基于多源异构数据融合的硐室安全分析方法
1.本发明涉及信息融合技术领域,尤其是涉及基于多源异构数据融合的硐室安全分析方法。
背景技术:
2.硐室是一种未直通地表出口的、横断面较大而长度较短的水平坑道,其作用是安装各种设备、机器,存放材料和工具,或作其他专门用途,如机修房、炸药库、休息室等。现有技术下,对硐室安全分析还是基于风险源的评估,其大多采用ls法或lec法,比较依赖于定性描述以及专家评分。相对来说,更侧重于对硐室宏观评价,并不能从微观角度描述硐室具体情况。当然,也有专家或学者通过传感器采集硐室具体数据,然后利用机器学习模型对硐室安全分析,但其多属于单一数据源分析,不够准确。
技术实现要素:
3.本发明的目的是提供一种多源异构数据分析方法,以对硐室安全状态进行定量分析,从而解决现有分析方法不能反映硐室微观状况以及评价不准确的问题。
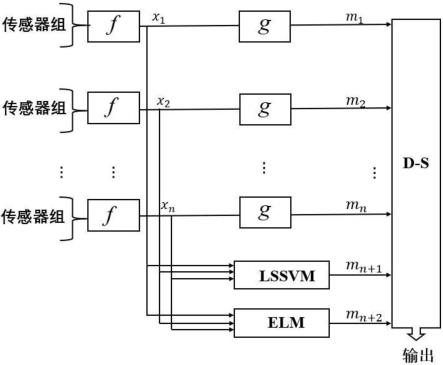
4.为实现上述目的,本发明提供了如下技术方案:基于多源异构数据融合的硐室安全分析方法,将硐室安全状态划分为安全、轻微事故和严重事故三种,然后对指标数据进行如下处理:g环节,针对三种状态设置三种隶属度函数,然后分别计算每个指标对应三种状态的隶属度,并将计算结果作为当前环节的三维预测数据;lssvm环节,利用最小二乘支持向量机模型对所有指标进行综合计算,得到当前环节对应三种状态的三维预测数据;elm环节,利用超限学习机模型对所有指标进行综合计算,得到当前环节对应三种状态的三维预测数据;ds环节,将g环节、lssvm环节、elm环节的三维预测数据作为证据体,然后利用ds证据融合模型对证据体计算,从而得到最终的硐室状态预测结果。
5.优选的,g环节之前还设置有f环节,f环节采用加权平均法或贝叶斯法对同一指标的多条数据进行融合。
6.优选的,ds环节还包括对证据体进行零处理和权重分配;零处理利用证据体内的最大值对零因子进行修正;证据体表示为,若,则零处理后的证据体表示为,其中为修正因子;权重分配首先计算证据体之间的相关性矩阵,计算公式如下:
,式中,为相关性矩阵;为证据体总数;为相关性矩阵中第i行第j列的元素,表示证据体之间的相关性;分别表示第个和第个证据体的标准差,分别表示第个和第个证据体的均值,表示期望;的计算公式如下 然后通过相关性矩阵确定权重,计算公式如下:最后,利用权重对证据体更新,计算公式如下:式中,为更新后的证据体。
7.优选的,g环节、lssvm环节、elm环节采用并行方式完成指标计算。
8.综上,本发明采用上述硐室安全分析方法,通过传感器采集硐室微观数据,并结合模糊处理方法、最小二乘支持向量机模型以及超限学习机分别对采集数据进行定量分析,得到证据体,然后通过改进的ds证据融合理论对证据体综合计算,从而实现多源角度硐室安全状态的精准评估。
附图说明
9.图1为本发明实施例的整体流程图;图2为本发明实施例中f环节的流程图;图3为本发明实施例中g环节的流程图;图4为本发明实施例中lssvm环节的流程图;图5为本发明实施例中elm环节的流程图;图6为本发明实施例中ds环节的流程图。
具体实施方式
10.以下结合附图和实施例对本发明的技术方案作进一步说明。
11.应力、b值、热辐射、形变是反映硐室安全状态的四个指标,本方案依据上述指标通过数据融合技术对硐室的安全状态做出判断。如图1所示,基于多源异构数据融合的硐室安全分析方法,首先通过多组传感器分别测得各自的指标值组。各个指标值组的值经过f环节得到各自的输出。作为输入有三个用处,一是通过g环节得到证据体,二是通过lssvm模型得到证据体,三是通过elm模型得到证据体。上述三环节得到的证据体通过ds证据融合算法得到最终的三维输出,三维输出的每个维度分别代表三种状态(安全、轻微事故、严重事故)的概率。
12.f环节:如图2所示,采用加权平均法或贝叶斯法进行数据级融合初步处理,以提高最终预测结果的准确性,该环节部分数据处理结果见表1。
13.表1f环节处理后的四类指标值g环节:如图3所示,采用模糊处理方法去对f环节输出的数据进行处理。涉及到三种安全状态
‑‑
安全、轻微事故、严重事故,相应的输出也应分别给出三种状态的预测值,即输出三维预测数据。因此,需要对三种安全状态各设置一个隶属度函数,其表达式表示如下。
14.应力、形变、b值和热辐射四个指标分别经历g环节,最终得到4个三维预测数据,即四个证据体。以表1第三条数据为例,经过g环节计算得到应力、形变、b值、热辐射的概率分布分别为,,,。
15.lssvm环节:如图4所示,采用最小二乘支持向量机模型(lssvm模型)对输入指标进行计算,得到三维预测数据。lssvm模型按监督学习方式对数据进行二元分类。当然,lssvm模型作为机器学习模型的一种,其使用之前需要通过历史数据集对初始模型训练,以找到代表三种状态分类器的最佳参数。以表1第三条数据为例,lssvm模型的据测输出为。
16.elm环节:如图5所示,采用超限学习机模型(elm模型)对输入指标进行计算,得到三维预测数据。elm是基于前馈神经网络构建的机器学习模型,其使用之前同样也需要通过
历史数据集对初始模型训练,以找到最佳的输入权重、隐藏节点数等,最终通过三个输出层分别输出代表三种状态的预测值。以表1第三条数据为例,elm模型的据测输出为。
17.lssvm环节和elm环节均是将应力、形变、b值和热辐射四个指标同时作为输入,并进行综合预测的模型,每个模型最终只得到一个证据体。
18.ds环节:基于ds证据融合模型对g环节、elm环节和lssvm环节得到的六个证据体进行计算,从而得到最终的预测结果。但实际当中不能用传统ds证据理论,因为有置信冲突的问题,所以需要对ds证据理论模型进行改进。如图6所示,本方案在融合计算之前,首先对证据体进行零处理和权重分配。
19.零处理就是对零因子进行修正,比如有一个证据体为[0,0.99,0.01], 证据体中有零因子,那么就把证据体中的最高值0.99匀一点(即修正因子q=0.01)给零因子,处理后的证据体也就是[0.01,0.98,0.01]。以表1中第三行数据为例,六个证据体经过零处理后变为,,,,, 。
[0020]
权重分配首先要计算证据体之间的相关性矩阵,然后利用相关性矩阵找到每个证据体的权重系数。相关性矩阵计算公式如下:,式中,为相关性矩阵;n为证据体的总数;为相关性矩阵中第i行第j列的元素,表示证据体之间的相关性;分别表示第个和第个证据体的标准差,分别表示第个和第个证据体的均值,表示期望。的计算公式如下得到相关性矩阵后,利用如下公式计算权重系数。
[0021]
并对它小于零的项进行处理,即小于零则赋值为0,最后通过权重系数对证据体更新,即证据体分别乘以权重系数。
[0022]
以表1第三条数据为例,首先根据上面相关性计算公式得到他的皮尔森相关性矩
阵为,把小于零的项赋值为零,并计算六个证据体的权重为,将权重与相应的证据体相乘即得到,然后对所得到的进行后续处理。
[0023]
得到了新的六个证据体后,再用传统的ds证据融合理论的公式进行计算得到最终的融合结果。ds证据融合计算方法如下:式中,为事件的集合,本文中即安全、轻微事故、严重事故这三个事件的集合;为冲突系数;表示各环节产生的证据体。
[0024]
以表1中第三行数据为例,得到最终的数据融合结果为,所以融合结果判定硐室状态为轻微事故。
[0025]
此外,本方案在g环节、elm环节和lssvm环节采用了并行计算方式,以加快数据处理速度。
[0026]
以上是本发明的具体实施方式,但本发明的保护范围不应局限于硐室安全分析。任何熟悉本领域的技术人员在本发明所揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内,因此本发明的保护范围应以权利要求书所限定的保护范围为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1