一种基于读写分离的HDFS随机读加速方法与流程
一种基于读写分离的hdfs随机读加速方法
技术领域
1.本发明涉及大数据存储领域,尤其涉及一种基于读写分离的hdfs随机读加速方法。
背景技术:
2.hdfs即hadoop分布式文件系统(hadoopdistributedfilesystem),以面向数据追加和读取优化的开源分布式文件系统,具备可移植、高容错性和大规模水平扩展的特性。作为海量数据的底层平台,hdfs存储了海量的结构化和非结构化数据,支撑着复杂查询、交互式分析等丰富的应用场景。hdfs的性能问题将影响所有大数据系统和应用,因此对hdfs存储性能的优化至关重要。
3.hdfs读写数据通过dataxceiverserver提供的服务建立socket服务,接受客户端的各种请求,每种请求有不同的操作码,服务端通过操作码类型判断请求类型。
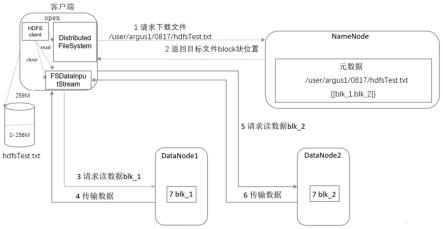
4.hdfs原生读流程如图1所示:
5.1)hdfs客户端向namenode发起rpc(远程过程调用),获得文件的开始部分或全部block列表(包含所在datanode列表,这些datanode会按照hdfs定义的拓扑结构得出客户端的距离,然后进行排序);
6.2)客户端通过namenode拿到所查文件的位置信息之后,构造blockreader对象用于读取数据,而blockreader会首先尝试建立blockreaderlocal(本地短路读),如果短路读不可用,则建立unixdomainsockets(unix域套接字),如果还是没有成功,则建立tcp连接进行远端读;
7.3)datanode接收到客户端的socket请求后,创建dataxceiver来响应请求,然后通过判断op的类型来进行相应的操作;如果是read_block会调用readblock方法,然后实例化blocksender对象将数据发送到客户端,发送方式分为两种,一种是使用传统方式读取数据,另一种是使用零拷贝方式实现数据传输;以packet为单位读取数据,直到这个block全部读完位置;
8.4)如果第一个block块读完,客户端关闭指向第一个block的datanode连接,继续访问namenode读取下一个block,重复2和3步直至读完所有数据;
9.5)client(hdfs客户端)将所有读的数据写入目标文件;
10.6)关闭连接。
11.整个查询过程流程比较复杂,并且在大规模小文件查询过程中会产生大量随机读,更加影响性能。
12.目前hdfs数据读取过程较复杂,存在大量校验,随着业务的查询要求越来越高,会存在大量的随机读请求且hdfs不适合处理大量随机读;我们在高并发大规模小文件查询过程中会产生大量随机读导致iobusy但ioread/write很小,磁盘真正的性能无法发挥出来,查询性能较慢,对业务影响较大。
技术实现要素:
13.本发明所要解决的技术问题是针对背景技术的不足提供一种基于读写分离的hdfs随机读加速方法,基于datanode进程建立dngrpcserver服务,简化数据读取流程,处理数据读取请求,拿到namenode查询的文件位置直接向对应的块位置的datanode发送grpc请求,通过传输粒度的较少加速数据传输,直接读取文件所在的磁盘位置,提高随机读能力。
14.本发明为解决上述技术问题采用以下技术方案:
15.一种读写分离的hdfs随机读加速方法,具体包含如下步骤;
16.步骤1,将hdfs的读和写完全分离;hdfs为hadoop分布式文件系统;
17.步骤2,将查询逻辑下沉至数据节点datanode,直接读取本地磁盘文件,从而简化读的流程,使性能接近本地文件系统的性能;
18.步骤3,利用hdfs的分布式及副本机制进行操作,文件的每个块都有多个副本存储在不同的数据节点datanode上,数据节点datanode会定时将磁盘块数据向名称节点namenode进行汇报,客户端查询时优先读取数据节点datanode的本地磁盘文件,保证数据的本地读取。
19.作为本发明一种读写分离的hdfs随机读加速方法的进一步优选方案,在步骤1中,数据的读和写采取hdfs的应用程序编程接口api,写入以顺序写为主,保持原分布文件系统文件夹hdfsdirectory机制不变。
20.作为本发明一种读写分离的hdfs随机读加速方法的进一步优选方案,在步骤1中,hdfs读,具体包含如下步骤:
21.步骤1.1,hdfs客户端client向名称节点namenode发起远程过程调用rpc,获得文件的块信息;
22.步骤1.2,hdfs客户端client根据块位置信息通过google远程过程调用grpc向指定数据节点datanode发起连接;
23.步骤1.3,数据节点datanode的数据节点远程过程调用服务dngrpcserver收到请求之后,初始化块读取器blockreader对象进行本地短路读,读完数据之后构造google远程过程调用grpc返回;
24.步骤1.4,继续访问名称节点namenode读取下一个块block,重复步骤1.2和步骤1.3直至数据读完;
25.步骤1.5,hdfs客户端client将所有读的数据写入目标文件;
26.步骤1.6,关闭连接。
27.作为本发明一种读写分离的hdfs随机读加速方法的进一步优选方案,在步骤1.1中,所述文件的块信息包含所在数据节点datanode列表。
28.作为本发明一种读写分离的hdfs随机读加速方法的进一步优选方案,在步骤2中,数据节点datanode进程:建立数据节点远程过程调用服务dngrpcserver服务,hdfs客户端数据节点client通过名称节点namenode拿到所查文件的位置信息之后,直接根据位置信息获取所在datanode地址,向所在数据节点datanode发送google远程过程grpc请求,datanode收到请求直接文件获取磁盘中的位置进行本地短路读。
29.本发明采用以上技术方案与现有技术相比,具有以下技术效果:
30.1、本发明一种读写分离的hdfs随机读加速方法简化hdfs数据读取流程,提高查询
效率;
31.2、本发明一种读写分离的hdfs随机读加速方法读写分离机制,提高处理能力;
32.3、本发明一种读写分离的hdfs随机读加速方法封装特有grpc,加速数据传输,减轻传输粒度;
33.4、本发明一种读写分离的hdfs随机读加速方法引用unixdomainsockets(unix域套接字),加强读取文件能力;
34.5、本发明一种读写分离的hdfs随机读加速方法逻辑下沉至datanode,直接和本地文件系统交互,提高磁盘ioread/write处理能力;
35.6、本发明基于datanode进程建立dngrpcserver服务,简化数据读取流程,处理数据读取请求,拿到namenode查询的文件位置直接向对应的块位置的datanode发送grpc请求,通过传输粒度的较少加速数据传输,直接读取文件所在的磁盘位置,提高随机读能力。
附图说明
36.图1是原生hdfs读流程示意图;
37.图2是本发明hdfs架构图示意图;
38.图3是本发明hdfs读数据流图。
具体实施方式
39.下面结合附图对本发明的技术方案做进一步的详细说明:
40.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
41.本发明将hdfs的读和写完全分离。数据的读写依然采取hdfs的api,写入以顺序写为主,保持原hdfsdirectory机制不变;将查询逻辑下沉至datanode,直接读取本地磁盘文件,从而简化读的流程,使性能接近本地文件系统的性能;同时利用hdfs的分布式及副本机制,即能保证数据本地读,同时简化了设计。
42.基于datanode进程建立dngrpcserver服务,简化数据读取流程,处理数据读取请求,拿到namenode查询的文件位置直接向对应的块位置的datanode发送grpc请求,通过传输粒度的较少加速数据传输,直接读取文件所在的磁盘位置,提高随机读能力。
43.一种读写分离的hdfs随机读加速方法,具体包含如下步骤;
44.步骤1,将hdfs的读和写完全分离;hdfs为hadoop分布式文件系统;
45.其中,数据的读写采取hdfs的api(applicationprogramminginterface应用程序编程接口),写入以顺序写为主,保持原hdfsdirectory(分布式文件系统文件夹)机制不变;
46.步骤2,将查询逻辑下沉至datanode(数据节点),直接读取本地磁盘文件,从而简化读的流程,使性能接近本地文件系统的性能;
47.步骤3,利用hdfs的分布式及副本机制进行操作,文件的每个块都有多个副本存储在不同的数据节点datanode上,数据节点datanode会定时将磁盘块数据向名称节点namenode进行汇报,客户端查询时优先读取数据节点datanode的本地磁盘文件,保证数据
的本地读取。
48.如图2所示,datanode(数据节点)进程建立dngrpcserver(数据节点远程过程调用服务)服务,client(hdfs客户端)通过namenode(名称节点)拿到所查文件的位置信息之后,直接根据位置信息获取所在datanode(数据节点)地址,向所在datanode(数据节点)发送grpc(google remoteprocedurecall,google远程过程调用)请求,datanode(数据节点)收到请求直接文件获取磁盘中的位置进行本地短路读。
49.本发明hdfs读流程如下图3所示,具体流程如下:
50.步骤1.1,hdfs客户端向名称节点namenode发起远程过程调用rpc,获得文件的块信息;所述块信息包含所在datanode列表;
51.步骤1.2,client(hdfs客户端)根据块位置信息通过grpc(googleremoteprocedure call,google远程过程调用)向指定datanode(数据节点)发起连接;
52.步骤1.3,datanode(数据节点)的dngrpcserver(数据节点远程过程调用服务)收到请求之后,初始化blockreader(块读取器)对象进行本地短路读,读完数据之后构造grpc(google remoteprocedurecall,google远程过程调用)返回;
53.步骤1.4,继续访问namenode(名称节点)读取下一个block(块),重复步骤1.2和步骤1.3直至数据读完;
54.步骤1.5,client(hdfs客户端)将所有读的数据写入目标文件;
55.步骤1.6,关闭连接。
56.下表为hdfs原生readfully与修改之后的hdfs的性能对比,基于新的随机读方式,提升了整体hdfs查询性能。其中表1为原生hdfs查读性能与修改之后的查询性能对比。
57.表1
58.数据大小原生readfullytps本次发明readfullytps性能提升4k110299228 8k1231101607 16k158895305
59.技术人员可以理解的是,除非另外定义,这里使用的所有术语(包括技术术语和科学术语)具有与本发明所属领域中的普通技术人员的一般理解相同的意义。还应该理解的是,诸如通用字典中定义的那些术语应该被理解为具有与现有技术的上下文中的意义一致的意义,并且除非像这里一样定义,不会用理想化或过于正式的含义来解释。
60.以上实施例仅为说明本发明的技术思想,不能以此限定本发明的保护范围,凡是按照本发明提出的技术思想,在技术方案基础上所做的任何改动,均落入本发明保护范围之内。上面对本发明的实施方式作了详细说明,但是本发明并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下做出各种变化。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1