一种基于多通道脉动阵列的神经网络加速器
本发明属于计算机人工智能,尤其涉及一种基于多通道脉动阵列的神经网络加速器装置。
背景技术:
1、随着人工智能的飞速发展与应用,神经网络经历了从感知机、多层感知机到目前广泛运用的卷积神经网络的架构迭代,用于对神经网络加速的装置也经历了通用计算平台cpu、gpu到专用神经网络加速器平台的迭代,目前的专用神经网络加速器通常以脉动阵列实现矩阵运算,以实现神经网络结构中的卷积运算和全连接层运算。神经网络种类逐渐增多,神经网络的深度和广度也逐渐增加,数据量和计算复杂度的增加对神经网络加速器中的脉动阵列的吞吐率、利用率等提出了更高的要求。
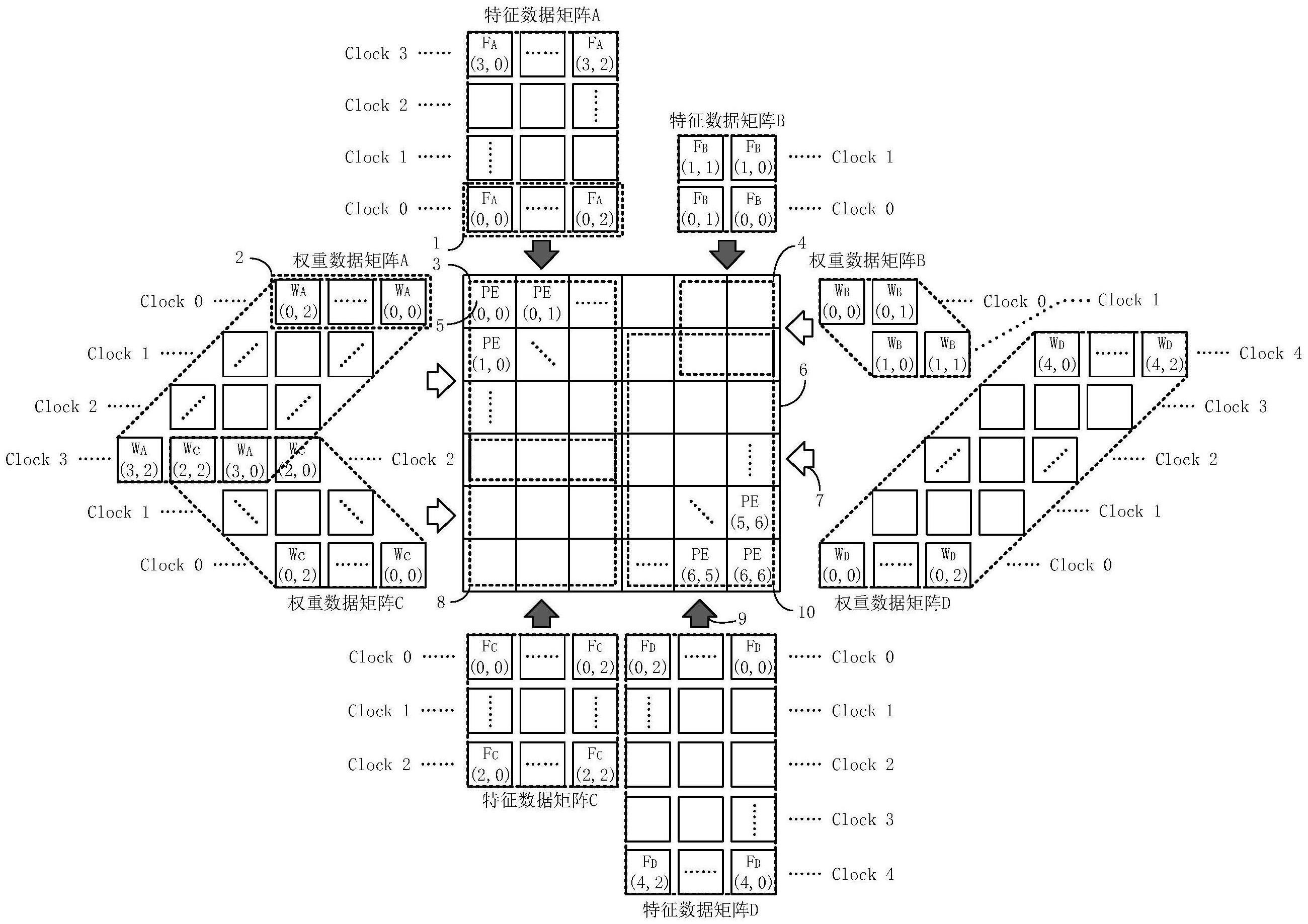
2、传统的脉动阵列一般仅有两个数据流通道,分别是特征数据流通道及权重数据流通道,两数据流通道的方向相互垂直。在计算的过程中,每个时钟周期两个数据流通道分别依次送入一组特征数据及一组权重数据。在clock0计算周期,特征数据流通道送入对应特征矩阵f(0,0)的单个特征数据到pe(0,0),权重数据流通道送入对应权重矩阵w(0,0)的单个权重数据到pe(0,0),pe(0,0)计算单元完成特征数据和权重数据的相乘后将特征数据和权重数据按数据流方向送给后续相邻pe单元;在clock1计算周期,特征数据流通道送入对应特征矩阵f(1,0),f(0,1)的两个特征数据分别到pe(0,0),pe(0,1),权重数据流通道送入对应权重矩阵w(0,1),w(1,0)的两个权重数据分别到pe(0,0),pe(1,0),对应pe单元对新送入的数据作乘法运算并和之前的结果累加。依次类推,在每个新的计算周期都将依次将特征数据和权重数据脉动送入脉动阵列中,最终完成对数据流的送入和计算。
3、传统的脉动阵列尽管在每个计算周期内可以实现多个pe计算单元的并行处理,但是传统的脉动阵列在面对多种类、复杂化的神经网络存在一定的缺陷:在面对不同规模、不同种类神经网络时,传统的脉动阵列只能以固定的pe计算单元规模、固定的数据流规模单线程的执行矩阵乘法运算,通常在一次加速运算中仅能针对一种类型的神经网络实现加速,在使得计算效率低下的同时也会浪费pe计算单元资源并不具备复用拓展性。传统的脉动阵列在加速处理的过程中存在数据处理时间以及结果载出时间过长的问题,从而在pe计算单元处理能力相同的情况下,需要更多的处理时长,导致吞吐率和计算速度的降低。
技术实现思路
1、本发明目的在于提供一种基于多通道脉动阵列的神经网络加速器装置,以解决基于传统脉动阵列的神经网络加速器处理时间过长、pe基本单元利用率偏低、不具备复用性及拓展性等问题。
2、为解决上述技术问题,本发明的具体技术方案如下:
3、一种基于多通道脉动阵列的神经网络加速器装置,包括由可配置数量的(n×n)个pe基本计算单元排布组成的多通道脉动阵列,所述多通道脉动阵列包括两方向四通道的多个特征数据流通道及两方向四通道的多个权重数据流通道。特征数据流通道用于将特征数据送入脉动阵列中;权重数据流通道用于将权重数据送入脉动阵列中。所述特征数据流通道及权重数据流通道在具体应用中的方向和个数可根据需求进行动态配置,若矩阵运算规模较大时可将数据流通道规模缩减,以支持大规模矩阵运算;若矩阵运算规模较小时可将数据流通道规模拓展,以支持多个小规模矩阵运算,可同时实现最多4个矩阵的并行运算。所述数据流通道通过增加数据流流向及数据流规模实现并行运算,可以在一个计算周期针对多个神经网络加速,避免了在小规模运算时pe基本单元的资源浪费,实现对pe基本单元的高效利用和复用,节省硬件开销。
4、进一步,所述多通道脉动阵列对特征数据流通道和权重数据流通道的数据流送入模式作了新的改进,传统脉动阵列的数据流通道每个计算周期以两个方向逐步送入单个或多个分离数据,多通道脉动阵列的数据流将在每个计算周期以多个方向送入整行的权重数据以代替分离数据。脉动阵列在计算的过程中,必须等待所有特征数据和权重数据都完全流过每个pe基本单元才能完成运算,传统的脉动阵列由于每个计算周期送入单个数据,故需要等待数据流过每个pe基本单元的时间会相对更长。假设特征矩阵规模为(m×p),权重矩阵规模为(m×n),在pe基本单元运算速度一致的情况下做对比。对于传统脉动阵列,当所有特征数据和权重数据都流过pe基本运算单元时,视为完成了一次处理,定义tp为所需处理时长,对于传统脉动阵列,有tp=m+p+n-2;由于传统脉动阵列以离散形式送入数据,所以在处理时间之外还需要一段时间使所有的运算结果载出,该载出时间等于脉动阵列中所用到的pe基本单元从左上角到右下角的步长,定义tl为载出时间,对于传统脉动阵列,有tl=p+n-1;由于前期送入的数据会在后期送入的数据处理的过程中率先载出,故对于整体脉动阵列处理时间和载出时间存在重叠,在减去重叠部分后可得传统脉动阵列的运算时间t=2p+m+n-2;所述多通道脉动阵列针对传统脉动阵列过高的运算时间做了改进,在每个计算周期将整体一行特征数据送入脉动阵列的一行pe基本单元中,与此同时其余特征数据保持静止,权重数据以离散的方式逐个送入该行pe基本单元中,处理时间等于在脉动阵列上移动特征数据长度所需的时间步数,因此对于多通道脉动阵列,有tp=p+n-1;所述多通道脉动阵列在计算得到第一个结果时就可以开始结果载出流程,从而使得载出时间和处理时间重叠比例大幅增加,所述多通道脉动阵列总的运算时间t=p+n+logm-1;所述多通道脉动阵列在理想情况下可以并行处理四种不同的网络矩阵,从而相比单线程传统脉动阵列可以实现最高三周期整体运算时间及单周期的优化时间,在处理并行四种神经网络加速的情况下最高可实现δt=(7p+4m+3n-logm-7)的运算时间缩减,从而大幅提升运算效率。
5、进一步,所述多通道脉动阵列基于可配置规模的(n×n)个pe基本运算单元阵列。所述pe基本单元接口包括上行pe特征数据输入输出接口、下行pe特征数据输入输出接口、左列pe权重输入输出接口、右列pe权重输入输出接口、运算结果输出接口;所述pe基本单元内部组件包括四个数据选择器、四个数据暂存寄存器、多通道结果寄存器组、通道选择器、乘法器及加法器。所述pe基本单元包括两个方向的权重输入接口及特征输入接口以满足多通道脉动阵列多方向多通道数据流的特性,pe基本单元能够同时接收来自四个输入输出接口的数据,通过控制器仲裁以实现对通道的选择以及数据的寄存。所述pe基本单元在每个计算周期将通过仲裁优先选择一个方向的pe特征输入接口及一个方向的pe权重输入接口用于接收当前计算周期所需处理的数据;对于其余输入接口的数据,若数据无需做运算处理,则通过数据选择器将其直接送入次级pe单元;若数据需做运算处理,则通过数据选择器将其暂存在数据暂存寄存器中待下一计算周期处理。对于需要处理的数据,则由通道选择器根据仲裁结果选择合适的通道,将待处理数据依次送入乘法器和加法器中完成矩阵乘法运算,将结果暂存在多通道结果寄存器组。所述多通道寄存器组根据不同的数据流输入方向组合,分别存储不同数据流方向输入数据的临时运算结果,并在下次该数据流组合的数据到来时,将临时数据送入加法器中做结果的累加。所述pe基本单元可以实现对四种数据流组合的仲裁运算,实现pe基本单元在多种数据流方向、多种神经网络情况下的复用,大幅节省了设计开销,并提高了pe基本单元的利用率。
6、本发明还提供了所配合的一系列组件,以实现基于多通道脉动阵列的神经网络加速器的功能。所述组件包括控制器单元、接口单元、存储器单元、池化激活单元。
7、所述控制器单元用于执行算法以适配不同类型的神经网络,并根据运算要求和算法配置仲裁控制数据流的通道数及流向,协调内部各硬件的工作;
8、所述接口单元包含四条并行的原始数据输入接口及结果输出接口、用于调试的外部接口、用于配置信息传输的配置信息接口,所述四条并行的输入输出接口基于axi协议总线实现,用于接受未经处理的原始数据及输出最终处理完成的结果,并通过仲裁以实现对四种不同神经网络的并行加速运算;所述调试接口基于apb协议实现,用于在不影响数据流输入输出的情况下查看并调试内部各硬件单元的处理结果。
9、所述存储器单元用于对原始数据做初始化处理,将原始的数据及流程中数据根据运算需求及算法配置转换为合适的特征矩阵数据,并对脉动阵列中间结果数据做缓存,根据配置将缓存数据处理后送入脉动计算阵列;
10、所述池化激活单元用于对中间结果数据做激活操作和池化操作,所述激活操作使用leakyrelu激活函数;所述池化操作使用最大值池化;
11、一种基于多通道脉动阵列的神经网络加速器装置,其工作流程如下:
12、s1,通过配置接口及原始输入接口取得配置信息,包括各神经网络的类型、网络的层数、卷积核的尺寸、步长等信息,根据所获得信息进行仲裁,根据多通道脉动阵列规模判断能并行处理的网络数量。
13、s2,根据控制器单元的仲裁结果,从接口单元取得待处理神经网络的权重数据等基本信息;接受多个输入接口的并行神经网络原始数据,并将其余接口的数据做暂存处理。
14、s3,启动神经网络运算,存储器单元对原始数据做数据整理,形成待处理的特征数据矩阵及权重数据矩阵。
15、s4,根据多个网络的特征数据矩阵及权重数据矩阵规模进行仲裁,将多个并行处理的网络数据分配到合适的数据流方向及数据流接口。
16、s5,根据仲裁结果,在对应的计算周期将特征数据和权重数据通过数据流送入多通道脉动阵列,在脉动阵列的pe基本计算单元中完成矩阵的乘加运算,并在脉动结束后将寄存器组中的数据整合为完整的结果数据;
17、s6,将经过多通道脉动阵列运算结束的数据送入激活与池化单元进行进一步的处理运算;
18、s7,控制器单元根据算法定义的神经网络的类型对经过处理后的数据作仲裁处理,经过存储器单元的进一步数据整合进行下层网络的运算或进行结果的输出;
19、本发明的优势和有益效果有以下方面:
20、本发明的一种基于多通道脉动阵列的神经网络加速器装置,对基于传统脉动阵列的神经网络加速器的脉动阵列部分做了提升运算效率和利用率的改进,由于改进后的多通道脉动阵列具有更多的数据流通道及数据流方向,所以能够同时使用多条数据流通道利用空闲的pe基本单元资源并行处理数据,提升了脉动阵列的利用率;由于改进后的多通道脉动阵列在数据流传输中采用整行特征数据的传输方式替代离散特征数据的传输方式,所以能够大幅减少处理时间中的结果载出延迟,提升了脉动阵列的运算效率;配合改进后的pe基本单元,所述装置能够在更小的硬件规格下实现对多种神经网络的并行加速处理,同时具有更高的运算处理速度及更高的脉动阵列利用率。
- 还没有人留言评论。精彩留言会获得点赞!