基于图正则化的非线性正交非负矩阵分解图像聚类方法
本发明用于矩阵分解以及聚类改进,具体涉及到一种带有图正则项的非线性非负矩阵分解、图像聚类方法。
背景技术:
1、随着机器学习与数据挖掘的发展,为解决维数灾难以及数据重构问题,产生了多种有效的降维方式与聚类算法,这是应用于各类大规模数据处理的必然需要,也是推动机器学习应用于实际的前提条件。
2、目前,矩阵分解是一种研究比较常见的降维方式,并应用到图像识别、推荐系统、数据聚类等各个领域。其中非负矩阵分解是一种在系数矩阵和基矩阵上添加非负约束来近似数据矩阵的方法,nmf将输入的数据矩阵分解为基矩阵与系数矩阵,在语音、图像识别、数据降维、信息提取、推荐系统等方面都有较为广泛的应用,也是机器学习与数据处理任务中常用的聚类技术。
3、普通的非负矩阵分解用于聚类时无法获得非线性数据的有效聚类,因此对原始数据矩阵进行非线性变换,将数据进行映射到高维空间,然后对非线性的非负数据进行非负矩阵分解,产生超平面对数据进行聚类,并对聚类指示矩阵添加正则约束,提高聚类结果的精度。以往研究中图正则项常用于子空间聚类中,例如谱聚类中对聚类指示矩阵添加正交约束。因此结合以往对非负矩阵分解在聚类方向的正则化方式以及约束条件,本文发明提出一种结合图正则化的非线性正交非负矩阵分解聚类算法,相较于以往的聚类算法有更高的精度。
4、名词解释:
5、karush-kuhn-tucker条件:即卡罗需-库恩-塔克条件,是在满足一些有规则的条件下,一个非线性规划(nonlinear programming)问题能有最优化解法的一个必要和充分条件。
技术实现思路
1、为解决上述技术问题,本发明公开了一种基于图正则化的非线性非负矩阵分解聚类算法。
2、为实现上述目的,本发明的技术方案如下:
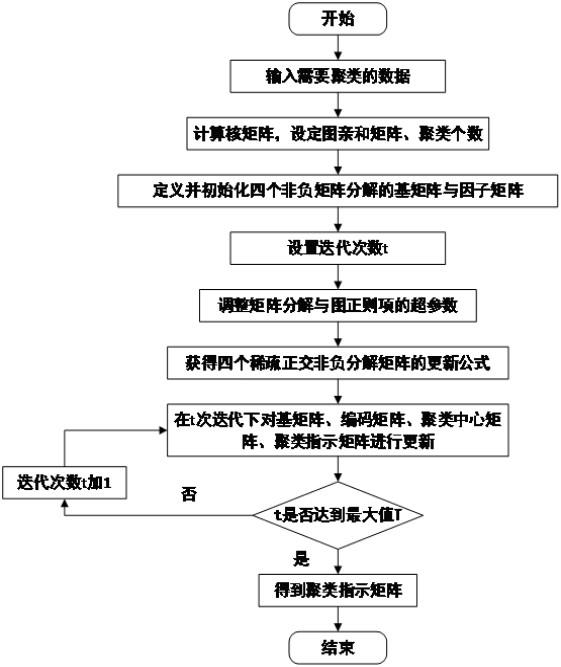
3、一种基于图正则化的非线性正交非负矩阵分解图像聚类方法,包括以下步骤:
4、步骤一、输入需要聚类的图像的数据矩阵:收集所需要聚类的数据信息,表示由n个数据点组成;表示m维实数空间,m表示样本的维度,n表示样本的个数;
5、步骤二、将数据矩阵映射到一个高维的d维非线性的映射空间得到非线性数据矩阵:
6、,然后计算得到核矩阵 k:;设定图亲和矩阵a和聚类种数k,其中;d>m;
7、步骤三、定义并初始化四个稀疏非负矩阵分解的矩阵,四个稀疏非负矩阵分解的矩阵分别为映射空间中的基矩阵f、编码矩阵h、聚类中心矩阵z、聚类指示矩阵s;
8、步骤四、定义基于图正则化的非线性非负矩阵分解聚类的目标函数并确定四个稀疏非负矩阵分解的矩阵的更新公式;
9、步骤五、对映射空间中的基矩阵f、编码矩阵h、聚类中心矩阵z、聚类指示矩阵s进行迭代更新,迭代求解基于图正则化的非线性非负矩阵分解聚类的目标函数,得到编码矩阵h;
10、步骤六、利用,一步得到聚类指示矩阵s与聚类中心矩阵z,将聚类指示矩阵s作为最终的聚类结果。
11、进一步的改进,所述步骤一中,数据矩阵通过将人脸图片灰度化,然后取每个像素点的位置和灰度值得到。
12、进一步的改进, 所述步骤二中,聚类种数k=4;所述步骤五中,迭代次数最大值为t。
13、进一步的改进,所述步骤四中,基于图正则化的非线性非负矩阵分解聚类的目标函数如下所示:
14、(1)
15、其中,x表示数据矩阵;
16、表示对数据矩阵进行非线性映射到高维空间;
17、f表示映射空间中的基矩阵;
18、h表示编码矩阵;
19、l表示图拉普拉斯矩阵;
20、s表示聚类指示矩阵;
21、z表示聚类中心矩阵;
22、i表示单位矩阵;
23、t表示矩阵转置;
24、tr表示矩阵的迹;
25、表示超参数;
26、s聚类得到结果,其中;
27、其中s表示聚类指示矩阵,z表示聚类的聚类中心矩阵。
28、进一步的改进,所述步骤四中,四个稀疏非负矩阵分解的矩阵的更新公式通过如下步骤得到:
29、求拉格朗日函数:
30、(2)
31、利用拉格朗日函数,对映射空间中的基矩阵f、编码矩阵h、聚类中心矩阵z、聚类指示矩阵s分别求偏导,并用karush-kuhn-tucker条件获取映射空间中的基矩阵f、编码矩阵h、聚类中心矩阵z、聚类指示矩阵s的更新公式,其表述分别为:
32、编码矩阵h更新公式的表达式为:
33、 (3)
34、其中;
35、映射空间中的基矩阵f更新公式的表达式为:
36、(4)
37、聚类中心矩阵z更新公式的表达式为:
38、(5)
39、聚类指示矩阵s更新公式的表达式为:
40、 (6)
41、其中, 表示矩阵的第i行第j列的元素值,和分别表示第t+1次和第t次迭代下编码矩阵h的第i列第j行的元素值;和分别表示第t+1次和第t次迭代下映射空间中基矩阵f的第i行第j列的元素值;和分别表示第t+1次和第t次迭代下聚类中心矩阵z的第i行第j列的元素值;和分别表示第t+1次和第t次迭代下聚类指示矩阵s的第i行第j列的元素值。
42、进一步的改进,所述步骤二中,将进行如下变换得到目标函数第一项中非线性矩阵分解部分:
43、(7)
44、其中w表示特征空间中的基矩阵,f表示映射空间中的基矩阵,h表示编码矩阵,i表示单位矩阵。
45、进一步的改进,所述步骤三中,编码矩阵h为k×n的矩阵,映射空间中的基矩阵f为n×k的矩阵,聚类中心矩阵z为k×k的矩阵,聚类指示矩阵s为k×n的矩阵。
46、本发明的有益效果:
47、本发明提供了一种基于图正则化的非线性正交非负矩阵分解聚类,与以往的基于非负矩阵分解的聚类方法相比:
48、首先本算法中对数据信息进行非线性映射到高维空间,使得相比于普通的非负矩阵分解聚类能更准确的对非线性数据进行聚类,比如环状数据,可以生成非线性的超平面进行划分;其次本算法将生成的编码矩阵分解为聚类中心矩阵与聚类指示矩阵,使得能根据目标方程一步得到聚类结果,不需要将编码矩阵再采取k-means;最后对编码矩阵与聚类指示矩阵添加了图正则化约束和正交约束,增强了编码矩阵与聚类指示矩阵的表达力。
49、在传统的非负矩阵分解聚类基础上,对数据进行非线性映射到高维空间,采用非线性非负矩阵分解,通过划分超平面有效提高环形数据聚类效果;将非线性非负矩阵分解得到的编码矩阵分解为聚类中心矩阵和聚类指示矩阵,对编码矩阵和聚类指示矩阵添加图正则化约束,提高算法的聚类准确性,使得通过目标函数的优化能够一步得到聚类结果(聚类指示矩阵)。而以往的非负矩阵分解聚类方法,需要先获得编码矩阵(数据表示),然后再对编码矩阵进行矩阵分解,才能得到聚类结果,是一种两步(two-step)聚类方法。
50、因此本发明相比以往的谱聚类、非负矩阵分解聚类具有更高的聚类精度。
- 还没有人留言评论。精彩留言会获得点赞!