池化层gap、全连接层fc1、全连接层fc2以及一个relu层δ组成;
10.门网络的输出采用如下公式(1)表示:
[0011][0012]
其中,ci是fpn第i层的输入,假设gatenet的输入特征的形状为hi×
wi×ci
,hi表示输入特征的长度、wi表示输入特征的宽度、ci表示输入特征的通道,输出特征形状为ho×
wo×co
,h0表示输出特征的长度、w0表示输出特征的宽度、c0表示输出特征的通道。
[0013]
门网络的结构采用3
×
3卷积层conv采集上下文关系信息,卷积层之后是全局平均池化层gap,用于捕获整个图像的上下文关系信息,最后,使用全连接层fc输出一个二维矢量采用如下公式(2)表示门网络的输出
[0014][0015]
门网络包含2
×
2的最大池化层max pooling、步长为2的3
×
3卷积层conv,然后是全局平均池化gap和一个全连接层fc,采用如下公式(3)计算的输出
[0016][0017]
激活函数采用概率π={π1,π2,...,πk}的连续微分函数,通过下式预测k维one-hot编码αi:
[0018][0019]
式中,i=1,...,k,gi,...,gk是gumbel(0,1)提取的独立同分布样本,τ是温度参数。
[0020]
本发明的有益效果是,本发明在两个广泛使用的无人机捕获数据集进行了大量实验,并与最先进的方法(sota)对比,从而验证了dycc-net的有效性。实验结果表明,dycc-net的推理时间不到sota模型推理时间的三分之一,从而降低了模型的计算成本。通过本发明还发现,dycc-net的ap
75
性能指标高出sota模型1.97%。
附图说明
[0021]
图1是现有无人机检测器的静态架构图;
[0022]
图2是本发明面向无人机目标检测的动态上下文关系采集网络结构的应用原理图;
[0023]
图3是本发明面向无人机目标检测的动态上下文关系采集网络结构的结构原理图;
[0024]
图4是本发明面向无人机目标检测的动态上下文关系采集网络结构中动态门的结构原理图;
[0025]
图5是本发明面向无人机目标检测的动态上下文关系采集网络结构中伪标签生成算法的流程图;
[0026]
图6是本发明面向无人机目标检测的动态上下文关系采集网络结构实施例中无人机在距离地面100m高空上拍摄的图像,dycc-net的检测效果图;
[0027]
图7是本发明面向无人机目标检测的动态上下文关系采集网络结构实施例中在近地面时,dycc-net的检测效果图。
具体实施方式
[0028]
下面结合附图和具体实施方式对本发明进行详细说明。
[0029]
本发明提出了面向无人机目标检测的动态上下文关系采集网络(dycc-net:dynamic context collectionnetwork)结构。如图2所示,dycc-net能够根据输入图像的的
复杂程度,选择性地执行上下文关系采集模块,从而实现对于输入的感知推理。本发明提出基于伪标签型的半监督学习策略(pseudo learning:pseudo-label-based semi-supervised learning strategy),该策略将生成的伪标签作为监督信号,根据输入的图像的难度,有效地分配计算资源。本发明中,dycc-net通过动态门,实现针对不同输入,执行或者跳过上下文关系采集模块。也就是说,针对简单的输入图像,dycc-net会跳过上下文关系采集模块,而对于复杂的输入图像,dycc-net会执行上下文关系采集模块。
[0030]
图3为dycc-net结构原理图,dycc-net由四个模块组成。第一个模块是骨干网络,用于特征提取。第二个模块是顶到底通路(top-down path),用于多尺度特征提取。第三个模块是本发明提出的动态上下文采集器(dycc:dynamic context collector),用于支持输入感知推理。最后一个模块是检测头,用于估算边框位置和分类得分。
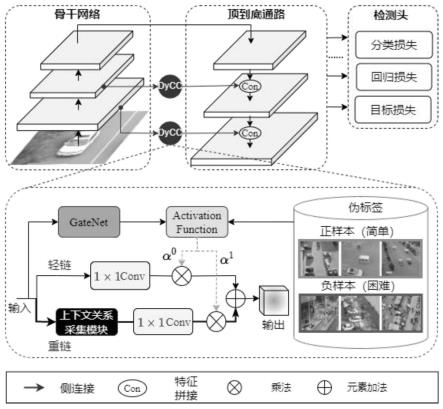
[0031]
dycc由三个组件构成,即动态门、重链和轻链。动态门包含门网络(gatenet)和激活函数,负责预测门信号,为输入分配相应的链
‑‑‑
即重链或者轻链。dycc的目标是针对简单图像或者复杂图像,分配不同的算力,从而降低计算成本。dycc-net的计算成本不会在训练期间降低,因为轻链、重链全都不加区分地处理简单图像或者复杂图像。在推理期过程中,简单输入只运行轻链而跳过重链,从而降低dycc-net的计算成本。
[0032]
动态门用于学习从输入图像特征图ci至门信号的映射函数。信号α是近似二维的one-hot编码,数值趋近于[0,1]时选择重链,数值趋近于[1,0]时选择轻链。在训练阶段,两条链的输出分别与两个元素α0和α1相乘。在测试阶段,如果动态门的输出值趋近于[1,0],重链会被忽略,只运行轻链。动态门由门控网络和门激活函数(activation function)组成。
[0033]
门控网络(gatenet)不但要准确地选择合适的链路,还要保证尽可能少的计算量。本发明设计了三种gatenet,如图4所示。图4中的第一个门控网络“gatenet-i”由一个全局平均池化层gap,两个全连接层fc1和fc2,以及一个relu层δ组成,该层输出一个二维矢量π。
[0034]
gatenet-i的计算成本约为轻链的gatenet-ii包括卷积层,计算量是轻链的10倍左右,gatenet-iii有包含池化层,计算量与轻链接近。另外还使用gumbel-softmax函数实现π逼近one-hot编码。可以用下列数学公式定义gatenet-i的输出
[0035][0036]
其中,ci是fpn第i层的输入。假设gatenet的输入特征的形状为hi×
wi×ci
(hi表示输入特征的长度、wi表示输入特征的宽度、ci表示输入特征的通道),输出特征形状为ho×
wo×co
(h0表示输出特征的长度、w0表示输出特征的宽度、c0表示输出特征的通道),gatenet-i的计算成本约为轻链的虽然,这个计算成本几乎可以忽略不计,但由于gap的ci层直接用1
×
1值表示hi×
wi特征图,所以gatenet-i提取的特征缺乏上下文关系信息。
[0037]
卷积层能够丰富特征图中的上下文关系信息。门控网络的第二种设计(“gatenet-ii”)采用3
×
3卷积层conv采集上下文关系信息。卷积层之后是全局平均池化层gap,用于捕获整个图像的上下文关系信息。最后,使用全连接层fc输出一个二维矢量π。可以用下列数学公式表示gatenet-ii的输出
[0038][0039]
门控网络(gatenet-iii)包含2
×
2的最大池化层max pooling,步长为2的3
×
3卷积层conv,然后是全局平均池化gap和一个全连接层fc。同样,也可以用数学公式表示gatenet-iii的输出
[0040][0041]
gatenet-iii的计算成本与轻链相近。因此,在实验中用gatenet-iii确定门信号。
[0042]
本发明将gumbel-softmax函数用作门激活函数,训练不可微决策的模型参数。如图4所示,gumbel-softmax函数用作类别概率π={π1,π2,...,πk}的连续微分函数,通过下式预测k维one-hot编码αi[0043][0044]
式中,i=1,...,k,gi,...,gk是gumbel(0,1)提取的独立同分布(i.i.d.:independent and identically distributed)样本,τ是温度参数。在τ较低的情况下,门控激活函数的输出接近one-hot编码,当τ提高时收敛到均匀分布。gumbel-softmax是连续分布α的偏导数估算器。
[0045]
本发明提出了基于伪标签半监督学习策略用于路径选择,称作“伪标签学习”。图5表示伪标签的生成过程。用伪标签标注简单图像和复杂图像。对于现有检测器能够轻易识别的简单图像,标注为1。对于现有检测器难以识别的复杂图像,标注为0。与无监督学习相比,我们提出的gatenet经过伪标签训练之后,可以更加合理地选择适当途径,取得更好的效率-精度平衡。图5中,灰框中的图像是未标签数据,这类数据送入训练好的基模型以估算平均精度。绿框中的图像是正样本,红框中的图像是负样本。
[0046]
本发明中的伪学习策略可以分为两步,即伪标签生成、利用生成的伪标签训练。首先,基线模型经过模型训练并完成目标检测标注,再用这个模型推理整个数据集中的所有图像。采用ap
50
指标评估各个图像的预测结果。ap
50
值高于规定阈值的图像标注为1(简单图像),ap
50
值低于规定阈值的图像标注为0(复杂图像)。我们将实验阈值设定为0.6。因此,我们可以生成数据集的伪标签。然后用生成的伪标签训练dycc-net,完成原始目标检测标注,从而保持目标检测性能。
[0047]
本发明的优点为:
[0048]
1.本发明提出了一种无人机视角的检测器,支持输入感知推理,称作dycc-net,该网络可以根据输入的复杂性忽略或者运行上下文采集模块,从而极大程度地减少冗余计算,提高推理效率。
[0049]
2.本发明设计了dycc,通过引入gumbel-softmax函数,解决离散变量在训练网络中梯度无法反向传播的问题。
[0050]
3.本发明提出了基于伪标签的半监督学习策略,称为“伪标签学习”,在该策略的指导下,将计算能力正确分配给各种输入,在效率与精度之间取得更好的折中。
[0051]
实施例
[0052]
在两个广泛使用的无人机捕获数据集,visdrone2021和uavdt,进行了大量实验。与最先进的10种方法对比,从而验证了dycc-net的有效性。采用ap
75
,ap
75
,map评价目标检
测结果。实验结果表明,dycc-net的推理时间不到目前最先进的检测器推理时间的三分之一,从而降低了模型的计算成本。经过本发明研究发现,dycc-net的ap
75
性能指标高出sota模型1.94%。总体实验结果如下图表1所示。
[0053]
表1
[0054][0055]
本发明所对比的模型均已发表于人工智能相关领域的顶级期刊或者会议上,包括cvpr、eecv、iccv、aaai、pr、tip等。对比的模型:ssd:single shot multibox detector,frcnn:fasterrcnn,yolov5:you only look once version five,dshnet:dual.sampler and head network,glsan:global-local self-adaptive network,clustdet:clustered detection,crenet:cluster region estimation network,tph-yolov5:transformerpredictionheads-yolov5,ufpmp-det:unified foreground packing detector。
[0056]
图6和图7分别展示了dycc-net在实际无人机图像上取得的目标检测效果。如图6所示,无人机在距离地面100m高空上拍摄的图像,dycc-net依然能够有效地检测远处公路
上的轿车。如图7所示,在近地面时,dycc-net能够检测密集区域的人群。由此可以看出,dycc-net可以有效地检测并识别无人机拍摄的目标。
[0057]
表2总结了基础模型与核心模块的消融实验结果。算法计算量的度量单位为flops。其中,yolov5+tinyhead+cc表示yolov5集成了低级、高分辨率特征图的预测头和上下文关系采集模块。最后一行数据表明,本发明dycc-net可以将yolov5+tinyhead+cc的计算成本降低约10%(flops为456.17g vs.505.46g),同时获得与sota相媲美的检测性能(recall为57.01%vs.57.16%,ap
50
为59.72%vs.59.98%)。
[0058]
表2
[0059]
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1