一种结合自监督和有监督的早产儿眼底图像异常检测方法
1.本发明属于计算机视觉与医疗辅助技术领域,更为具体地讲,该发明涉及一种结合自监督和有监督的早产儿眼底图像异常检测方法。
背景技术:
2.随着医学成像技术和计算机技术的不断发展和进步,医学图像分析已成为医学研究、临床疾病诊断和治疗中一个不可或缺的工具和技术手段。近几年来,深度学习(deep learning,dl),特别是深度卷积神经网络(convolutional neural networks,cnns)已经迅速发展成为医学图像分析的研究热点,它能够从医学图像大数据中自动提取隐含的疾病诊断特征。有效的机器学习技术使医疗专业人员能够做出更好的决策,为疾病的识别和研究带来创新,也能更好地提高医疗诊断和临床实验的效率。
3.早产儿视网膜病(rop)是指多病因(早产、低出生体重、氧疗等)引起的视网膜血管发育异常的眼底疾病。主要发生在早产儿及低出生体重儿。该病是世界范围内新生儿致盲的首要原因,约占儿童致盲原因的6%~18%。尽管绝大部分早产儿视网膜病可自行退化,但仍有部分早产儿可进展为较严重的早产儿视网膜病,导致患儿失明。然而,很多地区专门从事rop的眼科医生很少,这为新生儿的健康诊断造成了不便。为了解决专业诊断医生数量不足以及rop诊断效率低的问题,目前已经出现了一些使用传统机器学习手段辅助rop诊断的方法,比如采用卷积神经网络模型等方法对rop患者的眼底照片进行检测。但使用这种方法构建一个好的神经网络模型往往需要大量高质量的有标签数据,这需要专业的医生花费大量的时间、精力以及金钱去对图像进行标注,这是一项困难且繁重的任务。同时,在一定区域内,rop患者的数目也是有限的,导致没有足够的异常数据来支撑一个模型,而且很有可能还会因为数据量小而导致模型在不同地区的泛化性能较差。所以在实际情况中,很难通过传统的方式来训练一个好的神经网络模型,这对于医学诊断是不利的。
4.无监督学习是指:当我们缺乏足够的先验知识,难以进行人工标注类别或进行人工类别标注的成本太高时,我们希望计算机能代我们完成这些工作,或至少提供一些帮助。根据类别未知(没有被标记)的训练样本解决模式识别中的各种问题,称之为无监督学习。
5.自监督学习(self-supervised learning)是无监督学习的一种,可以被看作是机器学习的一种“理想状态”,模型直接从无标签数据中自行学习,无需标注数据。其核心在于,如何自动为数据产生标签。例如,把输入的图片均匀分割成3*3的格子,每个格子里面的内容作为一个patch,随机打乱patch的排列顺序,然后用打乱顺序的patch作为输入,正确的排列顺序作为标签,进行网络的训练。类似这种自动产生的标注,完全无需人工参与。根据深度学习的特性,我们可以将自监督学习得到的知识迁移到新的任务中去,比如图像分类的任务,这样就可以解决数据量缺乏而导致训练不充分或过拟合的问题。
6.由于正常眼底图像容易获得,且数量很多,所以可以用来进行自监督学习,将学习到的知识迁移到有标签的分类任务中去。更进一步的,实验发现,自监督学习的特征具有更好的泛化性能,而有监督任务学习到的特征则包含更高级的语义信息,若将两者学习到的
特征拼接在一起,当作一个整体特征,就可以极大增强分类模型的特征提取能力和泛化能力,以此大幅提升模型的准确性和鲁棒性。
技术实现要素:
7.本发明的目的在于克服现实情况下,大量高质量的有标签眼底图像难以获得,有限的数据量导致传统有监督学习训练出的rop判别模型的准确性、鲁棒性和泛化能力较低的问题。因此我们提出了一种基于自监督和有监督学习特征相结合的策略,可以显著提高对rop眼底图像诊断的性能。
8.为实现上述发明目的,本发明基于自监督学习和有监督学习特征相结合的rop异常检测算法,其特点在于首先利用正常眼底图像的大量数据进行无监督学习,学习到更利于新任务泛化的图像特征。同时,利用相对少量的高质量有标签的正常眼底图像和异常眼底图像进行有监督的学习,学习图像更丰富的语义特征,最后将这两种特征进行拼接,得到一个更加丰富的图像特征,再对这个特征进行线性分类,完成异常检测即可,具体包括以下步骤:
9.(1)数据收集
10.从医院采集大量正常眼底照片,越多越好,此部分用作自监督学习。
11.除此之外,还需要尽可能采集正常眼底图像和患者眼底图像,其中患者眼底图像中需要包含各个阶段的异常眼底图像,这部分图像用作有监督学习。
12.要求采集到的每组图像按眼球为单位来保存。同时要求用作有监督学习的正常眼底和有患病特征的眼底图像的数量尽量均衡,图片均为彩色三通道图像。
13.(2)图像标注
14.对用作自监督学习的图像不做标注处理。
15.对用作无监督学习的图像由医学专家进行审核标注,默认将来自正常人的眼底图像标签默认赋值为0,对于来自rop患者的眼底图像,如果图像中没有rop患病特征,可以认为是正常图像,但为了防止引入数据噪声,这部分图像忽略不计,若有患病特征则标记为rop图像,赋值为1。图像数据依旧以眼球为单位进行存放。
16.另外,这两部分数据都应该按训练集、验证集、测试集的方式进行划分。
17.(3)数据预处理
18.这里我们主要使用三种数据处理的方式。
19.①
数据清洗:
20.由于拍摄操作存在一定的偶然性,会引入不同程度的图像噪声,比如图像模糊不清,或者有大面积的图像亮斑等,所以首先将这部分图像进行删除。另外在图像存储时,因保存格式的不同会导致图像分布有所差异,故统一为.png格式保存。
21.②
图像规范化:
22.由于原始图像尺寸不一致,且图像较大,冗余特征过多。因此对图像在保留其原始特征的情况下进行压缩,统一将原始图像尺寸resize为224
×
224.
23.③
光照调节
24.眼底图像受拍摄环境的影响较大,这会导致图像有不同程度的亮度差异以及图像会出现不同程度的亮斑,所以采用均匀分布来调整图像的亮度。
25.(4)数据增强
26.这里我们主要使用三种数据增强的方式。
27.①
色彩变换
28.由于不同人的眼睛色素存在一些差异,所以拍摄出的图像底色也会有不同的差异,所以对图像进行轻微的色彩变化,并扩充图像的数量,降低色彩不一致带来的影响。
29.②
图像旋转
30.由于网络的训练需要尽可能多的数据,所以对图像进行随机轻微旋转和镜像翻转来继续扩充图像数据。
31.③
图像标准化
32.为了尽可能减少奇异数据对模型带来的不良影响,我们使用z-score标准化方法,对图像的r、g、b三个通道的像素值分别进行标准化处理,即:
[0033][0034]
其中x
scale
是归一化后的新的图像数据,x是原始图像,μ是所有样本均值,σ是样本标准差。
[0035]
(5)模型选择
[0036]
由于需要捕捉细微的图像特征且实验表明无监督学习在更深的网络下表现更好,所以我们选择resnet50作为backbone训练两种方式下的图像特征提取器。
[0037]
(6)自监督特征提取器
[0038]
在本阶段使用划分好的大量正常图像作为数据集,将图像划分成3*3的patch,将其进行随机打乱再将正确的顺序作为标签,让模型进行排序,训练一个神经网络,然后去掉输出层,保留全连接层,作为特征提取器,全连接层的输出作为图像表征。
[0039]
(7)有监督特征提取器
[0040]
在本阶段使用标注过的眼底图像作为数据集,使用传统的有监督学习训练方式,训练另一个神经网络,同理去掉输出层,保留全连接层作为特征提取器,该特征提取器同样输出图像的表征。
[0041]
(8)最终分类模型训练
[0042]
在本阶段,将自监督过程所得到的图像特征和有监督阶段的图像特征拼接在一起,作为一张图像的表征,输入一个简单的逻辑回归分类器中,使用正常的训练方式训练该分类器即可。
[0043]
(9)最终测试
[0044]
在最终测试阶段,即模型整体评估预测的阶段,将训练阶段最好结果的模型参数载入模型,此时模型参数不需要再进行学习调整,全部固定,然后给模型输入提取出的眼底图像表征,得到分类结果,并对所有的结果进行整合,得到相应的统计结果即可。
附图说明
[0045]
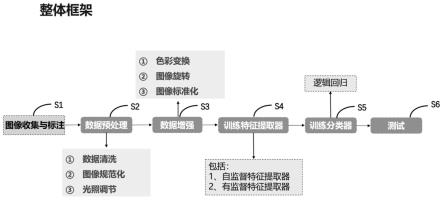
图1是本发明一种基于自监督和有监督特征相结合的早产儿视网膜病异常检测方法流程图;
[0046]
图2是数据预处理示意图;
[0047]
图3是数据增强示意图;
[0048]
图4是特征提取器训练示意图;
[0049]
图5是线性分类器训练过程的示意图。
具体实施方式
[0050]
下面结合附图对本发明的具体实施方式进行描述,以便本领域的技术人员更好地理解本发明。需要特别提醒注意的是,在以下的描述中,当已知功能和设计的详细描述也许会淡化本发明的主要内容时,这些描述在这里将被忽略。
[0051]
图1是本发明基于自监督和有监督特征相结合的早产儿视网膜病(rop)异常检测方法流程图。
[0052]
在本流程中,如图1所示,本发明基于自监督和有监督特征相结合的早产儿视网膜病(rop)异常检测方法包括以下步骤:
[0053]
s1:原始图像收集与标注
[0054]
(1)图像收集
[0055]
首先,需要从医院采集大量正常眼底照片,越多越好,此部分用作自监督学习。其次,需要尽可能采集另一批正常眼底图像和患者眼底图像,其中患者眼底图像中需要包含各个阶段的异常眼底图像,这部分图像用作有监督学习。
[0056]
要求采集到的每组图像按眼球为单位来保存。同时要求用作有监督学习的正常眼底和有患病特征的眼底图像的数量尽量均衡,图片均为彩色三通道图像。
[0057]
(2)图像标注
[0058]
对用作自监督学习的图像不做标注处理。
[0059]
对用作无监督学习的图像由医学专家进行审核标注,默认将来自正常人的眼底图像标签默认赋值为0,对于来自rop患者的眼底图像,如果图像中没有rop患病特征,可以认为是正常图像,但为了防止引入数据噪声,这部分图像忽略不计,若有患病特征则标记为rop图像,赋值为1。图像数据依旧以眼球为单位进行存放。
[0060]
s2:数据预处理
[0061]
这里我们主要对数据进行下述三种方式的预处理。
[0062]
①
数据清洗:
[0063]
由于拍摄操作存在一定的偶然性,会引入不同程度的图像噪声,比如图像模糊不清,或者有大面积的图像亮斑等,所以首先将这部分图像进行删除。
[0064]
②
图像规范化:
[0065]
由于原始图像尺寸不一致,且图像较大,冗余特征过多,不便数据传输和神经网络计算。因此对图像在保留其原始特征的情况下进行压缩,统一将原始图像尺寸resize为224
×
224.
[0066]
③
光照调节
[0067]
眼底图像受拍摄环境的影响较大,这会导致图像有不同程度的亮度差异以及图像会出现不同程度的亮斑,所以采用均匀分布来调整图像的亮度。
[0068]
s3:数据增强
[0069]
这里我们主要使用三种数据增强的方式。
[0070]
①
色彩变换
[0071]
由于不同人的眼睛色素存在一些差异,所以拍摄出的图像底色也会有不同的差异,所以对图像进行轻微的色彩变化,并扩充图像的数量,降低色彩不一致带来的影响。
[0072]
②
图像旋转
[0073]
由于网络的训练需要尽可能多的数据,所以对图像进行随机轻微旋转和镜像翻转来继续扩充图像数据。
[0074]
③
图像标准化
[0075]
为了尽可能减少奇异数据对模型带来的不良影响,我们使用z-score标准化方法,对图像的r、g、b三个通道的像素值分别进行标准化处理,即:
[0076][0077]
其中x
scale
是归一化后的新的图像数据,x是原始图像,μ是所有样本均值,σ是样本标准差。
[0078]
s4:训练特征提取器
[0079]
(1)模型选择
[0080]
由于需要捕捉细微的图像特征且实验表明无监督学习在更深的网络下表现更好,所以我们选择resnet50作为backbone训练两种方式下的图像特征提取器。
[0081]
(2)自监督特征提取器
[0082]
在本阶段使用划分好的大量正常图像作为数据集,将图像划分成3*3的patch,将其进行随机打乱再将正确的顺序作为标签,让模型进行排序,训练一个神经网络,然后去掉输出层,保留全连接层,作为特征提取器,全连接层的输出作为图像表征。
[0083]
(3)有监督特征提取器
[0084]
在本阶段使用标注过的眼底图像作为数据集,使用传统的有监督学习训练方式,训练另一个神经网络,同理去掉输出层,保留全连接层作为特征提取器,该特征提取器同样输出图像的表征。
[0085]
s5:训练最终的分类模型
[0086]
在本阶段,将有标签图像经过两个特征提取器提取特征,然后将自监督过程所得到的图像特征和有监督阶段的图像特征拼接在一起,作为一张图像的表征,输入一个简单的逻辑回归分类器中,使用正常的训练方式训练该分类器即可。
[0087]
s6:测试
[0088]
在最终测试阶段,即模型整体评估预测的阶段,将训练阶段最好结果的模型参数载入模型,此时模型参数不需要再进行学习调整,全部固定,然后给模型输入提取出的眼底图像表征,得到分类结果,并对所有的结果进行整合,得到相应的统计结果即可。
[0089]
本发明中,针对现实情况的数据限制以及传统训练策略得到网络准确性、鲁棒性以及泛化能力较低的问题提出了一种基于自监督和有监督学习特征相结合的策略。本发明中在rop分类和医学图像分类等关键技术上做出了创新。
[0090]
尽管上面对本发明说明性的具体实施方式进行了描述,以便于本技术领域的技术人员理解本发明,但应该清楚,本发明不限于具体实施方式的范围,对本技术领域的普通技术人员来讲,只要各种变化在所附的权利要求限定和确定的本发明的精神和范围内,这些
变化是显而易见的,一切利用本发明构思的发明创造均在保护之列。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1