面向流程型工业生产数据流的回归模型选择方法及系统与流程
本发明涉及流程型工业生产,尤其涉及一种面向流程型工业生产数据流的回归模型选择方法及系统。
背景技术:
1、随着机器学习技术在流程型工业生产过程中的广泛应用,数学模型性能的好坏直接影响对生产过程的控制效果。现有技术中,回归类数学模型的建立主要依赖人为的经验进行超参数设定,通过mae、mse、rmse等模型评判指标作为评判标准对超参数不断调整,最后选择最佳的模型作为输出结果。
2、在流程型的工业生产场景下,由于生产工况不稳定性,要求数学模型具有高效的自动更新能力以适应工况的频繁波动,而人力无法像机器一样进行大量的迭代尝试且缺少对模型持续有效性的检测。
技术实现思路
1、(一)要解决的技术问题
2、鉴于现有技术的上述缺点、不足,本发明提供一种面向流程型工业生产数据流的回归模型选择方法及系统,其解决了现有技术中依赖人为经验确定回归模型导致效率低下以及现有技术中不能确定出一个能够综合反映出最有效的回归模型的技术问题。
3、(二)技术方案
4、为了达到上述目的,本发明采用的主要技术方案包括:
5、第一方面,本发明实施例提供一种面向流程型工业生产数据流的回归模型选择方法,所述方法包括:
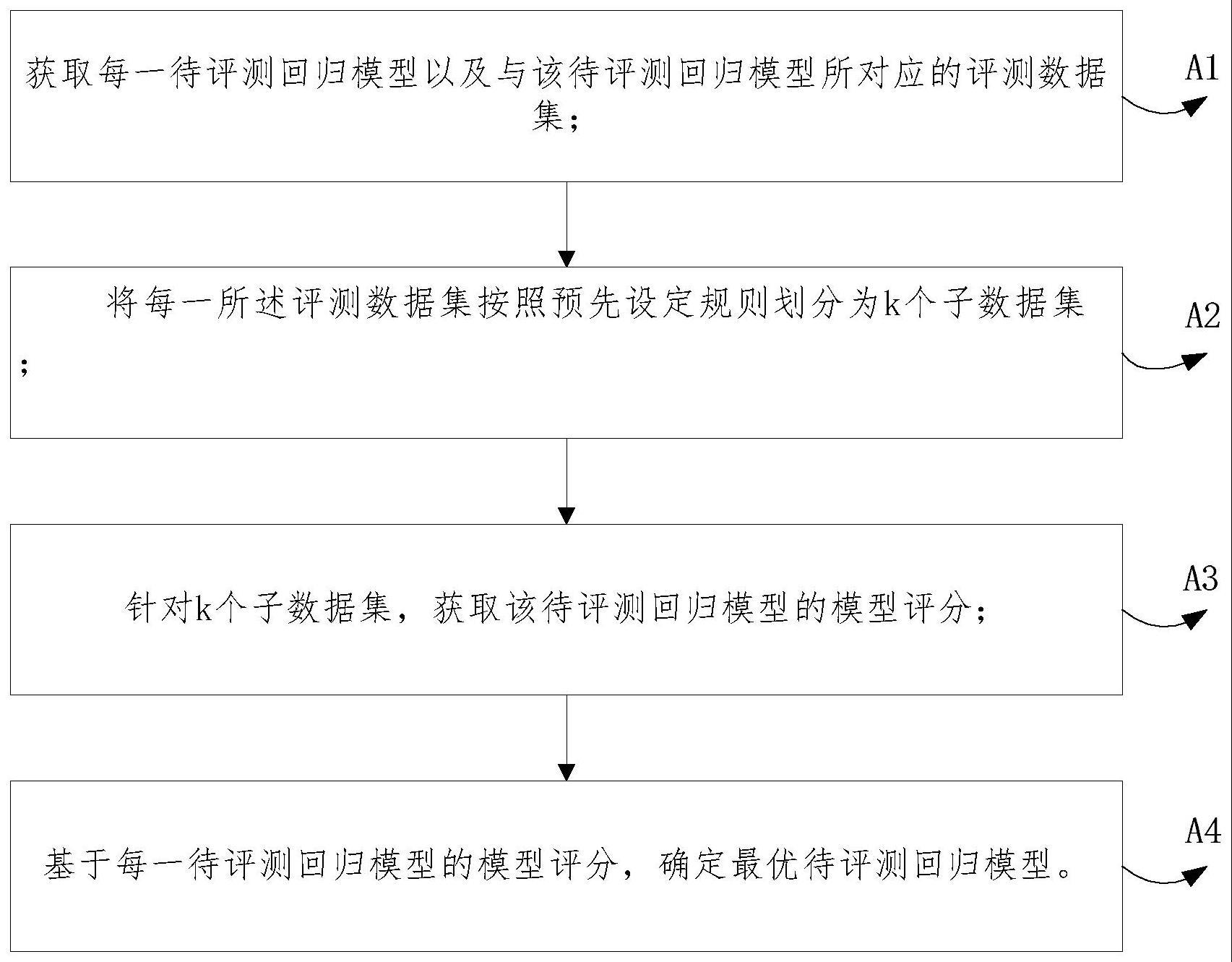
6、a1、获取每一待评测回归模型以及与该待评测回归模型所对应的评测数据集;
7、a2、将每一所述评测数据集按照预先设定规则划分为k个子数据集;
8、a3、针对k个子数据集,获取该待评测回归模型的模型评分;
9、该待评测回归模型的模型评分由每一子数据集的评测指标值计算得到;其中,每一子数据集的评测指标值包括:修正误差百分比指标值、拟合度相似指标值、向量相似性指标值、结构相似指标值;
10、a4、基于每一待评测回归模型的模型评分,确定最优待评测回归模型。
11、优选地,
12、其中,与该待评测回归模型所对应的评测数据集包括:n条评测数据;
13、每条评测数据包括:该待评测回归模型训练所使用的自变量及与该自变量对应的因变量的实际值以及与该自变量对应的待评测回归模型所得到的因变量的预测值和表示该条测评数据时间的时间戳。
14、优选地,所述a2具体包括:
15、按照时间顺序将评测数据集随机划分为k个子数据集;
16、其中,k为预先设定值,且k≥5;
17、其中,该评测数据集所对应的k个子数据集满足:
18、任一子数据集包含测评数据的条数大于10;
19、任意两个子数据集之间不相交;
20、最大子数据集的测评数据的条数小于等于最小子数据集的测评数据的条数的2倍。
21、优选地,所述a3具体包括:
22、a31、针对k个子数据集,分别获取每一子数据集的评测指标值;
23、a32、基于每一子数据集的评测指标值,获取与该k个子数据集所对应的待评测回归模型的第一评测矩阵;
24、a33、基于所述待评测回归模型的第一评测矩阵和预先设定的阈值,获取该待评测回归模型的第二评测矩阵;
25、a34、基于所述待评测回归模型的第二评测矩阵,获取所述待评测回归模型的模型评分。
26、优选地,
27、所述修正误差百分比指标值预先采用公式(1)计算得到;
28、所述公式(1)为:
29、
30、其中,s1(y_true,y_pred)为所述修正误差百分比指标值;
31、y_truei为该子数据集中的第i条测评数据中的因变量的实际值;
32、y_predi为该子数据集中的第i条测评数据中的因变量的预测值;
33、n为该子数据集中测评数据的条数;
34、所述拟合度相似指标值预先采用公式(2)计算得到;
35、所述公式(2)为:
36、s2(y_true,y_pred)=1-|1-w|;
37、其中,w为针对该子数据集预先利用最小二乘法求解使得损失函数的损失值最小化时所对应的参数w;
38、所述损失函数为:
39、其中,e为损失函数的损失值;
40、εi为该子数据集中第i条测评数据所对应的预先设定的服从标准正态分布的随机项;
41、s2(y_true,y_pred)为拟合度相似指标值;
42、所述向量相似性指标值预先采用公式(3)计算得到;
43、所述公式(3)为:
44、
45、其中,
46、其中,s3(y_true,y_pred)为向量相似性指标值;
47、所述结构相似指标值预先采用公式(4)计算得到;
48、所述公式(4)为:
49、
50、其中,μ1为该子数据集中因变量的实际值y_true的均值;
51、μ2为该子数据集中因变量的预测值y_pred的均值;
52、σ1为该子数据集中因变量的实际值y_true的方差;
53、σ2为该子数据集中因变量的预测值y_pred的方差;
54、σ12为该子数据集中因变量的实际值y_true与该子数据集中因变量的预测值y_pred的协方差;
55、c1、c2分别为预先设定的常数。
56、优选地,
57、所述第一评测矩阵为:
58、
59、其中矩阵元素s1j表示在k个子数据集中的第j个子数据集的修正误差百分比指标值;
60、矩阵元素s2j表示在k个子数据集中的第j个子数据集的拟合度相似指标值;
61、矩阵元素s3j表示在k个子数据集中的第j个子数据集的向量相似性指标值;
62、矩阵元素s4j表示在k个子数据集中的第j个子数据集的结构相似指标值。
63、优选地,所述a33具体包括:
64、针对所述第一评测矩阵的任一矩阵元素,按照公式(5)确定新的数值,并得到与所述第一评测矩阵对应的第二评测矩阵;
65、所述公式(5)为:
66、
67、其中,sij为所述第一评测矩阵的第j列的第i行的元素数值,其中,i=1,2,3,4;
68、δ为预先设定的阈值,且0.5≥δ≥0.1;
69、为sij的新的数值;
70、所述第二评测矩阵为:
71、
72、优选地,a34具体包括:
73、a341、基于所述待评测回归模型的第二评测矩阵,获取该待评测回归模型的第二评测矩阵中数值为0的元素的数量和该待评测回归模型的第二评测矩阵中数值不为0的元素的数量;
74、a342、基于该待评测回归模型的第二评测矩阵中数值为0的元素的数量和该待评测回归模型的第二评测矩阵中数值不为0的元素的数量,采用公式(6)获取所述待评测回归模型的模型评分;
75、其中,所述公式(6)为:
76、
77、其中,n0为该待评测回归模型的第二评测矩阵中数值为0的元素的数量;
78、n1为该待评测回归模型的第二评测矩阵中数值不为0的元素的数量;
79、score为所述待评测回归模型的模型评分。
80、优选地,所述方法还包括:
81、a5、获取所述最优待评测回归模型所对应的自变量,并输入到所述最优待评测回归模型中,得到相应的因变量。
82、另一方面,本实施例提供一种执行如上述的面向流程型工业生产数据流的回归模型选择方法的系统,所述系统包括:
83、接收模块,用于获取每一待评测回归模型以及与该待评测回归模型所对应的评测数据集;
84、划分模块,用于将所述评测数据集及按照预先设定规则划分为k个子数据集;
85、评分模块,用于针对k个子数据集,获取该待评测回归模型的模型评分;
86、该待评测回归模型的模型评分由每一子数据集的评测指标值计算得到;其中,每一子数据集的评测指标值包括:修正误差百分比指标值、拟合度相似指标值、向量相似性指标值、结构相似指标值;
87、确定模块,用于基于每一待评测回归模型的模型评分,确定最优待评测回归模型。
88、(三)有益效果
89、本发明的有益效果是:本发明的一种面向流程型工业生产数据流的回归模型选择方法及系统,由于获取每一待评测回归模型以及与该待评测回归模型所对应的评测数据集;然后将每一所述评测数据集按照预先设定规则划分为k个子数据集;并针对k个子数据集,获取该待评测回归模型的模型评分;最后基于每一待评测回归模型的模型评分,确定最优待评测回归模型。本发明中获取的该待评测回归模型的模型评分从不同角度出发可反应模型综合性能的评测指标,实现对回归模型优劣的量化评分,节省建模的人力、时间成本的同时,解决了单一的评测指标无法真实反映回归模型有效性的问题。
- 还没有人留言评论。精彩留言会获得点赞!