基于伪单词序列生成的病例分类的零样本蒸馏系统及方法
本发明属于自然语言处理领域,具体指代基于伪单词序列生成的病例分类的零样本蒸馏系统及方法。
背景技术:
1、病例是医疗部门指某种疾病的实例,记录着某个人或生物患过某种疾病,病例对医疗、预防、教学、科研、医院管理等都有重要的作用。但是在实际情况中,很多病例数据无法获得,并且病例包含许多不同的类别信息,如果利用人工进行筛选,会增加很大的人力成本,并且病例太多出错率也会增加。病例数据分类是为了实现辅助疾病诊断,比如在对癌症分型或糖尿病等疾病类型判断中,需要根据医院检查的各项指标和患者自身病况来判断,但是鉴于数据隐私性,一些病人的医疗和个人特征数据一般不会公开。因此在实际情况下,我们想要得到一个轻量化易于部署的可以判断患者患病类型的模型,就可以通过经过这些未公开数据训练后的模型,生成这些数据的伪样本,并且蒸馏得到所需要的轻量化模型。所以在这种情况下,自然语言处理的零样本知识蒸馏便可以解决该问题。
2、首先介绍一下知识蒸馏,知识蒸馏最初由hinton提出,指通过引入训练好的复杂、但预测精度优越教师模型(teacher model),来诱导精简、低复杂度,更适合推理部署学生网络(student network)的训练,从而实现知识迁移(knowledge transfer)。
3、但是,在实际的蒸馏过程中,需要用到原始训练数据集,但是由于数据隐私性,诸如生物特征数据和病人的医疗保健等数据一般不会公开,所以原始训练数据不可得.。由此便提出了零样本的知识蒸馏。传统的自然语言处理零样本知识蒸馏,研究的数据集样本较多类别较少,生成伪样本的方式是离散的不易于优化,并且在生成伪样本的方式上有所欠缺。
4、有鉴于此,本发明提出的基于伪单词序列的伪样本生成方法,可以通过教师模型本身的词嵌入层,生成接近与原始数据的词嵌入向量在同一空间下的伪样本,连续易于优化,从而提高蒸馏性能。并且,本发明还在技术方面有创新,因为图像是连续的可以直接优化,所以图像较好生成,但是自然语言中的文本是离散的,不易于直接优化,所以本发明也从新的角度提出了文本伪样本生成方式。
技术实现思路
1、针对现有技术存在的缺陷,本发明的目的在于提供基于伪单词序列生成的病例分类的零样本蒸馏系统及方法,以解决现有技术中,文本单词生成离散不易于优化从而导致伪样本不接近于真实数据分布,蒸馏效果底下。本发明能够在由于数据隐私等原因导致的真实数据不可得的情况下,使得在真实数据上训练好的教师模型可以更好的转移和压缩其知识给轻量化的学生模型,从而方便部署,并达到知识转移的目的,并且本发明不需要单独的生成模型,可以直接通过教师模型词嵌入层优化连续的伪样本向量。
2、为达到上述目的,本发明采用的技术方案如下:
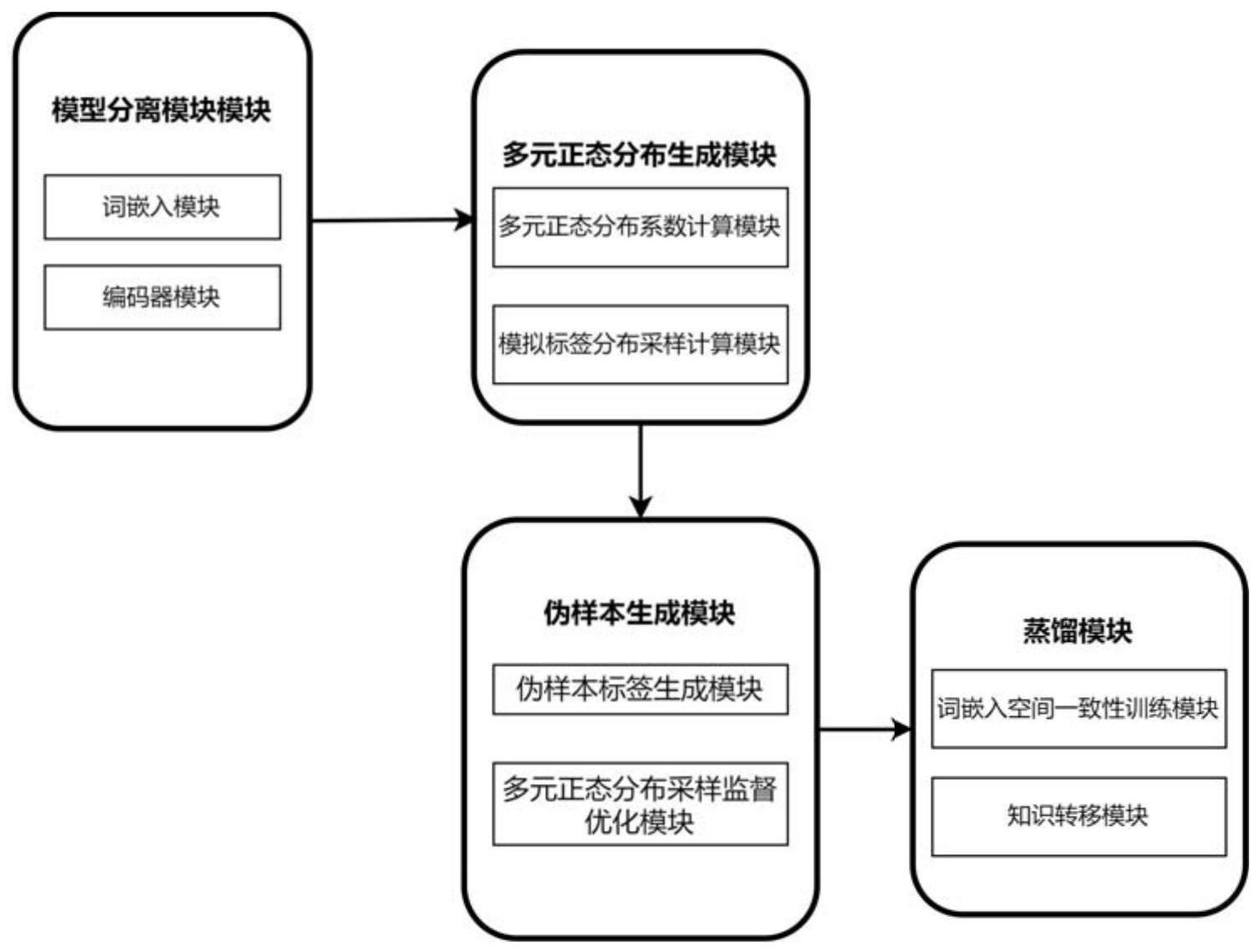
3、本发明的基于伪单词序列生成的病例分类的零样本蒸馏系统及方法,其特征在于,包括:模型分离模块;多元正态分布生成模块;伪样本生成模块;蒸馏模块;
4、所述模型分离模块,将教师模型分割成词嵌入层和剩余的编码层,并对公开病例数据集进行分句处理,本技术中的“公开病例数据集”为互联网上公开的病例数据集,包括心脏病,新冠感染等疾病的病例数据,要先对其进行分句处理;
5、所述多元正态分布生成模块包括:多元正态分布系数计算模块、模拟标签分布采样计算模块;
6、所述多元正态分布系数计算模块,根据训练好的教师模型的pooler层权重计算多元正态分布的相关系数矩阵,并且设置多元正态分布方差矩阵为对角线矩阵,计算得到协方差矩阵,计算类多元正态分布系数,得到对应的多元正态分布;
7、所述模拟标签分布采样模块,对得到的多元正态分布进行随机采样,并且对采样得到的样本进行softmax计算;
8、所述伪样本生成模块包括:伪样本标签生成模块、多元正态分布采样监督优化模块;
9、所述伪样本标签分布生成模块,从设定的最小值和设定的最大值之间进行均匀分布采样,用得到的样本代替bert词表中的单词索引输入到教师模型的词嵌入层得到词嵌入向量,再将其输入到教师模型中得到伪样本标签分布;
10、所述多元正态分布采样监督优化模块,将多元正态分布采样做伪样本标签分布的监督信息,优化教师模型分割出来的词嵌入层,直到得到符合要求的词嵌入向量,并且重新初始化词嵌入层;
11、所述蒸馏模块包括:词嵌入空间一致性训练模块、知识转移模块;
12、所述词嵌入空间一致性训练模块,将教师模型词嵌入向量与学生模型词嵌入向量经过线性层转换后处于同一空间内;
13、所述知识转移模块,将生成的词嵌入向量分别输入教师模型,以及学生模型的线性层,转化为设定维度的词嵌入向量,得到教师模型和学生模型输出的标签分布,将其对齐,从而把教师模型的知识迁移到轻量化的学生模型当中。
14、进一步地,所述多元正态分布生成模块通过将已经在真实训练数据上训练好的教师模型的词嵌入层和编码层进行分离,形成新的模型并保存;
15、所述新的模型包括:词嵌入层模块、编码器模块;
16、词嵌入层模块:对输入x进行转变,公式表达如下:
17、y=et(x)+es(x)+ep(x),
18、其中,et为将单词转换为固定维的向量表示形式算子,es为分割嵌入算子,ep为位置嵌入算子;
19、transformer编码器模块,采用注意力机制a,注意力机制具有q(query),k(key),v(value)三个来源于相同输入的矩阵,组成编码器fa,以及相应的残差机制和层归一化fn,公式表达如下:
20、
21、其中softmax的表达式为:
22、
23、n为softmax输入向量的n个值,
24、编码器的表达式为:
25、y=fn...(fn(fn(x+fa(x))+fa(fn(x+fa(x))))。
26、进一步地,所述对应的多元正态分布,公式表达如下:
27、
28、
29、σ=d·c·d
30、c(i,j)为类相似性系数,wi和wj分别为教师模型pooler层的第i位置和第j位置的神经元权重,d为由多元正态分布的每一元标准差组成的对角线矩阵,σ为多元正态分布的协方差矩阵。
31、进一步地,所述模拟标签分布采样模块在softmax计算过程中加入放缩系数调整得到的不同类别数据模拟标签分布的概率尖锐度。
32、进一步地,所述模拟标签分布采样模块,对多元正态分布进行采样得到噪声z,将其输入到教师模型最后一层分类线性层与权重w相乘中得到输出,并将该输出除以放缩系数α后输入到softmax函数fs中计算得到模拟标签分布,公式表达如下:
33、z~n(μ,σ)
34、
35、进一步地,所述伪样本标签分布生成模块-将随机生成的均匀分布整数代替bert词表中的单词索引x输入到教师模型的词嵌入层femb得到词嵌入向量,再将其输入到教师模型的编码层fec(θt)中得到伪样本标签分布-其中θt为教师模型参数,公式表达如下:
36、y=fec(femb(x),θt)。
37、进一步地,所述多元正态分布采样监督优化模块,利用采样得到的多元正态分布样本n作为标签信息,监督伪样本的生成,反向传播优化词嵌入层et,直到生成满足条件的伪样本作为最终的伪样本x,损失函数采用了交叉熵损失lce和kl散度损失lkl并且加入温度系数τ来控制标签分布尖锐度,公式表达如下:
38、
39、进一步地,所述词嵌入空间一致性训练模块,通过输入公开病例数据集第i个句子xi到教师模型的嵌入层et和学生模型的嵌入层es,将教师模型词嵌入向量与学生模型词嵌入向量经过线性层转换后做kl散度lkl处理,优化线性层使双方词嵌入向量处于同一空间内,公式表达如下:
40、
41、进一步地,所述知识转移模块,将生成的词嵌入向量x分别输入教师模型的编码层ft(θt),以及转换词向量维度的线性层ffc,转化为768维度的词嵌入向量,得到教师模型和学生模型输出的标签分布,将其对齐,从而把教师模型的知识迁移到轻量化的学生模型当中-采用kl散度lkl作为损失函数,优化学生模型的编码层fs(θs),公式表达如下:
42、
43、本发明的有益效果:
44、1、本发明考虑了数据隐私情景,病例数据包含病患者的年龄、性别、过往病历和身体的各项指标等,如癌症诊断分类数据集中包含肿瘤平均光滑度和平均半径等指标来共同判断癌症的种类。本发明通过已经训练好的病例分类教师模型,生成伪单词序列用于蒸馏过程,将教师模型的知识更好的转移和压缩到轻量化的学生模型当中,从而在没有原始病例数据集的情况下也可以得到学生模型,将其部署于相应的病例诊断场景,达到不错的诊断效果;
45、2、本发明通过多元正态分布采样模拟真实文本数据的标签分布,并将其作为监督信息生成伪单词序列,并且将公开病例数据集句子作为输入,监督生成模型生成伪样本;
46、3、本发明提出了一种新的文本生成方式,通过优化和生成连续的词嵌入向量作为伪单词序列,克服文本离散难以优化的缺点,并且以生成过程的损失作为约束条件,挑选满足条件的伪单词序列作为最优伪样本,从而进行下一步的蒸馏过程,将教师模型知识转移到学生模型中;
- 还没有人留言评论。精彩留言会获得点赞!