一种片上缓存的数据调度方法及系统
1.本发明涉及数据处理技术领域,特别涉及一种片上缓存的数据调度方法及系统。
背景技术:
2.由于深度神经网络模型通常包含巨量的模型参数,通常情况下无法将所有的参数数据缓存到片上缓存单元中。为了通过提高片上缓存单元的利用率,以提高以cnns为代表的深度神经网络模型的效率,有不同的学者提出不同的想法,例如:有学者设计“灵活”的缓存单元以提高片上数据重用率,还有学者提出从动态调整各类缓存区的大小降低数据移动量的角度来提高片上缓存单元的利用率。
3.现有技术中,对于同一cnn的不同运算层,对应的各级缓存的资源分配策略也应该不相同,现有的cnn加速器中的各级缓存普遍采用固定存储量的双缓存结构。现有cnn加速器只能在多种存储容量中进行权衡,最终为各级缓存选择一个平均值。对于优化循环调度后,所需存储量大于分配存储量的运算层,由于存储带宽不能满足tile计算块的运算效率,因此只能调整循环调度策略,从而降低了加速器的计算性能,cnn加速器中存储结构的不灵活最终会造成加速器整体能效的降低。
技术实现要素:
4.本发明提供一种偏上缓存的数据调度方法及系统,解决现有技术中的片上缓存效率较低的技术问题。
5.本发明的技术方案为:提供了一种片上缓存的数据调度方法,所述方法包括:接收控制单元的调度请求,所述调度请求携带配置指示,所述调度请求为运算器根据当前需要待运算的数据发出;基于所述配置指示执行相应的配置操作,并向所述控制单元反馈当前的状态信息以便所述控制单元将所述状态信息上报至加速器,并将所述配置指示发送给存储块单元,由所述存储块单元根据所述配置指示执行缓存单元的地址映射转换、并基于所述调度请求执行相应的调度操作。
6.在一种可选的方式中,所述配置指示包括:连接信息、配置信息,所述基于所述配置信息执行相应的配置操作,包括:
7.基于所述连接信息选择一从接口,每一所述从接口连接有片上缓存单元;
8.基于所述连接信息选择相互连接的从接口及主接口;
9.由所选择的从接口通过与其连接的主接口向所述存储块单元传输所述配置信息。
10.在一种可选的方式中,所述存储块单元根据所述配置指示执行缓存单元的地址映射转换,包括:
11.基于所述配置信息对所述缓存单元进行数据存储区的划分;
12.基于所述缓存单元当前的状态选择目标缓存单元;
13.对所选择的目标缓存单元进行相应地址的映射转换;
14.更新所述目标缓存单元的状态。
15.在一种可选的方式中,所述调度请求还包括数据类型,所述基于所述调度请求执行相应的调度操作,包括:
16.基于循环拆分策略及所述数据类型将所述存储块单元划分为若干缓冲区,任两个缓冲区的容量不一样;
17.基于循环排序策略及所述数据类型确定数据的访问顺序;
18.基于循环展开策略进行相应的数据传输参数的配置。
19.在一种可选的方式中,所述基于循环拆分策略及所述数据类型将所述存储块单元划分为若干缓冲区,包括:
20.基于所述数据类型确定需要的缓冲区的容量;
21.基于确定的结果将所述存储块单元划分为若干缓冲区。
22.在一种可选的方式中,所述基于循环排序策略及所述数据类型确定数据的访问顺序,包括:
23.基于所述数据类型确定对应的缓存级别;
24.基于所述缓存级别及由低到高级别的原则确定访问顺序。
25.在一种可选的方式中,所述数据类型包括数据流模式,所述基于循环展开策略进行相应的数据传输参数的配置,包括:
26.根据所述数据流模式调整avi传输模式。
27.本发明还提供一种片上缓存的数据调度系统,包括:控制单元,用于接收运算器的调度指示,向交叉互联单元发出调度请求;
28.交叉互联单元,用于接收控制单元的调度请求,基于所述配置指示执行相应的配置操作,并向所述控制单元反馈当前的状态信息以便所述控制单元将所述状态信息上报至加速器,并将所述配置指示发送给存储块单元,所述调度请求携带配置指示;
29.缓存块单元,用于根据所述配置指示执行缓存单元的地址映射转换、并基于所述调度请求执行相应的调度操作。
30.本发明还提供一种计算设备,包括:处理器、存储器、通信接口和通信总线,所述处理器、所述存储器和所述通信接口通过所述通信总线完成相互间的通信;
31.所述存储器用于存放至少一可执行指令,所述可执行指令使所述处理器执行所述片上缓存的数据调度方法的步骤。
32.本发明还提供一种计算机存储介质,所述存储介质中存储有至少一可执行指令,所述可执行指令使处理器执行所述片上缓存的数据调度方法的步骤。
33.本发明相较于现有技术,其有益效果为:基于当前待运算数据来进行相应的调度配置,提高数据缓存灵活性及效率。
附图说明
34.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面对实施例中所需要使用的附图作简单的介绍,下面描述中的附图仅为本发明的部分实施例相应的附图。
35.图1示出了本发明实施例提供了一种片上缓存的数据调度方法的流程示意图;
36.图2示出了本发明实施例提供了一种片上缓存的数据调度系统的结构示意图;
37.图3示出了本发明实施例提供了一种片上缓存的数据调度系统的地址更换模块的
结构示意图;
38.图4-1示出了本发明实施例提供了一种片上缓存的数据调度方法的基于eyeriss的alexnet运算层功效比较示意图;
39.图4-2示出了本发明实施例提供了一种片上缓存的数据调度方法的基于tpu的alexnet运算层功效比较示意图;
40.图5-1示出了本发明实施例提供了一种片上缓存的数据调度方法的基于eyeriss的mobilenet运算层功效比较示意图;
41.图5-2示出了本发明实施例提供了一种片上缓存的数据调度方法的基于tpu的mobilenet运算层功效比较示意图;
42.图6示出了本发明实施例提供了一种片上缓存的数据调度系统的结构框图;
43.图7示出了本发明实施例提供的计算设备的结构示意图。
具体实施方式
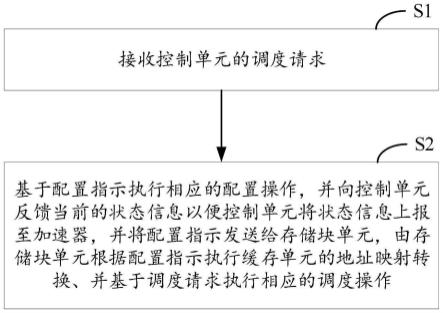
44.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
45.本发明中所提到的方向用语,例如「上」、「下」、「前」、「后」、「左」、「右」、「内」、「外」、「侧面」、「顶部」以及「底部」等词,仅是参考附图的方位,使用的方向用语是用以说明及理解本发明,而非用以限制本发明。
46.本发明术语中的“第一”“第二”等词仅作为描述目的,而不能理解为指示或暗示相对的重要性,以及不作为对先后顺序的限制。
47.在本发明中,除非另有明确的规定和限定,术语“安装”、“相连”、“连接”、“固定”等术语应做广义理解,例如,可以是固定连接,也可以是可拆卸连接,或成一体;可以是机械连接,也可以是电连接;可以是直接相连,也可以通过中间媒介间接相连,可以是两个元件内部的连通或两个元件的相互作用关系。对于本领域的普通技术人员而言,可以根据具体情况理解上述术语在本发明中的具体含义。
48.请参见图1,本发明优选实施例提供了一种片上缓存的数据调度方法的流程示意图,在本实施例中,该方法应用于片上缓存的数据调度系统,见图2,该系统包括控制单元21、交叉互联单元22及缓存块单元23,该方法包括:
49.步骤s1、接收控制单元的调度请求,所述调度请求携带配置指示;
50.具体地,控制单元21接收到运算器的调度指示,向交叉互联单元22发起调度请求,该调度请求携带配置指示,该配置指示包括待运算数据的类型、大小等,所述调度请求为运算器根据当前需要待运算的数据发出,即运算器有运算需求时,根据当前待运算数据来发出调度指示,例如根据待运算数据的大小、类型等发出调度指示,以便控制单元控制其他单元进行对应的调度配置,与待运算数据匹配,提高运算效率及便利性。该配置指示携带对应的配置信息,该配置信息包括各缓存级别的axi访问地址空间以及缓存级别内部各种数据的axi访存地址空间。
51.步骤s2、基于所述配置指示执行相应的配置操作,并向所述控制单元反馈当前的
状态信息以便所述控制单元将所述状态信息上报至加速器,并将所述配置指示发送给存储块单元,由所述存储块单元根据所述配置指示执行缓存单元的地址映射转换、并基于所述调度请求执行相应的调度操作;
52.具体地,该向交叉互联单元22接收到控制单元21的调度请求后,根据该配置指示执行相应的配置操作,并向所述控制单元21反馈当前的状态信息以便所述控制单元21将所述状态信息上报至加速器,由所述存储块单元23根据所述配置指示执行缓存单元的地址映射转换、并基于所述调度请求执行相应的调度操作。
53.在本发明实施例中,基于当前待运算数据来进行相应的调度配置,提高数据缓存灵活性及效率。
54.在本实施例的一个可选方式中,所述配置指示包括:连接信息、配置信息,所述基于所述配置信息执行相应的配置操作,包括:
55.基于所述连接信息选择一从接口,每一所述从接口连接有片上缓存单元;
56.具体地,该交叉互联单元包括两个从接口(axi slave),及若干主接口(axi master),其中一个从接口连接外部的dram(off-chip dram),另一个连接寄存器堆(register file)。在本实施例中,该片上缓存单元可包括:dram(off-chip dram)、register file等。
57.基于所述连接信息选择相互连接的从接口及主接口;
58.具体地,根据连接信息选择相互连接的从接口及主接口,例如,主接口被配置为与存储输入特征值或网络模型权重的bank块连接时,它与连接off-chip dram的axi slave端口互联;如果主接口被配置为与存储可跨层共享的特征值的bank块连接时,它与连接register file的axi slave端口互联。
59.由所选择的从接口通过与其连接的主接口向所述存储块单元传输所述配置信息。
60.具体地,根据选择好的通道向存储块单元传输配置信息,以供该存储块单元基于配置信息进行调度配置,以满足当前待运算数据的缓存要求。
61.在本实施例的一个可选方式中,所述所述存储块单元根据所述配置指示执行缓存单元的地址映射转换,包括:
62.基于所述配置信息对所述缓存单元进行数据存储区的划分;
63.具体地,如图3所示,为存储块单元的地址转换模块的结构图,包括:索引转换子模块、状态更新子模块、addr gen子模块、recon-mem bank division子模块、bank state子模块等,其中,recon-mem bank division子模块用于根据配置信息将各bank划分为不同的同的参数存储区,索引转换子模块用于对id特征进行转换,形成索引号标识,该id特征包括:batch id、layer id、特征层id、“tile”的坐标(x,y)以及尺寸(size),其中,“tile”的坐标(x,y)以及尺寸(size)通过addr gen子模块来处理,bank state模块用于记录了每一个bank块当前的状态,即属于存储哪种数据的存储区,以及是否可以清空等状态,状态更新子模块用于修改对应bank块的状态,比如某个bank块是存储输入特征值的,则数据读取后可将其状态修改为可清空。在执行卷积等操作时,索引转换子模块将相应“tile”的id转换为配置信息以更新缓冲区。状态更新单元根据配置信息更新缓存块—“bank”的状态表。addr gen单元根据“tile”的坐标(x,y)和大小生成“bank”缓冲区的物理地址。同时,生成库id和对应库块中的地址,以访问有关特征映射和权重的片上缓冲区。
64.在本实施例中,我们通过动态重组的方法将多个“bank”块组成特定的缓存区(如输入缓存区,输出缓存区和权重缓存区)。在进行卷积等运算时,根据片上缓冲区划分策略,将多个“bank”被动态分组为一组以形成缓冲区(例如,输入缓冲区、输出缓冲区缓冲区,或权重缓冲区)。控制单元通过解析配置指示,生成片上缓冲单元的划分策略和可重构交叉开关的连接网络模型,从而存储起始地址,缓冲区的大小,以及寄存器中每个缓冲区块的状态。
65.基于所述缓存单元当前的状态选择目标缓存单元;
66.具体地,根据缓存单元当前的状态来选择目标缓存单元,例如,需要使用的缓存单元的状态是不可用时,该缓存单元不属于目标缓存单元,如果该缓存单元的状态是可用时,则该缓存单元属于目标缓存单元;
67.对所选择的目标缓存单元进行相应地址的映射转换;
68.具体地,根据配置信息对目标缓存单元进行地址映射转换,如将配置好的虚地址到实地址。
69.更新所述目标缓存单元的状态。
70.具体地,通过状态更新子模块更新所述目标缓存单元当前的状态,即将当前的状态覆盖之前的状态。
71.在本实施例的一个优选方案中,所述调度请求还包括数据类型,所述基于所述调度请求执行相应的调度操作,包括:
72.基于循环拆分策略及所述数据类型将所述存储块单元划分为若干缓冲区,任两个缓冲区的容量不一样;首先,基于所述数据类型确定需要的缓冲区的容量;基于确定的结果将所述存储块单元划分为若干缓冲区。即确定片上存储器中针对不同类型数据需要的存储块数据,然后由recon-mem bank division将各bank块划分为不同的缓冲区,并更新bank信息记录表。
73.具体地,预先设置循环拆分策略,该策略包括数据类型与拆分的缓冲区对应,例如:由循环拆分策略计算得到针对输入特征在第0级存储中需要分配m0bit的存储空间,并且假定输入特征值的数据位宽为8bit,假定数据的在0级缓存中的维度为1,在1级缓存中的维度为2,在第1级存储中需要分配m1bit,则m1=8*2*1*m0。假定第1级存储的bank块大小为b1,则需要在第一级存储区中划分给输入输入特征的bank数据为
74.又例如:由式(1)可知,在循环拆分后的第i级缓存中,某一类型所需存储量为i级和更高级别缓存区中(i,i-1,
…
,0)该类型数据在各循环维度上拆分因子的乘积。由于本文的ax i地址空间按照字节编址,因此为了完成地址空间的计算,需要在式(1)的基础上增加数据位宽,从而得到如式(1)所示的以字节为单位的地址空间分配方法。
[0075][0076]
其中,所述dj是j级缓存的维度子集,表示该缓存级别中相应维度的数据量;d是所有维度的集合;b表示运算数据位宽,#widthb表示以字节为单位的数据位宽。交叉互联网络在接收到地址空间的配置信息后,会优先针对各级缓存容量粗粒度划分存储块,其划分策
略如式(2)所示。
[0077][0078]
其中,所述l表示cnn模型的卷积层数,#bank
l
表示弹性存储结构内存储块的数量,#banki表示i级缓存分配的存储块数目,#banks表示存储块的容量。在得出各级缓存所需存储块数目后。并且交叉互联网络利用类似于式(1)的方法计算各类型数据需要的存储块数量,进而实现对于地址空间划分。
[0079]
以特征图尺寸中的x维度为例,其中n代表缓存在存储结构中的级别,xi代表特征图在相应级别中的尺寸,这种拆分方法的目的是将输入特征(i)、输出特征(o)以及权重(w)这些大数据块拆分成小数据块,以便存储在距离计算单元更近的缓存级别中,表1所示为一个3级存储结构的循环拆分结果。
[0080]
表1三级层次化存储结构的循环拆分
[0081]
[0082]
[0083][0084]
基于循环排序策略及所述数据类型确定数据的访问顺序;
[0085]
具体地,根据数据类型及循环排序策略确定数据的访问顺序,首先是基于所述数据类型确定对应的缓存级别;然后基于所述缓存级别及由低到高级别的原则确定访问顺序。例如:确定各类数据的在片上缓存单元的各类型数据在存储中的组织方式,即数据访问顺序,然后由reconfigurable corrbar子模块动态配置各master到各slave接口互联。
[0086]
在本实施例中,由于循环排序会改变各类型数据在存储中的组织方式,如果直接将循环拆分后各类型数据的容量作为地址空间,那么在不同的循环排序策略下,读取以及写入地址会经常发生大幅度变化,从而降低axi(advanced extensible interface)在连续突发传输过程中的读写效率,因此还需要结合循环排序,进一步分析各类型数据在存储中的组织方式。可采用类似于访问cache的数据缓存方式,即访存的优先级从0级到l级逐级递减。并且对于同类型的数据,高级别缓存会将低级别的数据作为基本存储块进行排列,因此只需要考虑该级别缓存中基本数据块的排列方式。为了将按连续地址访问各数据块,本文采用按照底层循环优先的原则排列基本数据块,即从循环的最底层开始向上遍历,从而能够提高axi的突发传输效率。
[0087]
以表2中的各级循环为例,0级缓存中,对于权重而言,优先对卷积核尺寸维度的数据进行存储,然后以3*3的卷积核为单位存储2组输入通道,最后2*3*3为单位存储4组输出通道;对于输入特征而言,优先存储宽度为18的特征行,再以特征行为单位,存储18个特征行,最后以一张特征图为单位存储2组输入通道;对于输出特征而言,优先存储宽度为16的特征行,再以特征行为单位,存储16个特征行,最后以一张特征图为单位存储4组输出通道。在1级缓存中,将0级缓存作为基本数据块,对于权重数据,由于在该级别没有循环,因此只存储一个基本数据块的量;对于输入和输出特征而言,优先存储行方向上的2组拆分数据,再存储列方向上的2组拆分数据;在2级缓存中,将1级缓存作为基本数据块,在不考虑批处理维度情况下,三种数据都将优先存储输入通道上的4组拆分数据,再存储输出通道上的8组拆分数据。
[0088]
表2卷积层示例
[0089][0090][0091]
基于循环展开策略进行相应的数据传输参数的配置。
[0092]
具体地,根据数据流模式调整avi传输模式,确定在各接口之间通过基于axi协议进行数据传输时配置信息,如burst_size和burst_len等。
[0093]
进一步地,这是一种并行计算方法,通过将循环映射到并行计算结构上来加速循环的计算。即如果有多个运算单元,则可以同时并行进行相同类型的运算,从而提高计算效率。但是不同的循环展开策略对应的数据重构模式不同,从而导致对访存量不同。
[0094]
进一步地,以循环展开数据流fx|fy为例,使用该数据流的tile计算块分别在pe(计算单元)阵列的行方向和列方向上对卷积核的尺寸进行展开,所以当0级缓存向1级缓存发送读取数据请求时,需要配置burst_size和burst_len以满足当前运算并行度的需求。由于不同硬件平台资源的限制,axi能提供的最大burst_size也不同,本节将依据axi协议进行讨论。
[0095]
以alexnet的运算层conv1和conv3(conv2与conv1类似,处理方式也类似,此处以conv1及conv3为例),conv1的卷积核尺寸为11*11,conv3的卷积核尺寸为3*3,假设权重的数据位宽为16bit,即一个权重占用2字节地址。对于conv1而言,所需并行输出量为242字节,理论上axi可以提供的burst_size最大值为128字节,因此需要同时改变burst_len的大小,在最大burst_size传输的情况下,burst_len需要为2时才能满足需求;对于conv3而言,所需并行输出量为18字节,那么只需将burst_size配置为32时即可满足需求。
[0096]
由于各级缓存间的通信使用axi的突发传输,而单次突发传输的数据量(burst_size)以及突发传输的长度(burst_len),共同决定了突发传输的并行输出能力;同时,由于循环展开方法决定了当前缓存级别的并行运算能力,因此当前缓存级别的输入数据量需要满足并行运算的需求。所以结合以上两点原因,循环展开策略决定了缓存级别间axi(advanced extensible interface)通信过程的相关参数配置。
[0097]
在本实施例中,alexnet的运算层在弹性存储与普通双缓存中的功耗对比如图4-1及4-2所示,弹性存储电路的整体功耗要低于双缓存结构,基于eyeriss的弹性存储功耗最大为4.45*107pj,最小为0.94*107pj,整体功耗相较于双缓存结构下降了17.72%;基于tpu的弹性存储的功耗最大为6.56*107pj,最小为0.71*107pj,整体功耗相较于双缓存结构下降了18.43%。由于conv1和conv2中双缓存所需的存储量较小,因此弹性存储对于两个运算层的单次访问功耗相较于要大于双缓存结构,即导致了conv1和conv2中弹性存储的访存功耗略大于双缓存结构。
[0098]
alexnet运算层功耗:
[0099]
mobilenet的运算层在弹性存储与普通双缓存中的功耗对比如图5-1及5-2所示,基于eyeriss的弹性存储功耗最大为2.89*107pj,最小为0.73*107pj,整体功耗相较于双缓存结构下降了27.13%;基于tpu的弹性存储功耗最大为2.95*107pj,最小为0.56*107pj,整体功耗相较于双缓存结构下降了13.52%,两者功耗的最大值均出现在conv10中。在基于eyeriss的弹性存储中,conv10的循环调度方法在弹性存储级别上对ox、oy以及c维度分别进行了因子为7、7和2的循环拆分,同时在片外dram级别对k使用了因子为4的循环拆分,从而增加了各类型数据访问弹性存储的次数,产生了更多功耗。而在基于tpu的弹性存储中,conv10的循环调度方法在弹性存储级别上对c维度进行了因子为1024的循环拆分,同时在片外dram级别对k使用了因子为4的循环拆分,从而增加了输入特征以及输出特征访问弹性存储的次数,导致了更多功耗的产生。
[0100]
mobilenet运算层功耗:
[0101]
resnet的运算层在弹性存储与普通双缓存中的功耗对比如图5所示,基于eyeriss的弹性存储功耗最大为1.82*108pj,最小为1.07*107pj,整体功耗相较于双缓存结构下降了30.28%;基于tpu的弹性存储功耗最大为6.20*107pj,最小为1.16*107pj,整体功耗相较于双缓存结构下降了17.33%,两者功耗的最大值均出现在conv8中。在基于eyeriss的弹性存储中,conv10的循环调度方法在弹性存储级别上对ox和oy维度分别进行了因子为14和28的循环拆分,同时在片外dram级别对k和ox分别使用了因子为16和2的循环拆分,从而增加了各类型数据访问弹性存储的次数,产生了更多功耗。而在基于tpu的弹性存储中,conv10的循环调度方法在弹性存储级别上对ox和oy维度分别进行了因子为28和28的循环拆分,同时在片外dram级别对k使用了因子为4的循环拆分,从而增加了输入特征以及输出特征访问弹性存储的次数,导致了更多功耗的产生。
[0102]
在本发明实施例中,基于当前待运算数据来进行相应的调度配置,提高数据缓存灵活性及效率。
[0103]
另外,采用循环拆分、循环排序及循环展开策略可以提高axi的突发传输效率。
[0104]
基于上述实施例,本发明还提出一种片上缓存的数据调度系统,如图6所示:该系统包括控制单元21、交叉互联单元22及缓存块单元23,其中:
[0105]
控制单元21,用于接收运算器的调度指示,向交叉互联单元发出调度请求;
[0106]
交叉互联单元22,用于接收控制单元的调度请求,基于所述配置指示执行相应的配置操作,并向所述控制单元反馈当前的状态信息以便所述控制单元将所述状态信息上报至加速器,并将所述配置指示发送给存储块单元,所述调度请求携带配置指示;
[0107]
缓存块单元23,用于根据所述配置指示执行缓存单元的地址映射转换、并基于所述调度请求执行相应的调度操作;
[0108]
具体地,计算器如果有数据运算任务,根据待运算数据生成调度指示,向控制单元21发起该调度指示,以使得缓存块单元与待运算数据相匹配,控制单元21接收到该调度指示后,对其进行解析,得到配置信息及对应的循环调度策略(如循环拆分、循环排序、循环展开策略),控制单元21向交叉互联单元22发起调度请求,该交叉互联单元22接收到控制单元21的调度请求后,根据该配置指示执行相应的配置操作,并向所述控制单元21反馈当前的状态信息以便所述控制单元21将所述状态信息上报至加速器,由所述存储块单元23根据所述配置指示执行缓存单元的地址映射转换、并基于所述调度请求执行相应的调度操作。待调度完成后,运算器开始执行运算操作,在运算过程中,低级别缓存通过axi主接口向axi从接口发送数据读取和写请求,从相应存储块取出数据或将数据写入对应存储块。
[0109]
在一种可选方式中,所述配置指示包括:连接信息、配置信息,所述交叉互联单元22具体用于:
[0110]
基于所述连接信息选择一从接口,每一所述从接口连接有片上缓存单元;
[0111]
基于所述连接信息选择相互连接的从接口及主接口;
[0112]
由所选择的从接口通过与其连接的主接口向所述存储块单元传输所述配置信息。
[0113]
在一种可选方式中,所述存储块单元23具体用于:
[0114]
基于所述配置信息对所述缓存单元进行数据存储区的划分;
[0115]
基于所述缓存单元当前的状态选择目标缓存单元;
[0116]
对所选择的目标缓存单元进行相应地址的映射转换;
[0117]
更新所述目标缓存单元的状态。
[0118]
在一种可选方式中,所述调度请求还包括数据类型,所述存储块单元23具体用于:
[0119]
基于循环拆分策略及所述数据类型将所述存储块单元划分为若干缓冲区,任两个缓冲区的容量不一样;
[0120]
基于循环排序策略及所述数据类型确定数据的访问顺序;
[0121]
基于循环展开策略进行相应的数据传输参数的配置。
[0122]
在一种可选方式中,所述存储块单元23具体用于:
[0123]
基于所述数据类型确定需要的缓冲区的容量;
[0124]
基于确定的结果将所述存储块单元划分为若干缓冲区。
[0125]
在一种可选方式中,所以存储块单元23具体用于:
[0126]
基于所述数据类型确定对应的缓存级别;
[0127]
基于所述缓存级别及由低到高级别的原则确定访问顺序。
[0128]
在一种可选方式中,所述数据类型包括数据流模式,所以存储块单元23具体用于:
[0129]
根据所述数据流模式调整avi传输模式。
[0130]
在本发明实施例中,基于当前待运算数据来进行相应的调度配置,提高数据缓存
灵活性及效率。
[0131]
另外,采用循环拆分、循环排序及循环展开策略可以提高axi的突发传输效率。
[0132]
本发明实施例提供了一种非易失性计算机存储介质,所述计算机存储介质存储有至少一可执行指令,该计算机可执行指令可执行上述任意方法实施例中的片上缓存的数据调度方法。
[0133]
可执行指令具体可以用于使得处理器执行以下操作:
[0134]
接收控制单元的调度请求,所述调度请求携带配置指示,所述调度请求为运算器根据当前需要待运算的数据发出;
[0135]
基于所述配置指示执行相应的配置操作,并向所述控制单元反馈当前的状态信息以便所述控制单元将所述状态信息上报至加速器,并将所述配置指示发送给存储块单元,由所述存储块单元根据所述配置指示执行缓存单元的地址映射转换、并基于所述调度请求执行相应的调度操作。
[0136]
在一种可选的方式中,所述配置指示包括:连接信息、配置信息,所述可执行指令使所述处理器执行以下操作:
[0137]
基于所述连接信息选择一从接口,每一所述从接口连接有片上缓存单元;
[0138]
基于所述连接信息选择相互连接的从接口及主接口;
[0139]
由所选择的从接口通过与其连接的主接口向所述存储块单元传输所述配置信息。
[0140]
在一种可选的方式中,所述可执行指令使所述处理器执行以下操作:
[0141]
基于所述配置信息对所述缓存单元进行数据存储区的划分;
[0142]
基于所述缓存单元当前的状态选择目标缓存单元;
[0143]
对所选择的目标缓存单元进行相应地址的映射转换;
[0144]
更新所述目标缓存单元的状态。
[0145]
在一种可选的方式中,所述调度请求还包括数据类型,所述可执行指令使所述处理器执行以下操作:
[0146]
基于循环拆分策略及所述数据类型将所述存储块单元划分为若干缓冲区,任两个缓冲区的容量不一样;
[0147]
基于循环排序策略及所述数据类型确定数据的访问顺序;
[0148]
基于循环展开策略进行相应的数据传输参数的配置。
[0149]
在一种可选的方式中,所述可执行指令使所述处理器执行以下操作:
[0150]
基于所述数据类型确定需要的缓冲区的容量;
[0151]
基于确定的结果将所述存储块单元划分为若干缓冲区。
[0152]
在一种可选的方式中,所述可执行指令使所述处理器执行以下操作:
[0153]
基于所述数据类型确定对应的缓存级别;
[0154]
基于所述缓存级别及由低到高级别的原则确定访问顺序。
[0155]
在一种可选的方式中,所述数据类型包括数据流模式,所述可执行指令使所述处理器执行以下操作:
[0156]
根据所述数据流模式调整avi传输模式。
[0157]
在本发明实施例中,基于当前待运算数据来进行相应的调度配置,提高数据缓存灵活性及效率。
[0158]
另外,采用循环拆分、循环排序及循环展开策略可以提高axi的突发传输效率。
[0159]
图7示出了本发明实施例提供的计算设备的结构示意图,本发明具体实施例并不对设备的具体实现做限定。
[0160]
如图7所示,该计算设备可以包括:处理器(processor)702、通信接口(communications interface)704、存储器(memory)706、以及通信总线708。
[0161]
其中:处理器702、通信接口704、以及存储器706通过通信总线708完成相互间的通信。通信接口704,用于与其它设备比如客户端或其它服务器等的网元通信。处理器702,用于执行程序710,具体可以执行上述片上缓存的数据调度方法实施例中的相关步骤。
[0162]
具体地,程序710可以包括程序代码,该程序代码包括计算机操作指令。
[0163]
处理器702可能是中央处理器cpu,或者是特定集成电路asic(application specific integrated circuit),或者是被配置成实施本发明实施例的一个或各个集成电路。设备包括的一个或各个处理器,可以是同一类型的处理器,如一个或各个cpu;也可以是不同类型的处理器,如一个或各个cpu以及一个或各个asic。
[0164]
存储器706,用于存放程序710。存储器706可能包含高速ram存储器,也可能还包括非易失性存储器(non-volatile memory),例如至少一个磁盘存储器。
[0165]
程序710具体可以用于使得处理器702执行以下操作:
[0166]
接收控制单元的调度请求,所述调度请求携带配置指示,所述调度请求为运算器根据当前需要待运算的数据发出;
[0167]
基于所述配置指示执行相应的配置操作,并向所述控制单元反馈当前的状态信息以便所述控制单元将所述状态信息上报至加速器,并将所述配置指示发送给存储块单元,由所述存储块单元根据所述配置指示执行缓存单元的地址映射转换、并基于所述调度请求执行相应的调度操作。
[0168]
在一种可选的方式中,所述配置指示包括:连接信息、配置信息,程序710具体可以用于使得处理器702执行以下操作:
[0169]
基于所述连接信息选择一从接口,每一所述从接口连接有片上缓存单元;
[0170]
基于所述连接信息选择相互连接的从接口及主接口;
[0171]
由所选择的从接口通过与其连接的主接口向所述存储块单元传输所述配置信息。
[0172]
在一种可选的方式中,程序710具体可以用于使得处理器702执行以下操作:
[0173]
基于所述配置信息对所述缓存单元进行数据存储区的划分;
[0174]
基于所述缓存单元当前的状态选择目标缓存单元;
[0175]
对所选择的目标缓存单元进行相应地址的映射转换;
[0176]
更新所述目标缓存单元的状态。
[0177]
在一种可选的方式中,所述调度请求还包括数据类型,程序710具体可以用于使得处理器702执行以下操作:
[0178]
基于循环拆分策略及所述数据类型将所述存储块单元划分为若干缓冲区,任两个缓冲区的容量不一样;
[0179]
基于循环排序策略及所述数据类型确定数据的访问顺序;
[0180]
基于循环展开策略进行相应的数据传输参数的配置。
[0181]
在一种可选的方式中,程序710具体可以用于使得处理器702执行以下操作:
[0182]
基于所述数据类型确定需要的缓冲区的容量;
[0183]
基于确定的结果将所述存储块单元划分为若干缓冲区。
[0184]
在一种可选的方式中,程序710具体可以用于使得处理器702执行以下操作:
[0185]
基于所述数据类型确定对应的缓存级别;
[0186]
基于所述缓存级别及由低到高级别的原则确定访问顺序。
[0187]
在一种可选的方式中,所述数据类型包括数据流模式,程序710具体可以用于使得处理器702执行以下操作:
[0188]
根据所述数据流模式调整avi传输模式。
[0189]
在本发明实施例中,基于当前待运算数据来进行相应的调度配置,提高数据缓存灵活性及效率。
[0190]
另外,采用循环拆分、循环排序及循环展开策略可以提高axi的突发传输效率。
[0191]
综上,虽然本发明已以优选实施例揭露如上,但上述优选实施例并非用以限制本发明,本领域的普通技术人员,在不脱离本发明的精神和范围内,均可作各种更动与润饰,因此本发明的保护范围以权利要求界定的范围为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1