一种基于数据驱动的车辆转向灯健康监测和寿命预测系统
1.本发明涉及了一种车辆监测和控制预测系统,尤其是涉及了一种基于数据驱动的车辆转向灯健康监测和寿命预测系统。
背景技术:
2.作为汽车的主要构成部件之一,转向灯成为了车辆向外界传达行车状态的主要行经,行车过程中正确的使用转向灯,对周围的车辆和行人起到了安全提示和保障作用。随着汽车工业与电子技术的迅猛发展,转向灯的各项性能得到了显著的提升,其中基于嵌入式控制的led转向灯成为了主流。然而,转向灯的频繁启停控制和不间断的闪烁,极大的影响了其可靠性和使用寿命,如何在复杂工况下对车辆转向灯进行健康检测和寿命预测成为一个关键问题。汽车转向灯工作时产生的电流较小,环境变化导致的温度和电压波动,使得电流产生明显变化,极大的降低了转向灯的可靠性和使用寿命。人工智能技术的发展,基于数据驱动的系统在健康监测和寿命预测领域表现出卓越的性能。但是,现有的数据驱动系统主要采用离线诊断,诊断结果的实时性和可靠性依旧不足。此外,基于数据驱动的寿命预测系统依赖大量的高质量带标签样本,此项任务需要耗费大量的人力物力。因此,有必要设计一款具有低资源和少样本的实时监测系统,用于实现转向灯运行状态下的健康监测和寿命预测。
技术实现要素:
3.为了克服现有技术对汽车转向灯健康监测的不足,本发明提出了一种基于数据驱动的车辆转向灯健康监测和寿命预测系统,系统结合通过硬件采集转向灯的多源数据,并通过数据驱动的方式实现转向灯的健康监测和寿命预测。
4.与其他系统相比,本发明提出的系统可实现数据的低资源传输、连续过程检测、实时监测和寿命精准预测。结合小样本迁移学习技术,实现模型快速训练,模型的鲁棒性和泛化性得到极大提升。
5.本发明解决其技术问题所采用的技术方案是:
6.所述系统包括数据采集系统、数据传输系统和云端服务器;
7.数据采集系统,和车辆转向灯电连接,实时采集车辆转向灯的传感数据并发送到数据传输系统;
8.数据传输系统,和数据采集系统连接通信,接收车辆转向灯的传感数据并经过压缩采样处理后发送到云端服务器;
9.云端服务器,接收压缩采样处理后的车辆转向灯的传感数据进行处理实现车辆转向灯的健康监测和寿命预测。
10.所述的数据采集系统、数据传输系统布置在车辆,云端服务器布置在云端。
11.所述数据采集系统包括温度采集单元、照度采集单元、电流采集单元和电压采集单元;电流采集单元和电压采集单元分别连接到车辆转向灯的驱动电路上,所述温度采集
单元、照度采集单元、电流采集单元和电压采集单元均与485数据总线单元相连接,485数据总线单元连接到数据传输系统的压缩感知单元。
12.所述数据传输系统包括fpga处理单元、压缩感知单元和nb-iot数据传输网络单元;压缩感知单元和数据采集系统的485数据总线单元连接,fpga处理单元经压缩感知单元和nb-iot数据传输网络单元连接,nb-iot数据传输网络单元和云端服务器的数据恢复单元连接。
13.所述的云端服务器内包括数据传输系统和数据恢复单元,所述数据驱动系统包括源域模型训练单元和目标域模型预测单元;数据恢复单元和所述数据传输系统连接通信,数据恢复单元和源域模型训练单元均连接到目标域模型预测单元。
14.所述的云端服务器中,源域模型训练单元内设有源域模型,目标域模型预测单元内设有目标域模型,针对源域模型和目标域模型进行以下训练处理:
15.(1):将预先采集到车辆转向灯的温度、照度、电流和电压数据划分为训练样本和测试样本,训练样本较多数且不设置有故障类型标记,测试样本较少数且设置有标记;
16.(2):采用训练样本在源域模型训练单元内对源域模型进行预训练,获得训练后的源域模型;
17.(3):将训练后的源域模型的权重和偏差迁移到目标域模型的神经网络的卷积模块和随机池化层中;
18.(4):使用测试样本对标域模型进行微调处理,进一步优化调整神经网络的权重和偏差;
19.(5):将最终获得的目标域模型部署到目标域模型预测单元上用于车辆转向灯的实时健康监测和寿命预测。
20.本发明总系统中为保证监测和预测结果的可靠性同时,减少对标签数据量的依赖,引入了模型的小样本迁移学习来对所述源域模型和目标域模型进行训练。
21.所述源域模型主要由编码器和解码器组成:
22.所述编码器主要由输入层l、第一卷积层ec1、第一池化层ep1、第二卷积层ec2、第二池化层ep2依次连接构成,第一卷积层ec1、第一池化层ep1、第二卷积层ec2和第二池化层ep2均是由多个神经元构建而成,且神经元数量依次递减;
23.所述解码器主要由与解码器结构对称的神经元结构组成。所述解码器主要由第二池化层ep2、第三卷积层dc2、第三池化层dp2、第四卷积层ec1依次连接构成,第二池化层ep2、第三卷积层dc2、第三池化层dp2、第四卷积层ec1均是由多个神经元构建而成,且神经元数量依次递增。
24.所述编码器的第二池化层ep2和所述解码器的第二池化层ep2共用,为同一个第二池化层ep2。
25.所述目标域模型主要由卷积模块c1、随机池化层p1、卷积模块c2、随机池化层p2和连续三个全连接层依次连接组成。本发明是利用leaky relu激活函数和随机池化用于设计所述目标域网络模型结构。
26.考虑到模型在训练过程中需要大量的带标签样本,充足的样本需要传感器长时间采集,影响数据质量,并且在数据传输过程中需要可能会出现样本丢失或缺失等问题。本发明通过引入所述数据压缩感知、所述小样本迁移学习和无监督的自编码深度学习网络来减
少对高质量数据的依赖,以及引入小样本迁移学习实现模型训练,能够提高数据质量,提高检测预测的准确性。
27.本发明总系统用所述压缩感知技术,相较于奈奎斯特理论,可以用少量的测量值还原出原始的信号,减少了数据的传输量,在保证数据质量的同时,还具有一定的容错能力。
28.本发明以温度、照度、电流和电压作为原始数据来进行网络模型的训练和分类,通过多源数据的融合,使得模型的泛化性和鲁棒性得到提升。
29.本发明的有益效果为:
30.1)采用压缩感知技术对数据进行采样、重构,实现了少量测量值重构原始的信号功能,减少了无线数据的传输量。同时,在保证数据质量的同时,具有一定的容错能力,极大的保证了预测模型的鲁棒性。
31.2)采用嵌入式技术对转向灯运行时的温度、照度、电流和电压进行采集,通过多源数据的融合提高了转向灯健康检测和寿命预测模型的泛化性和鲁棒性。
32.3)结合小样本迁移学习和源域无监督模型的训练,减少了对带标签数据样本的依赖,减少了大量的人力成本。小样本迁移学习,通过利用源于模型的参数对目标域模型参数进行初始化,减少了目标域模型对测试样本的依赖和模型的训练时间,提高了模型的泛化性。
附图说明
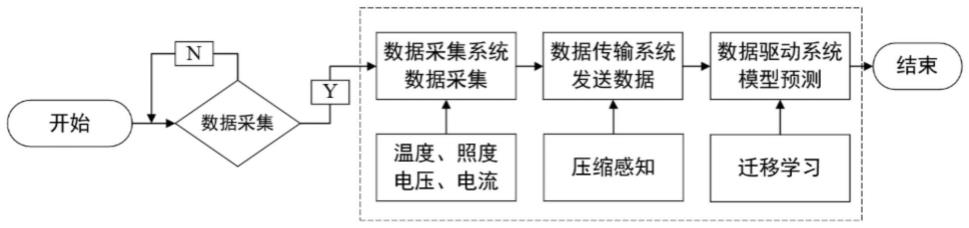
33.图1是本发明系统的运行流程图;
34.图2是本发明系统的整体架构示意图;
35.图3是网络模型的参数迁移过程示意图。
具体实施方式
36.下面对本发明做进一步说明。
37.如图1所示,本发明的具体实施例情况如下:
38.本发明系统的实施方法是:首先,利用温度传感器、照度传感器以及硬件电路,采集转向灯实际运行工况下的温度、照度、电压和电流;然后,利用fpga的并行计算能力,对采集的数据进行压缩感知进行,并将压缩数据发送至云服务器端;之后,使用数据驱动模型对重构数据进行特征提取;最后,利用提取的特征实现转向灯的健康监测和寿命预测。实现对转向灯健康监测的同时,降低维护成本,增加经济效益,并利用寿命预测,实现转向灯的预防性维护,减少突发故障带来的损失。
39.如图2所示,系统包括数据采集系统1、数据传输系统2和云端服务器4,上述系统在完成实际部署后,可实现实时监测与精准寿命预测;
40.数据采集系统1,和车辆转向灯电连接,实时采集车辆转向灯的传感数据并发送到数据传输系统2;
41.数据传输系统2,和数据采集系统连接通信,接收车辆转向灯的传感数据并经过压缩采样处理后发送到云端服务器;
42.云端服务器4,接收压缩采样处理后的车辆转向灯的传感数据进行处理实现车辆
转向灯的健康监测和寿命预测。
43.其中数据采集系统1、数据传输系统2布置在车辆上,云端服务器4布置在云端。
44.数据采集系统1包括温度采集单元1-2、照度采集单元1-1、电流采集单元1-4和电压采集单元1-3;电流采集单元1-4和电压采集单元1-3分别连接到车辆转向灯的驱动电路上,温度采集单元1-2、照度采集单元1-1、电流采集单元1-4和电压采集单元1-3均与485数据总线单元1-5相连接,485数据总线单元1-5连接到数据传输系统2的压缩感知单元2-2。
45.温度采集单元1-2、照度采集单元1-1通过传感器采集环境的温度和照度数据,电流采集单元1-4和电压采集单元1-3从车辆转向灯的驱动电路的硬件电路中进行采集获得电流和电压,485数据总线1-5将采集到的传感数据传输到数据传输系统中。
46.数据传输系统3包括fpga处理单元2-1、压缩感知单元2-2和nb-iot数据传输网络单元2-3;压缩感知单元2-2和数据采集系统1的485数据总线单元1-5连接,fpga处理单元2-1经压缩感知单元2-2和nb-iot数据传输网络单元2-3连接,nb-iot数据传输网络单元2-3和云端服务器4的数据恢复单元2-4连接。
47.数据采集系统中采集的传感数据发送到压缩感知单元2-2,fpga处理器单元2-1控制压缩感知单元2-2对传感数据进行压缩感知处理获得压缩采样后的传感数据,然后再通过nb-iot数据传输单元2-3将压缩采样后的传感数据传输至云端服务器4的的数据恢复单元2-4。
48.数据采集系统和数据传输系统通过fpga处理器单元和高速无线通讯单元实现连接。
49.在进行数据传输前,通过部署在边缘端的fpga处理器单元2-1对上述需要采集的数据,进行压缩感知,保证了数据的处理效率和传输的质量,并在云端服务器中,通过压缩感知恢复原始数据,在减少传输数据量的同时,实现一定的容错预测。
50.云端服务器4内包括数据传输系统3和数据恢复单元2-4,数据驱动系统3包括源域模型训练单元3-1和目标域模型预测单元3-2;数据恢复单元2-4和数据传输系统3的nb-iot数据传输网络单元2-3连接通信,数据恢复单元2-4和源域模型训练单元3-1均连接到目标域模型预测单元3-2。
51.数据恢复单元2-4和数据驱动系统3运行在云服务器4中。云端服务器4为数据恢复单元和数据驱动系统的运行平台,通过云端服务器4中的数据恢复单元2-4对压缩采样后的传感数据进行恢复操作获得恢复的传感数据,然后将恢复的传感数据发送到目标域模型预测单元3-2;
52.源域模型训练单元3-1预先接收输入的多源传感数据,包括温度、照度、电流和电压,对源域模型进行训练获得源域模型,然后将网络参数发送到目标域模型预测单元3-2;
53.目标域模型预测单元3-2根据恢复的传感数据进行检测和预测,从而利用部署在云端服务器中的目标域模型预测单元最终实现转向灯的健康监测与寿命预测。
54.云端服务器4中,源域模型训练单元3-1内设有源域模型,目标域模型预测单元3-2内设有目标域模型,针对源域模型和目标域模型进行以下训练处理:
55.1):将预先从外部实验采集到车辆转向灯的温度、照度、电流和电压数据划分为训练样本和测试样本,训练样本较多数且不设置有故障类型标记,测试样本较少数且设置有标记;
56.2):采用训练样本在源域模型训练单元3-1内对源域模型进行预训练,获得训练后的源域模型;
57.3):将经过良好训练的训练后的源域模型的权重和偏差迁移到目标域模型的神经网络的卷积模块和随机池化层中;
58.4):使用少量标记的测试样本对标域模型进行微调处理,进一步优化调整神经网络的权重和偏差;
59.5):将最终获得的目标域模型部署到目标域模型预测单元3-2上用于车辆转向灯的实时健康监测和寿命预测。
60.实时健康监测和寿命预测时是将实时获得的传感数据输入到目标域模型预测单元3-2,目标域模型预测单元3-2预测输出健康监测结果和寿命预测结果。
61.如图3所示,源域模型主要由编码器和解码器组成,网络模型的结构构建过程如下:
62.第一步:编码器搭建
63.编码器主要由输入层l、第一卷积层ec1、第一池化层ep1、第二卷积层ec2、第二池化层ep2依次连接构成,第一卷积层ec1、第一池化层ep1、第二卷积层ec2和第二池化层ep2均是由多个神经元构建而成,且神经元数量依次递减。
64.首先,数据恢复单元2-4对数据传输系统2压缩后的传感数据进行恢复还原,然后对同一时刻采集的四类传感数据进行归一化组合,以特征数为m构成一个m维的训练样本,输入到输入层l;
65.然后,将输入层l的数据再传输第一卷积层ec1通过卷积操作得到一个h
m1
×hd1
矩阵,m1代表卷积层数,d1代表卷积层ec1中神经元的个数;
66.之后,将第一卷积层ec1卷积得到的h
m1
×hd1
矩阵输入到第一池化层ep1进行池化操作,得到一个h
m1
×hp1
的特征矩阵,h
p1
代表经过池化后的数据维度;
67.在此基础上,再次经第二卷积层ec2进行卷积操作得到h
m2
×hd2
的卷积结果,最后再经第二池化层ep2进行池化操作得到h
m2
×hp2
的编码器输出矩阵;
68.卷积层和池化层矩阵维度关系:第二池化层《第二卷积层《第一池化层《第一卷积层《输入层的神经元数。
69.第二步,解码器搭建
70.解码器主要由与解码器结构对称的神经元结构组成。解码器主要由第二池化层ep2、第三卷积层dc2、第三池化层dp2、第四卷积层ec1依次连接构成,第二池化层ep2、第三卷积层dc2、第三池化层dp2、第四卷积层ec1均是由多个神经元构建而成,且神经元数量依次递增。
71.解码器输出最终得到一个1
×
d维矩阵。
72.源域模型以欧几里得范数作为损失函数,初始化权重和偏置参数α=(w
eci
,w
epi
,w
dcj
,w
dpj
,b
eci
,b
epi
,b
dcj
,b
pj
)。其中w
eci
,w
epi
和b
eci
,b
epi
分别为编码器的第i个卷积层和第i个池化层的权重和偏置;w
dcj
,w
dpj
和b
dcj
,b
pj
分别为解码器的第j个卷积层和第j个池化层的权重和偏置。最终,形成一个完整的源域模型,用于实现数据的预先无标签预测。
73.如图3所示,目标域模型主要由卷积模块c1、随机池化层p1、卷积模块c2、随机池化层p2和连续三个全连接层依次连接组成。
74.具体的网络模型的结构和参数如下:
75.卷积模块c1:卷积核窗长为64,步长为16,卷积核数目为16,输入特征大小为2048
×
1,输出特征大小为128
×
16,激活函数为leaky relu。
76.随机池化层p1:池化核的窗长2,步长2,输出特征大小为64
×
16。
77.卷积模块c2:卷积核窗长为3,步距为1,卷积核数目为32,输出特征大小为64
×
32,激活函数为leaky relu。
78.随机池化层p2:池化核窗长度为2,步距为2,输出特征大小为32*32。
79.全连接层1:神经元数量为512,
80.全连接层2:神经元128个。
81.全连接层3:神经元数量为10,激活函数为leaky relu。
82.具体实施中,数据采集系统中,照度采集单元采用bh1750,温度采集单元采用sht20,温度采集单元、照度采集单元、电流采集单元和电压采集单元采样频率为2hz,采样时间为10min。数据处理系统中的fpga处理器选型为ep4ce10f17c8n,提高了数据的处理能力。
83.本说明书的实施例所述的内容仅仅是对发明构思的实现形式的列举,仅作说明用途。本发明的保护范围不应当被视为仅限于本实施例所陈述的具体形式,本发明的保护范围也及于本领域的普通技术人员根据本发明构思所能想到的等同技术手段。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1