一种基于特征解耦的跨模态异质人脸识别和原型修复方法
本发明涉及图像处理,特别涉及一种基于特征解耦的跨模态异质人脸识别和原型修复方法。
背景技术:
1、在现实生活中,人脸识别系统所接收到的待检索目标人脸照片与系统预存的注册人脸照片可能不属于同一个模态(域)。比如说,注册人脸照片是可见光域的标准证件照,而待检索目标人脸照片是采集自红外摄像头的近红外图片。在这种情况下,由于这两种异质图片所处模态存在巨大差异,因而加大了系统的匹配和识别难度。这个问题被称为跨模态异质人脸识别。此外,在一些非受控场景,待检索目标人脸照片可能带有夸张的面部表情、或存在大角度的头部姿态、或部分面部被遮挡等,无法从视觉上提供良好的个人样貌特征供人工鉴别和比对。
2、自编码器(auto encoder)是一种人工神经网络,它有两个主要组成部分:编码器与解码器。编码器用于将输入图片编码,解码器使用编码来重构输入图片。自编码的目的是对输入数据学习出一种语义层次的表征,通常用于特征提取和降维。特征解耦(featuredisentanglement)旨在从真实数据中对具有不同的语义的生成因子进行解耦,分离出其对应的独立特征表示。特征解耦的前提是提取特征,而解耦一般利用信息熵或者变换空间后的数学特性来完成。特征解耦可用于多模态特征表示,它将多模态数据解耦为两种特征,一种表示模态之间的共同语义信息,另一种表示每个模态的独特属性。其中共同语义信息可用于跨模态人脸检索以及风格迁移中的身份信息保持等。
3、生成对抗网络(gan)于2014年被蒙特利尔大学ian goodfellow等学者提出,gan技术鉴于其强大的生成能力被广泛应用于图片生成任务,并被图灵奖得主yann lecun赞誉为“机器学习这二十年来最酷的想法”。gan是非监督式学习的一种方法,通过让两个神经网络相互博弈的方式进行学习。具体来说,gan由一个生成器与一个(或多个)判别器组成。生成器从潜在空间中随机取样作为输入,其输出结果需要尽量模仿训练集中的真实样本。判别器的输入则为真实样本或生成器输出的虚拟样本,其目的是将生成器的输出从真实样本中尽可能分辨出来。生成器和判别器相互对抗、不断调整网络参数,最终使判别器无法判断生成器的输出结果是真实样本或是生成样本,从而达到一种“纳什均衡”状态。
4、基于此,本发明旨在提出一种跨模态异质人脸识别和原型修复方法,一方面在特征空间中解耦出待检索人脸模态不相关的身份特征,以达成系统的准确识别目标人脸;另一方面在像素空间中对该检索人脸进行跨模态的脸部原型修复,复原正脸的、带有中性表情的、去遮挡的注册人脸所在域原型图片。
技术实现思路
1、针对现有技术中的上述不足,本发明提供了一种基于特征解耦的跨模态异质人脸识别和原型修复方法,主要目的在于处理待检索目标人脸(域a)与注册人脸(域b)模态不一致情况下的异质人脸识别,并同时对域a的待检索目标人脸修复其在域b的脸部原型供人工鉴别和比对。
2、一种基于特征解耦的跨模态异质人脸识别和原型修复方法,包括以下步骤:
3、s1、模型训练集准备:一个训练集包含来自域a和域b的nd个身份类别;域a中的每张图片x服从pdataa分布,即x~pdataa,并标记为而域b中的每张图像y服从pdatab分布,即y~pdatab,并标记为或表示x或y的身份标签;或表示x或y是否包含面部变化;根据和的值,在训练集中选取未带有面部变化的域a和域b的图片并分别构建真实的域a和域b的原型库;真实的域a原型库中的每张图片表示为xrp~preala,真实的域b原型库中的每张图片表示为yrp~prealb;
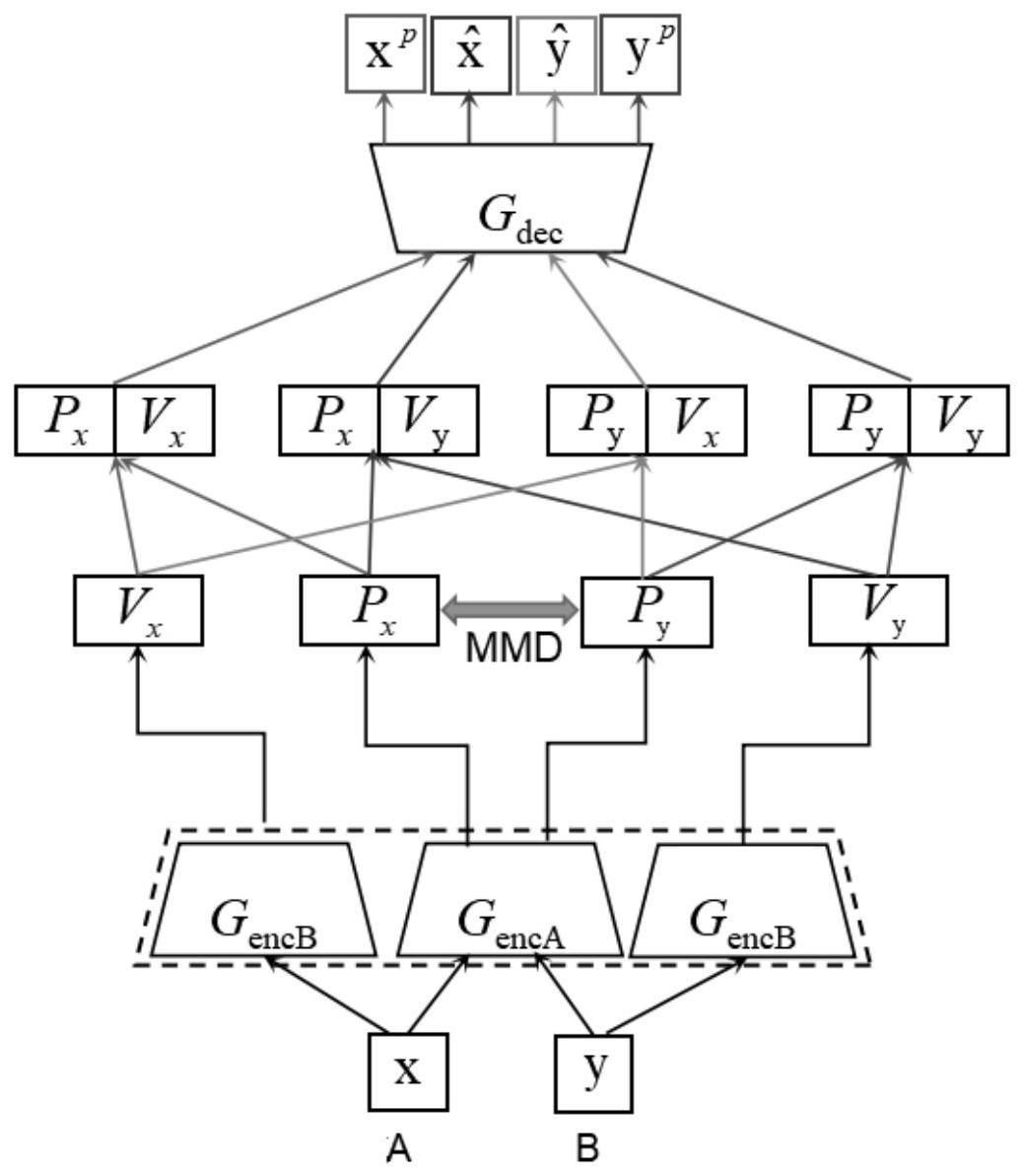
4、s2、模型结构:
5、s21、生成器g:g由两个编码器即genca和gencb,以及一个解码器即gdec组成;genca对x的原型特征px和y的原型特征py进行编码;随后,而gencb对x的域特征vx和y的域特征vy进行编码;gdec接收px和vx的拼接特征、px和vy的拼接特征、py和vx的拼接特征、以及py和vy的拼接特征作为四个输入,然后分别生成四个不同的原型图片,即x在域a的同模态原型xp、x在域b的跨模态原型、y在域a的跨模态原型、和y在域b的同模态原型yp;
6、s21、判别器d和d包含两个子判别器did和dgan;did是一个身份相关的子判别器,用于预测域b中的身份类别;它输出一个nd维度的向量,其中nd表示训练集中的身份类别数量;dgan是一个gan相关的子判别器,用于区分域b中的真假原型;类似地,也是一个多任务判别器,它包含两个子判别器和输出一个nd维向量,用于域a中的身份预测,而用于对域a中的真假原型进行区分;
7、s3、模型训练:本模型的训练包含g和d之间以及g和之间两个交替对抗训练阶段,具体过程如下:
8、s31、阶段1:训练d和g;在这个训练阶段中,g和d被训练相互对抗竞争,以使得g为域a的输入图片x生成跨模态的域b原型以及为域b的输入图片y生成同模态的域b原型yp;
9、对于d=[dgan,did],它有两个训练目标:1)给定g生成的虚假域b原型和yp以及真实的域b原型yrp,dgan期望将和yp归类为虚假原型,同时将yrp归类为真实原型;2)给定域b的输入图片y,did期望正确预测其身份标签因此,训练判别器d的最终目标函数vd为:
10、
11、其中α1是平衡超参数;和定义为和其中是did中的第i个元素;
12、对于g,它也有两个训练目标:1)欺骗dgan使其将和yp分类为真实的域b原型;2)使did将的身份标签预测为与x的身份标签相同即将yp的身份标签预测为与y的身份标签相同即因此,训练生成器g的最终目标函数vg为:
13、
14、其中λ1是平衡超参数,和各自定义为和
15、s32、阶段2:训练和g;在这个训练阶段,g和被训练为相互对抗竞争,以使g为域b的输入图片y生成跨模态的域a原型以及为域a的输入图片x生成同模态的域a原型xp;
16、对于它有两个类似于d的训练目标:1)给定由g生成的虚假域a原型和xp以及真实的域a原型xrp,期望将和xp分类为虚假原型,同时将xrp分类为真实原型;2)给定域a的输入图像x,期望准确地预测其身份标签因此,训练判别器的最终目标函数如下:
17、
18、其中α2是平衡超参数,和定义为和其中是中的第i个元素;
19、对于g,它有如下两个训练目标:1)欺骗使其将和xp都分类为真实的域a原型;2)使将的身份标签预测为与y的身份标签相同即将xp的身份标签预测为与x的身份标签相同即综合上述两个目标,训练生成器g的最终目标函数可表述为:
20、
21、其中λ2是平衡超参数,和各自定义为和
22、作为优选的,步骤s1中,如果x包含任意面部变化,包括姿势、表情或遮挡,则否则
23、作为优选的,在实验中,使用包含近红外与可见光图片的buaanir-vis数据集,该数据集被随机划分为50个志愿者的训练集和100个志愿者的测试集,训练集和测试集无任何交集;在模型训练和测试过程中,buaanir-vis数据集的所有图片均先被转换为128×128像素的灰度图。
24、作为优选的,对于g的编码器genca,模型采用在ms-celeb-1m数据集预训练好的lightened-cnn作为骨干网络为域a或域b输入图片提取一个256维的原型特征;对于g的另一个编码器gencb,模型采用casia-net作为骨干网络为域a或域b输入图片提取一个50维的域特征;而对于g中的解码器gdec,模型选择用反向casia-net作为解码网络并同时在每个反卷积层后引入批归一和指数线性单元;gdec接收一个306维的特征向量并输出一张128×128维图片;对于判别器d和模型选择以casia-net为骨干网络并额外填加了一层全连接层;d和网络中每个卷积层后都进行了批归一化处理和指数线性单元激活;d(或)接收一张128×128维图片并输出一个nd+1维的向量,其中前nd维被did或用来预测域b或域a中人脸图片的身份标签,而最后1维被预留给dgan或用以打分进而区分域b(或域a)中的真假原型图片。
25、本发明的有益效果为:
26、1、不同于现有跨模态人脸识别技术只关注系统自动识别准确率,本发明引入了跨模态人脸原型修复过程,提供了人工鉴别和比对途径,进而提高了复杂环境下人脸识别系统的鲁棒性。此项发明技术尤其适用于刑事侦查和犯罪识别。
27、2、发明融合了解耦表征学习与生成对抗学习技术,通过在潜在特征空间中仅解耦原型和域特征,进而在像素空间中自适应地移除了人脸变化信息(包括表情、姿态等)。本发明提供了一种针对通用面部变化移除的跨模态原型修复网络。
- 还没有人留言评论。精彩留言会获得点赞!